旷世轻量化网络ShuffulNetV2学习笔记
旷世轻量化网络ShuffulNetV2学习笔记
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design

Abstract
目前,神经网络体系结构的设计主要由计算复杂性的间接度量来指导,即FLOPs.。然而,速度等直接指标也取决于其他因素,如内存访问成本和平台特性。因此,这项工作建议评估目标平台上的直接度量,而不仅仅是考虑FLOPs.。基于一系列的控制实验,这项工作得出了一些有效网络设计的实用指南。因此,提出了一种新的体系结构,称为ShuffleNet V2。综合烧蚀实验证明,我们的模型在速度和精度方面是最先进的。
总结:

1 Introduction
深度卷积神经网络(CNN)的体系结构已经发展了多年,变得更加精确和快速。自AlexNet的里程碑式工作【15】以来,ImageNet的分类精度已通过新结构得到显著提高,其中包括VGG【25】、GoogLeNet【28】、ResNet【5、6】、DenseNet【11】、ResNeXt【33】、SE Net【9】和自动中性架构搜索【39、18、21】。
除了准确性之外,计算复杂性也是另一个重要的考虑因素。现实世界的任务通常旨在通过目标平台(如硬件)和应用场景(如自动驾驶要求低延迟)在有限的计算预算下获得最佳精度。这推动了一系列朝着轻量级架构设计和更好的速度精度权衡方向发展的工作,其中包括Xception【2】、MobileNet【8】、MobileNet V2【24】、ShuffleNet【35】和CondenceNet【10】等等。群卷积和深度卷积是这些工作的关键。
为了衡量计算复杂性,一个广泛使用的指标是浮点运算的数量,即FLOPs。然而,FLOPs是一个间接指标。它是一个近似值,但通常不等同于我们真正关心的直接指标,例如速度或延迟。在之前的作品中已经注意到这种差异【19、30、24、7】。例如,MobileNet v2[24]比NASNET-A[39]快得多,但它们的失败率相当。这一现象在图1(c)(d)中得到了进一步的例证,图1(c)(d)显示了具有类似FLOPs的网络具有不同的速度。因此,使用FLOPs作为计算复杂性的唯一度量是不够的,可能导致次优设计。

FLOPS和FLOPs的区别:

