Hash表(C语言)
一、简介:
哈希表又称散列表。哈希表存储的基本思想是:以数据表中的每个记录的关键字 key为自变量,通过一种函数H(key)计算出函数值。把这个值解释为一块连续存储空间(即数组空间)的单元地址(即下标),将该记录存储到这个单元中。在此称该函数H为哈函数或散列函数。按这种方法建立的表称为哈希表或散列表。
二、哈希冲突:
不同key值产生相同的地址,H(key1)=H(key2)
处理冲突的方法:
(1)开放寻址法:![]() , i=1,2,…, k(k<=m-1),其中H(key)为散列函数,m为散列表长,
, i=1,2,…, k(k<=m-1),其中H(key)为散列函数,m为散列表长,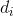 为增量序列,可有下列三种取法:
为增量序列,可有下列三种取法:
1.=1,2,3,…, m-1,称线性探测再散列;
2.![]() ...,
...,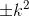 ,(k<=m/2)称二次探测再散列;
,(k<=m/2)称二次探测再散列;
3.=伪随机数序列,称伪随机探测再散列。
例:有一组数据19 01 23 14 55 68 11 86 37要存储在表长11的数组中,其中H(key)=key MOD 11
线性探测再散列
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| key | 55 | 1 | 14 | 19 | 86 | ||||||
| 23冲突 | 23 | ||||||||||
| 68冲突 | 68冲突 | 68 | |||||||||
| 11冲突 | 11冲突 | 11冲突 | 11冲突 | 11冲突 | 11 | ||||||
| 37冲突 | 37冲突 | 37 | |||||||||
| 最终存储结果 | 55 | 1 | 23 | 14 | 68 | 11 | 37 | 19 | 86 |
(2)再散列法:![]() ,i=1,2,…,k。
,i=1,2,…,k。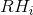 均是不同的散列函数,即在同义词产生地址冲突时计算另一个散列函数地址,直到冲突不再发生,这种方法不易产生“聚集”,但增加了计算时间
均是不同的散列函数,即在同义词产生地址冲突时计算另一个散列函数地址,直到冲突不再发生,这种方法不易产生“聚集”,但增加了计算时间
(3)链地址法(拉链法):将所有关键字为同义词的记录存储在同一线性链表中,产生hash冲突后在存储数据后面加一个指针,指向后面冲突的数据:
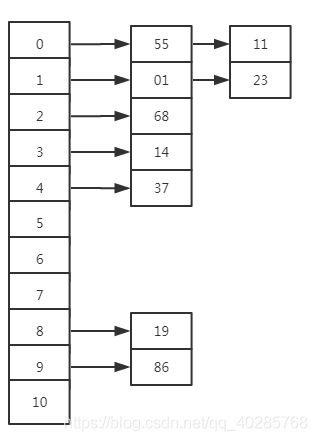
三、hash表的查找:
查找过程和造表过程一致,假设采用开放定址法处理冲突,则查找过程为:
1.对于给定的key,计算hash地址index = H(key)
2.如果数组arr[index]的值为空 则查找不成功
3.如果数组arr[index]== key 则查找成功
4.否则使用冲突解决方法求下一个地址,直到arr[index] == key 或者 arr[index] == null
hash表的查找效率
决定hash表查找的ASL因素:
(1)选用的hash函数
(2)选用的处理冲突的方法
(3)hash表的饱和度,装载因子 α=n/m(n表示实际装载数据长度,m为表长)
一般情况,假设hash函数是均匀的,则在讨论ASL时可以不考虑它的因素,hash表的ASL是处理冲突方法和装载因子的函数,前人已经证明,查找成功时如下结果:

可以看到无论哪个函数,装载因子越大,平均查找长度越大,那么装载因子α越小越好?也不是,就像100的表长只存一个数据,α是小了,但是空间利用率不高啊,这里就是时间空间的取舍问题了。通常情况下,认为α=0.75是时间空间综合利用效率最高的情况。上面的这个表可是特别有用的。假设我现在有10个数据,想使用链地址法解决冲突,并要求平均查找长度<2,那么有:1+α/2 <2,即α<2,即 n/m<2 (n=10),即m>10/2,即m>5,即采用链地址法,使得平均查找长度< 2,那么m>5。
hash表的构造应该是这样的:

四、hash表的删除:
首先链地址法是可以直接删除元素的,但是开放定址法是不行的,拿前面的双探测再散列来说,假如我们删除了元素1,将其位置置空,那 23就永远找不到了。正确做法应该是删除之后置入一个原来不存在的数据,比如-1。
五、算法实现:
#include
#include
#define hashtype int//声明数组元素类型
typedef struct {
int key; //键(在数组中的索引)
hashtype val; //值(元素值)
}DataType; //对基本数据类型进行封装,类似泛型
typedef struct {
DataType data;
struct HashNode *next; //key冲突时,通过next指针进行连接
}HashNode;
typedef struct {
int size;
HashNode *table;
}HashMap, *hashmap;
//f1_createHashMap
//将给定的整形数组构建为HashMap,size为数组长度
HashMap *CreateHashMap(int *nums, int size) {
//分配内存空间
HashMap *hashmap = (HashMap*)malloc(sizeof(HashMap));
hashmap->size = 2 * size;//2倍可寻找到‘冲突机会’和‘空间利用率’的一个平衡
//hash表分配空间
hashmap->table = (HashNode *)malloc(sizeof(HashNode)*hashmap->size);
//初始化
int j = 0;
for (j = 0; jsize; j++) {
hashmap->table[j].data.val = INT_MIN;
hashmap->table[j].next = NULL;
}
int i = 0;
//建立HashMap
while (isize;
