决策树算法原理及实现
决策树算法原理及实现
转载自:https://www.cnblogs.com/sxron/p/5471078.html
(一)认识决策树
1、决策树分类原理
决策树是通过一系列规则对数据进行分类的过程。它提供一种在什么条件下会得到什么值的类似规则的方法。决策树分为分类树和回归树两种,分类树对离散变量做决策树,回归树对连续变量做决策树。
近来的调查表明决策树也是最经常使用的数据挖掘算法,它的概念非常简单。决策树算法之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它是如何工作的。直观看上去,决策树分类器就像判断模块和终止块组成的流程图,终止块表示分类结果(也就是树的叶子)。判断模块表示对一个特征取值的判断(该特征有几个值,判断模块就有几个分支)。
如果不考虑效率等,那么样本所有特征的判断级联起来终会将某一个样本分到一个类终止块上。实际上,样本所有特征中有一些特征在分类时起到决定性作用,决策树的构造过程就是找到这些具有决定性作用的特征,根据其决定性程度来构造一个倒立的树--决定性作用最大的那个特征作为根节点,然后递归找到各分支下子数据集中次大的决定性特征,直至子数据集中所有数据都属于同一类。所以,构造决策树的过程本质上就是根据数据特征将数据集分类的递归过程,我们需要解决的第一个问题就是,当前数据集上哪个特征在划分数据分类时起决定性作用。
2、决策树的学习过程
一棵决策树的生成过程主要分为以下3个部分:
-
特征选择:特征选择是指从训练数据中众多的特征中选择一个特征作为当前节点的分裂标准,如何选择特征有着很多不同量化评估标准标准,从而衍生出不同的决策树算法。
-
决策树生成: 根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止生长。 树结构来说,递归结构是最容易理解的方式。
-
剪枝:决策树容易过拟合,一般来需要剪枝,缩小树结构规模、缓解过拟合。剪枝技术有预剪枝和后剪枝两种。
3、基于信息论的三种决策树算法
划分数据集的最大原则是:使无序的数据变的有序。如果一个训练数据中有20个特征,那么选取哪个做划分依据?这就必须采用量化的方法来判断,量化划分方法有多重,其中一项就是“信息论度量信息分类”。基于信息论的决策树算法有ID3、CART和C4.5等算法,其中C4.5和CART两种算法从ID3算法中衍生而来。
CART和C4.5支持数据特征为连续分布时的处理,主要通过使用二元切分来处理连续型变量,即求一个特定的值-分裂值:特征值大于分裂值就走左子树,或者就走右子树。这个分裂值的选取的原则是使得划分后的子树中的“混乱程度”降低,具体到C4.5和CART算法则有不同的定义方式。
ID3算法由Ross Quinlan发明,建立在“奥卡姆剃刀”的基础上:越是小型的决策树越优于大的决策树(be simple简单理论)。ID3算法中根据信息论的信息增益评估和选择特征,每次选择信息增益最大的特征做判断模块。ID3算法可用于划分标称型数据集,没有剪枝的过程,为了去除过度数据匹配的问题,可通过裁剪合并相邻的无法产生大量信息增益的叶子节点(例如设置信息增益阀值)。使用信息增益的话其实是有一个缺点,那就是它偏向于具有大量值的属性--就是说在训练集中,某个属性所取的不同值的个数越多,那么越有可能拿它来作为分裂属性,而这样做有时候是没有意义的,另外ID3不能处理连续分布的数据特征,于是就有了C4.5算法。CART算法也支持连续分布的数据特征。
C4.5是ID3的一个改进算法,继承了ID3算法的优点。C4.5算法用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足在树构造过程中进行剪枝;能够完成对连续属性的离散化处理;能够对不完整数据进行处理。C4.5算法产生的分类规则易于理解、准确率较高;但效率低,因树构造过程中,需要对数据集进行多次的顺序扫描和排序。也是因为必须多次数据集扫描,C4.5只适合于能够驻留于内存的数据集。
CART算法的全称是Classification And Regression Tree,采用的是Gini指数(选Gini指数最小的特征s)作为分裂标准,同时它也是包含后剪枝操作。ID3算法和C4.5算法虽然在对训练样本集的学习中可以尽可能多地挖掘信息,但其生成的决策树分支较大,规模较大。为了简化决策树的规模,提高生成决策树的效率,就出现了根据GINI系数来选择测试属性的决策树算法CART。
4、决策树优缺点
决策树适用于数值型和标称型(离散型数据,变量的结果只在有限目标集中取值),能够读取数据集合,提取一些列数据中蕴含的规则。在分类问题中使用决策树模型有很多的优点,决策树计算复杂度不高、便于使用、而且高效,决策树可处理具有不相关特征的数据、可很容易地构造出易于理解的规则,而规则通常易于解释和理解。决策树模型也有一些缺点,比如处理缺失数据时的困难、过度拟合以及忽略数据集中属性之间的相关性等。
(二)ID3算法的数学原理
前面已经提到C4.5和CART都是由ID3演化而来,这里就先详细阐述ID3算法,奠下基础。
1、ID3算法的信息论基础
关于决策树的信息论基础可以参考“决策树1-建模过程”
(1)信息熵
信息熵:在概率论中,信息熵给了我们一种度量不确定性的方式,是用来衡量随机变量不确定性的,熵就是信息的期望值。若待分类的事物可能划分在N类中,分别是x1,x2,……,xn,每一种取到的概率分别是P1,P2,……,Pn,那么X的熵就定义为:
 ,从定义中可知:0≤H(X)≤log(n)
,从定义中可知:0≤H(X)≤log(n)
当随机变量只取两个值时,即X的分布为 P(X=1)=p,X(X=0)=1−p,0≤p≤1则熵为:H(X)=−plog2(p)−(1−p)log2(1−p)。
熵值越高,则数据混合的种类越高,其蕴含的含义是一个变量可能的变化越多(反而跟变量具体的取值没有任何关系,只和值的种类多少以及发生概率有关),它携带的信息量就越大。熵在信息论中是一个非常重要的概念,很多机器学习的算法都会利用到这个概念。
(2)条件熵
假设有随机变量(X,Y),其联合概率分布为:P(X=xi,Y=yi)=pij,i=1,2,⋯,n;j=1,2,⋯,m
则条件熵(H(Y∣X))表示在已知随机变量X的条件下随机变量Y的不确定性,其定义为X在给定条件下Y的条件概率分布的熵对X的数学期望:

