一文入门大规模预训练语言模型丨“悟道之巅”公开课实录(1)

如果你错过了上一波深度学习引发的NLP范式转换,不要再错过这一波超大预训练模型的崛起。
近日,“悟道”核心团队推出首档公开课,公开课已全部上线,手把手帮助中国开发者理解并应用“悟道”,从而进一步挖掘“悟道”的潜力,开发自己的智能应用。
通过“悟道”公开课,开发者们将与预训练模型这一人工智能领域最重要的趋势保持同步,更有120万+“悟道之巅”比赛奖金可以拿(点击文末“阅读原文”也可报名)。
第一讲视频点此观看
第二讲视频点此观看
第三讲视频点此观看
第四讲视频点此观看
第五讲视频点此观看
本期课程可以看做是面向所有人的大规模预训练模型(下文简称“大模型”)科普课,从大模型与传统机器学习模型的区别、机器学习范式的变化和 GPT-3 讲起,进一步介绍悟道模型及主要技术、悟道之巅大赛参与方式以及悟道 API 使用说明。
本期主讲人为清华大学知识工程实验室博士生于济凡,师从李涓子教授和唐杰杰教授,曾参与悟道2.0研发。

主要内容如下:
-
大规模预训练模型背景
-
悟道模型介绍及主要技术
-
悟道之巅大赛介绍
-
API 使用说明及演示
其中,前三个部分普及性比较强,最后一个部分会对 API 的完整使用进行说明和简单地尝试。同时,提出一些使用 API 的方法和思路,帮助使用者提升 API 使用效率。
一、大模型为什么是“第三代人工智能”?
大规模预训练模型是第三代人工智能标志性的里程碑之一。
第一代人工智能是基于符号AI的符号模型、规则模型、感知机模型等。
由于大数据方法的进步以及计算资源的丰富,基于大数据驱动的统计学习方法,人们已经初步实现第二代感知智能对于文本、图像、语音等感知和识别。通过近些年的发展,深度学习、机器学习等概念逐渐流行起来,推进了推荐系统、图像识别、人脸检测等不同领域的应用。

