GLIP:语言-图像关联预训练模型
原文:Li, Liunian Harold, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang and Jianfeng Gao. “Grounded Language-Image Pre-training.” ArXiv abs/2112.03857 (2021).
源码:https://github.com/microsoft/GLIP
本文提出了一种语言-图像关联预训练模型GLIP,用于学习对象级、语言感知和语义丰富的视觉表示。GLIP将目标检测和短语关联任务统一起来进行预训练。这种统一带来了两个好处:1)它允许GLIP从检测和关联数据中学习,以改进这两个任务,并bootstrap一个良好的关联模型;2)GLIP可以通过自训练的方式生成关联框来利用大量的图像-文本对,使学习到的表示具有丰富的语义。我们在27M的关联数据上对GLIP进行了预训练,这些数据包括3M的人工注释数据和24M网络爬取的图像-文本对。GLIP学习到的表示在各种目标识别任务上都表现出很强的零样本和小样本迁移性能。1)当在COCO和LVIS数据集上直接评估GLIP模型时(预训练期间没有看过COCO中的任何图像),GLIP在COCO val和LVIS val上分别达到了49.8和26.9 AP,超过了许多有监督的基线。2)在COCO上进行微调后,GLIP在COCO val上达到了60.8 AP,在COCO test-dev上达到了61.5 AP,超过了之前的SOTA水平。3) 当迁移到13个下游目标检测任务时,1样本的GLIP能够与完全监督的Dynamic Head相匹敌。
注:Phrase Grounding不好翻译,Grounding有接地、基础、搁浅的意思,但是这些放在Phrase后面说不通,我这里倾向于理解成关联、联系、定位的意思。我们可以将Phrase Grounding理解为把句子里面的短语和图像里面的对象/区域关联起来,就好比用导线把电器/物品连接到地面一样。
