matlab手写数字识别_手写数字识别系统 基于python
环境基于Python3.6和Tensorflow框架 实现手写数字识别系统
本文使用python基于TensorFlow设计手写数字识别算法,并编程实现GUI界面,构建手写数字识别系统。 文中首先对如何对手写数字图像的获取进行了介绍; 其次,对待手写数字图片的预处理的进行了介绍,包括二值化、高斯滤波、膨胀、腐蚀等图像处理方法,图片的预处理是利用opencv和PIL实现的; 之后,探讨了读取MNIST训练数据集数据与标签,设置CNN神经网络参数 ,归一化数据集标签并训练CNN神经网络; 最后GUI界面使用PyQt5,该识别器可以实时识别从GUI(图形用户界面)中画出的数字图片,利用截图的方式存储图片,并对图片进行预处理,进行界面分割成多个区域分别进行CNN识别,最终以一图一数字的形式组合返回至前端的手写数字识别系统。 实验结果表明,本方法具有较高的识别率,并具有较好的抗噪性能。系统组成
获取手写数字图像:用户使用鼠标在所开发系统的手写面板上书写多个数字。
手写数字图像预处理:对手写数字图像进行图像灰度化、图像二值化、去噪(干扰)等操作。
CNN神经网络训练:读取MNIST训练数据集数据与标签,设置CNN神经网络参数(隐藏层层数、迭代次数、激活函数等),归一化数据集标签并训练CNN神经网络。
手写数字图像识别:利用训练神经网络得到的权重信息测试手写数字识别功能。
开发环境
Windows 10 +python3.6 +tensorflow框架MNSIT数据集
MNIST 数据集来自美国国家标准与技术研究所National Institute of Standards and Technology (NIST)。训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员。测试集(test set) 也是同样比例的手写数字数据。它是一个计算机视觉数据集,它包含70000张手写数字的灰度图片,其中每一张图片包含 28 X 28 个像素点。每一张图片都有对应的标签,也就是图片对应的数字。数据集被分成两部分:60000 行的训练数据集(mnist.train)和10000行的测试数据集(mnist.test)。 其中:60000 行的训练集分拆为 55000 行的训练集和 5000 行的验证集。60000行的训练数据集是一个形状为 [60000, 784]的张量,第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点。在此张量里的每一个元素,都表示某张图片里的某个像素的强度值,值介于 0 和 1 之间。60000 行的训练数据集标签是介于 0 到 9 的数字,用来描述给定图片里表示的数字。称为 “one-hot vectors”。一个 one-hot向量除了某一位的数字是 1 以外其余各维度数字都是 0。如标签 0 将表示成 ( [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ] )。因此,其标签是一个 [60000, 10] 的数字矩阵。 [link]http://www.tensorfly.cn/tfdoc/tutorials/deep_cnn.htmlCNN神经网络
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一 。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification,因此也被称为“平移不变人工神经网络(Shift-Invariant Artificial Neural Networks, SIANN)”。 对卷积神经网络的研究始于二十世纪80至90年代,时间延迟网络和LeNet-5是最早出现的卷积神经网络 ;在二十一世纪后,随着深度学习理论的提出和数值计算设备的改进,卷积神经网络得到了快速发展,并被应用于计算机视觉、自然语言处理等领域 。 卷积神经网络仿造生物的视知觉(visual perception)机制构建,可以进行监督学习和非监督学习,其隐含层内的卷积核参数共享和层间连接的稀疏性使得卷积神经网络能够以较小的计算量对格点化(grid-like topo-logy)特征,例如像素和音频进行学习、有稳定的效果且对数据没有额外的特征工程(feature engineering)要求 。 [link]https://baike.baidu.com/item/卷积神经网络/17541100?fr=aladdinCNN神经网络训练模块程序实现
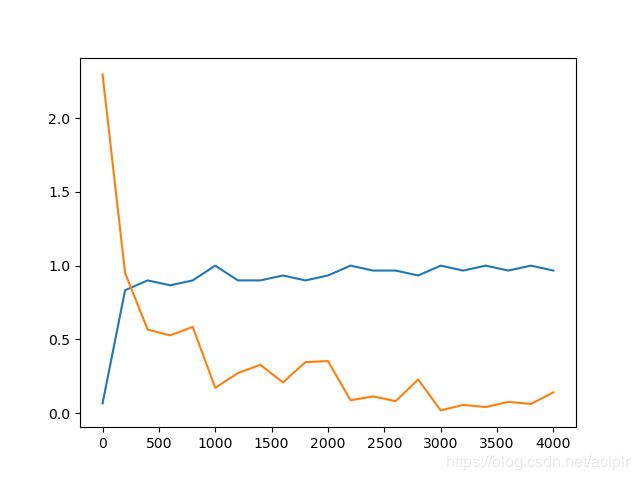
