NNLM-pytorch
NNLM笔记
提出了神经网络语言模型。该模型使用前n-1词来预测第n个词,计算概率p(wn|w1,w2,````,wn-1)。首先先将前n-1个词用one-hot表示,然后使用投影矩阵降维,再将降维后的n-1个词的表示拼接起来,
2003年提出
Bengio将神经网络引入语言模型的训练中,并得到了词向量这个副产物。词向量对后面深度学习在自然语言处理方面有很大的贡献,也是获取词的语义特征的有效方法
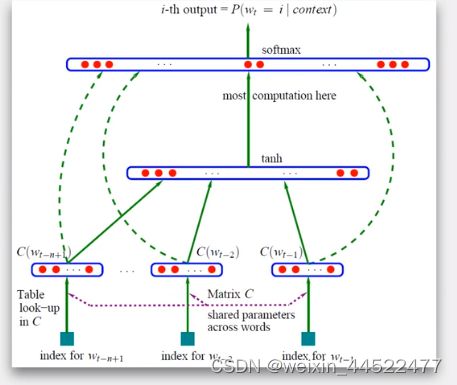
现在的任务:输入wt-n+1,````wt-1.这前n-1个单词,然后预测出下一个单词wt
import torch
import torch.nn as nn
import torch.optim as optimizer
import torch.utils.data as Data
dtype = torch.FloatTensor
sentences = ['I like cat','I love coffee','I hate milk']
sentences_list = " ".join(sentences).split() # 'i','like','cat','i'.'love
# 构建一个词汇表,set去重,转换为list
vocab = list(set(sentences_list))
# for i in enumerate枚举的意思
# word到索引的字典,索引转换为词的字典
word2idx = {w:i for i, w in enumerate(vocab)}
idx2word = {i:w for i, w in enumerate(vocab)}
# 获得词汇表有多少类
V = len(vocab)
# 构建x
def make_data(sentences):
input_data = []
target_data = []
# 遍历每个句子
for sen in sentences:
sen = sen.split() #[i like cat
# 从开始到倒数第二个词,而且我要的使索引
input_tmp = [word2idx[w] for w in sen[:-1]]
target_tmp = word2idx[sen[-1]]
input_data.append(input_tmp)
target_data.append(target_tmp)
return input_data,target_data
# Dataset
# 获取数据
input_data,target_data = make_data(sentences)
# 上面返回的是list
# 下面转换为tensor
input_data,target_data = torch.LongTensor(input_data),torch.LongTensor(target_data)
dataset = Data.TensorDataset(input_data,target_data)
loader = Data.DataLoader(dataset,16,True)
# paraeters
# 维度
m = 2
# 输入数据的长度
n_step = 2
# 隐藏层
n_hidden = 10
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
# 先embedding,首先是行数,维度
self.C = nn.Embedding(V,m)
# 将x送入隐藏层
# nn.Parameter将这个参数添加到模型当中
# 通过Embedding()之后,会将每一个词的索引,替换为对应的词向量,love的词的索引是3,查询word embedding表得3得向量为[0.2,0.1]
# 于是就会将原来x中3得值替换为该向量,所有值都替换完之后,x = [[[0.3,0.8],[0.2,0.4]],[[0.3,0.8],[0.2,0.1]]
self.H = nn.Parameter(torch.randn(n_step * m,n_hidden).type(dtype))
self.d = nn.Parameter(torch.randn(n_hidden).type(dtype))
self.b = nn.Parameter(torch.randn(V).type(dtype))
self.W = nn.Parameter(torch.randn(n_step * m,V).type(dtype))
self.U = nn.Parameter(torch.randn(n_hidden,V).type(dtype))
def forward(self,X):
"""
X :【batch_size,n_steop]
:param X:
:return:
"""
# 转换为3维的
X = self.C(X) # [batch_size,n_step,m]
# contact
X = X.view(-1,n_step * m ) # [batch_size,nstep*,]
hidden_out = torch.tanh(self.d + torch.mm(X,self.H)) # [batch_size,n_hidden]
output = self.b + torch.mm(X,self.W) +torch.mm(hidden_out,self.U)
return output
model = NNLM()
# 优化器
optim = optimizer.Adam(model.parameters(),lr=1e-3)
# 分类问题,损失
criterion = nn.CrossEntropyLoss()
for epoch in range(5000):
for batch_x, batch_y in loader:
pred = model(batch_x)
loss = criterion(pred,batch_y)
if (epoch+ 1 )% 1000 == 0:
print(epoch +1,loss.item())
optim.zero_grad()
loss.backward()
optim.step()
# 测试一下
# Pred
pred = model(input_data)#.max(1,keepdim=True)
print(pred)
pred = model(input_data).max(1,keepdim=True)[1]
print(pred)
print(idx2word[idx.item()] for idx in pred.squeeze())
D:\soft\Anaconda\envs\py3.9\python.exe D:/soft/pycharm/pythonProject2/nnlm.py
1000 0.02741100825369358
2000 0.005694000516086817
3000 0.0022972060833126307
4000 0.0011358462506905198
5000 0.0006150456028990448