间接(FLOPs)和直接(speed)指标之间的差异可归因于两个主要原因。首先,对速度有相当大影响的几个重要因素没有被FLOPs考虑在内。其中一个因素是memory access cost 内存访问成本(MAC)。在某些操作(如组卷积)中,这样的成本占运行时间的很大一部分。这可能是具有强大计算能力的设备(如GPU)的瓶颈。在网络架构设计过程中,不应简单地忽略这一成本。另一个是 degree of parallelism平行度。在相同的FLOPs下,具有高并行度的模型可能比另一个具有低并行度的模型快得多。
其次,根据平台的不同,使用相同触发器的操作可能有不同的运行时间。例如,张量分解在早期的工作中被广泛使用【20,21,22】,以加速矩阵乘法。然而,最近的工作【19】发现【22】中的分解在GPU上甚至更慢,尽管它减少了75%的失败率。我们研究了这个问题,发现这是因为最新的CUDNN[23]库专门针对3×3 conv进行了优化。我们不能肯定3×3 conv比1×1 conv慢9倍。
根据这些观察结果,我们提出了有效的网络架构设计应考虑两个原则。首先,应该使用直接度量(例如速度),而不是间接度量(例如触发器)。其次,应在目标平台上评估此类指标。
在这项工作中,我们遵循这两个原则,并提出了一种更有效的网络架构。在第2节中,我们首先分析了两个具有代表性的最先进网络的运行时性能【15,14】。然后,我们推导出了四条高效网络设计准则,这些准则不仅仅考虑触发器。虽然这些指南与平台无关,但我们在两个不同的平台(GPU和ARM)上进行了一系列受控实验,并进行了专门的代码优化,以确保我们的结论是最先进的。
在第3节中,我们根据指南设计了一种新的网络结构。由于其灵感来源于ShuffleNet【15】,因此被称为ShuffleNet V2。通过第4节中的综合验证实验,证明它比之前两种平台上的网络都更快、更准确。图1(a)(b)给出了比较的概述。例如,考虑到4000万次浮点运算的计算复杂性预算,ShuffleNet v2的精度分别比ShuffleNet v1和MobileNet v2高3.5%和3.7%。
2 Practical Guidelines for Efficient Network Design
我们的研究是在CNN库的行业级优化的两个广泛采用的硬件上进行的。我们注意到,我们的CNN库比大多数开源库更高效。因此,我们确保我们的观察结果和结论是可靠的,并对行业实践具有重要意义。
1)GPU。使用单个NVIDIA GeForce GTX 1080Ti。卷积库是CUDNN 7.0[23]。我们还激活了CUDNN的基准函数,分别为不同的卷积选择最快的算法。
2)ARM。高通Snapdragon 810。我们使用高度优化的基于Neon的实现。单个线程用于评估。
其他设置包括:打开全部优化选项(例如,用于减少小操作开销的张量融合)。输入图像大小为224×224。每个网络随机初始化并评估100次。使用平均运行时间。
为了启动我们的研究,我们分析了两种最先进网络的运行时性能,即ShuffleNet v1[35]和MobileNet v2[24]。它们在ImageNet分类任务上都是高效和准确的。它们都广泛用于低端设备,如手机。虽然我们只分析这两个网络,但我们注意到它们代表了当前的趋势。其核心是组卷积和深度卷积,这也是其他最先进网络的重要组成部分,如ResNeXt【33】、Xception【2】、MobileNet【8】和CondenceNet【10】。
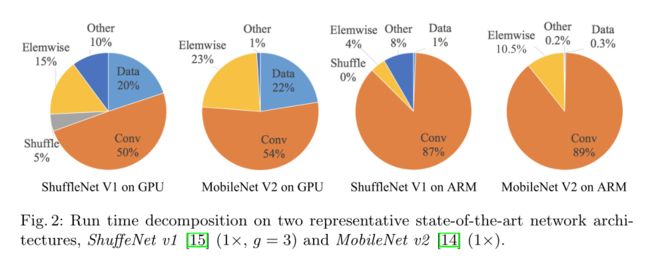
整个运行时针对不同的操作进行分解,如图2所示。我们注意到,FLOPs度量只考虑卷积部分。虽然这部分占用了大部分时间,但其他操作,包括数据I/O、数据无序和元素操作(AddTensor、ReLU等)也占用了大量时间。因此,FLOPs对实际运行时间的估计不够准确。
基于这一观察结果,我们从几个不同的方面对运行时(或速度)进行了详细的分析,并得出了一些有效网络架构设计的实用指南。
G1) Equal channel width minimizes memory access cost (MAC).
现代网络通常采用深度可分离卷积[12,13,15,14],其中点方向卷积(即1×1卷积)占了大部分复杂性[15]。我们研究了1×1卷积的核形状。形状由两个参数指定:输入通道c1和输出通道c2的数量。设h和w为特征映射的空间大小,1×1卷积的触发器为 B = h w c 1 c 2 B=hwc_1c_2 B=hwc1c2。
为了简单起见,我们假设计算设备中的缓存足够大,可以存储整个特征映射和参数。因此,内存访问成本(MAC)或内存访问操作的数量是 M A C = h w ( c 1 + c 2 ) + c 1 c 2 MAC=hw(c_1+c_2)+c_1c_2 MAC=hw(c1+c2)+c1c2。请注意,这两个术语分别对应于输入/输出特征映射和内核权重的内存访问。
根据均值不等式,我们得到

因此,MAC有一个由FLOPs给出的下限。当输入和输出通道数相等时,达到下限。
结论是理论性的。实际上,许多设备上的缓存不够大。此外,现代计算库通常采用复杂的阻塞策略来充分利用缓存机制[24]。因此,实际MAC可能会偏离理论MAC。为了验证上述结论,进行了如下实验。通过重复堆叠10个构建块来构建基准网络。每个块包含两个卷积层。第一个包含c1输入通道和c2输出通道,第二个包含其他通道。
表1通过改变比率c1:c2来报告运行速度,同时固定总的触发器。很明显,当c1:c2接近1:1时,MAC变得更小,网络评估速度更快。

G2) Excessive group convolution increases MAC.

