AlphaFold2源码解析(10)--补充信息1(residue_constants)
AlphaFold2源码解析(10)–补充信息1(residue_constants)
这篇文章总结的很好,来之生信小兔,这里只是收藏一下,转载来源https://blog.csdn.net/weixin_60737527/article/details/125905270?spm=1001.2014.3001.5502
residue_constances.py 是AlphaFold中最基本的模块,其中包含了所有蛋白质氨基酸的各种参数、相关数据以及在后面数据处理中所需工具。是AlphaFold中最基础的部分
氨基酸的基础知识与相关数据表示
在生物化学等课程中,关于氨基酸的各种知识讲述较为详细,但是较少提及氨基酸具体的分子结构、各个原子的命名方法等。
首先,我们知道,氨基酸结构通式为H2N-CHR-COOH:
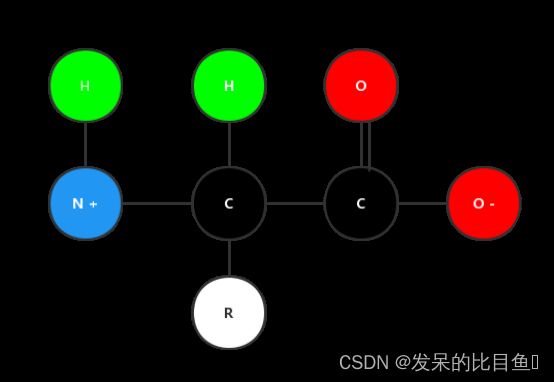
氨基酸结构主要特点是:有氨基和羧基连接在同一个碳原子上,我们把该碳原子称为中心碳,则氨基酸中心碳还连接H原子与侧链基团R。不同氨基酸的差别就在于R基团的不同。
原子标注
AlphaFold中采用的原子标注依照PDB惯例。以连接羧基的碳原子(中心碳)为α-碳,羧基中碳原子、氧原子直接用C、O表示;与α-碳相连的氮原子直接用N表示。羧基中的羟基、氨基中的氢在形成肽链时脱水缩合,与问题的研究无关;与α-碳连接的H和与N连接的另一个H,是每个氨基酸都存在的,并且它们的位置与肽链的走向无关,所以不考虑这些原子。例如,对于Gly甘氨酸,它的原子种类组成就可以写成:‘C’,‘CA’,‘N’,‘O’。其中CA即为α-碳(在编写代码时直接用α等希腊字母是错误的,采用CA、CB、NZ等表示C-α、C-β、Nζ)。
对于其它含有复杂侧链的氨基酸,原子种类会更加的丰富。这时我们把碳链当作主链,那么R基中与α-C连接的碳为β-C,之后依次为γ-C、δ-C…如果有两个碳连接在β-C,那么另一个主链外的碳命名为CG1(C-γ1),以此类推。对于这里的所有氨基酸,只用到了α~ζ六个希腊字母。
对于一些氨基酸,如Arg精氨酸,末端的NH2、NH整体表示,连在中间的N按照希腊字母顺序命名为NE(N-ε)。即使链中原子发生改变,希腊字母顺序依旧,例如如半胱氨酸中的SG(S-γ)以及前面精氨酸中NE等。而把基团作为整体表示的情况需要结合具体情况,例如前面的精氨酸末端NH2、NH整体表示,酪氨酸中末端OH也是整体表示,而丝氨酸末端OH直接连在主链,所以不是用OH整体表示,而是OG(O-γ)。
含有苯环的情况,命名规律也是如此。如酪氨酸,苯环上的碳原子标注如下:

这样,我们就可以对每个氨基酸进行原子标注。最终的标注数据保存在该模块下中的residue_atoms字典中。
residue_atoms = {
'ALA': ['C', 'CA', 'CB', 'N', 'O'],
'ARG': ['C', 'CA', 'CB', 'CG', 'CD', 'CZ', 'N', 'NE', 'O', 'NH1', 'NH2'],
'ASP': ['C', 'CA', 'CB', 'CG', 'N', 'O', 'OD1', 'OD2'],
'ASN': ['C', 'CA', 'CB', 'CG', 'N', 'ND2', 'O', 'OD1'],
'CYS': ['C', 'CA', 'CB', 'N', 'O', 'SG'],
'GLU': ['C', 'CA', 'CB', 'CG', 'CD', 'N', 'O', 'OE1', 'OE2'],
'GLN': ['C', 'CA', 'CB', 'CG', 'CD', 'N', 'NE2', 'O', 'OE1'],
'GLY': ['C', 'CA', 'N', 'O'],
'HIS': ['C', 'CA', 'CB', 'CG', 'CD2', 'CE1', 'N', 'ND1', 'NE2', 'O'],
'ILE': ['C', 'CA', 'CB', 'CG1', 'CG2', 'CD1', 'N', 'O'],
'LEU': ['C', 'CA', 'CB', 'CG', 'CD1', 'CD2', 'N', 'O'],
'LYS': ['C', 'CA', 'CB', 'CG', 'CD', 'CE', 'N', 'NZ', 'O'],
'MET': ['C', 'CA', 'CB', 'CG', 'CE', 'N', 'O', 'SD'],
'PHE': ['C', 'CA', 'CB', 'CG', 'CD1', 'CD2', 'CE1', 'CE2', 'CZ', 'N', 'O'],
'PRO': ['C', 'CA', 'CB', 'CG', 'CD', 'N', 'O'],
'SER': ['C', 'CA', 'CB', 'N', 'O', 'OG'],
'THR': ['C', 'CA', 'CB', 'CG2', 'N', 'O', 'OG1'],
'TRP': ['C', 'CA', 'CB', 'CG', 'CD1', 'CD2', 'CE2', 'CE3', 'CZ2', 'CZ3',
'CH2', 'N', 'NE1', 'O'],
'TYR': ['C', 'CA', 'CB', 'CG', 'CD1', 'CD2', 'CE1', 'CE2', 'CZ', 'N', 'O',
'OH'],
'VAL': ['C', 'CA', 'CB', 'CG1', 'CG2', 'N', 'O']
}
所有的氨基酸包含的原子种类保存在atom_types列表中。
atom_types = [
'N', 'CA', 'C', 'CB', 'O', 'CG', 'CG1', 'CG2', 'OG', 'OG1', 'SG', 'CD',
'CD1', 'CD2', 'ND1', 'ND2', 'OD1', 'OD2', 'SD', 'CE', 'CE1', 'CE2', 'CE3',
'NE', 'NE1', 'NE2', 'OE1', 'OE2', 'CH2', 'NH1', 'NH2', 'OH', 'CZ', 'CZ2',
'CZ3', 'NZ', 'OXT']
所有的原子种类数为atom_type_num。atom_order是根据atom_types每个原子在列表中的索引位置进行标注,每个原子对应一个数,以字典的形式储存。
atom_order = {atom_type: i for i, atom_type in enumerate(atom_types)}
atom_type_num = len(atom_types) #atom_type_num=37
在这些氨基酸中,每个氨基酸含有的原子个数不同,最多的有14个。所以可以用长度为14、元素为各个原子类型的列表表示各个氨基酸,若原子个数不足14,用空字符串补足。restype_name_to_atom14_names便是如此。
restype_name_to_atom14_names = {
'ALA': ['N', 'CA', 'C', 'O', 'CB', '', '', '', '', '', '', '', '', ''],
'ARG': ['N', 'CA', 'C', 'O', 'CB', 'CG', 'CD', 'NE', 'CZ', 'NH1', 'NH2', '', '', ''],
'ASN': ['N', 'CA', 'C', 'O', 'CB', 'CG', 'OD1', 'ND2', '', '', '', '', '', ''],
'ASP': ['N', 'CA', 'C', 'O', 'CB', 'CG', 'OD1', 'OD2', '', '', '', '', '', ''],
'CYS': ['N', 'CA', 'C', 'O', 'CB', 'SG', '', '', '', '', '', '', '', ''],
'GLN': ['N', 'CA', 'C', 'O', 'CB', 'CG', 'CD', 'OE1', 'NE2', '', '', '', '', ''],
'GLU': ['N', 'CA', 'C', 'O', 'CB', 'CG', 'CD', 'OE1', 'OE2', '', '', '', '', ''],
'GLY': ['N', 'CA', 'C', 'O', '', '', '', '', '', '', '', '', '', ''],
'HIS': ['N', 'CA', 'C', 'O', 'CB', 'CG', 'ND1', 'CD2', 'CE1', 'NE2', '', '', '', ''],
'ILE': ['N', 'CA', 'C', 'O', 'CB', 'CG1', 'CG2', 'CD1', '', '', '', '', '', ''],
'LEU': ['N', 'CA', 'C', 'O', 'CB', 'CG', 'CD1', 'CD2', '', '', '', '', '', ''],
'LYS': ['N', 'CA', 'C', 'O', 'CB', 'CG', 'CD', 'CE', 'NZ', '', '', '', '', ''],
'MET': ['N', 'CA', 'C', 'O', 'CB', 'CG', 'SD', 'CE', '', '', '', '', '', ''],
'PHE': ['N', 'CA', 'C', 'O', 'CB', 'CG', 'CD1', 'CD2', 'CE1', 'CE2', 'CZ', '', '', ''],
'PRO': ['N', 'CA', 'C', 'O', 'CB', 'CG', 'CD', '', '', '', '', '', '', ''],
'SER': ['N', 'CA', 'C', 'O', 'CB', 'OG', '', '', '', '', '', '', '', ''],
'THR': ['N', 'CA', 'C', 'O', 'CB', 'OG1', 'CG2', '', '', '', '', '', '', ''],
'TRP': ['N', 'CA', 'C', 'O', 'CB', 'CG', 'CD1', 'CD2', 'NE1', 'CE2', 'CE3', 'CZ2', 'CZ3', 'CH2'],
'TYR': ['N', 'CA', 'C', 'O', 'CB', 'CG', 'CD1', 'CD2', 'CE1', 'CE2', 'CZ', 'OH', '', ''],
'VAL': ['N', 'CA', 'C', 'O', 'CB', 'CG1', 'CG2', '', '', '', '', '', '', ''],