2016 年,张钹院士提出了第三代人工智能的雏形,由此,深度学习走向下一个 10 年的发展历程。
DARPA 在 2018 年发布了 AI Next 计划,核心思路是推进数据统计与知识推理融合的计算、与脑认知机理融合的计算,目的在于解决目前AI无法解决的问题,让人工智能更好地融入现代生活。
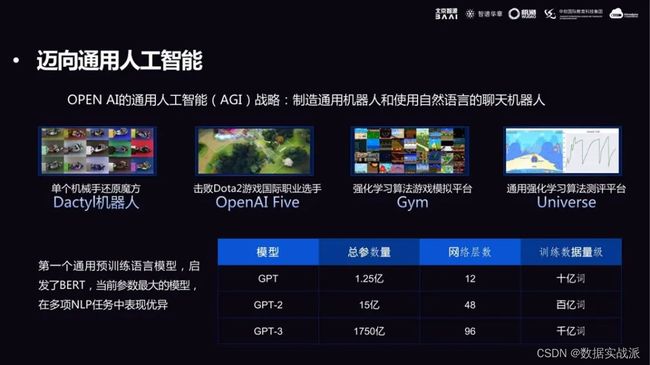
在迈向通用人工智能的过程中,一些具有代表性的研究机构,比如 Open AI,提出了通用人工智能的战略(AGI 战略),其内容包括制造通用机器人和能够使用自然语言聊天的机器人等。
在这一阶段,Open AI 作为时代的引领者,制作了单个机械手还原魔方的 Dactyl 机器人、击败了 Dota2 职业国际职业选手的 Open AI Five、强化学习算法游戏模拟平台 Gym 以及通用强化学习算法评测平台 Universe等。
自从大模型提出后,AI 技术逐渐在不同领域大放异彩,甚至在一些重要任务上超过了人类。但这也并不代表以上所有方法都是在大模型里实现的。
客观来看,近年来能让人们感受到“质变”的都是规模比较大的模型,比较有代表性的就是 GPT。
GPT 团队最开始做 GPT-1 时,其总参数量只有 1.25 亿,到 GPT-2 时总参数量达到 15 亿,但这并没有掀起太大波澜。2020 年疫情期间,GPT-3 横空出世,飙升的 1750 亿参数,使它不仅在比较擅长的领域发挥作用,甚至在不擅长的领域也发挥了作用。
至此,人们开始相信,使用更大规模的模型能够解决一些通用的人工智能问题。
2020 年 5 月份以来,大规模的 GPT-3 用无监督的方式,甚至不需要进行下游翻译,就能很好地完成一些下游任务。因此,大模型被当做新一代通用人工智能的解决思路的基底。
近年来,人们在大模型上的探索,类似于人工智能的军备竞赛,Open AI 的通用人工智能战略即从语言模型开始探索。
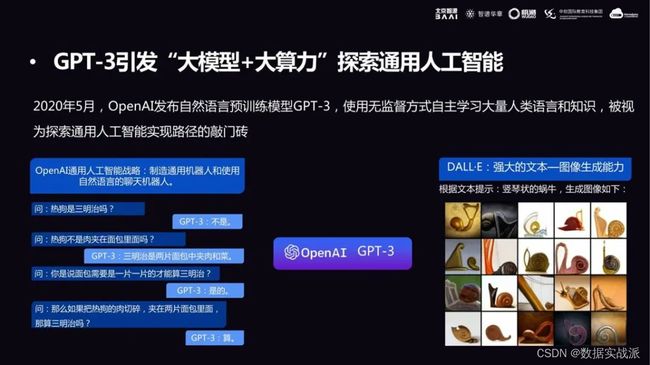
上图演示的是 GPT-3 在无监督场景下对话的情况,可以看出,它说的话已经带有一定的认知能力和知识储备。
新事物的出现也会伴随很多质疑的声音。但抛开质疑来看,GPT-3 的表现相对于“传统大模型”的表现或者以前的语言建模表现,已经有了很大进步。
OpenAI 提出 GPT-3 之后,他们也不满足于只做语言类的模型,在去年年末到今年年初的这段时间,他们发布了 DELL·E——一种基于文本直接生成图像的大模型。
简而言之,现在的“大模型”已经不仅限于自然语言,而是开始进行跨模态的的研究。
这样的大背景下,大公司能够进行大规模语言模型的发布,但是小公司、初创公司或者学校内的实验室等小团队或个人开发者,很少有强大的算力资源、足够的经费、统筹协调的能力以及丰富的技术团队。所以,他们很难通过自己的能力训练出一个 GPT-3 级别的大模型。
在过去需求不大的时候,大家对于模型参数量还能接受,很多公司会选择训练一个自己的 bert 或者自己领域的 bert。
但发展到 GPT-3 1750 亿的参数量,对于大部分的初创公司来说已经是天文数字。因此,商业模式也在悄然发生变化。

比如,目前全球已经有 10 余家公司基于 GPT-3 的大模型来完成下游任务。
这些公司也获得了融资,如上图列出的 Replit、Message bird 等。这些公司并没有训练自己的大模型,而是把已有的“大模型”用好或者把它融入到自己的场景中,这种方式已经能够创造出新的领域了。
从某个角度来看,虽然大模型会造成大公司在计算资源方面极大地发展和技术垄断,但是也为更多的个人开发者提供了新的机遇。
以前,利用大模型必须要自己训练;现在,大公司会把像 GPT-3 这种超大规模的模型封装成云服务,提供给个人开发者,并且帮助他们完成各自的任务。

上图是智源发布会上展示的一页 PPT,这页 PPT 形象地表达了“大模型时代”的到来。
它所囊括的超大数据、超大算力和超大模型的基底,其实是未来工业和未来人工智能生态中各个领域都会应用到的一种能源产业,类似于发电厂。
大量初创者或独立团队应该考虑,如何将 AI 大模型融入到自己的场景中并开展研究。
二、悟道模型能做什么?怎么实现的?
在 2021 年 3 月,悟道1.0 发布,成为中国首个超大规模的智能模型。
在此之前,我们看到的“大模型”都是由美国的 Open AI、 Facebook 这些大公司、科研机构发布。

