数据结构之哈希表以及常用哈希的算法表达(含全部代码)
目录
为什么要有哈希
哈希表
含义
创建哈希表需要注意的点
算法的选择
哈希冲突的处理
线性探测法
再哈希法
链表法
哈希表的实现(代码部分)
确定结构体(节点)
准备一个哈希算法
创建一个哈希表(即开辟空间)
创建节点
数据加入哈希表的具体实现
获取数据,数据加入哈希表
打印哈希表
查找哈希表(重点,这也能帮你理解哈希表的结构与优势所在)
销毁哈希表
主函数
为什么要有哈希
如果要存储一组数据,我们都能想到使用数组或者链表来存储,但是实际生产生活中,数据都是非常庞大的,动辄几十G,几十T,甚至以P来计算。这样一来,数组和链表的优势以劣势就非常明显了。
| 插入数据 | 查找数据 | |
| 数组 | 劣势 | 优势 |
| 链表 | 优势 | 劣势 |
既然这两种方法都不能完美解决实际问题,那就一定会有一种方法的诞生来处理它,我们的哈希表就这样诞生啦,哈希表集这两种存储形式的优点于一身,接下来就让我们走进哈希表吧。
哈希表
含义
哈希表也叫散列表,哈希表是一种数据结构,它提供了快速的插入操作和查找操作,无论哈希表总中有多少条数据,在有足够优秀的哈希算法时,插入和查找的时间复杂度都是为O(1)。
散列表 ( Hash table ),是根据键(Key)而直接访问在记忆体储存位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表 。表中存储的是一个地址,我们通过键值计算出来的哈希值得到这个地址,再取这个地址中的数据即可。
创建哈希表需要注意的点
算法的选择
常见的算法形式有,根据键值进行加法运算,减法运算,乘法运算,位移运算。
值得一说的是位移运算,无论是前移还是后移, 都会使键值转换出来的哈希值大小难以确定,可能有键值很大,但是哈希值很小的情况,这就让使用者无法大致确定键值对应的哈希值。但这并不是缺点,看实际生产要求。
而一般都是以上几种运算的复合运算作为哈希算法。例如;
hashvalue = (hashvalue << 4) + hashvalue + *key++;
//hashvalue为哈希值,key为键值哈希冲突的处理
哈希冲突即为不同键值通过哈希算法得到了相同的哈希值,这种情况,我们肯定不能将数据直接存储到对应的地址去,这样会将原来的数据覆盖。对此常见的 方法有一下三种,我们最推荐使用链表的方式。
线性探测法
在线性探测哈希表中,数据的插入是线性的查找空白单元,例如我们将数88经过哈希函数后得到的数组下标是16,但是在数组下标为16的地方已经存在元素,那么就找17,17还存在元素就找18,一直往下找,直到找到空白地方存放元素。
再哈希法
双哈希是为了消除原始聚集和二次聚集问题,线性探测每次的探测步长都是固定的。双哈希是除了第一个哈希函数外再增加一个哈希函数用来根据关键字生成探测步长,这样即使第一个哈希函数映射到了数组的同一下标,但是探测步长不一样,这样就能够解决聚集的问题。
第二个哈希函数必须具备如下特点
- 和第一个哈希函数不一样
- 不能输出为0,因为步长为0,每次探测都是指向同一个位置,将进入死循环,经过试验得出
stepSize = constant-(key%constant);形式的哈希函数效果非常好,constant是一个质数并且小于数组容量
链表法
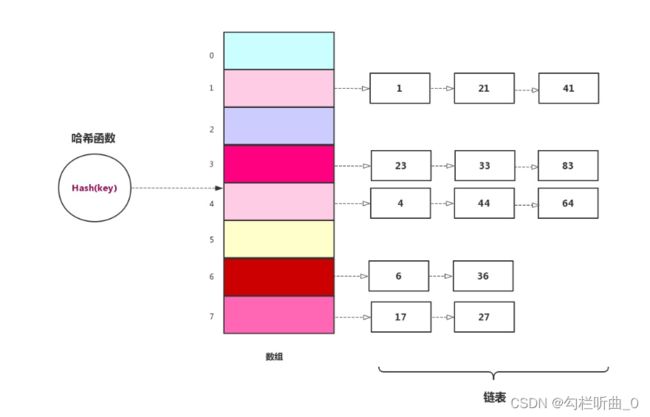
通过在哈希表中再寻找一个空位解决冲突的问题,还有一种更加常用的办法是使用「链表法」来解决哈希冲突。「链表法」相对简单很多,「链表法」是每个数组对应一条链表。当某项关键字通过哈希后落到哈希表中的某个位置,把该条数据添加到链表中,其他同样映射到这个位置的数据项也只需要添加到链表中,并不需要在原始数组中寻找空位来存储。
哈希表的实现(代码部分)
确定结构体(节点)
#define HASHSIZE 256 //你的哈希表的元素个数
typedef int mydatatype;
typedef unsigned char uint8;
struct node
{
//char * key;//键值,最好使用指针,这里为了便捷,使用数组
char key[128];
mydatatype data;//这个东西就是你的数据
struct node * next; //解决哈希冲突的链表法
};准备一个哈希算法
/*
GetHashValue:获取哈希值
@key:输入的键值
返回值:
输入的键值对应的哈希值
*/
uint8 GetHashValue(const char * key)
{
uint8 hashvalue = 0;
while(*key)
{
hashvalue = (hashvalue << 4) + hashvalue + *key++; //首先我们应该准备一个哈希算法
//你可能会要调试多次
}
printf("hashvalue = %d\n",hashvalue);
return hashvalue;
}创建一个哈希表(即开辟空间)
/*
GetHashTable: 得到一个哈希表
返回值:
哈希表所需的空间
*/
struct node ** GetHashTable(void)
{
//这个空间开出来就是为了保存地址的
//因此sizeof(struct node *)
return (struct node **)calloc(sizeof(struct node *) , HASHSIZE); //calloc会初始化空间为0
}创建节点
/*
GetDataNode: 创建节点的函数
@key:输入的键值
@data:键值对应的数据