//判断是否冲突
if (hashmap->table[pos].data.val == INT_MIN) {
//不冲突
//把元素在数组中的索引作为key
hashmap->table[pos].data.key = i;
//把元素值作为value
hashmap->table[pos].data.val = nums[i];
}
//冲突
else {
//给当前元素分配一个结点,并为结点复制
HashNode *lnode = (HashNode*)malloc(sizeof(HashNode)), *hashnode;
lnode->data.key = i;
lnode->data.val = nums[i];
lnode->next = NULL;
//从冲突位置开始,遍历链表
hashnode = &(hashmap->table[pos]);
while (hashnode->next != NULL) {
hashnode = hashnode->next;
}
//将当前结点连接到链表尾部
hashnode->next = lnode;
}
//处理下一个元素
i++;
}
//处理完成,返回HashMap
return hashmap;
}
//f2_GetHashNode
int Get(HashMap hashmap, int value) { //根据元素值,计算其位置
int pos = abs(value) % hashmap.size;
HashNode *pointer = &(hashmap.table[pos]);
//在当前链表遍历查找该结点
while (pointer != NULL) {
if (pointer->data.val == value)
return pointer->data.key;
else
pointer = pointer->next;
}
//未找到,返回-1
return -1;
}
//f3_Put,与建立HashMap时插入元素的方法相同
int Put(HashMap hashmap, int key, int value) {
int pos = abs(value) % hashmap.size;
HashNode *pointer = &(hashmap.table[pos]);
if (pointer->data.val == INT_MIN)
{
pointer->data.val = value;
pointer->data.key = key;
}
else {
while (pointer->next != NULL)
pointer = pointer->next;
HashNode *hnode = (HashNode *)malloc(sizeof(HashNode));
hnode->data.key = key;
hnode->data.val = value;
hnode->next = NULL;
pointer->next = hnode;
}
return 1;
}
//f4_PrintHashMap
void PrintHashMap(HashMap* hashmap) {
printf("%===========PrintHashMap==========\n");
int i = 0;
HashNode *pointer;
while (isize) {
pointer = &(hashmap->table[i]);
while (pointer != NULL) {
if (pointer->data.val != INT_MIN)
printf("%10d", pointer->data.val);
else
printf(" [ ]");
pointer = pointer->next;
}
printf("\n---------------------------------");
i++;
printf("\n");
}
printf("===============End===============\n");
}
//f5_DestoryHashMap
void DestoryHashMap(HashMap *hashmap) {
int i = 0;
HashNode *hpointer;
while (isize) {
hpointer = hashmap->table[i].next;
while (hpointer != NULL) {
hashmap->table[i].next = hpointer->next;
//逐个释放结点空间,防止内存溢出
free(hpointer);
hpointer = hashmap->table[i].next;
hashmap->table[i].next = NULL;//消除野指针
}
//换至下一个结点
i++;
}
free(hashmap->table);
hashmap->table = NULL;
free(hashmap);
hashmap = NULL;
printf("Destory hashmap Success!");
}
int main(int argc, char **argv)
{
int nums[] = { 34,54,32,32,56,78 };
//创建HashMap
HashMap *hashmap = CreateHashMap(nums, 6);
PrintHashMap(hashmap);
//查找元素
printf("%d\n", Get(*hashmap, 78));
DestoryHashMap(hashmap);
getchar();
return 0;
} 五、版权声明:
本文节选或转载CSDN博主「洌冰」的原创文章,遵循 CC 4.0 BY-SA 版权协议,以下附上原文出处链接。
原文链接:https://blog.csdn.net/u011109881/article/details/80379505
本文节选或转载CSDN博主「Rnan_wang」的原创文章,遵循 CC 4.0 BY-SA 版权协议,以下附上原文出处链接。
原文链接:https://blog.csdn.net/qq_19446965/article/details/102290770