'UNK': ['', '', '', '', '', '', '', '', '', '', '', '', '', ''],
}
在氨基酸内标注原子时,我们发现,由于一些氨基酸部分结构具有对称性,导致命名时会出现摸棱两可的情况,如天冬氨酸Asp中OD1与OD2。所以定义residue_atom_renaming_swaps,用以氨基酸内部原子命名交换。
residue_atom_renaming_swaps = {
'ASP': {'OD1': 'OD2'},
'GLU': {'OE1': 'OE2'},
'PHE': {'CD1': 'CD2', 'CE1': 'CE2'},
'TYR': {'CD1': 'CD2', 'CE1': 'CE2'},
}
氨基酸的字符表示
对于蛋白质氨基酸,我们除了使用其全称,更倾向于使用单字符或三字符缩写表示方法。而在处理各种氨基酸数据信息时,单字符和三字符都是存在的,所以为了之后数据处理的方便,这里定义了两个字典:restype_1to3是以单字符为键,以三字符为值;restype_3to1是以三字符为键,单字符为值。
restype_1to3= {
'A': 'ALA',
'R': 'ARG',
'N': 'ASN',
'D': 'ASP',
'C': 'CYS',
'Q': 'GLN',
'E': 'GLU',
'G': 'GLY',
'H': 'HIS',
'I': 'ILE',
'L': 'LEU',
'K': 'LYS',
'M': 'MET',
'F': 'PHE',
'P': 'PRO',
'S': 'SER',
'T': 'THR',
'W': 'TRP',
'Y': 'TYR',
'V': 'VAL',
}
restype_3to1 = {v: k for k, v in restype_1to3.items()}
这两个字典对于后面氨基酸表示符的转换是非常有帮助的。
与前面的原子标注一样,我们也需要氨基酸种类、数目以及等信息。残基种类(单字符表示)保存在restypes列表中,restype_num为氨基酸种类数。restypes列表中对应氨基酸的对应索引位置保存在restype_order列表中。
restypes = ['A', 'R', 'N', 'D', 'C', 'Q', 'E', 'G', 'H', 'I', 'L', 'K', 'M', 'F', 'P', 'S', 'T', 'W', 'Y', 'V']
restype_order = {restype: i for i, restype in enumerate(restypes)}
restype_num = len(restypes)
在实际遇到的问题中,也可能会出现不属于这20种氨基酸的情况,于是对于所有的未知氨基酸,由unk_restype='UNK'来表示(三字符),单字符表示为X。unk_restype_index表示未知氨基酸索引,restypes_with_x为包含未知氨基酸X的列表,restype_order_with_x为包含X的各氨基酸索引字典。
unk_restype_index = restype_num
restypes_with_x = restypes + ['X']
restype_order_with_x = {restype: i for i, restype in enumerate(restypes_with_x)}
在hhlblits惯例中,除了上面单字符表示氨基酸使用的字母,所有26字母有都对应的氨基酸,如B映射为氨基酸D,U映射为氨基酸C等等,X表示未知氨基酸,而'-'表示缺失氨基酸。HHBLITS_AA_TO_ID是键为字符、值为[0,2,1]的字典,它把字母映射为对应氨基酸索引。
HHBLITS_AA_TO_ID = {
'A': 0,
'B': 2,
'C': 1,
'D': 2,
'E': 3,
'F': 4,
'G': 5,
'H': 6,
'I': 7,
'J': 20,
'K': 8,
'L': 9,
'M': 10,
'N': 11,
'O': 20,
'P': 12,
'Q': 13,
'R': 14,
'S': 15,
'T': 16,
'U': 1,
'V': 17,
'W': 18,
'X': 20,
'Y': 19,
'Z': 3,
'-': 21,
}
ID_TO_HHBLITS_AA是将氨基酸索引映射成部分单字符。
ID_TO_HHBLITS_AA = {
0: 'A',
1: 'C', # Also U.
2: 'D', # Also B.
3: 'E', # Also Z.
4: 'F',
5: 'G',
6: 'H',
7: 'I',
8: 'K',
9: 'L',
10: 'M',
11: 'N',
12: 'P',
13: 'Q',
14: 'R',
15: 'S',
16: 'T',
17: 'V',
18: 'W',
19: 'Y',
20: 'X', # Includes J and O.
21: '-',
}
restypes_with_x_and_gap:包含未知氨基酸'X'与缺失氨基酸'-'的列表。
MAP_HHBLITS_AATYPE_TO_OUR_AATYPE:将hhblits中氨基酸转成restype_with_x_and_gap中对应氨基酸索引。
restypes_with_x_and_gap = restypes + ['X', '-']
MAP_HHBLITS_AATYPE_TO_OUR_AATYPE = tuple(
restypes_with_x_and_gap.index(ID_TO_HHBLITS_AA[i])
for i in range(len(restypes_with_x_and_gap)))
氨基酸的结构信息
氨基酸的一些结构信息可以由load_stereo_chemical_props函数得到,包括所有键长、键角等信息。但是,知道某一分子所有键长键角信息,这个分子的具体结构就完全确定了吗?答案是否定的。
如图所示,该分子所有键长与键角都是不变的,但是分子的结构仍是可以变化的。我们发现,当键长键角确定后,这些分子形成的二面角是不固定的,分子内部二面角变化会影响分子结构,就像机械臂一样。所以对于所有键长键角都确定的情况,我们把相对固定的(如上图中底面三个原子和转动的三个原子作为整体)的一群原子作为一个整体,整体内部所有原子的相对位置都是固定的,而相邻的整体之间相对位置不固定。此时,只要确定了所有相邻整体二面角,整个分子结构也就确定了。
如下图所示,ABC为一个整体,BCD也是一个整体,二面角可以由4个原子A,B,C,D确定。这个分子一共有3个二面角,所以我们可以用这三个二面角来参数化(parameterize)该分子,二面角可以由4个原子表示。则该分子参数化为:[[A,B,C,D],[B,C,D,E],[C,D,E,F]]。这些二面角在AlphaFold中称为扭转角(tursion angles),每个扭转角转动轴是固定的,所以只有一个自由度(degrees of freedom)。
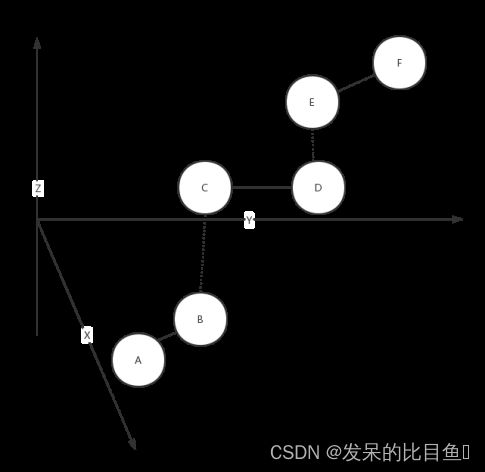
依据相对位置固定划分分子,会出现相同原子在不同整体的情况,是因为这些分子在转轴上。在AlphaFold中,则是依据原子对扭转角的依赖性而划分,将原子分组为“刚性组”(rigid groups)。以上图为例,令该分子中扭转角为{θ1,θ2,θ3},ABC固定时,D原子位置依赖于θ1,而与θ2,θ3无关,所以D原子属于θ1组(group);E原子位置受θ1与θ2共同影响,与θ2直接相关,与θ3无关,它属于θ2组;F为θ3组。ABC三原子位置与θ无关,单独分为一组。
在氨基酸中,把仅依赖氨基酸主链框架的原子归为“backbone rigid group”,简称bb-group,它包含C、CA、CB、N四个原子。在赖氨酸中,由于没有R基,bb-group只有C、CA、N。主链氢原子H位置依赖于 ω , ϕ \omega, \phi ω,ϕ,扭转角,表示这些原子与主链夹角,分别归为 ω \omega ω-group、 ϕ \phi ϕ-group。 ψ \psi ψ扭转角为羧基氧与主链夹角,所以羧基氧O属于 ψ \psi ψ-group。 χ 1 , χ 2 , χ 3 , χ 4 \chi_1, \chi_2, \chi_3, \chi_4 χ1,χ2,χ3,χ4 依次表示侧链上的扭转角,依赖相应角的原子归为 χ \chi χ-group。在赖氨酸中,由于没有侧链,也就没有角;精氨酸(arg)虽有角,但是角度很小,仅在0度附近,故忽略此角。所以对于蛋白质氨基酸,我们一共定义7种扭转角,记为
S t u r s i o n n a m e s = { ω , ϕ , ψ , χ 1 , χ 2 , χ 3 , χ 4 } S_{tursion \ names}=\{\omega,\phi,\psi,\chi_1,\chi_2,\chi_3, \chi_4 \} Stursion names={ω,ϕ,ψ,χ1,χ2,χ3,χ4}
其中前三个为主链扭转角,后4个为侧链扭转角。
以精氨酸为例,刚性组rigid group划分如下。
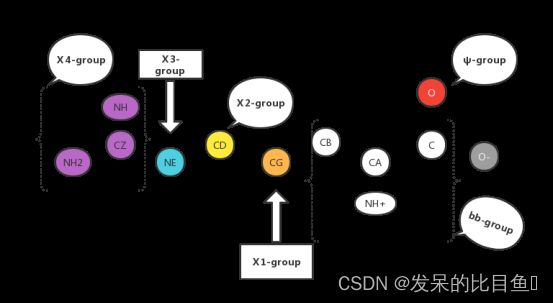
其中的各个Ⅹ扭转角可表示为Ⅹ1:[‘N’, ‘CA’, ‘CB’, ‘CG’], Ⅹ2[‘CA’, ‘CB’, ‘CG’, ‘CD’],Ⅹ3[‘CB’, ‘CG’, ‘CD’, ‘NE’], Ⅹ4[‘CG’, ‘CD’, ‘NE’, ‘CZ’]。
对于所有氨基酸的bb-group、ψ-group、Ⅹ-group,如下表所示(摘自论文补充材料P24)。
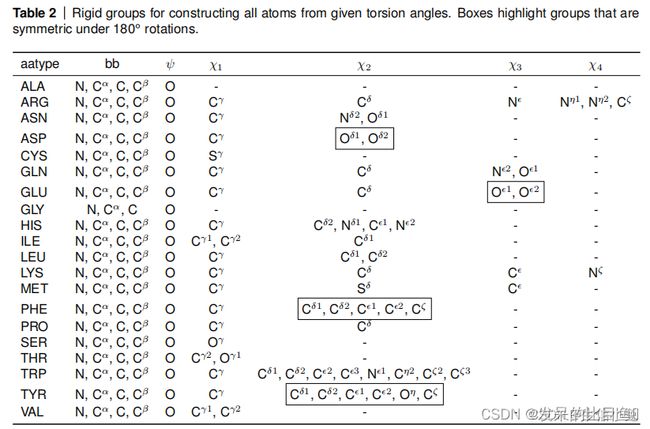
各个氨基酸的各个Ⅹ角(氨基酸扭转角Ⅹ的参数化数据)保存在chi_angle_atoms字典中,键为氨基酸残基名,值为各个Ⅹ角组成的列表,列表中中间两个原子为转轴上的原子。丙氨酸、赖氨酸无Ⅹ角,故为空列表。
chi_angles_atoms = {
'ALA': [],
# Chi5 in arginine is always 0 +- 5 degrees, so ignore it.
'ARG': [['N', 'CA', 'CB', 'CG'], ['CA', 'CB', 'CG', 'CD'],
['CB', 'CG', 'CD', 'NE'], ['CG', 'CD', 'NE', 'CZ']],
'ASN': [['N', 'CA', 'CB', 'CG'], ['CA', 'CB', 'CG', 'OD1']],
