YOLO界再起波澜!mAP 51.4,149FPS,目标检测,一个就够了
机器之心发布
作者:百度飞桨团队
百度飞桨团队发布了 PP-YOLOE,与其他 YOLO 系列算法相比,其具有更强的性能、更丰富灵活的配置方案以及更全硬件支持三大优势。
此前,机器之心报道过的 PaddleDetection 项目再次升级,发布了全新进化版 YOLO 模型——PP-YOLOE,并再次以极佳的性能表现刷新业界性能榜单指标,在目标检测领域引起了广泛关注。

论文地址:https://arxiv.org/abs/2203.16250
项目地址:https://github.com/PaddlePaddle/PaddleDetection
相较于其他 YOLO 系列算法,PP-YOLOE 主要有以下三大优势:
更强性能:PP-YOLOE 的 s/m/l/x 全系列四个尺寸在精度及速度方面均超越其他同体量算法。详细数据如图 1 所示,其中 PP-YOLOE-l 在 COCO test-dev 上精度可达 51.4%,在 V100 上使用 TRT FP16 进行推理,速度可达 149FPS,相较于YOLOX-l[4]精度提升 1.3 AP,速度提升 24.96%;相较于YOLOv5-x[5]精度提升 0.7AP,TRT-FP16 加速 26.8%;相较于PP-YOLOv2[6]精度提升 1.9 AP,速度提升 13.35%。
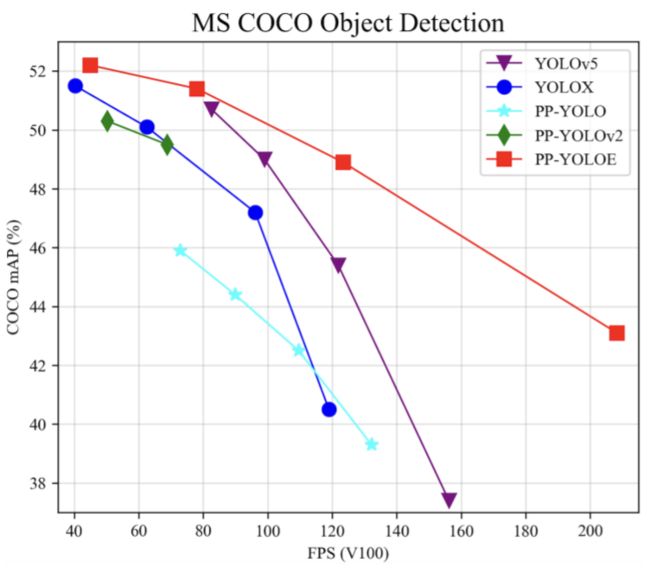
图 1 PP-YOLOE 各尺寸模型性能与其他模型对比示意图
更丰富灵活的配置方案:PP-YOLOE 不仅提供 4 种固定尺寸,且支持开发者灵活地定制化配置更多尺寸;顺畅支持包括模型量化、剪枝和蒸馏在内丰富的模型优化策略,满足实际产业场景中速度和精度的极致追求;全面高质量支持包括 TensorRT 和 OpenVINO 在内的加速库,还提供一键转出 ONNX 格式,可顺畅对接 ONNX 生态。
更全硬件支持:PP-YOLOE 在结构设计上避免使用 DCN、Matrix NMS 等不易部署的算子,使其可以方便地部署到不同的硬件当中。当前已经完备支持 NVIDIA V100、T4 这样的云端 GPU 架构以及如 Jetson 系列等边缘端 GPU 设备。
PP-YOLOE 关键技术改进点深入解读
PP-YOLOE 相较前几代 YOLO 算法的性能提升主要源于以下三点改进:
1. 新颖、统一的 Backbone 和 Neck 设计,更方便灵活配置多种尺寸。
2. 引入了更高效的标签分配策略 TAL(Task Alignment Learning)的动态匹配策略,解决了目标检测任务中常见的分类回归不均衡难题,提高检测精度。
3. 设计了更简洁的 ET-Head(Efficient Task-aligned Head),以少量的速度损失为代价提升了精度。
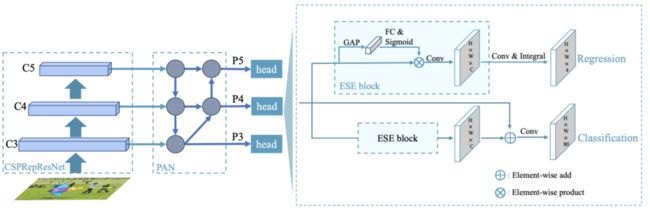
图 2 PP-YOLOE 模型结构示意图
下面展开详细介绍。
可扩展的 Backbone 和 Neck
以 ResNet 为代表的残差连接网络和以 DenseNet 为代表的密集连接网络在现代卷积神经网络中被广泛应用。主要是因为残差连接可以作为一种模型集成的方法,解决了梯度消失问题;密集连接融合则具有不同感受野的中间层特征,在目标检测等任务上表现出了良好的性能。综合以上两种结构的特点,飞桨团队设计了 RepResBlock 结构,并用于 PP-YOLOE 的 Backbone 和 Neck 中。
重新设计 Backbone 和 Neck 的初衷之一是在利用密集连接中的特征复用和多感受野融合等优势的同时,避免巨大的内存访问成本 (Memory Access Cost,MAC) 所导致的速度下降等劣势。为此主要通过以下三步核心设计实现:
为了减少内存访问带来的开销,首先借鉴了TreeNet[1]中的 TreeBlock 并将其简化成如上图中的 (a) 所示的形式,在最小化 block 的同时保留了特征复用和多感受野融合的特点。
