学习笔记|NLP中的注意力机制汇总
说在前面的话:
前段时间因为组会要对注意力机制做一个报告,我在收集资料的时候发现,网上很多所谓的attention总结无非最后都陷入了对transformer模型和自注意力机制的解释中,其实这并没有对所有的注意力机制类型进行一个详细的总结,这对一个初学者来说很容易陷入一个思维定势中。因此我决定深入剖析各个经典文章中所使用的Attention机制,并对他们进行一个分类总结。可以说这篇文章内容是全网最全的,应该找不到比这个更全的总结了,除了参考一些综述和网上资料,我还根据自己的理解整合并加入了一些新的内容。本文参考的文献和网上资料都会在最后部分给出。
目录
一、Attention的含义
二、Attention的可解释性
三、Attention的种类
四、Attention的网络架构及分析
五、其他Attention
六、参考文献
一、Attention的含义
-
Attention机制的原理来源于人脑中视觉系统通常是有选择性地关注事物的某些部分,而忽略掉无关紧要的部分,从而快速筛选出重要的信息
-
Attention的计算本质是根据事物之间的关系进行线性加权得到新的表示,这个表示蕴含了各个事物之间的相对重要程度
-
Attention是一种思想、机制,可以用到很多模型和结构中。常见的应用领域有:机器翻译、文本生成、推荐系统、图像分割、语音识别等
-
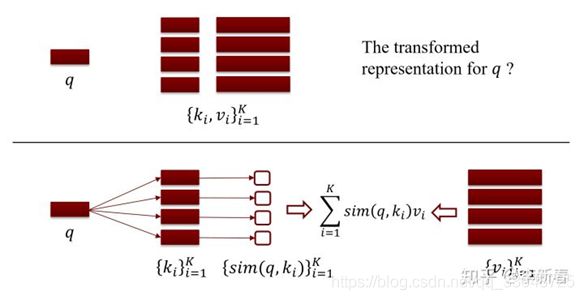
Attention的计算过程类似“检索”的过程,计算方式可以视作某种相似度计算。但与检索不同,检索最终要从检索库中取出与查询向量相似度最高的向量,而注意力计算只是通过计算查询向量与检索库中所有向量之间的相似度获得一个权重向量,进而将这个权重向量应用到原本向量(即线性加权)
假设给定一个要查询的向量表示q,以及对应的检索库![]() ,其中
,其中 是关键字
是关键字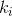 对应的评分,那么查询向量q从检索库中检索的计算过程就是:
对应的评分,那么查询向量q从检索库中检索的计算过程就是: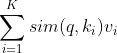 ,其中
,其中![]() 是计算查询向量q和关键字的相似度函数。
是计算查询向量q和关键字的相似度函数。
二、Attention的可解释性
自2014年Bahdanau将attention作为软对齐引入神经机器翻译以来,大量的自然语言处理工作都将其作为模型中一个提高性能的重要模块,大量的实验表明attention机制是计算高效且效果显著的。Attention的另一个好处就是,attention是解释神经模型内部工作的重要方法之一,因此为了能更好的了解其内在机理来优化模型,现在也有很多研究是针对Attention机制的可解释性的探讨,解释其为什么有效,并且提供证明,这是一个很有价值的研究方向。但是,也有学者对其提出质疑,认为attention机制并不具备可解释性。
人类注意力认知过程是选择性地专注于一件或几件事物而忽略其他事物的认知过程。而注意力机制则是模拟这一过程给予序列数据不同位置不同的权重,通过权重大小突出重要信息和抑制不相关信息。
有一些研究将attention可视化了出来,比如说在目标检测中使用attention,其权重会倾向于要检测的物体本身,在翻译或理解句子时就会把注意力集中到对句子贡献大的词语上,在语音识别中注意力权重会集中到语音频谱集中的波段。这个可视化的结果和我们人类的注意力认知过程是相符合的,因为我们会选择性地将注意力分配到显眼或重要的事物而忽略掉其他事物。

现在有一些文章研究attention是否能帮助神经网络模型可解释,但是他们得出的结论有些矛盾,比如以下这两篇,第一篇的结论是attention机制不可解释,是个黑盒子。第二篇是对第一篇不可解释论证方法的反驳,但并不是证明attention可解释。