'ASP': [['N', 'CA', 'CB', 'CG'], ['CA', 'CB', 'CG', 'OD1']],
'CYS': [['N', 'CA', 'CB', 'SG']],
'GLN': [['N', 'CA', 'CB', 'CG'], ['CA', 'CB', 'CG', 'CD'],
['CB', 'CG', 'CD', 'OE1']],
'GLU': [['N', 'CA', 'CB', 'CG'], ['CA', 'CB', 'CG', 'CD'],
['CB', 'CG', 'CD', 'OE1']],
'GLY': [],
'HIS': [['N', 'CA', 'CB', 'CG'], ['CA', 'CB', 'CG', 'ND1']],
'ILE': [['N', 'CA', 'CB', 'CG1'], ['CA', 'CB', 'CG1', 'CD1']],
'LEU': [['N', 'CA', 'CB', 'CG'], ['CA', 'CB', 'CG', 'CD1']],
'LYS': [['N', 'CA', 'CB', 'CG'], ['CA', 'CB', 'CG', 'CD'],
['CB', 'CG', 'CD', 'CE'], ['CG', 'CD', 'CE', 'NZ']],
'MET': [['N', 'CA', 'CB', 'CG'], ['CA', 'CB', 'CG', 'SD'],
['CB', 'CG', 'SD', 'CE']],
'PHE': [['N', 'CA', 'CB', 'CG'], ['CA', 'CB', 'CG', 'CD1']],
'PRO': [['N', 'CA', 'CB', 'CG'], ['CA', 'CB', 'CG', 'CD']],
'SER': [['N', 'CA', 'CB', 'OG']],
'THR': [['N', 'CA', 'CB', 'OG1']],
'TRP': [['N', 'CA', 'CB', 'CG'], ['CA', 'CB', 'CG', 'CD1']],
'TYR': [['N', 'CA', 'CB', 'CG'], ['CA', 'CB', 'CG', 'CD1']],
'VAL': [['N', 'CA', 'CB', 'CG1']],
}
我们发现,每种氨基酸含有Ⅹ角个数是不同的,最多有4个,在residue_constants模块中还定义了一个存储氨基酸Ⅹ角掩码数据的二维数组chi_angle_mask,某氨基酸含有哪些Ⅹ角,对应数组中对应位置为1,否则为0,对应位置依次表示Ⅹ1~4;每行数组对应一个氨基酸,与restype_order、restypes顺序一致。
chi_angles_mask = [
[0.0, 0.0, 0.0, 0.0], # ALA
[1.0, 1.0, 1.0, 1.0], # ARG
[1.0, 1.0, 0.0, 0.0], # ASN
[1.0, 1.0, 0.0, 0.0], # ASP
[1.0, 0.0, 0.0, 0.0], # CYS
[1.0, 1.0, 1.0, 0.0], # GLN
[1.0, 1.0, 1.0, 0.0], # GLU
[0.0, 0.0, 0.0, 0.0], # GLY
[1.0, 1.0, 0.0, 0.0], # HIS
[1.0, 1.0, 0.0, 0.0], # ILE
[1.0, 1.0, 0.0, 0.0], # LEU
[1.0, 1.0, 1.0, 1.0], # LYS
[1.0, 1.0, 1.0, 0.0], # MET
[1.0, 1.0, 0.0, 0.0], # PHE
[1.0, 1.0, 0.0, 0.0], # PRO
[1.0, 0.0, 0.0, 0.0], # SER
[1.0, 0.0, 0.0, 0.0], # THR
[1.0, 1.0, 0.0, 0.0], # TRP
[1.0, 1.0, 0.0, 0.0], # TYR
[1.0, 0.0, 0.0, 0.0], # VAL
]
各个氨基酸残基 χ \chi χ角中,有些角具有特殊性质,它们以 π \pi π为周期,即 χ \chi χ角旋转 π \pi π角度的整数倍,对结构没有影响。该特性储存在chi_pi_periodic二维数组中,在该数组中,若某氨基酸某 χ \chi χ角具有 π \pi π周期特性,则数组对应位置为1,否则为0。
chi_pi_periodic = [
[0.0, 0.0, 0.0, 0.0], # ALA
[0.0, 0.0, 0.0, 0.0], # ARG
[0.0, 0.0, 0.0, 0.0], # ASN
[0.0, 1.0, 0.0, 0.0], # ASP
[0.0, 0.0, 0.0, 0.0], # CYS
[0.0, 0.0, 0.0, 0.0], # GLN
[0.0, 0.0, 1.0, 0.0], # GLU
[0.0, 0.0, 0.0, 0.0], # GLY
[0.0, 0.0, 0.0, 0.0], # HIS
[0.0, 0.0, 0.0, 0.0], # ILE
[0.0, 0.0, 0.0, 0.0], # LEU
[0.0, 0.0, 0.0, 0.0], # LYS
[0.0, 0.0, 0.0, 0.0], # MET
[0.0, 1.0, 0.0, 0.0], # PHE
[0.0, 0.0, 0.0, 0.0], # PRO
[0.0, 0.0, 0.0, 0.0], # SER
[0.0, 0.0, 0.0, 0.0], # THR
[0.0, 0.0, 0.0, 0.0], # TRP
[0.0, 1.0, 0.0, 0.0], # TYR
[0.0, 0.0, 0.0, 0.0], # VAL
[0.0, 0.0, 0.0, 0.0], # UNK
]
氨基酸中各个刚性组原子的绝对位置,储存在rigid_group_atom_positions字典中,它以氨基酸为键,氨基酸中各个原子信息为值,值以[atomname,index,(x,y,z)]形式表示,index是根据原子属于哪一rigid group而定, b b 、 ω 、 φ 、 ψ 、 χ 1 、 χ 2 、 χ 3 , χ 4 bb、ω、φ、ψ、\chi_1、\chi_2、\chi_3,\chi_4 bb、ω、φ、ψ、χ1、χ2、χ3,χ4分别对应0,1,2,3,4,5,6,7。
对于坐标数据,它是把rigid group中的原子放在同一局部坐标系(或称为frame)中,x轴在旋转轴方向上,坐标系使得表示表示扭转角4原子中第1个原子在xy平面,第3个原子在原点,第2个原子在x轴负半轴。
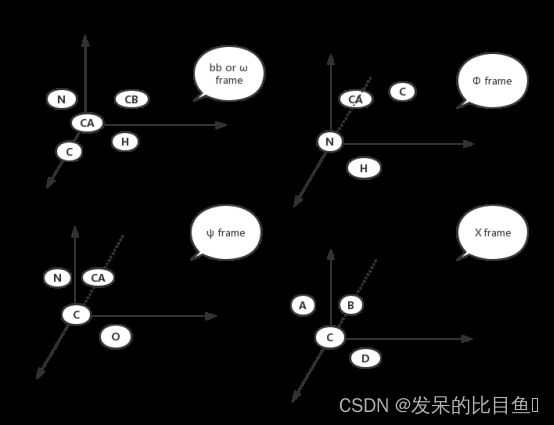
-
b b bb bb-group:氨基酸主链刚性组,含有N,CA,C,CB四个原子,该坐标系CA为坐标原点,C在x轴正向,N在xy平面,从而得到此坐标系下4个原子相应坐标。
-
ω ω ω-group:坐标系与 b b bb bb-group坐标系相同,得到与中心碳相连的H坐标( ψ \psi ψ-group只有与中心碳相连的H)。
-
ϕ \phi ϕ-group: ϕ \phi ϕ角=[C,CA,N,H]。N为坐标原点,CA在x轴负半轴,与CA连接的C在xy平面,从而确定H坐标(Φ-group只有氨基H)。
-
ψ \psi ψ-group: ψ \psi ψ角=[N,CA,C,O]。C为坐标原点,CA在x轴负半轴,与C连接的N在xy平面,从而确定O坐标( ψ \psi ψ-group只有羧基O)。
-
ϕ \phi ϕ-group:在
chi_angle_atoms相应氨基酸相应 χ \chi χ中, χ \chi χ角=[A,B,C,D],中间两个原子B,C为旋转轴,在x轴上;第3个原子C为坐标原点,原子B在x负半轴;第1个原子A在xy平面,从而确定该坐标下第4个原子坐标(第四个原子属于该 χ \chi χ-group)。
rigid_group_atom_positions = {
'ALA': [
['N', 0, (-0.525, 1.363, 0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.526, -0.000, -0.000)],
['CB', 0, (-0.529, -0.774, -1.205)],
['O', 3, (0.627, 1.062, 0.000)],
],
'ARG': [
['N', 0, (-0.524, 1.362, -0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.525, -0.000, -0.000)],
['CB', 0, (-0.524, -0.778, -1.209)],
['O', 3, (0.626, 1.062, 0.000)],
['CG', 4, (0.616, 1.390, -0.000)],
['CD', 5, (0.564, 1.414, 0.000)],
['NE', 6, (0.539, 1.357, -0.000)],
['NH1', 7, (0.206, 2.301, 0.000)],
['NH2', 7, (2.078, 0.978, -0.000)],
['CZ', 7, (0.758, 1.093, -0.000)],
],
'ASN': [
['N', 0, (-0.536, 1.357, 0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.526, -0.000, -0.000)],
['CB', 0, (-0.531, -0.787, -1.200)],
['O', 3, (0.625, 1.062, 0.000)],
['CG', 4, (0.584, 1.399, 0.000)],
['ND2', 5, (0.593, -1.188, 0.001)],
['OD1', 5, (0.633, 1.059, 0.000)],
],
'ASP': [
['N', 0, (-0.525, 1.362, -0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.527, 0.000, -0.000)],
['CB', 0, (-0.526, -0.778, -1.208)],
['O', 3, (0.626, 1.062, -0.000)],
['CG', 4, (0.593, 1.398, -0.000)],
['OD1', 5, (0.610, 1.091, 0.000)],
['OD2', 5, (0.592, -1.101, -0.003)],