由于直接堆叠简化版的 TreeBlock 仍然会带来巨大的内存访问成本,因此需要对 TreeBlock 中各卷积分支解耦,将 concat 操作替换成 elementwise_add 操作,得到 RepResBlock 来实现重参数化,进一步优化网络结构。训练时网络结构如上图 (b) 所示,在部署时则可以被重参数化为如上图 (c) 所示的形式。这样在训练时既可增强模型的表征能力,在部署时也不会引入额外的计算量。
堆叠的 RepResBlock 与 CSP 结构结合组成了 CSPRepResStage。CSP 结构去除了冗余的 3x3 卷积,从而避免了巨大的参数量和计算量,使得模型在推理时更加高效。同时,ESE(Effective Squeeze and Extraction)也被引入 CSPRepResStage 以施加通道注意力,进一步提升特征表示能力。

图 3 RepResBlock 和 CSPRepResStage 结构示意图
重新设计 Backbone 和 Neck 的初衷之二是为了更方便地缩放模型尺寸,以适配不同算力的硬件。因此,需要统一 Backbone 和 neck 中的模块:
使用 CSPRepResStage 搭建 Backbone。与 ResNet 类似,PP-YOLOE 使用 3 个堆叠的卷积组成的 stem 结构以及 4 个 CSPRepResStage。
在 Neck 方面沿用了 PAN 的结构,由 5 个 CSPRepResStage 组成,与 Backbone 不同的是,Neck 中移除了 ESE 以及 RepResBlock 中的残差连接。
最终经过重新设计的 Backbone 和 Neck 相较于 PP-YOLOv2 中的结构精度提升 0.7AP, 速度也大幅提升。
更高效的标签分配策略 TAL (Task Alignment Learning)
标签分配是指在目标检测训练的过程中,将 ground truth 分配给 anchor box 或者 anchor point 以得到正例和负例进行监督学习。目标检测中的标签分配策略通常可以分为静态匹配和动态匹配两种:
静态匹配是指不依赖网络的输出,根据 ground truth 和 anchor 的 IoU 或者位置关系进行匹配,如 ATSS、YOLOv3 中的匹配策略等。
动态匹配是根据网络的输出来分配正例,如 SimOTA、TAL 等。TAL 设计了综合分类任务和回归任务的指标对 ground truth 进行分配,并依据这一指标来计算 loss 以及调整 loss 的权重,使得分类和回归任务的学习产生交互,达到了对齐分类和回归任务的效果。
由于目标检测任务包含分类和回归两个子任务,但这两个子任务的学习往往不存在交互,因此会导致分类和回归任务在预测上存在不一致的问题。具体表现为一些定位准确、分类置信度不高的预测框,被定位不准确、分类置信度高的预测框抑制。
在之前版本的PP-YOLOv1/v2[6][7]中是使用 IoU Aware 的方式,依据 IoU 和分类预测分数的综合指标作为 NMS 的置信度来缓解这一问题。但分类任务和回归任务的学习依然是相互独立的,为了更好地解决不一致问题,PP-YOLOE 中引入了 TOOD 中的 TAL(Task Alignment Learning)这一标签分配策略来对齐分类和回归任务。
飞桨团队在基线模型上分别对 ATSS、SimOTA 和 TAL 进行了实验探索,可以看到 TAL 得到了最优的精度表现。在引入了 TAL 之后,模型也得到了 0.9AP 的大幅提升。
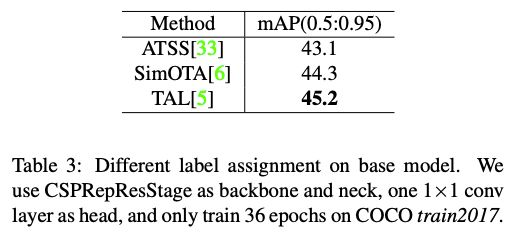
表 1 不同标签分配策略在 base 模型上的效果
更简洁有效的 ET-Head (Efficient Task-aligned Head)
由于分类和回归任务需要的特征往往不完全相同,为了同时得到任务通用和任务特有的特征,PP-YOLOE 中引入了TOOD[2]中提出的针对分类任务和回归任务对齐的 T-Head (Task-aligned Head),并对其进行了改进。

图 4 ET-Head 结构示意图
ET-Head 具体结构如上图所示,相较于原始的 T-Head 在网络结构上主要进行了以下四点改进:
移除了 T-Head 中耗时的任务交互特征模块;
在精度无损的条件下,将通道注意力模块简化成了更加高效的 ESE block;
将分类任务对齐模块简化成了 shortcut,进一步提升了速度;