★ 相关工作
CLIP:从自然语言监督中学习可迁移的视觉模型
ALIGN:基于噪声文本监督的视觉和视觉语言表示学习
ConVIRT:从自然配对的图像和文本数据中对比学习医学视觉表示
Swin Transformer:基于移动窗口的分层视觉Transformer
★ 论文故事
视觉识别模型通常被训练成预测一组固定的预先确定的对象类别,这限制了它们在实际应用中的可用性,因为需要额外的标注数据来泛化到新的视觉概念和领域。CLIP表明,可以在大量原始图像-文本对上有效地学习图像级的视觉表示。由于与图像配对的文本包含的视觉概念比任何预定义概念库都多,因此预训练的CLIP模型语义丰富,可以轻松地在零样本设置下迁移到下游的图像分类和图文检索任务上。然而,为了获得对图像的细粒度理解,正如许多任务所要求的那样,如目标检测、分割、人类姿态估计、场景理解、动作识别、视觉语言理解等,非常需要对象级视觉表示。
在本文中,我们证明了“短语关联”(Phrase Grounding,识别句子中短语和图像中对象/区域之间细粒度对应关系的任务)是一项有效且可扩展的预训练任务,可以学习对象级、语言感知和语义丰富的视觉表示,并提出了语言-图像关联预训练模型GLIP。
我们的方法将短语关联和目标检测任务统一起来,因为目标检测可以被视为上下文无关的短语关联任务,而短语关联可以被视为上下文有关的目标检测任务。我们的主要贡献如下。
通过将目标检测改为短语关联,将检测和关联统一起来。这种重新表述改变了检测模型的输入:它不仅将图像作为输入,还将描述检测任务中所有候选类别的文本提示作为输入。如图1(左)所示,COCO目标检测的文本提示是一个包含80个短语的文本字符串,即80个COCO对象类名。