from tensorflow.examples.tutorials.mnist import input_dataimport tensorflow.contrib.slim as slimimport matplotlib.pyplot as pltimport tensorflow as tf#调用第三方库# ----------------------------------------------------------------------------------------------------------------------mnist = input_data.read_data_sets('MNIST_data',one_hot=True)# 第一次运行会自动下载到代码所在的路径下# MNIST_data 是保存的文件夹的名称sess = tf.InteractiveSession()# ----------------------------------------------------------------------------------------------------------------------def build_graph(): keep_prob_1 = tf.placeholder(dtype=tf.float32, shape=[], name='keep_prob_1') keep_prob_2 = tf.placeholder(dtype=tf.float32, shape=[], name='keep_prob_2') keep_prob_3 = tf.placeholder(dtype=tf.float32, shape=[], name='keep_prob_3') # 输入的数据 每张图片的大小是 28 * 28 # 方便矩阵乘法处理 x = tf.placeholder(tf.float32, shape=[None, 784]) y_ = tf.placeholder(tf.float32, shape=[None, 10]) x_image = tf.reshape(x, [-1, 28, 28, 1]) # 将输入tensor x调整成为28*28的矩阵形式 # 第一个卷积层 32个卷积核 h_conv1 = slim.conv2d(x_image, 32, [3, 3], 1, padding='SAME', activation_fn=tf.nn.relu) # 进行卷积操作W*X+b,得到线性变 化结果,在利用Tensoflow的relu规则进行非线性映射,得出卷积结果h_convi # 第二个卷积层 32个卷积核 h_conv2 = slim.conv2d(h_conv1, 32, [3, 3], 1, padding='SAME', activation_fn=tf.nn.relu) # 第二个池化层 h_pool1 = slim.max_pool2d(h_conv2, [2, 2], [2, 2], padding='SAME') # 采用了最大池化方法,其中ksize表示取样池的大小,strides表示步长,padding表示边缘补齐方法,SAME方式会在图片边缘补0,补齐边缘像素为1,最终得出池化结果h_pool1 # 第三个卷积层 64个卷积核 h_conv3 = slim.conv2d(slim.dropout(h_pool1, keep_prob_1), 64, [3, 3], 1, padding='SAME', activation_fn=tf.nn.relu) # 卷积层2的输入为32张特征映射图,有64个卷积核,最终将输出64个特征映射图 线性变化的结果 # 第四个卷积层 64个卷积核 h_conv4 = slim.conv2d(h_conv3, 64, [3, 3], 1, padding='SAME', activation_fn=tf.nn.relu) # 非线性变化的结果 # 第二个池化层 h_pool2 = slim.max_pool2d(h_conv4, [2, 2], [2, 2], padding='SAME') # 把矩阵flattern成一维的 flatten = slim.flatten(h_pool2) # 第一个全连接层 h_fc1 = slim.fully_connected(slim.dropout(flatten, keep_prob_2), 256, activation_fn=tf.nn.relu) # 全连接层设有256个神经元,本层的神经元数需要根据经验和实验结果进行反复调参确定。 # 第二个全连接层,输出为10个类别 y_conv = slim.fully_connected(slim.dropout(h_fc1, keep_prob_3), 10, activation_fn=None) #输出层为10维的向量 """ 这里我们定义的神经网络包括三个卷积层和两个全连接层,每个卷积层紧跟一个池化层。输入值的维度是batch_sizex784,代表batch_size个图片,每个图片大小是28x28,转换成一维的数据就是784。输出层维度是batch_sizex10,每一项是一个1x10个数组,代表一张图片属于0 - 9 每个数字的概率,最大的概率对应的数字就是分类的结果数字。 三个卷积层共享同样的padding、激活函数、Batch Normalization方法,所以我们提出来放到arg_scope里面。 第一个卷积层有32个卷积核,代表一张原始输入图片经过该卷积层会生成32张新的图片。