作为中国 AI 基础建设的先行者,北京人工智能研究院认为,完成超大规模的中文模型或在中国话语权下发布智能大模型是责无旁贷的。在悟道1.0 发布之后,也吸引了国内外的关注。吴恩达教授也表示,悟道1.0 也会有益于中国在人工智能领域增强信心,提升研发实力。
目前,悟道团队的人数有限,但是也说明有大量的探索空间,留给独立开发者自由探索。
悟道大模型的终极目标,是让机器能够像人一样思考。
一直关注大模型的读者,可能已经读过这句“惠业苦研虽久成,禅风散尽见真迹”,这看起来像文学家给我们写的诗,但实际上,这句诗是悟道1.0 发布时,通过悟道1.0 简单生成的结果。
悟道1.0 并没有经过很复杂的过程,或者专门在诗词语料上做特定训练,就能够得到相对不错的写诗结果。
在文艺上的自由创作,已经证明了“大模型”的实力。可以想象,“大模型”在某些领域也许已经可以像人一样去获得自己的品位、艺术鉴赏的能力,并以此帮助文艺作品达到更好的效果。

在推出“大模型”之后,为了使整个模型生态有比较好的铺展,相关人员以悟道大模型作为基础,开发了一整套悟道应用平台(包括样例应用)。
但受限于团队制作人员,我们因此搭建了一套面向认知的智能服务,把团队中不同类型的大模型集成到系统中,更好地帮助大家。
悟道应用平台,不仅面向 NLP 领域的研究者或有相关技术能力的研究者,也面向其他不同领域的研究者或创业者,这是“大模型”带来的福利。

因为,“大模型”不应仅面对自然语言处理或者人工智能领域,而应该面向更多其他领域或专业。
目前搭建的悟道融合知识的大模型平台,相关人员将其封装为 SaaS 和 Paas 服务,希望能为社区打造一套知识与数据双轮启动的具备认知性能的系统。
这套平台现在就可以通过应用中心文档进行账号注册、开发者的认证以及应用的申请和 API 的调用。

目前,悟道开放平台已经具备简单的应用中心,其中包括作诗作画、科普问答、人设问答、图文问答、文案生成、看图说话等比较直接的基础功能。该平台还有很大的潜力和发展进步空间。
很多人认为,“大模型”可以用更好的方式呈现,而且可以做出更有趣的应用。
这需要人工智能的研究群体以及全中国的创新创业群体一起合作、出谋划策,把悟道做到极致。
这也正是举办悟道之巅——AI 创新应用大赛的原因之一。

接下来,我们展示一些 AI 应用的成果。
图中的两首诗,一首是唐朝的冷门诗,一首是悟道基于题目生成的。
在简单的图灵测试之后发现,如果对于诗词格律不是特别了解,人们很难分辨出哪首是唐诗。这说明若能在某些领域把悟道开发到极致,或许能做到以假乱真的效果。
在作画部分,比如输出金门大桥,悟道生成的结果虽然像素和分辨率较低,但也能看得出它代表了什么。
悟道还画了女演员刘亦菲的肖像,虽然未能达到惟妙惟肖,但至少能够看出这是一个女明星。
悟道还能生成一些在现实生活中完全不存在的东西。比如,一只带着墨镜的猫趴在桌子上,一个人骑着自行车飞向月球。

目前,悟道团队将一些功能封装成了几个部分,包括文本生成、快速写诗、藏头诗、宋词、智能问答、新闻生成、画图等这样的 API 接口,可帮助对产品有直接需求的研究者、创业者进行智能产品开发。
三、即刻体验“悟道”,开发自己的AI 创新应用

通过以上的内容,各位可以了解到“大模型”怎样工作。悟道团队也为大模型做了比较基础的系统,希望能够吸引专业人士或其他领域的创业者群策群力,一起完善整个悟道生态体系。
相关人员也申请了一笔资金,专门用于举办悟道之巅 AI 创新应用大赛(奖金120万元+)。
本次比赛,也是基于以上 API 接口给大家做基础的样例。
这个渠道将悟道系统开放给公众,让有感兴趣的人可以直接体验悟道系统的效果,对于有想法的团队也将给予奖励支持。