群卷积是现代网络体系结构的核心[7,15,25,26,27,28]。它通过将所有通道之间的密集卷积更改为稀疏(仅在通道组内)来降低计算复杂度(FLOPs)。一方面,它允许在给定固定触发器的情况下使用更多通道,并增加网络容量(从而提高精度)。然而,另一方面,信道数量的增加会导致更多MAC。
形式上,根据G1和等式1中的符号,1×1组卷积的MAC和FLOPs之间的关系为
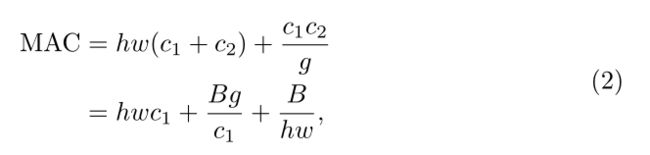
其中g是组数, B = h w c 1 c 2 / g B=hwc_1c_2/g B=hwc1c2/g是触发器。很容易看出,给定固定的输入形状 c 1 × h × w c_1×h×w c1×h×w和计算成本B,MAC随着g的增长而增加。
为了研究实际应用中的影响,通过叠加10个逐点分组卷积层来构建基准网络。表2报告了使用修复总失败次数时使用不同的组号。很明显,使用大量组数会显著降低运行速度。例如,在GPU上使用8组比使用1组(标准密集卷积)慢两倍多,在ARM上慢30%。这主要是由于MAC的增加。我们注意到,我们的实现经过了专门的优化,比逐组计算卷积要快得多。

因此,我们建议根据目标平台和任务仔细选择组号。仅仅因为这样可以使用更多通道,使用大量组号是不明智的,因为快速增加的计算成本很容易超过精度提高的好处。
G3) Network fragmentation reduces degree of parallelism.
在GoogLeNet系列[29,30,3,31]和自动生成架构[9,11,10]中,每个网络块中都广泛采用了“多路径”结构。使用了很多小操作符(这里称为“分段操作符”),而不是几个大操作符。例如,在NASNET-A[9]中,分段操作符的数量(即一个构建块中的单个卷积或池操作的数量)是13。相反,在ResNet等常规结构中,这个数字是2或3。
虽然这种分散的结构有利于提高准确性,但它可能会降低效率,因为它对GPU等具有强大并行计算能力的设备不友好。它还引入了额外的开销,如内核启动和同步。
为了量化网络碎片如何影响效率,我们评估了一系列具有不同碎片程度的网络块。具体而言,每个构建块由1到4个1×1卷积组成,这些卷积按顺序或并行排列。块体结构如附录所示。每个砌块重复堆放10次。表3中的结果表明,碎片化显著降低了GPU上的速度,例如,4片段结构比1片段慢3倍。在ARM上,速度降低相对较小。

G4) Element-wise operations are non-negligible.
如图2所示,在像[15,14]这样的轻量级模型中,**元素操作(激活函数)**占用了大量时间,尤其是在GPU上。这里,元素级操作符包括ReLU、AddTensor、AddBias等。它们有较小的失败,但MAC相对较重。特别地,我们还将深度卷积(depthwise convolution)[12,13,14,15]视为一种元素操作,因为它也具有很高的MAC/FLOPs比。
为了验证,我们在ResNet中试验了“瓶颈”单元(1×1 conv,然后是3×3 conv,然后是1×1 conv,带有ReLU和快捷连接)。将分别删除ReLU和shortcut operations操作。表4中报告了不同变体的运行时间。我们观察到,在删除ReLU和shortcut operations后,GPU和ARM上都获得了大约20%的加速比。

结论和讨论
基于上述指导原则和实证研究,我们得出结论,一个高效的网络体系结构应该1)使用“平衡”卷积(相等的信道宽度);2)意识到使用组卷积的成本;3)降低碎片化程度;4)减少元素操作。这些理想的特性取决于平台特性(如内存操作和代码优化)这超出了理论上的失败。在实际的网络设计中,应考虑这些因素。
轻量级神经网络结构的最新进展[15,13,14,9,11,10,12]主要基于触发器的度量,没有考虑上述属性。例如,ShuffleNet v1【15】严重依赖于组卷积(违背G2)和瓶颈状构建块(违背G1)。MobileNet v2【14】使用了一个违反G1的反向瓶颈结构。它使用深度卷积和依赖于“厚”特征图。这违反了G4。自动生成的结构【9,11,10】高度碎片化,违反G3。
3 ShuffleNet V2: an Efficient Architecture
Review of ShuffleNet v1
ShuffleNet是一种最先进的网络体系结构。它被广泛应用于低端设备,如手机。它激励着我们的工作。因此,首先对其进行回顾和分析
根据文献[15],轻型网络面临的主要挑战是,在给定的计算预算(FLOPs)下,只能承受有限数量的特征信道。为了在不显著增加触发器的情况下增加通道数量,在[15]中采用了两种技术:逐点组卷积和瓶颈状结构。然后引入“channel shuffle”操作,以实现不同通道组之间的信息通信并提高准确性。构建块如图3(a)(b)所示。