但是追究他们论证结果差异的根源,根本原因是在于对可解释性这个定义理解的不同,而且他们的论证手段是否科学也很受争议。但是attention的可解释性大体可以分为两个。
可解释性的定义:
- Attention权重的高低应该与对应位置信息的重要程度正相关
- 高权重的输入单元对于输出结果有决定性作用
因为这些论证过程涉及很多数学知识和复杂的实验设计,所以我没有细看,了解不多。
感兴趣的同学可以自己去看这两篇文章。
不过attention机制现在是应用的越来越广了,在很多任务上都有很大的效果提升,所以在我们的研究中可以好好利用这个技巧。
三、Attention的种类
接下来是介绍attention的详细分类,主要集中于NLP领域,针对序列数据的处理。后面也会介绍一些其它领域的attention的应用。
根据目前大部分文章中所使用的attention的特点,可以从6个不同角度对Attention进行分类。
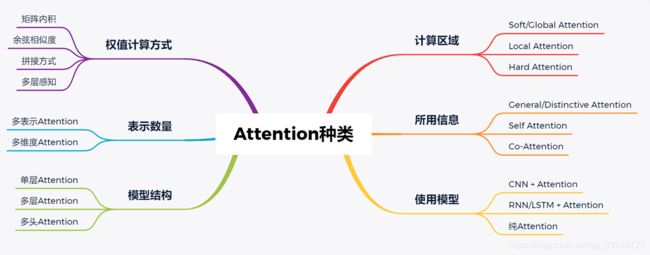
1、权重计算方式
权重计算方式也就是相似度计算。主要有以下几种:
(1)矩阵内积 
(2)余弦相似度 
(3)拼接方式(加性注意力) 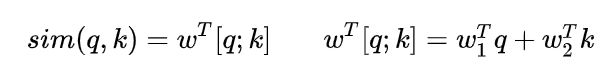
(4)多层感知 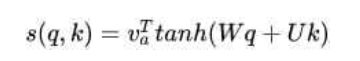
多层感知也就是MLP,在qk向量相加后经过激活函数激活再乘上一个向量。
以上所有计算方式除了qk向量,其他向量或矩阵都是需要学习的。
最常用的是1、3、4种。
2、计算区域
计算区域是指一个查询向量q在检索库中检索时,参与计算的key的数量。
(1)Soft/Global Attention
- 对所有key求权重概率,也就是说在查询的时候要计算检索库里面所有的key与查询向量q之间的相似度,是一种全局的计算方式
- 考虑了所有信息,但计算量比较大
(2)Hard Attention
- 直接精准定位到某个key,这个key的概率是1,其余key的概率全部是0
- 不可导,一般需要用强化学习的方法进行训练(或者使用gumbel softmax采样)
- 这种对齐方式要求很高,要求一步到位,如果没有正确对齐,会带来很大的影响
(3)Local Attention
- 以上两种方式的折中,对一个窗口区域进行计算
- 先用Hard方式定位到某个地方,以这个点为中心可以得到一个窗口区域,在这个小区域内用Soft方式来算Attention

