NLP学习笔记(五) 注意力机制
大家好,我是半虹,这篇文章来讲注意力机制 (Attention Mechanism) 在序列到序列模型中的应用
在上一篇文章中,我们介绍了序列到序列模型,其工作流程可以概括为以下两个步骤
首先,用编码器将输入序列编码成上下文向量,然后,用解码器将上下文向量解码成输出序列
这里所说的上下文向量,其实可以理解成输入序列的向量表示
如此以该向量作为联系,解码器就可以生成与输入序列相关的输出序列
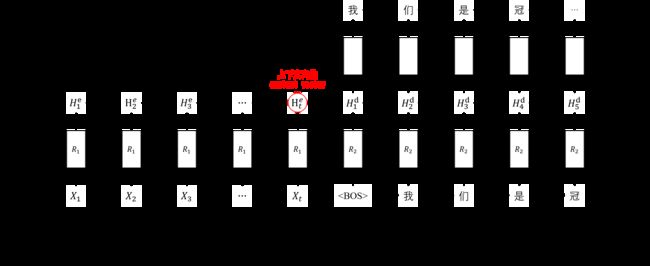
上图是基于循环神经网络的序列到序列模型示意图, R 1 R_{1} R1 是编码器, R 2 R_{2} R2 是解码器,二者都是循环神经网络
宏观上说,所有序列到序列模型的核心问题就两个:
- 编码器怎么得到上下文向量?
- 解码器怎么使用上下文向量?
序列到序列模型对上述两个问题有很多种设计方案,上图所展示的模型是一种较为基础的设计
该模型将编码器最后一步的隐状态作为上下文向量,然后用上下文向量初始化解码器的隐状态
但是,这样简单的设计会使得解码器将过多的信息压缩在隐状态中
在每一步解码的过程中,解码器的隐状态不仅需要记住当前步之前已解码的信息,还要记住输入序列的信息
我们能不能想办法减轻解码器信息压缩的情况呢?答案自然是肯定的,并且通过一个简单的改动就可以做到
那就是除了用上下文向量初始化解码器隐状态外,在每一步解码时将上下文向量作为解码器和分类层的输入
这样,解码器和分类层就能直接通过上下文向量获得输入序列的信息,使解码器隐状态需要保存的信息变少
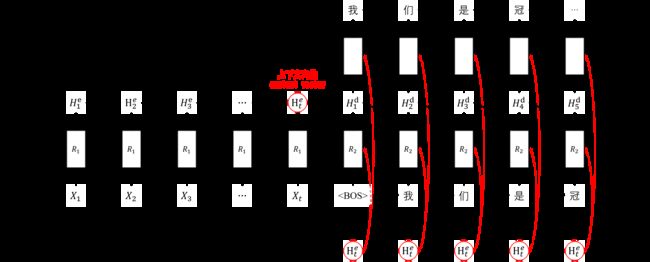
上图是改进后的序列到序列模型,该模型仍然是将编码器最后一步的隐状态作为上下文向量
不同之处在于上下文向量除了用于初始化解码器隐状态之外,还作为解码器和分类层的输入
好了,思路非常简单,在实现的时候提醒大家注意两个细节:
- 解码器和分类层在每个时间步里使用的上下文向量都是一样的
- 解码器和分类层会将上下文向量与原始输入拼接得到新的输入
然而,改进后的设计仍然无法解决编码器将过多的信息压缩在隐状态中
对于上述两种方案,编码器试图将整个输入序列的信息压缩到最后一个时间步的隐状态里面
当输入序列较长时,很容易会出现信息缺失的情况,要怎么解决呢,这就是注意力机制发挥作用的时候
使用注意力机制时:
- 编码器不再使用最后一个时间步的隐状态表示整个输入序列,而是保留序列中每个时间步的隐状态
- 解码器在每一步解码时,会动态计算当前步与输入序列所有隐状态的匹配分数,找出最相关的部分
这句话怎么理解呢?