tensor([[ 9.4481, 0.8564, -2.7897, -2.8303, 1.1038, 0.3093, -1.8339],
[-3.1282, 5.4857, -3.4849, -6.3472, -2.8064, -3.2702, -5.1880],
[-1.0392, -1.2272, -3.0040, -3.4432, 7.2797, -2.9803, -4.5407]],
grad_fn=<AddBackward0>)
tensor([[0],
[1],
[4]])
<generator object <genexpr> at 0x0000025C08AEC4A0>
进程已结束,退出代码0
import torch
import torch.nn as nn
import torch.optim as optimizer
import torch.utils.data as Data
dtype = torch.FloatTensor
sentences = ['I like cat','I love coffee','I hate milk']
sentences_list = " ".join(sentences).split() # 'i','like','cat','i'.'love
# 构建一个词汇表,set去重,转换为list
vocab = list(set(sentences_list))
# for i in enumerate枚举的意思
# word到索引的字典,索引转换为词的字典
word2idx = {w:i for i, w in enumerate(vocab)}
idx2word = {i:w for i, w in enumerate(vocab)}
# 获得词汇表有多少类
V = len(vocab)
# 构建x
def make_data(sentences):
input_data = []
target_data = []
# 遍历每个句子
for sen in sentences:
sen = sen.split() #[i like cat
# 从开始到倒数第二个词,而且我要的使索引
input_tmp = [word2idx[w] for w in sen[:-1]]
target_tmp = word2idx[sen[-1]]
input_data.append(input_tmp)
target_data.append(target_tmp)
return input_data,target_data
# Dataset
# 获取数据
input_data,target_data = make_data(sentences)
# 上面返回的是list
# 下面转换为tensor
input_data,target_data = torch.LongTensor(input_data),torch.LongTensor(target_data)
dataset = Data.TensorDataset(input_data,target_data)
loader = Data.DataLoader(dataset,16,True)
# paraeters
# 维度
m = 2
# 输入数据的长度
n_step = 2
# 隐藏层
n_hidden = 10
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
# 先embedding,首先是行数,维度
self.C = nn.Embedding(V,m)
# 将x送入隐藏层
# nn.Parameter将这个参数添加到模型当中
# 通过Embedding()之后,会将每一个词的索引,替换为对应的词向量,love的词的索引是3,查询word embedding表得3得向量为[0.2,0.1]
# 于是就会将原来x中3得值替换为该向量,所有值都替换完之后,x = [[[0.3,0.8],[0.2,0.4]],[[0.3,0.8],[0.2,0.1]]
self.H = nn.Parameter(torch.randn(n_step * m,n_hidden).type(dtype))
self.d = nn.Parameter(torch.randn(n_hidden).type(dtype))
self.b = nn.Parameter(torch.randn(V).type(dtype))
self.W = nn.Parameter(torch.randn(n_step * m,V).type(dtype))
self.U = nn.Parameter(torch.randn(n_hidden,V).type(dtype))
def forward(self,X):
"""
X :【batch_size,n_steop]
:param X:
:return:
"""
# 转换为3维的
X = self.C(X) # [batch_size,n_step,m]
# contact
X = X.view(-1,n_step * m ) # [batch_size,nstep*,]
hidden_out = torch.tanh(self.d + torch.mm(X,self.H)) # [batch_size,n_hidden]
output = self.b + torch.mm(X,self.W) +torch.mm(hidden_out,self.U)
return output
model = NNLM()
# 优化器
optim = optimizer.Adam(model.parameters(),lr=1e-3)
# 分类问题,损失
criterion = nn.CrossEntropyLoss()
for epoch in range(5000):
for batch_x, batch_y in loader:
pred = model(batch_x)
loss = criterion(pred,batch_y)
if (epoch+ 1 )% 1000 == 0:
print(epoch +1,loss.item())
optim.zero_grad()
loss.backward()
optim.step()
# 测试一下
# Pred
# pred = model(input_data)#.max(1,keepdim=True)
# print(pred)
pred = model(input_data).max(1,keepdim=True)[1]
# print(pred)
print([idx2word[idx.item()] for idx in pred.squeeze()])
D:\soft\Anaconda\envs\py3.9\python.exe D:/soft/pycharm/pythonProject2/nnlm.py
1000 0.03271440789103508
2000 0.007140910718590021
3000 0.002952432492747903
4000 0.0014770162524655461
5000 0.0007990959566086531
['cat', 'coffee', 'milk']
进程已结束,退出代码0