大部分文章中使用的是global attention
3、所用信息
所用信息是指在计算attention时是否用到外部信息或者说是否有多个输入。
(1)General/Distinctive Attention
- 这种方式利用到了外部信息,常用于需要构建两段文本关系的任务
- query一般包含了额外信息,根据外部query对原文进行对齐
- 这种方式可用于机器翻译、图像字幕生成、语音识别等任务
(ps:对齐的意思是指在原文中找到与query相关度高的key,对齐这种说法通常在机器翻译或图像字幕生成中使用,指与要生成的词语相关度高的信息)
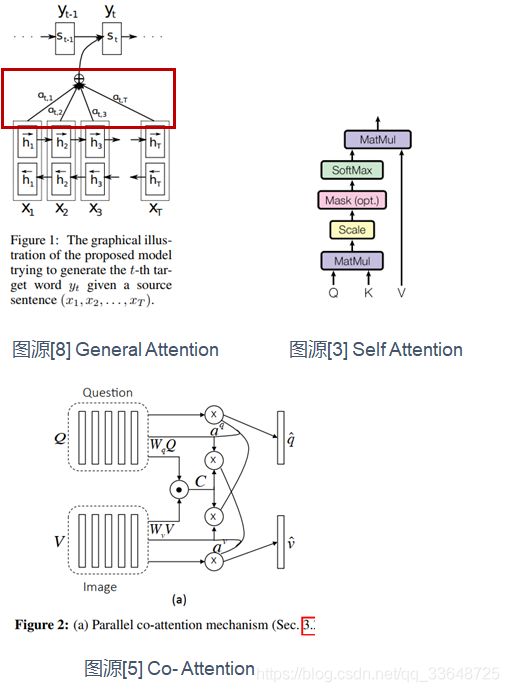
(2)Self Attention
- 这种方式只使用内部信息,key和value以及query只和输入原文有关,key=value=query
- 原文中的每个词可以跟该句子中的所有词进行Attention计算,相当于寻找原文内部的关系
- 这种方式可用于分类和推荐等任务
由于self attention不需要外部信息,所以可以应用在一些分类和推荐任务中.
(3)Co-Attention/Cross Attention
- 涉及到多个的输入(多视图/多模态),协同学习他们的注意力向量,以获得多个输入间的联系
- 可用于多模态/多视图数据分类、小样本学习等领域
这种方式与distinctive attention的区别是它对多个输入是同时处理的,而distinctive是先处理内部信息,然后外部信息使用内部信息。
4、模型结构
模型结构这个分类角度是指根据一个模型中attention的层次结构进行分类。
(1)单层Attention
- 用一个query对原文只做一次attention
- 普遍使用
(2)多层Attention
- 通常用于具有层次关系的模型
- 如文档分类,可对词向量做一次attention,接着对句向量做attention,再对文档向量做attention,层层连接
(3)多头Attention
- Transformer中所使用的multi-head attention
- 即使用多个query对原文进行了多次attention计算,再拼接起来
- 每个query都关注到原文的不同部分,相当于重复做多次单层Attention

5、表示数量
表示数量这个分类角度是从对多个embedding表示做attention还是从特征维度上做attention。
(1)多表示Attention
- 输入有多种embedding表示时,Attention可用于衡量不同embedding的重要性
- 最终得到的是embedding的weighted sum
- 这种方法可以结合各种embedding的优点,即让神经网络自己选择对下游任务效果好的embedding
这里的多种embedding表示可以指不同词嵌入方法得到的不同embedding表示,通过对这些表示计算attention从而得到效果好的词嵌入。也可以指通过多层神经网络训练后得到的各个隐层的特征表示,比如卷积神经网络,比起只使用最后一层的特征表示,将各个层的表示都利用起来可以充分利用浅层的颜色、边缘信息以及高层的抽象的语义信息,这样可以根据下游任务的特点通过注意力网络自行选择效果好的特征表示而抑制无效的特征表示。

(2)多维度Attention
- 这种attention可以用来衡量embedding向量各个维度之间的相关性
- 可在训练word/sentence/document embedding时添加一层attention层,得到的embedding向量质量更高,对下游任务的效果更好(词嵌入可预训练,或与下游任务一起训练)

6、使用的模型
使用模型是指attention可以和哪些模型结合起来使用。
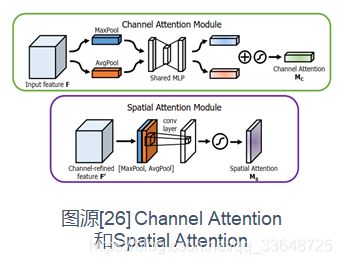
(1)CNN + Attention
其实在图像领域中卷积神经网络的概念就与attention类似,通过使用不同大小的卷积核进行卷积来模拟人脑视觉系统中的不同感受野大小,而attention机制是模拟人脑视觉系统对显眼或重要的事物给予更多的关注。那么attention在CNN中的使用常常在以下几个角度切入:
- 可以在卷积前、后或在池化层做attention代替max pooling
- Channel Attention:对通道做attention
- Spatial Attention:对空间做attention