],
'CYS': [
['N', 0, (-0.522, 1.362, -0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.524, 0.000, 0.000)],
['CB', 0, (-0.519, -0.773, -1.212)],
['O', 3, (0.625, 1.062, -0.000)],
['SG', 4, (0.728, 1.653, 0.000)],
],
'GLN': [
['N', 0, (-0.526, 1.361, -0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.526, 0.000, 0.000)],
['CB', 0, (-0.525, -0.779, -1.207)],
['O', 3, (0.626, 1.062, -0.000)],
['CG', 4, (0.615, 1.393, 0.000)],
['CD', 5, (0.587, 1.399, -0.000)],
['NE2', 6, (0.593, -1.189, -0.001)],
['OE1', 6, (0.634, 1.060, 0.000)],
],
'GLU': [
['N', 0, (-0.528, 1.361, 0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.526, -0.000, -0.000)],
['CB', 0, (-0.526, -0.781, -1.207)],
['O', 3, (0.626, 1.062, 0.000)],
['CG', 4, (0.615, 1.392, 0.000)],
['CD', 5, (0.600, 1.397, 0.000)],
['OE1', 6, (0.607, 1.095, -0.000)],
['OE2', 6, (0.589, -1.104, -0.001)],
],
'GLY': [
['N', 0, (-0.572, 1.337, 0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.517, -0.000, -0.000)],
['O', 3, (0.626, 1.062, -0.000)],
],
'HIS': [
['N', 0, (-0.527, 1.360, 0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.525, 0.000, 0.000)],
['CB', 0, (-0.525, -0.778, -1.208)],
['O', 3, (0.625, 1.063, 0.000)],
['CG', 4, (0.600, 1.370, -0.000)],
['CD2', 5, (0.889, -1.021, 0.003)],
['ND1', 5, (0.744, 1.160, -0.000)],
['CE1', 5, (2.030, 0.851, 0.002)],
['NE2', 5, (2.145, -0.466, 0.004)],
],
'ILE': [
['N', 0, (-0.493, 1.373, -0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.527, -0.000, -0.000)],
['CB', 0, (-0.536, -0.793, -1.213)],
['O', 3, (0.627, 1.062, -0.000)],
['CG1', 4, (0.534, 1.437, -0.000)],
['CG2', 4, (0.540, -0.785, -1.199)],
['CD1', 5, (0.619, 1.391, 0.000)],
],
'LEU': [
['N', 0, (-0.520, 1.363, 0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.525, -0.000, -0.000)],
['CB', 0, (-0.522, -0.773, -1.214)],
['O', 3, (0.625, 1.063, -0.000)],
['CG', 4, (0.678, 1.371, 0.000)],
['CD1', 5, (0.530, 1.430, -0.000)],
['CD2', 5, (0.535, -0.774, 1.200)],
],
'LYS': [
['N', 0, (-0.526, 1.362, -0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.526, 0.000, 0.000)],
['CB', 0, (-0.524, -0.778, -1.208)],
['O', 3, (0.626, 1.062, -0.000)],
['CG', 4, (0.619, 1.390, 0.000)],
['CD', 5, (0.559, 1.417, 0.000)],
['CE', 6, (0.560, 1.416, 0.000)],
['NZ', 7, (0.554, 1.387, 0.000)],
],
'MET': [
['N', 0, (-0.521, 1.364, -0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.525, 0.000, 0.000)],
['CB', 0, (-0.523, -0.776, -1.210)],
['O', 3, (0.625, 1.062, -0.000)],
['CG', 4, (0.613, 1.391, -0.000)],
['SD', 5, (0.703, 1.695, 0.000)],
['CE', 6, (0.320, 1.786, -0.000)],
],
'PHE': [
['N', 0, (-0.518, 1.363, 0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.524, 0.000, -0.000)],
['CB', 0, (-0.525, -0.776, -1.212)],
['O', 3, (0.626, 1.062, -0.000)],
['CG', 4, (0.607, 1.377, 0.000)],
['CD1', 5, (0.709, 1.195, -0.000)],
['CD2', 5, (0.706, -1.196, 0.000)],
['CE1', 5, (2.102, 1.198, -0.000)],
['CE2', 5, (2.098, -1.201, -0.000)],
['CZ', 5, (2.794, -0.003, -0.001)],
],
'PRO': [
['N', 0, (-0.566, 1.351, -0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.527, -0.000, 0.000)],
['CB', 0, (-0.546, -0.611, -1.293)],
['O', 3, (0.621, 1.066, 0.000)],
['CG', 4, (0.382, 1.445, 0.0)],
# ['CD', 5, (0.427, 1.440, 0.0)],
['CD', 5, (0.477, 1.424, 0.0)], # manually made angle 2 degrees larger
],
'SER': [
['N', 0, (-0.529, 1.360, -0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.525, -0.000, -0.000)],
['CB', 0, (-0.518, -0.777, -1.211)],
['O', 3, (0.626, 1.062, -0.000)],
['OG', 4, (0.503, 1.325, 0.000)],
],
'THR': [
['N', 0, (-0.517, 1.364, 0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.526, 0.000, -0.000)],
['CB', 0, (-0.516, -0.793, -1.215)],
['O', 3, (0.626, 1.062, 0.000)],
['CG2', 4, (0.550, -0.718, -1.228)],
['OG1', 4, (0.472, 1.353, 0.000)],
],
'TRP': [
['N', 0, (-0.521, 1.363, 0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.525, -0.000, 0.000)],
['CB', 0, (-0.523, -0.776, -1.212)],
['O', 3, (0.627, 1.062, 0.000)],
['CG', 4, (0.609, 1.370, -0.000)],
['CD1', 5, (0.824, 1.091, 0.000)],
['CD2', 5, (0.854, -1.148, -0.005)],
['CE2', 5, (2.186, -0.678, -0.007)],
['CE3', 5, (0.622, -2.530, -0.007)],
['NE1', 5, (2.140, 0.690, -0.004)],
['CH2', 5, (3.028, -2.890, -0.013)],
['CZ2', 5, (3.283, -1.543, -0.011)],
['CZ3', 5, (1.715, -3.389, -0.011)],
],
'TYR': [
['N', 0, (-0.522, 1.362, 0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.524, -0.000, -0.000)],
['CB', 0, (-0.522, -0.776, -1.213)],
['O', 3, (0.627, 1.062, -0.000)],
['CG', 4, (0.607, 1.382, -0.000)],
['CD1', 5, (0.716, 1.195, -0.000)],
['CD2', 5, (0.713, -1.194, -0.001)],
['CE1', 5, (2.107, 1.200, -0.002)],