如第2节所述,点态群卷积和瓶颈结构都会增加MAC(G1和G2)。这一成本不容忽视,尤其是对于轻型模型。此外,使用过多的组违反了G3。快捷连接中的元素级“添加”操作也是不可取的(G4)。因此,为了获得高的模型容量和效率,关键问题是如何在没有密集卷积和太多组的情况下保持大量等宽的信道。
Channel Split and ShuffleNet V2
为了达到上述目的,我们引入了一个称为通道分割的简单操作符。如图3(c)所示。在每个单元的开头,c特征通道的输入用c分为两个分支分别为 c − c ′ c-c^{'} c−c′和 c ′ c^{'} c′通道。在G3之后,一个分支仍然作为标识。另一个分支由三个具有相同输入和输出通道的卷积组成,以满足G1。这两个1×1卷积不再是分组卷积,这与[15]不同。这部分是为了遵循G2,部分是因为拆分操作已经生成了两个组。
在卷积之后,这两个分支被连接起来。因此,通道数保持不变(G1)。然后,使用与[15]中相同的“channel shuffle”操作来启用两个分支之间的信息通信。
洗牌后,下一单元开始。请注意,ShuffleNet v1【15】中的“add”操作已不存在。像ReLU和深度卷积这样的元素操作只存在于一个分支中。此外,三个连续的元素级操作“Concat”、“Channel Shuffle”和“Channel Split”被合并为单个元素级操作。根据G4,这些变化是有益的。
对于空间下采样,该单位略有修改,如图3(d)所示。已删除通道拆分操作符。因此,输出通道的数量增加了一倍。
提议的构建块(c)(d)以及由此产生的网络被称为ShuffleNet V2。基于以上分析,我们得出结论,这种架构设计是高效的,因为它遵循了所有的指导原则。
构建块被重复堆叠以构建整个网络。为简单起见,我们设置 c ′ = c / 2 c^{'}=c/2 c′=c/2。整体网络结构类似于ShuffleNet v1【15】,总结见表5。只有一个区别:在全局平均池之前添加了一个额外的1×1卷积层,以混合功能,这在ShuffleNet v1中是不存在的。与文献[15]类似,每个块中的通道数被缩放以生成不同复杂度的网络,标记为0.5×、1×,等等。

Analysis of Network Accuracy
ShuffleNet v2不仅高效,而且准确。有两个主要原因。首先,每个构建块的高效性允许使用更多的功能通道和更大的网络容量。
其次,在每个块中,一半的特征通道(当c0=c/2时)直接穿过块并连接到下一个块。这可以被视为一种特征重用,其精神与DenseN et[6]和CondenceNet[16]相似。
在DenseNet[6]中,为了分析特征重用模式,绘制了层间权重的l1范数,如图4(a)所示。很明显,相邻层之间的连接比其他层更强。这意味着所有层之间的紧密连接可能会引入冗余。最近的CondenceNet[16]也支持这一观点。

因此,ShuffleNet V2的结构通过设计实现了这种类型的特征重用模式。与DenseNet[6]一样,它具有重复使用特征以获得高精度的优点,但与前面分析的结果相比,它的效率要高得多。表8中的实验验证了这一点。
4 Experiment


5 Conclusion
我们建议网络架构设计应考虑速度等直接指标,而不是像FLOPs这样的间接指标。我们提出了实用指南和一种新的体系结构,ShuffleNet v2。综合实验验证了新模型的有效性。我们希望这项工作能够启发未来的网络架构设计工作,使其具有平台意识和更实用性