针对 T-Head 中复杂且对部署不友好的回归任务对齐模块,通过借鉴 GFL[3]中的积分模块来建模检测框。
为了进一步提升模型性能,在损失函数方面,则主要进行了以下两点改进:
采用 VFL(varifocal loss)作为分类 loss,VFL 使用 IACS(IoU-aware classification score)作为 target,使得模型可以学习到 classification score 和 IoU score 的联合分布;
采用 DFL(Distribution Focal Loss)来监督积分模块的学习,和 GIoU Loss 相结合共同监督回归任务的学习。
经过改进的 ET-Head,使模型取得了 0.5AP 的精度提升,最终模型在 COCO val 上达到了 50.9mAP 的精度,在 V100 上达到了 78.1FPS。
经过以上优化,PP-YOLOE-s/m/l/x 四个模型均在 COCO 2017 test-dev 取得了卓越的表现,具体对比结果如下图所示:
表 2:不同模型在 COCO 2017 test-dev 上的速度和精度比较
PaddleDetection 型产业级特色 PP 系列模型
除了 PP-YOLOE, PaddleDetection 还发布了轻量级 SOTA 目标检测算法 PP-PicoDet[9],成为边缘、低功耗硬件部署的最佳选择。同时在目标检测的基础上,持续拓展了如人体关键点、目标跟踪、人体属性分析、行为识别等高阶任务功能。有需求的用户可以到 Github 了解更多:
项目地址:https://github.com/PaddlePaddle/PaddleDetection
(1)PP-PicoDet[9]:0.7M,250FPS 超轻量目标检测算法,是业界首个 1M 内,且实现精度 mAP(0.5:0.95)超越 30 +的算法,且部署友好,被广泛应用在端侧场景。
图 5 PP-PicoDet 实际效果展示
(2)PP-TinyPose:122FPS、51.8mAP 超轻量关键点算法,精准实现人机交互任务,如手势控制、智能健身、体感游戏等。
图 6 PP-TinyPose 实际效果展示
(3)PP-Tracking:覆盖多类别跟踪、跨镜跟踪、流量统计等功能与应用目标跟踪系统,适用于智慧交通、安防监控等多个场景。
图 7 PP-Tracking 实际效果展示
(4)PP-Human:综合了目标检测、跟踪、关键点检测等核心能力的产业级开源实时行人分析工具,拥有人体属性分析、行为识别与流量计数与轨迹留存三大能力。
图 8 PP-Human 实际应用及效果示意图
面向产业需求的统一设计理念和极致的开发体验
以上提及的所有模型,均具有统一的使用方式及部署策略,不再需要进行模型转化、接口调整,更贴合工业大生产标准化、模块化的需求。
在模型优化方面,基于飞桨模型压缩工具库 PaddleSlim,能够快速实现模型小型化。PaddleDetection 提供剪裁、蒸馏、离线量化和量化训练等模型压缩策略,以及完整教程和 Benchmark。包含YOLOv3[8]、PP-PicoDet[9]、PP-YOLOE 等模型预测速度均有提升。
在部署方面,除了可以通过飞桨原生推理库 Paddle Inference 快速完成在服务端 GPU 或 ARM CPU 等硬件上的高性能加速部署,还可一键导出为 ONNX 格式,顺畅对接 ONNX 生态。
同时还有以下方式可供选择:
移动端 / 边缘端部署:基于飞桨轻量化推理引擎 Paddle Lite,可快速完成 20+ AI 加速芯片的适配,并支持 OpenVino 加速。PaddleDetection 推出的一系列轻量化模型,例如 PP-PicoDet[9], PP-TinyPose 均可以使用 Paddle Lite 部署在 ARM CPU、移动端 GPU、NPU 等嵌入式或 IoT 设备上。
服务化部署:基于飞桨服务化部署引擎 Paddle Serving,可以实现高性能、灵活易用的工业级在线推理服务。提供多种异构硬件和多种操作系统环境下推理解决方案。
云上飞桨 PaddleCloud:面向飞桨框架及其模型套件的部署工具箱,支持 Docker 化部署和 Kubernetes 集群部署两种方式,满足不同场景与环境的部署需求。