如图1(右)所示,任何目标检测模型都可以通过用单词-区域对齐分数替换边框分类器中的目标分类logits而转换为关联模型,这里的单词-区域对齐分数指的是,区域/边框的视觉特征与token/短语的语言特征的点积。使用语言模型计算语言特征,这为新的检测(或关联)模型提供了双编码器架构。CLIP仅在最后的点积层融合视觉和语言,与此不同的是,GLIP采用深度跨模态融合,如图1(中)所示,这对于学习高质量的语言感知视觉表示和实现优秀的迁移学习性能至关重要。检测和关联的统一还允许我们使用这两种类型的数据进行预训练,这对两项任务都有好处。在检测方面,关联数据显著丰富了视觉概念库。在关联方面,检测数据引入了更多的边界框注释,有助于训练新的SOTA短语关联模型。
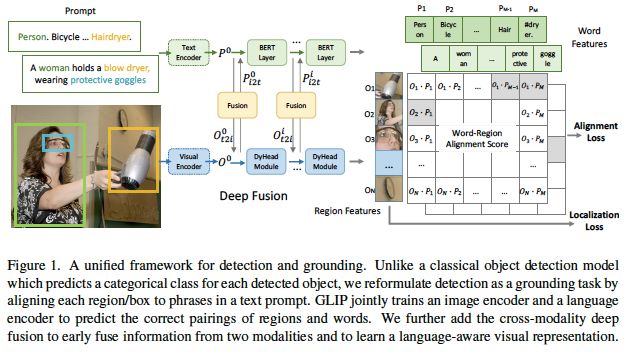
图1:用于检测和关联的统一框架。与经典的目标检测模型不同,我们通过将每个区域/边框与文本提示中的短语对齐,将检测重新定义为一项关联任务。GLIP联合训练一个图像编码器和一个语言编码器来预测区域和单词的正确配对。我们进一步将跨模态深度融合添加到两种模态的早期融合信息中,以学习语言感知的视觉表示。
使用大量的图像-文本数据扩大视觉概念。如果有一个好的关联模型(教师模型),我们可以通过自动生成大量图像-文本配对数据的关联框来增加GLIP的预训练数据,其中名词短语由NLP解析器检测。因此,我们可以在27M的关联数据上预训练GLIP-Large模型(学生模型),这些数据包括3M人工标注的细粒度数据和24M网上爬取的图像-文本对。对于24M的图像-文本对,有78.1M个高置信度的短语-边框伪注释,以及58.4M个唯一的名词短语。我们在图2中展示了两个生成框的真实示例。教师模型可以准确地定位一些可能很难理解的概念,如注射器、疫苗、美丽的蓝绿色加勒比海,甚至是抽象的单词。在这种语义丰富的数据上进行训练可以提供一个语义丰富的学生模型。相比之下,之前关于可扩展检测数据的工作根本无法预测教师模型预定义词汇表之外的概念。