第二层32个卷积核,代表在这一层每张输入的图片会生成32张新的图片, 依次类推。接下来是两个全连接层,为了将卷积层的输出接入到全连接层, 需要通过slim.flatten函数将卷积和池化后的特征摊平后输入全连接层。第一个全连接层共256个节点,将数据映射到256个节点;第二个全连接层将这256个节点映射到最终10个节点上,代表10个类别的结果。 [link]:https: // www.jianshu.com / p / c4a7eeff7e9f """ predict = tf.argmax(y_conv, 1) #交叉熵 '''训练和评估模型 为了训练我们的模型,我们首先需要定义损失函数(loss function),然后尽量最小化这个指标。这里使用的损失函数是 "交叉熵"(cross - entropy)。交叉熵产生于信息论里面的信息压缩编码技术,但是它后来演变成为从博弈论到机器学习等其他领域里的重要技术手段。它的定义如下: 计算交叉熵后,就可以使用梯度下降来优化参数。由于前面已经部署好网络结构,所以TensorFlow可以使用反向传播算法计算梯度,自动地优化参数,直到交叉熵最小。 TensorFlow提供了多种优化器,这里选择更加复杂的Adam优化器来做梯度最速下降,学习率0.0001。每次训练随机选择50个样本,加快训练速度,每轮训练结束后,计算预测准确度。 ''' cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))#类别预测与损失函数 softmax logdir指定了checkpoint和event文件保存的目录 train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)#训练模型 correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))#评估模型 accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))# 精确值 ''' loss 函数定义了一个我们想要优化的量。对于分类问题,loss 一般是正确的类别分布(true distribution)和预测的类别分布(predicted probability distribution across classes)之间的交叉熵(cross entropy)。对于回归问题,loss 一般是 预测值和真实值之间差值的平方和。 ''' return { 'x': x, 'y_': y_, 'keep_prob_1': keep_prob_1, 'keep_prob_2': keep_prob_2, 'keep_prob_3': keep_prob_3, 'loss': cross_entropy, 'accuracy': accuracy, 'train_step': train_step, 'y_conv': y_conv, 'predict': predict, }# ----------------------------------------------------------------------------------------------------------------------def train(): with tf.Session() as sess: graph = build_graph() sess.run(tf.global_variables_initializer())# 对于每一轮训练 saver = tf.train.Saver() STEP = [] ACCURACY = [] LOSS = [] # 在会话中执行网络定义的运算 for i in range(4001):#4001次训练 batch = mnist.train.next_batch(30) sess.run(graph['train_step'], feed_dict={graph['x']: batch[0], graph['y_']: batch[1], graph['keep_prob_1']: 0.25, graph['keep_prob_2']: 0.5, graph['keep_prob_3']: 0.5}) if i % 200 == 0:#每200次迭代输出一次 train_accuracy = sess.run(graph['accuracy'], feed_dict={graph['x']: batch[0], graph['y_']: batch[1], graph['keep_prob_1']: 1.0, graph['keep_prob_2']: 1.0, graph['keep_prob_3']: 1.0}) loss = sess.run(graph['loss'], feed_dict={graph['x']: batch[0], graph['y_']: batch[1], graph['keep_prob_1']: 1.0, graph['keep_prob_2']: 1.0, graph['keep_prob_3']: 1.0}) print("step %d, loss %g, training accuracy %g" % (i, loss, train_accuracy)) STEP.append(i) ACCURACY.append(train_accuracy) LOSS.append(loss) if i % 1000 == 0 and i > 0: saver.save(sess, './model.ckpt')#保存模型 ckpt文件是二进制文件,保存了所有的weights、biases、gradients等变量。