手写数字识别_pytorch
前言
nlp写完一个情感分析的程序后: 情感分析bert家族 pytorch实现(ing
打算玩一玩cv这个基本入门的demo。可能今晚或者明天写写CIFAR-10的,本来想用一下与训练resnet的(先挖个坑),结果发现手写数字识别只有单通道…
本文数据加载与训练参考 https://zhuanlan.zhihu.com/p/137571225
代码
导入依赖
import torch
import torchvision
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from torchvision import models
# 设置超参数
batch_size_train = 64
batch_size_test = 64
learning_rate = 0.01
momentum = 0.5
log_interval = 10
random_seed = 1
torch.manual_seed(random_seed)
数据加载
# 加载训练数据
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_train, shuffle=True)
# 加载测试数据
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_test, shuffle=True)
print('len(train_loader): ', len(train_loader))
print('len(test_loader): ', len(test_loader))
查看一个批次的数据
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
print(example_targets)
print(example_data.shape) # [64, 1, 28, 28]

其实不one-hot也没关系,因为nn.crossEntropyLoss有两种用法,详见 torch.nn.CrossEntropyLoss用法
# one hot编码一下
target_onehot = F.one_hot(example_targets)
print(example_targets)
print(target_onehot[:8])
print(target_onehot[:8].argmax(dim=-1))

fig = plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Ground Truth: {}".format(example_targets[i]))
plt.xticks([])
plt.yticks([])
plt.show()

模型定义
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.max_pool = nn.MaxPool2d(2)
self.relu = nn.ReLU()
self.dropout = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
# self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.conv1(x)
x = self.max_pool(x)
x = self.relu(x)
x = self.conv2(x)
x = self.dropout(x)
x = self.max_pool(x)
x = self.relu(x)
x = x.view(-1, 320)
x = self.fc1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
# x = self.sigmoid(x) 加sigmoid后loss降不下去
return x
实例化模型
model = Net()
def get_parameter_number(model_analyse):
# 打印模型参数量
total_num = sum(p.numel() for p in model_analyse.parameters())
trainable_num = sum(p.numel() for p in model_analyse.parameters() if p.requires_grad)
return 'Total parameters: {}, Trainable parameters: {}'.format(total_num, trainable_num)
# 查看一下模型总的参数量和可学习参数量
get_parameter_number(model)

训练与预测
定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate,
momentum=momentum)
train_losses = []
train_counter = []
test_losses = []
训练函数:
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
train_losses.append(loss.item())
train_counter.append(
(batch_idx * batch_size_train) + ((epoch - 1) * len(train_loader.dataset)))
torch.save(model.state_dict(), './model.pth')
torch.save(optimizer.state_dict(), './optimizer.pth')
开始训练6个epoch(自己调,也可以多点少点),模型很小,所以很快。
train(epoch=6)
定义测试函数
def test():
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = model(data)
test_loss += criterion(output, target).item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).sum()
test_loss /= len(test_loader.dataset)
test_losses.append(test_loss)
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
10000个样本的测试集上:
test()

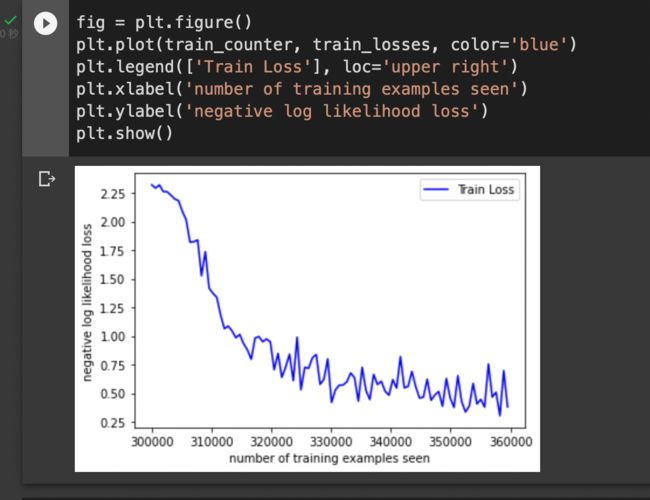
看图感觉其实epoch次数不用这么多…
fig = plt.figure()
plt.plot(train_counter, train_losses, color='blue')
plt.legend(['Train Loss'], loc='upper right')
plt.xlabel('number of training examples seen')
plt.ylabel('negative log likelihood loss')
plt.show()
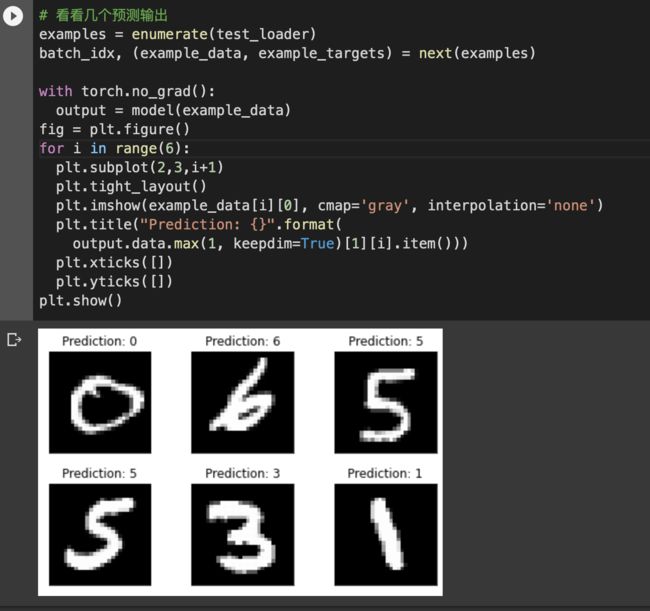
看看几个预测输出
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
with torch.no_grad():
output = model(example_data)
fig = plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Prediction: {}".format(
output.data.max(1, keepdim=True)[1][i].item()))
plt.xticks([])
plt.yticks([])
plt.show()