['CE2', 5, (2.104, -1.201, -0.003)],
['OH', 5, (4.168, -0.002, -0.005)],
['CZ', 5, (2.791, -0.001, -0.003)],
],
'VAL': [
['N', 0, (-0.494, 1.373, -0.000)],
['CA', 0, (0.000, 0.000, 0.000)],
['C', 0, (1.527, -0.000, -0.000)],
['CB', 0, (-0.533, -0.795, -1.213)],
['O', 3, (0.627, 1.062, -0.000)],
['CG1', 4, (0.540, 1.429, -0.000)],
['CG2', 4, (0.533, -0.776, 1.203)],
],
}
其它参数
-
ca_ca=3.80209737096:肽链中相邻两个氨基酸α-碳之间距离。 -
van_der_waals_radius={‘C’:1.7,‘N’:1.55,‘0’:1.52,'S’1.8}:各个原子的范德华半径,单位为埃(angstrom,A)。 -
between_res_bond_length_c_n= [1.329, 1.341] :相邻两个氨基酸残基之间肽键中C-N键长,列表中前者表示一般氨基酸中键长,后者表示脯氨酸pro的情况。
between_res_bond_length_stddev_c_n = [0.014, 0.016]:上组数据中相应键长的标准差。
-
between_res_cos_angles_c_n_ca= [-0.5203, 0.0353]:相邻两个氨基酸C-N-αC的夹角余弦值,为-0.5203±0.0353,角度为121.352 ± 2.315。between_res_cos_angles_ca_c_n= [-0.4473, 0.0311]:氨基酸主链中αC-C-N的夹角余弦值,为-0.4473±0.0311,角度为116.568 ± 1.995。
函数解析
load_stereo_chemical_props
该函数用于解析stereo_chemical_props.txt文件中氨基酸键长、键角等信息,把它转换成可以在后续程序中使用的数据。兔兔发现,在AlphaFold源码文件中并没有stereo_chemical_props.txt文件,所以还要在下面这个网址中进行下载。https://git.scicore.unibas.ch/schwede/openstructure/-/raw/7102c63615b64735c4941278d92b554ec94415f8/modules/mol/alg/src/stereo_chemical_props.txt

stereo_chemical_props.txt文件主要包含三部分:第一部分是各个氨基酸Residue内各个键Bond的键长均值Mean与标准差StdDev;第二部分是各个氨基酸内各个键角Angle的均值与标准差;第三部分是非成键距离,这里没有用到。各个部分由’-'与空行分隔。该函数只用了文件中前两个部分。
函数最终返回三个值:residue_bonds、residue_virtual_bonds与residue_bond_angles。字典residue_bonds是以氨基酸残基为键,以该氨基酸内各个化学键信息为值的字典,字典的值是一个包含该氨基酸所有化学键的列表,列表中每个值包含了键两端的原子atom1,atom2,键长length与标准差stddev,所以这里的值可以创建一个具名元组来包含这四个信息,用collections.namedtuple函数实现。同理,residue_bond_angles、residue_virtual_bonds也是以氨基酸残基为键,值分别是包含所有键角、虚拟键的列表,前者列表中各个值包含atom1,atom2,atom3,angle,stddev5个信息,atom2表示顶角,angle表示角度,stddev仍是标准差;后者列表中各个值包含atom1,atom3,length,stddev,它是根据前面键长信息与键角信息,利用余弦定理计算键角对边的长度,也就是不成键的atom1与atom3的距离,所以称为virtual bond。
Bond=collections.namedtuple('Bond',['atom1','atom2','length','stddev']) #具名元组,化学键或虚拟键的信息
BondAngle=collections.namedtuple('BondAngle',['atom1','atom2','atom3','angle','stddev']) #键角信息
@functools.lru_cache(maxsize=None)
def load_stereo_chemical_props():
'''解析stereo_chemical_props.txt文件'''
with open('E:/Flappy Bird/alphafold/stereo_chemical_props.txt') as f:
stereo_chemical_props=f.readlines()
lines_lter=iter(stereo_chemical_props) #获取可迭代对象身上的迭代器
next(lines_lter) #跳过首行标题
residue_bonds={} #用以储存氨基酸化学键信息
for line in lines_lter: #逐行获取数据
if line.strip()=='-':
break # 只读取文件第一部分,遇到分界先停止读取
bond,resname,length,stddev=line.split() #拆分字符,分别为化学键、氨基酸残基名,键长与标准差
atom1,atom2=bond.split('-') #把化学键拆成两端的原子
if resname not in residue_bonds:
residue_bonds[resname]=[] #创建储存氨基酸各个化学键信息的列表
residue_bonds[resname].append(Bond(atom1,atom2,float(length),float(stddev))) #把化学键信息添加到列表中
residue_bonds['UNK']=[] #表示未知氨基酸的各个化学键信息,值为空列表
next(lines_lter) #跳过空行
next(lines_lter) #跳过第二部分的首行标题
residue_bond_angles={} #用以储存氨基酸键角信息
for line in lines_lter:
if line.strip()=='-':
break #只读取文件第二部分,遇到分界停止读取
bond,resname,angle,stddev=line.split() #拆分字符,分布为两个相邻的化学键,氨基酸残基名,键角与标准差
atom1,atom2,atom3=bond.split('-') #把两个相邻的化学键拆分成三个原子
if resname not in residue_bond_angles:
residue_bond_angles[resname]=[] #创建储存氨基酸各个键角信息的列表
residue_bond_angles[resname].append(BondAngle(atom1,atom2,atom3,float(angle)*np.pi/180,
float(stddev)*np.pi/180))#把键角信息添加列表中,角度转成弧度制
residue_bond_angles['UNK']=[] #表示未知氨基酸的各个键角信息,为空列表
def make_bond_key(atom1_name,atom2_name):
'''利用两个原子创建一个化学键表示,并且固定了两个原子的前后顺序
return:"atom1_name-atom2_name"'''
return '-'.join(sorted([atom1_name,atom2_name]))
residue_virtual_bonds={} #用以储存氨基酸虚拟键信息
for resname,bond_angles in residue_bond_angles.items(): #逐个氨基酸获取所有键角信息
bond_cache={} #创建键为化学键、值为该化学键信息的字典
for b in residue_bonds[resname]: #逐个获取该氨基酸内各个键角信息
bond_cache[make_bond_key(b.atom1,b.atom2)]=b #往字典中添加键值
residue_virtual_bonds[resname]=[] #创建储存氨基酸各个虚拟键的信息
for ba in residue_bond_angles [resname]: #逐个获取该氨基酸的键角信息
bond1=bond_cache[make_bond_key(ba.atom1,ba.atom2)] #获取该键角ba中一个化学键
bond2=bond_cache[make_bond_key(ba.atom2,ba.atom3)] #获取该键角ba中另一个化学键
gamma=ba.angle #键角角度
length=np.sqrt(bond1.length**2+bond2.length**2-2*bond1.length*bond2.length*np.cos(gamma)) #余弦定理计算虚拟键长
dl_outer = 0.5 / length
dl_dgamma = (2 * bond1.length * bond2.length * np.sin(gamma)) * dl_outer
dl_db1 = (2 * bond1.length - 2 * bond2.length * np.cos(gamma)) * dl_outer
dl_db2 = (2 * bond2.length - 2 * bond1.length * np.cos(gamma)) * dl_outer
stddev = np.sqrt((dl_dgamma * ba.stddev) ** 2 +
(dl_db1 * bond1.stddev) ** 2 +
(dl_db2 * bond2.stddev) ** 2) #误差传递计算
residue_virtual_bonds[resname].append(Bond(ba.atom1,ba.atom3,length,stddev)) #把虚拟键信息添加列表中
return (residue_bonds ,
residue_virtual_bonds,
residue_bond_angles)