在这项研究中,我们表明,这种扩大关联数据的简单策略非常有效,大大提高了LVIS和13个下游检测任务的表现,尤其是在罕见类别上。当预训练的GLIP-L模型在COCO数据集上进行微调时,它在COCO val上达到了60.8 AP,在COCO test-dev上达到了61.5 AP,超过了当前以各种方式扩大目标检测数据的公开SOTA模型。
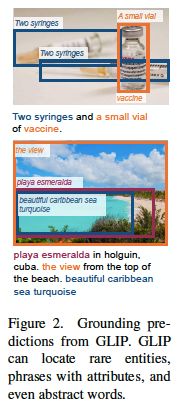
图2:GLIP的关联预测结果。GLIP可以关联稀有的实体、带有属性的短语,甚至是抽象的单词。
GLIP:“大一统”的迁移学习模型。关联重构和语义丰富的预训练有助于领域迁移。GLIP可以迁移到各种任务上,几乎不需要额外的人工注释。当在COCO和LVIS数据集上直接评估GLIP-L模型时(预训练期间没有看过COCO中的任何图像),它在COCO val和LVIS val上分别达到了49.8和26.9 AP,超过了许多有监督的基线。在13个现有的目标检测数据集上进行评估时,GLIP展示了优异的数据效率,这些数据集涵盖了细粒度物种检测、drone-view检测和ego-centric检测等场景,我们称之为“Object Detection in the Wild”(ODinW),例如,零样本的GLIP-L比在Objects365上预训练的10样本监督基线(DyHead)表现更好,而1样本的GLIP-L则与完全监督的DyHead相匹敌。此外,当特定于任务的注释可用时,可以只调优特定于任务的提示嵌入,而不调整整个模型,同时保持模型参数不变。在这种提示调优设置下,一个GLIP模型可以同时在所有下游任务上表现良好(表1),从而降低微调和部署的成本。

表1:在提示调优下,单个GLIP-L模型在14项任务上均实现了高性能。我们只对每个任务提示的嵌入进行调优,同时保持模型权重不变。
★ 模型方法
详见上文。
★ 实验结果

表2:GLIP模型变体的详细列表。