以上所有代码实现,均在 PaddleDetection 飞桨目标检测开发套件中开源提供:
飞桨 PaddleDetection 项目地址:
GitHub: https://github.com/PaddlePaddle/PaddleDetection
Gitee: https://gitee.com/paddlepaddle/PaddleDetection
想了解更多内容,可以参考飞桨官网:
官网地址:https://www.paddlepaddle.org.cn
飞桨开源框架项目地址:
GitHub: https://github.com/PaddlePaddle/Paddle
Gitee: https://gitee.com/paddlepaddle/Paddle
论文引用:
[1] Lu Rao. Treenet: A lightweight one-shot aggregation convolutional network. arXiv preprint arXiv:2109.12342, 2021. 2
[2] Chengjian Feng, Yujie Zhong, Yu Gao, Matthew R Scott, and Weilin Huang. Tood: Task-aligned one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3510–3519, 2021. 3, 4
[3] Xiang Li, Wenhai Wang, Lijun Wu, Shuo Chen, Xiaolin Hu, Jun Li, Jinhui Tang, and Jian Yang. Generalized focal loss: Learning qualified and distributed bounding boxes for dense obje
[4] Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, and Jian Sun. Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430, 2021. 1, 2, 4, 5
[5] glenn jocher et al. yolov5. https://github.com/ultralytics/yolov5, 2021. 1, 2, 3, 5, 6
[6] Xin Huang, Xinxin Wang, Wenyu Lv, Xiaying Bai, Xiang Long, Kaipeng Deng, Qingqing Dang, Shumin Han, Qiwen Liu, Xiaoguang Hu, Dianhai Yu, Yanjun Ma, and Osamu Yoshie. Pp-yolov2: A practical object detector, 2021. 1, 2, 5
[7] Xiang Long, Kaipeng Deng, Guanzhong Wang, Yang Zhang, Qingqing Dang, Yuan Gao, Hui Shen, Jianguo Ren, Shumin Han, Errui Ding, and Shilei Wen. Pp-yolo: An effective and efficient implementation of object detector. arXiv preprint arXiv:2007.12099, 2020. 1, 5
[8] Joseph Redmon and Ali Farhadi. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018. 1, 2,3
[9]Yu G, Chang Q, Lv W, et al. PP-PicoDet: A Better Real-Time Object Detector on Mobile Devices[J]. arXiv preprint arXiv:2111.00902, 2021.
——The End——

分享
收藏
点赞
在看