函数先读取txt文件,并分别利用文件前两部分创建了residue_bonds,residue_bond_angles这两个字典来储存各个氨基酸内各个键长或键角信息。这里文件解析时可以用readlines()直接获取,原代码是先采用read(),后用splitlines()拆分实现的,但效果是一样的。使用迭代器可以逐行解析,遇到分界时可以跳过空行、首行标题等。
在之后的residue_virtual_bonds,需要利用residue_bonds中键长信息与residue_bond_angles键角信息,为了后面计算虚拟键过程中准确获取键长,这里创建了bond_cache字典,字典的键是两个原子连接的字符串,该键是通过make_bond_key函数创建的,并且固定了两个原子的前后位置,这样也便于后面通过键对值的准确获取。
我们最终也可以查看一下结果:
residue_bonds,residue_virtual_bonds,residue_bond_angles=load_stereo_chemical_props()
print(residue_bonds)
print(residue_virtual_bonds)
print(residue_bond_angles)
seqence_to_onehot
该函数是用于将氨基酸序列转成二维数组(称为one-hot编码矩阵),便于后面的数据处理与应用。onehot 表示独热,它是指对一些数据的独热表示或独热编码,在自然语言处理等方面十分常见。在这里,是把所有氨基酸按一定顺序排列。之后对于某一氨基酸,它就可以表示成对应氨基酸位置的数值为1,其余为0的向量。例如,只考虑[‘A’,‘R’,‘N’,‘D’,‘C’]五种氨基酸,按照该顺序(或称为映射),'A’表示为[1,0,0,0,0],'D’表示为[0,0,0,1,0]。序列’ARN’可表示为:[[1,0,0,0,0],[0,1,0,0,0],[0,0,1,0,0]]。
def seqence_to_one_hot(seqence,mapping):
'''seqence:氨基酸序列,为字符串str
mapping:用于把氨基酸映射成0~(氨基酸种类数-1)之间整数的字典
return:one-hot 编码矩阵'''
num_entries=len(mapping) #字典mapping元素个数,即氨基酸种类数
one_hot_arr=np.zeros(shape=(len(seqence),num_entries),dtype=np.int32)
for aa_index,aa_type in enumerate(seqence):
aa_id=mapping[aa_type] #把该氨基酸映射成对应的数
one_hot_arr[aa_index,aa_id]=1 #独热表示,对应位置索引改为1
return one_hot_arr
在原代码中,该函数还有一个map_unknown_to_x这个参数,决定是否把考虑含有未知的氨基酸的情况,默认为False,如果为True,就把未知氨基酸表示成’X’,也作为独热编码一部分。并且原代码有很大一部分用于判断mapping是否合理,它要求mapping中值必须是0~(氨基酸数-1)之间的整数,否则报错。这两个部分对于该函数功能的正常实现其实没有太大影响,故兔兔略去此部分。
函数中的mapping是一个键为氨基酸残基单字符、值为整数的字典,所以前面的restype_order便可以作为这里的mapping。
one_hot=seqence_to_one_hot(seqence='ARAYNDC',mapping=restype_order)
print(one_hot)
通过上面的代码,可以测试该函数。得到’ARAYNDC’的one-hot编码为:
[[1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0]
[0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
_make_standard_atom_mask
该函数用于创建原子掩码。该函数根据各个氨基酸内原子种类来创建一个二维数组,其中每一个一维数组表示某个氨基酸内含有原子种类的情况。这里仍是先把所有原子按一定顺序排列,之后对于某一氨基酸,含有哪些原子,则数组中对应位置元素为1,否则为0。例如,若所有原子为[C,CA,CB,O,CG,CD,N],某氨基酸只含有[C,CA,N,O],则它的掩码表示为[1,1,0,1,0,0,1]。
def _make_standard_atom_mask():
mask=np.zeros(shape=(restype_num+1,atom_type_num)) #restype_num+1是考虑未知种类氨基酸的情况
for restype,restype_letter in enumerate(restypes): #逐个获取restypes中氨基酸种类restype_letter与对应位置索引restype
restype_name=restype_1to3[restype_letter] #把氨基酸单字符restype_letter转换成三字符restype_name表示
atom_names=residue_atoms[restype_name] #利用residue_atoms获取氨基酸restype_name内的所有原子
for atom_name in atom_names: #逐个获取restype_name内的原子
atom_type=atom_order[atom_name] #获取该原子的索引
mask[restype,atom_type]=1 #如果存在该原子,对应位置为1
return mask
STANDARD_ATOM_MASK=_make_standard_atom_mask()
_make_rigid_transformation_4×4
该函数用于创建变换矩阵,用以分子平移、旋转操作,即欧几里得变换,详细内容可参考《欧几里得变换详解》中的平移变换与旋转变换。在AlphaFold中,该函数创建变换矩阵的目的是将分子在局部坐标系(local frame)的局部坐标(local coordinates)转换成全局参考坐标系(global reference frame)下的全局坐标(global coordinates)。这个过程相当于将局部坐标系旋转平移使之与全局坐标系相同,此时分子的局部坐标也随坐标系平移旋转相应变换,最终得到全局坐标。这个过程也就是坐标变换。
_make_rigid_transformation_4×4有ex、ey、translation三个参数,ex表示局部坐标系x轴在全局坐标系下的方向向量(它可以不是单位向量,因为在该函数中有规范化处理);ey表示局部坐标系xy平面某向量在全局坐标系下的向量;ez不在函数参数中,它是ex、ey规范正交化后的外积。translation表示局部坐标系原点在全局坐标系下的坐标(向量)。
def _make_rigid_transformation_4x4(ex, ey, translation):
'''欧几里得变换矩阵,把局部坐标系下的坐标变换成全局坐标系下的全局坐标'''
ex_normalized = ex / np.linalg.norm(ex) #方向向量x规范化
ey_normalized = ey - np.dot(ey, ex_normalized) * ex_normalized #正交化
ey_normalized =ey_normalized/np.linalg.norm(ey_normalized) #规范化
eznorm = np.cross(ex_normalized, ey_normalized) #ez为ex、ey规范正交化后的外积
m = np.stack([ex_normalized, ey_normalized, eznorm, translation]).transpose() #旋转矩阵与平移矩阵组合
m = np.concatenate([m, [[0., 0., 0., 1.]]], axis=0) #补上变换矩阵的最后一行,形成变换矩阵
return m
以ex=[0,1,0],ey=[-1,0,0],translation=[1,0,0]为例,它表示局部坐标系在全局坐标系[1,0,0]位置,相对于全局坐标系沿z轴逆时针旋转90°。
m=_make_rigid_transformation_4x4(ex=[0,1,0],ey=[-1,0,0],translation=[1,0,0])
print(m)
最终得到的变换矩阵与实际意义相符。之后用该变换矩阵左乘分子在局部坐标系下的齐次坐标,即可得到该分子的全局坐标系下的齐次坐标。
make_rigid_group_constants
该函数用于获得一些刚性群常数,最终得到7个相关的数据。
-
restype_atom37_to_rigid_group:21×37维张量,张量中的值:0~8,表示某氨基酸残基某原子属于哪一rigid group,与rigid_group_atom_positions中rigid group意义一致。 -
restype_atom37_mask:21个氨基酸残基(20个氨基酸与1个未知氨基酸)37原子掩码,为21×37张量,每行表示相应氨基酸,每行中每个元素为1表示该氨基酸含有该原子,反之为0,表示不含该原子。 -
restype_atom37_rigid_group_positions:21×37×3维张量,表示各个氨基酸各个原子的三维坐标,如果坐标为[0,0,0],则该氨基酸不存在该原子。 -
restype_atom14_to_rigid_group:21×14维张量,相应的值(0~8)表示某氨基酸残基某原子属于哪一rigid group,与rigid_group_atom_positions中rigid group意义一致。 -
restype_atom14_mask:21个氨基酸14原子原子掩码,为21×14张量,每行表示相应氨基酸,每行中元素为1表示该氨基酸有该原子,反之为0,表示不含该原子。 -
restype_atom14_rigid_group_positions:21×14×3维张量,表示各个氨基酸各个原子在相应rigid group坐标系下的三维坐标(rigid_group_atom_positions中的坐标),如果坐标为[0,0,0],则该氨基酸不存在该原子或在原点。 -