(2)LSTM + Attention
- 为了缓解直接使用LSTM最后一个hidden state造成的信息损失问题
- 对所有hidden state进行加权,权重需要学习
- 这种方法可以关注到重要的hidden state,缓解了信息损失问题,但是会增加计算量
(3)纯Attention
- Transformer模型就是纯使用Self Attention和Multi-Head Attention来构造模型
以上从6个不同角度对attention机制进行了分类,这些机制都不是独立的,在应用中可以结合多种attention机制以达到想要的效果。接下来就介绍一些经典的网络架构,并且对所使用的attention机制进行分析。
四、Attention的网络架构及分析
1、Encoder-Decoder
首先是使用了encoder-decoder架构的经典的神经机器翻译NMT模型,这篇文章是多种attention机制的鼻祖,很多attention机制都是由这篇文章所发展而来。
- NMT模型包含三个部分,encoder, attention layer和decoder
- 主要关注他的attention layer部分,计算过程是这样的:我们要得到当前位置的单词的预测,我们现在拥有的信息是decoder的上一个输出yi-1和上一个隐状态si-1,以及encoder的所有隐状态h,我们要如何进行翻译的对齐呢?通过attention计算,也就是说通过计算decoder上一个隐状态和encoder所有隐状态的attention来对齐。计算公式就是上面三个式子。总结为右边一个式子,这个式子就是ppt一开头提到的那个attention计算公式。把decoder上一个隐状态当成查询向量q,encoder的隐状态当成k和v,通过计算qk的相似度再与v相乘得到一个context向量,这个向量可以在decoder端用来计算当前隐状态和预测值。
- 在一些文章中为了限制权值的大小,需要对权值进行归一化或缩放操作,可以使用softmax, sigmoid, tanh等函数


接下来从上一节的6个角度分析这个模型所用到的Attention机制吧。
(1)所用信息:Distictive Attention
利用了Decoder的隐状态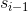 (外部信息)和Encoder的隐状态
(外部信息)和Encoder的隐状态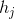 (原文信息)一起计算attention。
(原文信息)一起计算attention。
(2)计算区域:Global Attention
Encoder的每个隐状态都参与了每次解码的attention计算
(3)权重计算方式:Additive Attention/多层感知
sim(q,k)函数的计算方式为加性注意力计算
(4)使用模型:BiRNN + Attention
(5)层次结构:单层Attention
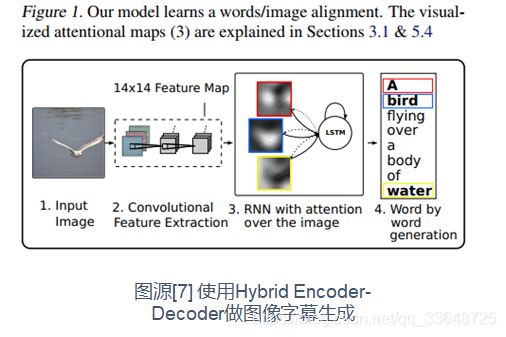
2、Hybrid Encoder-Decoder
- Attention机制可以将编码部分任意长度的输出表示变换到一个固定长度的context向量用于解码部分,从而实现编码部分和解码部分的解耦
- 因此引入Hybrid Encoder-Decoder,如Encoder可以使用CNN,Decoder使用RNN/LSTM
- 这种架构特别适用于多模态任务,例如图像字幕生成、可视问题回答、语音识别等
分析:
(1)所用信息:Co-Attention
在解码时利用Decoder的文本信息的hidden state和Encoder的图像信息的annotation state.
(2)计算区域:Soft Attention/Hard Attention
(3)权重计算方式:多层感知
(4)使用模型:CNN+LSTM+Attention
(5)层次结构:单层Attention
3、Memory Networks
- 问答机器人和聊天机器人需要从知识库中学习知识,因此这种网络的输入是一个知识库和一个查询
- End-to-End Memory Network通过使用一组memory blocks来存储知识库
- 通过计算memory block中所有知识的attention来实现查询的目的
- 这种网络可看作是注意力模型的泛化,因为它不止在单个序列上建模注意力,而是在一个包含大量序列的知识库上建模注意力