本次比赛中,奖金总计 120 万元,一等奖一支队伍,二等奖两支,三等奖六支,优胜奖三十支,而且会颁布“华智冰”优秀应用奖、先锋奖。
除了现金奖励之外,还有对于这些单位或团队提供孵化支持,包括算力、人才直通车、人才 offer 等各种各样的奖项。
比赛从 8 月份就已经开始了,有队伍已经尝试过,悟道团队仍然在接下来的这几门课程中,协同解决参赛者遇到的技术问题。

整个悟道之巅创新应用大赛,与其他算法数据比赛还是有差别的。
悟道之巅希望参赛者最终呈现的是比较好的产品,最好聚焦于某个特定领域,**如医疗、教育、社交、环境效率、个人生活或者游戏等不同类型的应用,结合悟道的能力进行效能的辅助提升,**以评比的方式得到最终的结果。
如果之前没有参加比赛,现在感兴趣,也可以扫描下方的二维码继续报名。

**比赛的通道到现在仍然开放,报名完全免费。**报名之后会自动获得一个 API 调用的内测名额和权限,同时也提供模型下载的自动认可,参赛者可以获得不错的体验感。
各位也可以加入相关比赛群,更多的比赛细节可以进行深度对接。
报名课程的人很多已经参与比赛,对于没参与比赛的同学,我们也始终保持开放的态度,欢迎大家参加。

在这次比赛中,开放了资源占用量相对合理且效果有保证的 9 个 API。
根据参赛者对于模型的占用以及并发量的能力,比赛为每支队伍限制了每天调用 API 的数额,包括图文、诗歌、文本和图像的引抠点,还有写诗、问答、宋词、新闻等 API 的次数。
当报名具体的比赛之后,各位可以看到效果。

在比赛数据一栏,会具体展示每个 API 的使用方法,也会把接口的要求和接口调用的流程展示清楚,可通过代码调用、网页调用均可。

PPT中给出了快速写诗的样例:首先输入队列名、标题、作者以及要解释模式的状态,再添加大赛报名页面给你提供的 token、key 和 secret,就可以得到结果。
上图就是以李白的写作方式得到的五言律诗,而且最终结果是可以经过多次的生成或者调试得到。
四、API 使用说明及思路展示
最后,除了 API 的使用说明之外,本次课程还会提供一些可能的解决思路,再尝试其可行性。

一般来说,API 以及模型是可以通过以下几种方式进行效果提升。
首先是最著名的 Fine-tuning,用特定语料微调。
许多人都知道先做预训练模型会让模型效果提升。比如,现在的悟道大模型是在通用的语料上进行训练,那么,只要继续训练,比如做医疗领域的对话,就给出医疗领域的对话样本。在进行微调之后,效果会变得更好。
**第二是引导语设计,相同的问题,不同问法得到的结果不同。**例如,曾经有一版模型是基于知乎的语料进行训练的。比如,只是简单提问“李白怎么样”,得到的答案并不太好。但如果用知乎体的方式进行询问,比如“如何看待李白的诗歌的贡献”,得到的答案就会非常丰富。
所以,鼓励各位对于引导语进行独特的探索和设计。这一部分也是现在研究领域里的热门,即对于 Prompt 引导语如何进行工程化设计和改进。
**第三是反向自检验,**这里引入一篇名叫《反向自检验的一种方法》的论文,这篇论文是前团队中一位优秀博士生创作的。虽然论文中的 API 调用不给执行度,但是可以通过一些模型反向检验答案,也可能提升答案质量。
比如,用李白的口吻生成一首诗,生成完毕后,可以反向询问模型:“这首诗是哪个诗人写的?”如果模型告诉你这首诗是李白写的,说明这首诗的确贴合李白的风格。如果模型回答这首诗的作者是其他诗人,比如王维,可能说明刚刚有关李白的信息并没有被模型收集好,如果正向反向都能够达到统一的效果,说明质量可以得到保证。
**第四是缓存及等待机制。**很多模型要达到效果是比较慢的,不能即时得出很好的结果。对于即时性要求较高的应用,就不适合直接生成。因此,可以把一些比较好的答案进行提前缓存,等有问题之后进行检索。如果有相关的就直接返回,如果没有可以再等待。
以上便是本期主要内容。
附:“悟道之巅”比赛报名和交流
大赛官网点此进入
文章原文
微信交流群:添加小助手微信biendata02备注“悟道之巅”加入讨论群。