返回值:
哈希表的一个节点
*/
static struct node * GetDataNode(const char * key,mydatatype data) //const关键字对变量加以限定,使它不能被改变
{
struct node * pnew = malloc(sizeof(struct node));
strcpy(pnew ->key,key); //注意,这里不能直接写pnew->key = key;
pnew ->data = data;
pmew ->next = NULL;
return pnew;
}数据加入哈希表的具体实现
/*
InsertDataToHashTable:将数据加入到哈希表
@ht:哈希表
@key:键值
@date:键值对应的数值
*/
static void InsertDataToHashTable(struct node ** ht,const char * key,mydatatype data)
{
struct node *pnew = GetDataNode(key,data);
//计算哈希值
uint8 hashvalue = GethashValue(key);
if(!ht[hashvalue]) //如果哈希表的下标为hashvalue的元素为空
//则这个地方是没有填入数据的 直接填入就可以了
{
ht[hashvalue]) = pnew;
}
else
{
//如果有hashvlaue与key值d都相同的情况
//一般有两种做法 1 直接丢弃不用 2 加上一个num计数
//一般我们用尾插法插入
struct node * p = ht[hashvalue];
while(p)
{
if(!strcmp(p ->key,key))
{
free(pnew);
printf("键值一样\n");
return;
}
p = p->next;
}
p = pnew; //p已经是最后一个节点的next
}
}获取数据,数据加入哈希表
/*
GetData:获取数据,加入到哈希表中
@ht:哈希表
*/
void GetData(struct node ** ht)
{
if(!ht)
return;
mydatatype data;
char key[128] = {0};
while(1)
{
//先输入键值,再输入data
if(scanf("%s%d",key,data) != 2)//你匹配上的东西不等于2 说明你的匹配失败
{
char ha[1024];
fgets(ha,1024,stdin); //将标准输入里面的东西拿掉
printf("输入有误,请重新输入\n");
` continue;
}
if(!strncmp(key,"##",2)) //输入“##”结束输入
break;
InsertDataToHashTable(ht,key,data);
}
}打印哈希表
/*
PrintHashTable:打印这个哈希表
@ht:哈希表
*/
void PrintHashTable(struct node ** ht)
{
int i;
for(i = 0;i < HASHSIZE;i++)
{
if(ht[i])
{
struct node *p = hr[i];
while(p)
{
printf("HV = %d\tkey = %s\tdata = %d\n",i,p->key,p->data);
p = p ->next;
}
}
}
}查找哈希表(重点,这也能帮你理解哈希表的结构与优势所在)
/*
FindData:查找哈希表
@ht:哈希表
@key:键值
*/
void FindData(struct node ** ht,const char * key)
{
uint8 hashvalue = GetHashValue(key);
if(ht[hashvalue]) //哈希表存在
{
struct node * p = ht[hashvalue];
int i = 1;
while(p)
{
if(strcmp(p ->key,key)
{
printf("找到了,键值为%d中的第%d个,value = %d\n",hashvalue,i,p->data);
return;
}
i++;
p = p ->next;
}
}
printf("查找的元素%s不存在\n",key);
}销毁哈希表
/*
DestoryHashTable:销毁这个哈希表
@ht:哈希表
*/
void DestoryHashTable(struct node ** ht)
{
int i = 0;
for(i = 0;i < HASHSIZE;i++)
{
struct node * p = ht[i];
struct node * pre = NULL;
while(!ht[i])
{
if(p ->next)
{
free(p);
pre ->next = NULL;
p = ht[i];
}
else
{
pre = p;
p = p ->next;
}
}
}
}主函数
int main()
{
struct node ** ht = GetHashTable();
GetData(ht);
PrintHashTable(ht);
printf("输入你要查找的键值:");
char buf[128] = {0};
scanf("%s",buf);
FindData(ht,buf);
DestoryHashTable(ht);
return 0;
}
如果有帮助的话,欢迎点赞收藏哦~,也可以点点关注,获取更多资源。