在tensorflow 0.11之前,保存在.ckpt文件中 plt.plot(STEP, ACCURACY) plt.plot(STEP, LOSS) plt.show()# ----------------------------------------------------------------------------------------------------------------------train()
def paintEvent(self, event): # paintEvent()函数是QWidget类中的虚函数,用于ui的绘制#重写重绘事件处理函数实现绘图 painter = QPainter(self) # 绘图事件 # 绘图时必须使用QPainter的实例,此处为__painter # 绘图在begin()函数与end()函数间进行 # begin(param)的参数要指定绘图设备,即把图画在哪里 # drawPixmap用于绘制QPixmap类型的对象 self.painter.begin(self) self.painter.drawPixmap(0, 0, self.board) # 0,0为绘图的左上角起点的坐标,__board即要绘制的图 self.painter.end() def mousePressEvent(self, event): # 鼠标按下时,获取鼠标的当前位置保存为上一次位置 self.lastPos = event.pos() # 上一次鼠标位置def mouseMoveEvent(self, event): self.currentPos = event.pos() # 当前的鼠标位置 self.painter.begin(self.board) self.painter.setPen(QPen(self.penColor, self.thickness)) # 默认画笔粗细为10xp #设置默认画笔颜色为黑色 self.painter.drawLine(self.lastPos, self.currentPos) # 绘制范围 self.painter.end() self.lastPos = self.currentPos self.update()*图像预处理
图像处理中,最基本的就是色彩空间的转换。一般而言,我们的图像都是 RGB 色彩空间的,但在图像识别当中,我们可能需要转换图像到灰度图、二值图等不同的色彩空间。PIL 在这方面也提供了极完备的支持。def measure(image): blur = cv.GaussianBlur(image, (5, 5), 0)#使用高斯滤波器模糊图像,该函数将源图像与指定的高斯核进行卷积,支持就地过滤。 gray = cv.cvtColor(blur, cv.COLOR_RGB2GRAY)#转换成灰度图 _, out = cv.threshold(gray, 0, 255, cv.THRESH_BINARY_INV | cv.THRESH_OTSU)#对图像二值化 threshold_type可以使用CV_THRESH_OTSU类型,这样该函数就会使用大律法OTSU得到的全局自适应阈值来进行二值化图片,而参数中的threshold不再起作用。 ret, thresh = cv.threshold(gray, 0, 255, cv.THRESH_BINARY_INV | cv.THRESH_OTSU)#cv.THRESH_BINARY_INV 参数取反 thresh:閾值。threshold_type –对图像取阈值的方法 kernel = cv.getStructuringElement(cv.MORPH_RECT, (5, 5))#函数getStructuringElement,可以获取常用的结构元素的形状:矩形(包括线形)、椭圆(包括圆形)及十字形。 erode = cv.dilate(thresh, kernel)#腐蚀 #腐蚀后的图像,只检测最外面的轮廓,压缩水平的、垂直的和斜的部分,也就是,函数只保留他们的终点部分。 #cvFindContours将图片中识别到的轮廓返回给contours变量,contours是一个list类型数据,里面存放了识别到的所有轮廓 contours, hierarchy = cv.findContours(erode, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)#用cvFindContours获取轮廓 #将轮廓画入开始的image图像并显示GUI界面