restype_rigid_group_default_frame:21×8×4×4维张量,表示各个氨基酸各个rigid group的仿射变换矩阵,即各个rigid group坐标系到前一个rigid group坐标系的坐标变换矩阵。对于bb-group、ω-group到bb-group,坐标系相同,为恒等变换; ϕ \phi ϕ、 ψ \psi ψ、 χ 1 \chi_1 χ1到 b b bb bb变换, χ 2 \chi_2 χ2到 χ 2 \chi_2 χ2、 χ 3 \chi_3 χ3到 χ 2 \chi_2 χ2、 χ 4 \chi_4 χ4到 χ 3 \chi_3 χ3,需要使用_make_rigid_transformation_4x4函数,ey为该坐标系x轴在上一坐标系的方向向量,ey与ex确定的平面使扭转角第一个原子落在该平面。
restype_atom37_to_rigid_group = np.zeros([21, 37], dtype=int)
restype_atom37_mask = np.zeros([21, 37], dtype=np.float32)
restype_atom37_rigid_group_positions = np.zeros([21, 37, 3], dtype=np.float32)
restype_atom14_to_rigid_group = np.zeros([21, 14], dtype=int)
restype_atom14_mask = np.zeros([21, 14], dtype=np.float32)
restype_atom14_rigid_group_positions = np.zeros([21, 14, 3], dtype=np.float32)
restype_rigid_group_default_frame = np.zeros([21, 8, 4, 4], dtype=np.float32)
def _make_rigid_group_constants():
for restype, restype_letter in enumerate(restypes):#restype:各氨基酸索引,restype_letter:氨基酸单字符
resname = restype_1to3[restype_letter] #把单字符转3字符
for atomname, group_idx, atom_position in rigid_group_atom_positions[
resname]: #获得resname氨基酸的原子、rigid-group类别序号、原子坐标
atomtype = atom_order[atomname] #获得氨基酸resname,原子atomname在atom_types中索引
restype_atom37_to_rigid_group[restype, atomtype] = group_idx #氨基酸resname,原子atomname属于rigid group的类别序号
restype_atom37_mask[restype, atomtype] = 1 #若氨基酸resname存在该原子,值为1,创建掩码
restype_atom37_rigid_group_positions[restype, atomtype, :] = atom_position #氨基酸resname原子atomname的坐标
atom14idx = restype_name_to_atom14_names[resname].index(atomname) #获得氨基酸resname,原子atomname在restype_name_to_atom14_names中索引
restype_atom14_to_rigid_group[restype, atom14idx] = group_idx #氨基酸resname,原子atomname属于rigid group的类别序号
restype_atom14_mask[restype, atom14idx] = 1 #若氨基酸resname存在该原子,值为1,创建掩码
restype_atom14_rigid_group_positions[restype,
atom14idx, :] = atom_position #氨基酸resname,原子atomname的坐标
for restype, restype_letter in enumerate(restypes):
resname = restype_1to3[restype_letter]
atom_positions = {name: np.array(pos) for name, _, pos
in rigid_group_atom_positions[resname]} #name:氨基酸resname中各原子名;pos:相应坐标系下原子坐标
# bb-group到bb-group,坐标系相同,为恒等变换
restype_rigid_group_default_frame[restype, 0, :, :] = np.eye(4)
# ω-group到bb-group,坐标系相同,为恒等变换
restype_rigid_group_default_frame[restype, 1, :, :] = np.eye(4)
# Φ 到bb变换
mat = _make_rigid_transformation_4x4(
ex=atom_positions['N'] - atom_positions['CA'], #N-CA在Φ-group坐标系x轴,为bb-group坐标系的ex
ey=np.array([1., 0., 0.]), #使第一个原子C在局部坐标系xy平面
translation=atom_positions['N']) #N为Φ-group坐标系原点
restype_rigid_group_default_frame[restype, 2, :, :] = mat
# ψ到bb变换
mat = _make_rigid_transformation_4x4(
ex=atom_positions['C'] - atom_positions['CA'], #C-CA在ψ-group坐标系x轴,为bb-group坐标系的ex向量
ey=atom_positions['CA'] - atom_positions['N'], #CA-N在ψ-group坐标系xy平面,为bb-group坐标系ey向量
translation=atom_positions['C']) #C为ψ-group坐标系原点
restype_rigid_group_default_frame[restype, 3, :, :] = mat
# Ⅹ1到bb变换
if chi_angles_mask[restype][0]: #判断氨基酸resname是否有Ⅹ1-group,1为True,表示有Ⅹ1-group
base_atom_names = chi_angles_atoms[resname][0] #氨基酸resname,Ⅹ1
base_atom_positions = [atom_positions[name] for name in base_atom_names] #Ⅹ1中4个原子局部坐标
mat = _make_rigid_transformation_4x4(
ex=base_atom_positions[2] - base_atom_positions[1], #CA-CB在Ⅹ1-group坐标系x轴,ex=CB-CA
ey=base_atom_positions[0] - base_atom_positions[1], #N-CA在Ⅹ1-group坐标系xy平面,为ey
translation=base_atom_positions[2]) #CB为Ⅹ1-group坐标系原点
restype_rigid_group_default_frame[restype, 4, :, :] = mat
# Ⅹ2到Ⅹ1
# Ⅹ3到Ⅹ2
# Ⅹ4到Ⅹ3
# 每个坐标系的旋转轴都是从上一坐标系原点开始,所有ex为该坐标系第3个原子在上个坐标系的坐标
for chi_idx in range(1, 4): #依次计算Ⅹ2到Ⅹ1、Ⅹ3到Ⅹ2、Ⅹ4到Ⅹ3的变换矩阵
if chi_angles_mask[restype][chi_idx]: #判断是否存在Ⅹchi_inx,有则进行计算
axis_end_atom_name = chi_angles_atoms[resname][chi_idx][2] #氨基酸resname,Ⅹchi_idx角第3个原子名
axis_end_atom_position = atom_positions[axis_end_atom_name] #该原子的局部坐标
mat = _make_rigid_transformation_4x4(
ex=axis_end_atom_position,
ey=np.array([-1., 0., 0.]),
translation=axis_end_atom_position) #氨基酸resname,Ⅹchi_idx角第3个原子为局部坐标系原点
restype_rigid_group_default_frame[restype, 4 + chi_idx, :, :] = mat
_make_rigid_group_constants()
make_atom14_dists_bounds
在知道氨基酸所有键长、键角、扭转角等信息后,我们也需要考虑在分子内部原子的大小。因为在后面预测蛋白质结构时,我们同样需要考虑原子是否会有重叠的情况。我们通常认为原子是有一定半径的球体,一旦两个原子之间的距离小于两原子半径之和,则两个原子有重叠(overlap),通常原子重叠部分不能太多,否则与事实不符。make_atom14_dist_bounds中参数overlap_tolerance参数表示允许两个原子最大重叠长度,默认为1.5(单位A);参数bound_length_tolerance_factor为键长容许偏差系数(类似于置信度),它表示键长允许范围,为[bond length- tolerance factor×stddev,bond_length+tolerance factor×stddev],tolerance factor默认为15。一旦键长短至使原子重叠超过该长度或键长在置信区间之外,则认为结构违例(structual violations)。
该函数最终得到一个包含lower_bound,upper_bound与stddev的字典,值都为21×14×14的张量,21表示氨基酸种类,14×14为对称矩阵,atom1行atom2列表示两个原子键长上下限、标准差。
def make_atom14_dists_bounds(overlap_tolerance=1.5,
bond_length_tolerance_factor=15):
"""计算键长上下界以评估 structual violations."""