分析:
(1)所用信息:Distinctive Attention
(2)计算区域:Global Attention
(3)权重计算方式:scaled dot production
(4)使用模型:RNN+Attention
(5)层次结构:单层Attention
(6)表示数量:多表示Attention
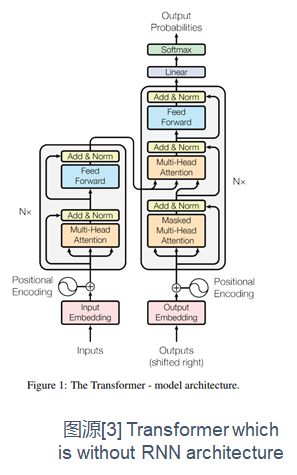
4、Network without RNNs
(1)RNN的缺点:
- RNN低效的循环结构使得序列计算非常耗时
- 只使用最后一个隐状态会造成信息丢失
(2)Transformer的特点:
- Transformer只使用self attention和multi-head attention进行计算,不嵌入任何RNN结构
- Transformer中的一个单元由Multi-Head Attention层+Position-wise FFN层组成(还分别接了residual层和归一化层),通过堆叠多个这样的单元构成Encoder和Decoder
- 在input embedding加上positional encoding以增加位置信息
- 可并行计算,计算效率和准确率大大提高
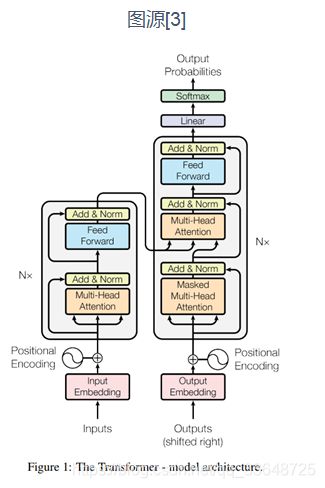
分析:
(1)所用信息:Self Attention和Distinctive Attention
编码部分是SA,解码部分是DA
(2)计算区域:Global Attention
(3)权重计算方式:scaled dot product
(4)使用模型:纯Attention
(5)层次结构:多头Attention
五、其他Attention(CV、GNN、多模态)
以上是Attention机制在NLP应用中常见的模型架构。这部分将介绍一些NLP之外的领域的Attention的应用。
1、多模态的共同注意网络
这个模型将图像和文本共同输入,分别使用Faster R-CNN和Glove+LSTM对图像和文本进行处理。获得相应特征向量后,将图像信息作为X,文本信息作为Y,一起输入到SA和GA的block里面计算attention,block有两种搭建方式,分别是stacking和encoder-decoder,经过attention block将得到两种模态信息的交互信息,再往后进行特征融合和分类。

分析:
(1)所用信息:Self Attention和Guided Attention(Distinctive Attention)
(2)计算区域:Global Attention
(3)权重计算方式:scaled dot product
(4)使用模型:纯Attention
(5)层次结构:多头Attention
2、图神经网络中的非对称注意力:GAT(Graph Attention Networks)
GAT是空域GNN的代表模型,相较于其他时域的模型,他很适合作为上手的模型。GAT的重点就是Attention,这个attention就是图中每个节点相对于其相邻节点的相互重要性。GAT的attention在理解上和其他模型的相比没有很大区别,因为GAT将图节点用投影矩阵投影到了F维,以方便后续使用神经网络处理,它的核心创新点就在于相邻节点对相互具有不一样的重要性,这个重要性可以量化,通过网络训练得出。
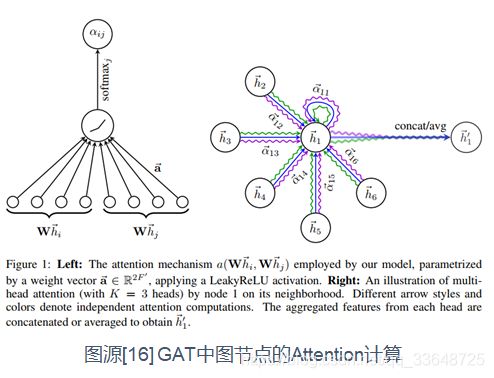

GAT中Attention计算的特点:
(1)权重计算方式:拼接方式
- 这导致
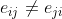 ,即相邻节点各自的注意力权重向量是不一样的,是非对称的
,即相邻节点各自的注意力权重向量是不一样的,是非对称的 - 这种非对称性在社交网络中有很直观的解释。例如,有一个大V和一个普通用户互相关注,但是,大V对于普通用户的重要性和普通用户对大V的重要性明显是不一样的
(2)计算区域:Global Attention
对当前节点的所有邻居节点都计算了attention
(3)层次结构:多头Attention
(4)使用模型:GNN + Attention
3、卷积神经网络注意力机制:SENet(Squeeze-and-Excitation Networks)


4、卷积神经网络注意力机制:CBAM(Convolutional Block Attention Module)