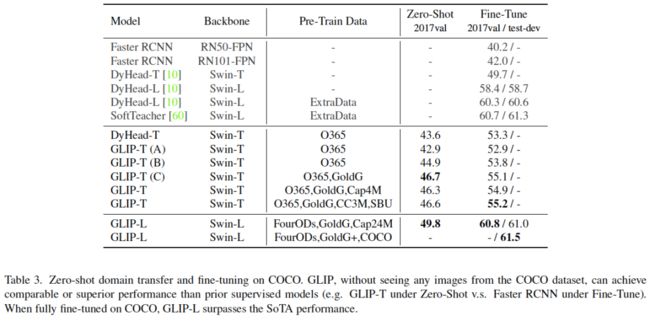
表3:在COCO数据集上的零样本迁移和微调的性能。GLIP在没有看到任何来自COCO数据集的图像的情况下,可以实现与之前的监督模型相当或更高的性能。当在COCO数据集上充分微调时,GLIP-L的性能超过了之前的SOTA水平。
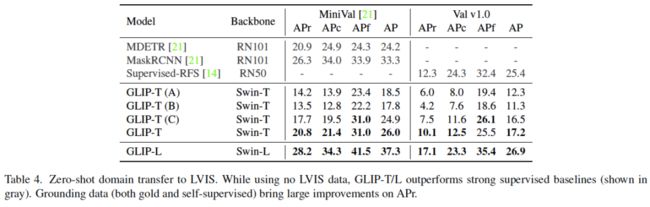
表4:零样本迁移到LVIS数据集上的性能。
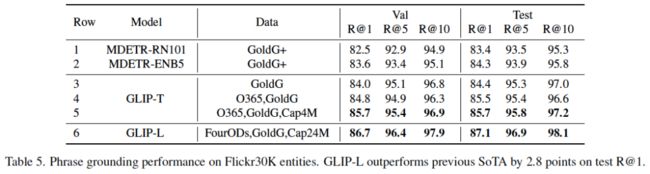
表5:在Flickr30K上的短语关联性能。GLIP-L在R@1测试结果上比之前的SOTA结果高出2.8个点。
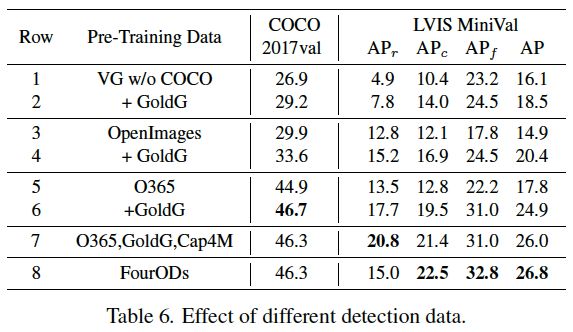
表6:不同预训练数据的影响。
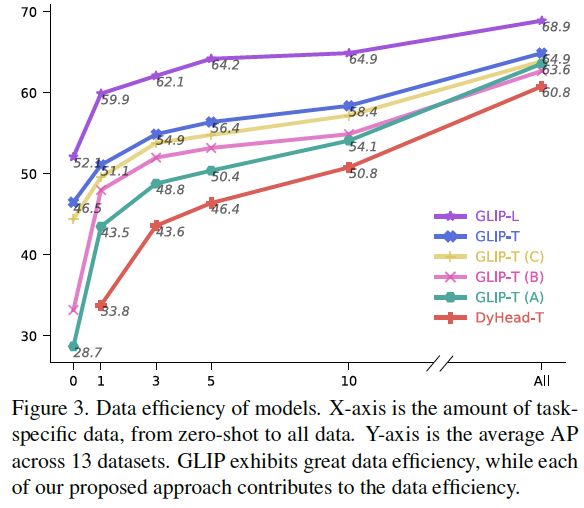
图3:GLIP和DyHead模型的数据效率。GLIP显示出了很高的数据效率。
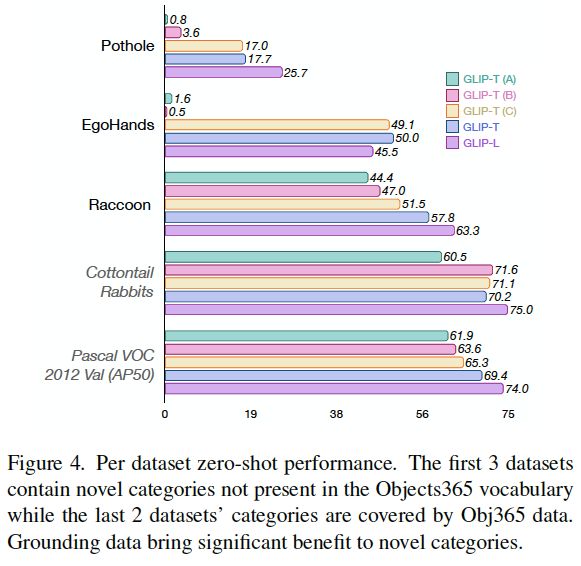
图4:GLIP在各数据集上的零样本性能。
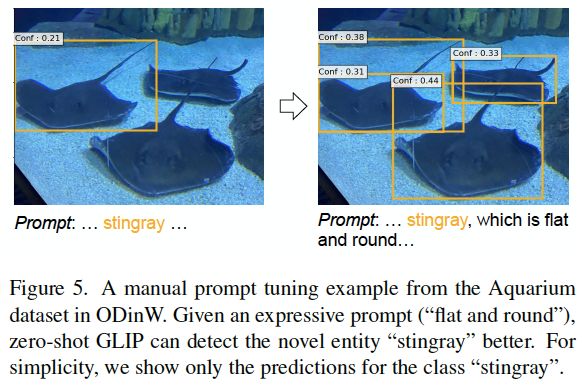
图5:来自ODinW中水族馆数据集的手动提示调优的示例。如果给出一个富有表现力的提示(“平而圆”),零样本GLIP可以更好地检测出“黄貂鱼”这个新的实体。简单起见,我们只展示了对“黄貂鱼”类的预测。
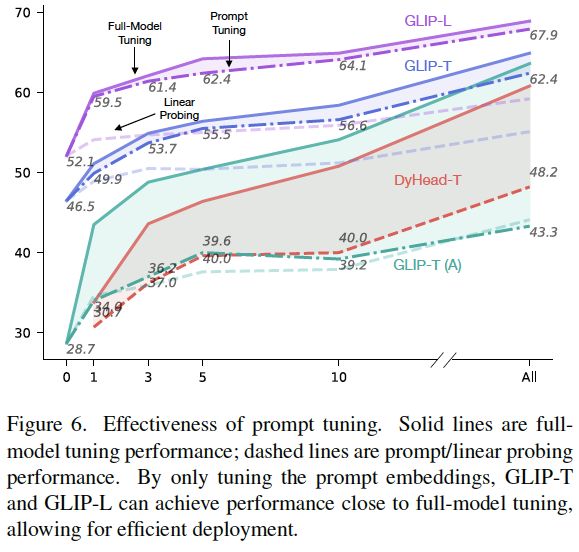
图6:提示调优的有效性。实线是全模型调优的性能,虚线是提示/线性探测的性能。通过仅调优提示嵌入,GLIP-T和GLIP-L可以实现接近全模型调优的性能,从而实现高效部署。

图7:用教师模型预测Conceptual Captions 12M数据集中的6个样本。短语和相应的边框用相同的颜色匹配。
