windows下面通过conda安装torch和cuda的正确添加源
在windows下面需要安装alphapose的依赖环境,首先需要安装pytorch=1.1.0, torchvision=0.3.0, cudatoolkit=10.0, cudnn=7.6.5。
如果没有添加conda的镜像,则会提示找不到这些包。
0. conda换回默认的源
conda config --remove-key channels1. 添加pytorch和torchvision的conda镜像,执行:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/2. 添加cudatoolkit的conda镜像,执行:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/linux-64/3. 添加cudnn的conda镜像,执行:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/linux-64/4. 最后执行命令使conda镜像生效:
conda config --set show_channel_urls yes5. 执行安装命令:
conda install pytorch==1.1.0 torchvision==0.3.0 cudatoolkit=10.0 cudnn=7.6.5
其中一般只执行0和1步骤,即可直接执行5步骤即可。
6. cudnn提示安装包找不到的情况
有时候比如想装cudnn = 8.0.5,但是执行 conda install cudnn=8.0.5, 却提示 “PackagesNotFoundError: The following packages are not available from current channels”,这个时候按照这篇进行处理
首先查看可用的cudnn版本,执行:anaconda search -t conda cudnn
![]()
出现如下图:
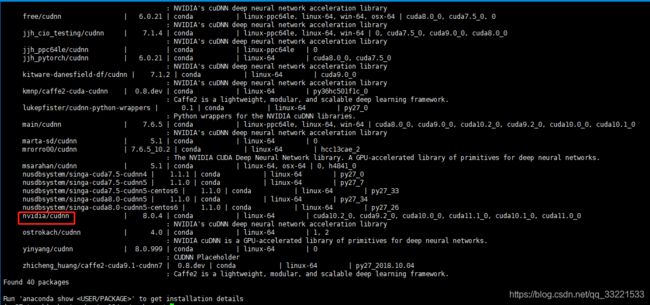
这个时候比如想装nvidia/cudnn这个版本,则执行:conda install -c https://conda.anaconda.org/nvidia cudnn,注意后面的/用空格代替
![]()
即可装上满足cuda 11.0的cudnn。
参考文献:
1. https://zhuanlan.zhihu.com/p/269972551
2. https://blog.csdn.net/just_h/article/details/90451935
3. https://www.cnblogs.com/yibeimingyue/p/13837929.html