六、参考文献
以下是本文内容涉及到的参考文献和网上资料,有部分给出了github链接,方便大家看代码。
[1] Chaudhari S , Polatkan G , Ramanath R , et al. An Attentive Survey of Attention Models[J]. 2019.
[2] Hu D . An Introductory Survey on Attention Mechanisms in NLP Problems[J]. 2018.
[3] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS, pages 5998–6008, 2017.
https://github.com/harvardnlp/annotated-transformer
[4] Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alexander J. Smola, and Eduard H. Hovy. Hierarchical attention networks for document classification. In HLT-NAACL, 2016.
https://github.com/arunarn2/HierarchicalAttentionNetworks
[5] Jiasen Lu, Jianwei Yang, Dhruv Batra, and Devi Parikh. Hierarchical question-image co-attention for visual question answering. In NIPS, pages 289–297, 2016.
https://github.com/karunraju/VQA
[6] Thang Luong, Hieu Pham, and Christopher D. Manning. Effective approaches to attention-based neural machine translation. In EMNLP, pages 1412–1421, Lisbon, Portugal, September 2015. ACL.
https://github.com/thisisiron/nmt-attention-tf2
[7] Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio. Show, attend and tell: Neural image caption generation with visual attention. In ICML, pages 2048–2057, 2015.
https://github.com/DeepRNN/image_captioning
[8] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014.
https://github.com/Lyusungwon/nmt
[9] Douwe Kiela, Changhan Wang, and Kyunghyun Cho. Dynamic meta-embeddings for improved sentence representations. In EMNLP, pages 1466–1477, 2018
https://github.com/facebookresearch/DME
[10] Zhouhan Lin, Minwei Feng, Cicero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen Zhou, and Yoshua Bengio. A structured selfattentive sentence embedding. arXiv preprint arXiv:1703.03130, 2017.
https://github.com/yufengm/SelfAttentive
[11] Wang Y , Huang H , Feng C , et al. CSE: Conceptual Sentence Embeddings based on Attention Model[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016.
[12] Yin W , Schütze, Hinrich, Xiang B , et al. ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs[J]. Computer ence, 2015.
https://github.com/Lapis-Hong/ABCNN
[13] William Chan, Navdeep Jaitly, Quoc Le, and Oriol Vinyals. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In ICASSP, pages 4960–4964. IEEE,
2016
[14] Yu, Zhou & Yu, Jun & Cui, Yuhao & Tao, Dacheng & Tian, Qi. (2019). Deep Modular Co-Attention Networks for Visual Question Answering. 10.1109/CVPR.2019.00644.
https://github.com/MILVLG/mcan-vqa
[15] Sainbayar Sukhbaatar, Jason Weston, Rob Fergus, et al. End-to-end memory networks. In NIPS, pages 2440–2448, 2015.
https://github.com/carpedm20/MemN2N-tensorflow
[16] Velikovi P , Cucurull G , Casanova A , et al. Graph Attention Networks[J]. 2017.
https://github.com/PetarV-/GAT
[17] Zhang, Yuanyuan & Du, Jun & Wang, Zirui & Zhang, Jianshu. (2018). Attention Based Fully Convolutional Network for Speech Emotion Recognition.
[18] Jain S , Wallace B C . Attention is not Explanation[J]. 2019.
[19] Wiegreffe S , Pinter Y . Attention is not not Explanation[J]. 2019.
[20] 知乎专栏:https://zhuanlan.zhihu.com/p/106662375
[21] 知乎专栏:https://zhuanlan.zhihu.com/p/91839581
CV中的注意力机制:
[22] Jaderberg, Max & Simonyan, Karen & Zisserman, Andrew & Kavukcuoglu, Koray. (2015). Spatial Transformer Networks. Advances in Neural Information Processing Systems 28 (NIPS 2015).
[23] Hu J , Shen L , Albanie S , et al. Squeeze-and-Excitation Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017.
[24] Wang F , Jiang M , Qian C , et al. Residual Attention Network for Image Classification[J]. 2017.
[25] Mnih, Volodymyr & Heess, Nicolas & Graves, Alex & Kavukcuoglu, Koray. (2014). Recurrent Models of Visual Attention. Advances in Neural Information Processing Systems. 3.
[26] Woo S , Park J , Lee J Y , et al. CBAM: Convolutional Block Attention Module[J]. 2018.
[27] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. 2014 ECCV.
[28] https://www.jianshu.com/p/8f5c13aa19a8
[29] https://cloud.tencent.com/developer/news/247227