用翻译任务来举例,假设现在我们要进行中译英,将 机器学习 翻译成 Machine Learning
当解码器在生成 Machine 时,其实应该将注意力放在输入中的 机器 两个字上
当解码器在生成 Learning 时,则是需要将注意力放在输入中的 学习 两个字上
在序列到序列模型中有两个比较经典的注意力机制,一是 Bahdanau Attention \text{Bahdanau Attention} Bahdanau Attention,二是 Luong Attention \text{Luong Attention} Luong Attention
下面我们以视频的方式直观看看这两个注意力机制的运作
Bahdanau Attention
Luong Attention
对于上述两种注意力机制,上下文向量都是动态计算的,并以不同的方式应用到解码过程
两者的不同之处如下所示:
| 不同之处 | Bahdanau Attention \text{Bahdanau Attention} Bahdanau Attention | Luong Attention \text{Luong Attention} Luong Attention |
|---|---|---|
| 上下文向量计算的输入 | 解码器上一 隐状态 编码器所有隐状态 |
解码器当前隐状态 编码器所有隐状态 |
| 解码器输入 | 当前输入 上下文向量 |
当前输入 |
| 分类层输入 | 当前隐状态 上下文向量 当前输入 |
当前隐状态 上下文向量 |
值得一提的是,虽然两者用于上下文向量计算的输入是不同的,但上下文向量的计算方式却是相似的
概括来说就是,在每一步解码时用单个解码器隐状态与所有编码器隐状态计算注意力权重后加权求和得到
公式化的表达:
- 给定所有编码器隐状态 H e = { H 1 e , H 2 e , ⋯ , H N e } H^{e} = \{H^{e}_{1},\ H^{e}_{2},\ \cdots,\ H^{e}_{N}\} He={H1e, H2e, ⋯, HNe} 以及单个解码器隐状态 H t d H^{d}_{t} Htd
- 待求为当前上下文向量 C t d C^{d}_{t} Ctd
计算步骤如下:
- 计算注意力权重分布: α i = softmax ( score ( H i e , H t d ) ) = exp ( score ( H i e , H t d ) ) ∑ j = 1 N exp ( score ( H j e , H t d ) ) \alpha_{i} = \text{softmax}(\text{score}(H^{e}_{i},\ H^{d}_{t})) = \frac{\exp{(\text{score}(H^{e}_{i},\ H^{d}_{t})})}{\sum_{j=1}^{N}{\exp({\text{score}(H^{e}_{j},\ H^{d}_{t})}})} αi=softmax(score(Hie, Htd))=∑j=1Nexp(score(Hje, Htd))exp(score(Hie, Htd))
- 计算当前上下文向量: C t d = ∑ i = 1 N α i H i e C^{d}_{t} = \sum_{i=1}^{N}{\alpha_{i} H^{e}_{i}} Ctd=∑i=1NαiHie
其中最核心的部分就是打分函数,用于计算编码器隐状态与解码器隐状态之间的匹配分数
在两种注意力机制中,对于打分函数有各自的设计,如下表所示:
| 注意力机制名称 | 打分函数名称 | 打分函数公式 |
|---|---|---|
| Bahdanau Attention \text{Bahdanau Attention} Bahdanau Attention | concat \text{concat} concat | score ( H i e , H t d ) = W b ⋅ tanh ( W a ⋅ [ H i e ; H t d ] ) \text{score}(H^{e}_{i},\ H^{d}_{t}) = W_{b} \cdot \tanh (W_{a} \cdot [H^{e}_{i};\ H^{d}_{t}]) score(Hie, Htd)=Wb⋅tanh(Wa⋅[Hie; Htd]) |
| Luong Attention \text{Luong Attention} Luong Attention | concat \text{concat} concat | score ( H i e , H t d ) = W b ⋅ tanh ( W a ⋅ [ H i e ; H t d ] ) \text{score}(H^{e}_{i},\ H^{d}_{t}) = W_{b} \cdot \tanh (W_{a} \cdot [H^{e}_{i};\ H^{d}_{t}]) score(Hie, Htd)=Wb⋅tanh(Wa⋅[Hie; Htd]) |
| Luong Attention \text{Luong Attention} Luong Attention | dot product \text{dot product} dot product | score ( H i e , H t d ) = ( H i e ) T ⋅ H t d \text{score}(H^{e}_{i},\ H^{d}_{t}) = (H^{e}_{i})^{T} \cdot H^{d}_{t} score(Hie, Htd)=(Hie)T⋅Htd |
| Luong Attention \text{Luong Attention} Luong Attention | general \text{general} general | score ( H i e , H t d ) = ( H i e ) T ⋅ W a ⋅ H t d \text{score}(H^{e}_{i},\ H^{d}_{t}) = (H^{e}_{i})^{T} \cdot W_{a} \cdot H^{d}_{t} score(Hie, Htd)=(Hie)T⋅Wa⋅Htd |