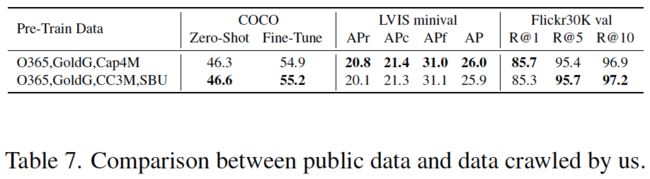
表7:公共数据和我们抓取的数据之间的比较。

表8:13个ODinW数据集的统计信息。
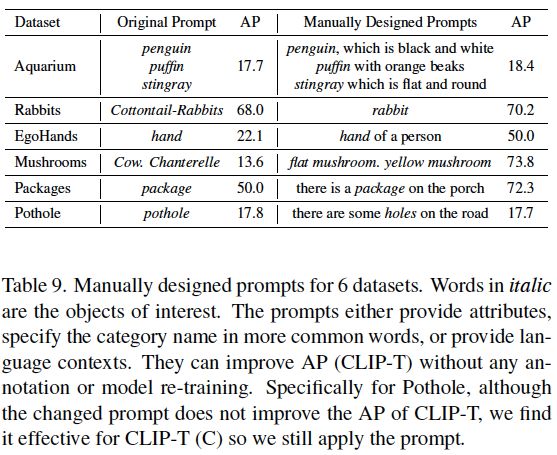
表9:手动设计6个数据集的提示。斜体字是人们感兴趣的对象。提示要么提供属性,用更常见的词指定类别名称,要么提供语言上下文。
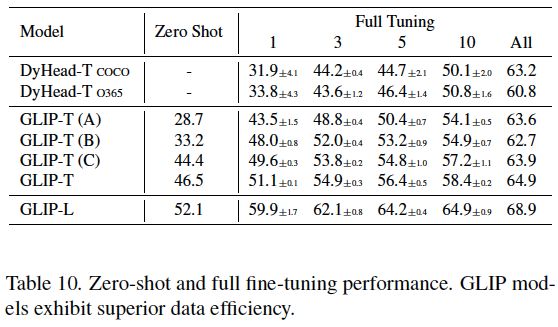
表10:GLIP、DyHead的零样本和微调的性能。GLIP模型显示出优越的数据效率。
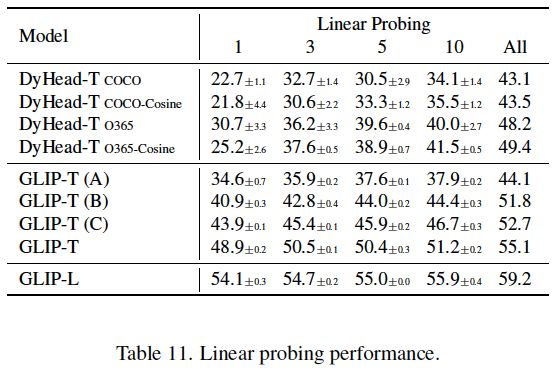
表11:GLIP的线性探测性能。
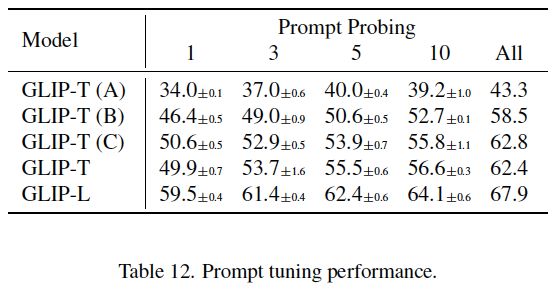
表12:GLIP的提示调优性能。

表13:GLIP在13个ODinW数据集上的零样本性能。
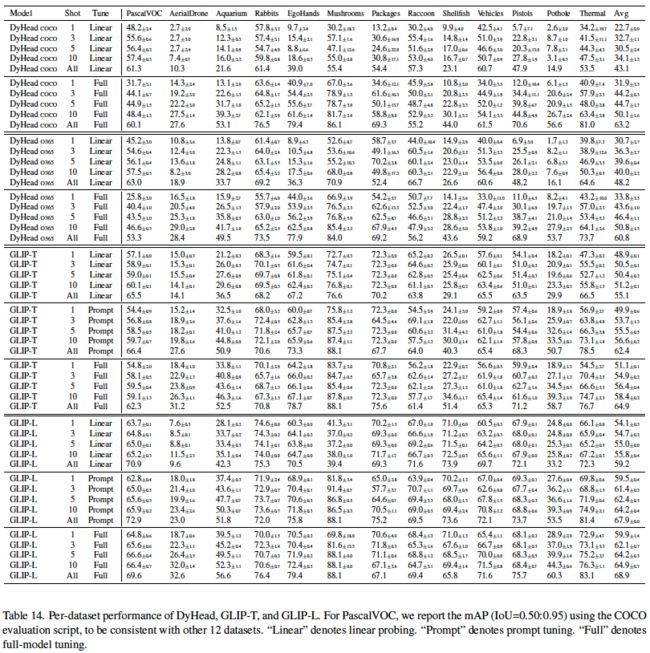
表14:DyHead、GLIP-T和GLIP-L在各数据集上的性能。“Linear”表示线性探测。“Prompt”表示提示调优。“Full”表示全模型调优。
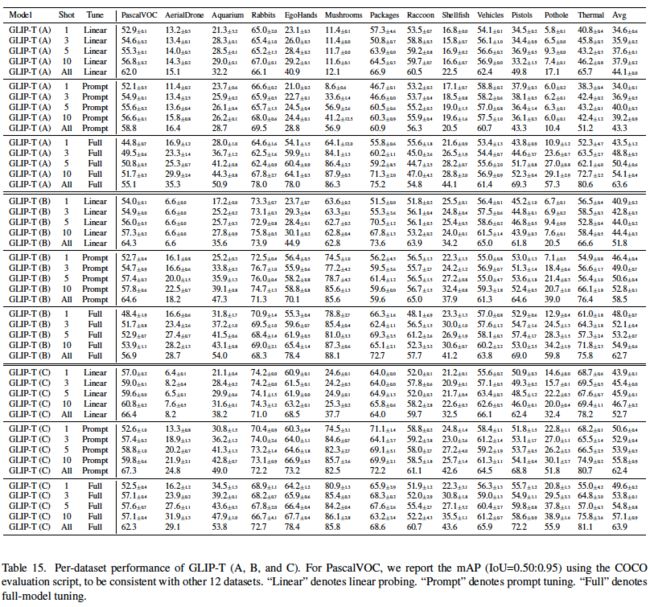
表15:GLIP-T在各数据集上的性能。“Linear”表示线性探测。“Prompt”表示提示调优。“Full”表示全模型调优。
★ 总结讨论
GLIP将目标检测和关联任务结合起来,以学习对象级、语言感知和语义丰富的视觉表示。经过预训练后,在已建立的数据集和13项下游任务上,GLIP在零样本和微调设定下显示了令人满意的结果。为了进一步了解这一问题,我们正在详细研究文本-图像数据大小对GLIP性能的影响。
多模态人工智能
为人类文明进步而努力奋斗^_^↑
欢迎关注“多模态人工智能”公众号,一起进步^_^↑