restype_atom14_bond_lower_bound = np.zeros([21, 14, 14], np.float32)
restype_atom14_bond_upper_bound = np.zeros([21, 14, 14], np.float32)
restype_atom14_bond_stddev = np.zeros([21, 14, 14], np.float32)
residue_bonds, residue_virtual_bonds, _ = load_stereo_chemical_props() #获取键长、虚拟键长
for restype, restype_letter in enumerate(restypes):
resname = restype_1to3[restype_letter] #氨基酸单字符restype_letter转3字符resname
atom_list = restype_name_to_atom14_names[resname] #从restype_name_to_atom14_names获取氨基酸resname的14原子表示列表
# create lower and upper bounds for clashes
for atom1_idx, atom1_name in enumerate(atom_list): #atom1_idx:原子列表中位置索引;atom1_name:原子名
if not atom1_name: #判断atom2_name是否为空
continue
atom1_radius = van_der_waals_radius[atom1_name[0]] #获取atom1_name原子半径
for atom2_idx, atom2_name in enumerate(atom_list): #atom2_idx:原子列表位置索引;atom2_name:原子名
if (not atom2_name) or atom1_idx == atom2_idx: #判断atom2_name是否为空以及atom1_name,atom2_name是否为氨基酸中同一原子
continue
atom2_radius = van_der_waals_radius[atom2_name[0]] #获取atom2_name原子半径
lower = atom1_radius + atom2_radius - overlap_tolerance #atom1_name与atom2_name两原子之间允许的最短距离(键长)
upper = 1e10 #两原子之间键长上界,先使其足够大
restype_atom14_bond_lower_bound[restype, atom1_idx, atom2_idx] = lower #氨基酸resname内原子之间键长下限
restype_atom14_bond_lower_bound[restype, atom2_idx, atom1_idx] = lower #补充距离矩阵另半部分,为对称矩阵
restype_atom14_bond_upper_bound[restype, atom1_idx, atom2_idx] = upper #氨基酸resname内原子之间键长上限
restype_atom14_bond_upper_bound[restype, atom2_idx, atom1_idx] = upper #补充距离矩阵另半部分,为对称矩阵
# overwrite lower and upper bounds for bonds and angles
for b in residue_bonds[resname] + residue_virtual_bonds[resname]: #获取氨基酸resname所有键长与虚拟键长
atom1_idx = atom_list.index(b.atom1) #atom1在atom_list位置索引
atom2_idx = atom_list.index(b.atom2) #atom2在atom_list位置索引
lower = b.length - bond_length_tolerance_factor * b.stddev #计算各个键长下界
upper = b.length + bond_length_tolerance_factor * b.stddev #计算各个键长上界
restype_atom14_bond_lower_bound[restype, atom1_idx, atom2_idx] = lower #氨基酸resname内原子之间键长下界
restype_atom14_bond_lower_bound[restype, atom2_idx, atom1_idx] = lower #补充距离矩阵另半部分,为对称矩阵
restype_atom14_bond_upper_bound[restype, atom1_idx, atom2_idx] = upper #氨基酸resname内各原子之间键长上界
restype_atom14_bond_upper_bound[restype, atom2_idx, atom1_idx] = upper #补充距离矩阵另半部分,为对称矩阵
restype_atom14_bond_stddev[restype, atom1_idx, atom2_idx] = b.stddev #氨基酸resname内原子之间键长标准差
restype_atom14_bond_stddev[restype, atom2_idx, atom1_idx] = b.stddev #补充标准差矩阵另半部分,为对称矩阵
return {'lower_bound': restype_atom14_bond_lower_bound, # shape (21,14,14)
'upper_bound': restype_atom14_bond_upper_bound, # shape (21,14,14)
'stddev': restype_atom14_bond_stddev, # shape (21,14,14)
}
a=make_atom14_dists_bounds()
chi_angles_atom_indices与chi_groups_for_atom
前面的几个函数,通常是直接处理并得到数据;或是属于工具函数,在其它模块或函数中使用;或直接对函数外的数据进行处理。对于这两个数据,该模块并没有将其放在函数中计算,而是直接进行处理。
chi_angles_atom_indices:20×4×4张量,表示各个氨基酸各个 χ \chi χ角。20为氨基酸数,4表示 χ 1 χ 4 \chi_1 ~ \chi_4 χ1 χ4,4表示每个 χ \chi χ角4个原子,原子用atom_order中相应的数表示。实质上是chi_angles_atom数据的另一种表示方法。
# An array like chi_angles_atoms but using indices rather than names.
chi_angles_atom_indices = [chi_angles_atoms[restype_1to3[r]] for r in restypes] #各个氨基酸各Ⅹ角,为三层列表嵌套
chi_angles_atom_indices = tree.map_structure(
lambda atom_name: atom_order[atom_name], chi_angles_atom_indices) #将上面嵌套列表中的原子映射成atom_order相应的数,
chi_angles_atom_indices = np.array([
chi_atoms + ([[0, 0, 0, 0]] * (4 - len(chi_atoms))) #若某氨基酸Ⅹ角不足4个,用若干个[0,0,0,0]补足4个
for chi_atoms in chi_angles_atom_indices])
chi_groups_for_atom:它是一个以(氨基酸名,原子名)元组为键,该氨基酸该原子所有:(Ⅹ位置索引,Ⅹ列表中原子索引)这样的元组组成的列表为值组成的字典。
# Mapping from (res_name, atom_name) pairs to the atom's chi group index
# and atom index within that group.
chi_groups_for_atom = collections.defaultdict(list) #创建类似字典的对象
for res_name, chi_angle_atoms_for_res in chi_angles_atoms.items(): #res_name:氨基酸;chi_angle_atoms_for_res:氨基酸各Ⅹ角
for chi_group_i, chi_group in enumerate(chi_angle_atoms_for_res): #chi_group_i:各Ⅹ角位置索引;chi_group:含4各原子的Ⅹ角列表
for atom_i, atom in enumerate(chi_group): #atom_i:原子位置索引;atom:原子名
chi_groups_for_atom[(res_name, atom)].append((chi_group_i, atom_i)) #以(res_name,atom)为键,(chi_group_i,atom_i)为值的字典
chi_groups_for_atom = dict(chi_groups_for_atom) #转成字典
总结
residue constants 作为AlphaFold中最为基础的模块,包含了关于蛋白质氨基酸各种结构信息、表示方法以及之后需要用到的函数,在后面计算蛋白质所有原子坐标,构造损失函数等方面会经常使用。
补充:
-
residue contants原代码中需要用到numpy(np)、collections、functools、tree、typing模块。其中typing在本文并未提及,它主要用来输入输出数据形式、数据类型的提示,但是从整体考虑是需要用到的。 -
第1个函数前
@functools.lru_cache是装饰器,可缓存maxsize个此函数的调用结果,提高程序执行效率,maxsize=None表示缓存次数无限制。