(3)信息增益
信息增益(information gain)表示得知特征X的信息后,而使得Y的不确定性减少的程度。定义为:

2、ID3算法推导
(1)分类系统信息熵
假设一个分类系统的样本空间(D,Y),D表示样本(有m个特征),Y表示n个类别,可能的取值是C1,C2,...,Cn。每一个类别出现的概率是P(C1),P(C2),...,P(Cn)。该分类系统的熵为:

离散分布中,类别Ci出现的概率P(Ci),通过该类别出现的次数除去样本总数即可得到。对于连续分布,常需要分块做离散化处理获得。
(2)条件熵
根据条件熵的定义,分类系统中的条件熵指的是当样本的某一特征X固定时的信息熵。由于该特征X可能的取值会有(x1,x2,……,xn),当计算条件熵而需要把它固定的时候,每一种可能都要固定一下,然后求统计期望。
因此样本特征X取值为xi的概率是Pi,该特征被固定为值xi时的条件信息熵就是H(C|X=xi),那么
H(C|X)就是分类系统中特征X被固定时的条件熵(X=(x1,x2,……,xn)):
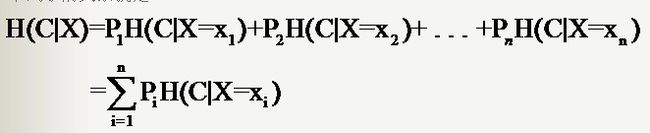
若是样本的该特征只有两个值(x1 = 0,x2=1)对应(出现,不出现),如文本分类中某一个单词的出现与否。那么对于特征二值的情况,我们用T代表特征,用t代表T出现, 表示该特征出现。那么:
表示该特征出现。那么:

与前面条件熵的公式对比一下,P(t)就是T出现的概率,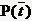 就是T不出现的概率。结合信息熵的计算公式,可得:
就是T不出现的概率。结合信息熵的计算公式,可得:


特征T出现的概率P(t),只要用出现过T的样本数除以总样本数就可以了;P(Ci|t)表示出现T的时候,类别Ci出现的概率,只要用出现了T并且属于类别Ci的样本数除以出现了T的样本数就得到了。
(3)信息增益
根据信息增益的公式,分类系统中特征X的信息增益就是:Gain(D, X) = H(C)-H(C|X)
信息增益是针对一个一个的特征而言的,就是看一个特征X,系统有它和没它的时候信息量各是多少,两者的差值就是这个特征给系统带来的信息增益。每次选取特征的过程都是通过计算每个特征值划分数据集后的信息增益,然后选取信息增益最高的特征。
对于特征取值为二值的情况,特征T给系统带来的信息增益就可以写成系统原本的熵与固定特征T后的条件熵之差:

(4)经过上述一轮信息增益计算后会得到一个特征作为决策树的根节点,该特征有几个取值,根节点就会有几个分支,每一个分支都会产生一个新的数据子集Dk,余下的递归过程就是对每个Dk再重复上述过程,直至子数据集都属于同一类。
在决策树构造过程中可能会出现这种情况:所有特征都作为分裂特征用光了,但子集还不是纯净集(集合内的元素不属于同一类别)。在这种情况下,由于没有更多信息可以使用了,一般对这些子集进行“多数表决”,即使用此子集中出现次数最多的类别作为此节点类别,然后将此节点作为叶子节点。
(三)C4.5算法
1、信息增益比选择最佳特征
以信息增益进行分类决策时,存在偏向于取值较多的特征的问题。于是为了解决这个问题人们有开发了基于信息增益比的分类决策方法,也就是C4.5。C4.5与ID3都是利用贪心算法进行求解,不同的是分类决策的依据不同。
因此,C4.5算法在结构与递归上与ID3完全相同,区别就在于选取决断特征时选择信息增益比最大的。
信息增益比率度量是用ID3算法中的的增益度量Gain(D,X)和分裂信息度量SplitInformation(D,X)来共同定义的。分裂信息度量SplitInformation(D,X)就相当于特征X(取值为x1,x2,……,xn,各自的概率为P1,P2,...,Pn,Pk就是样本空间中特征X取值为xk的数量除上该样本空间总数)的熵。
SplitInformation(D,X) = -P1 log2(P1)-P2 log2(P)-,...,-Pn log2(Pn)
GainRatio(D,X) = Gain(D,X)/SplitInformation(D,X)
在ID3中用信息增益选择属性时偏向于选择分枝比较多的属性值,即取值多的属性,在C4.5中由于除以SplitInformation(D,X)=H(X),可以削弱这种作用。
2、处理连续数值型特征
C4.5既可以处理离散型属性,也可以处理连续性属性。在选择某节点上的分枝属性时,对于离散型描述属性,C4.5的处理方法与ID3相同。对于连续分布的特征,其处理方法是:
先把连续属性转换为离散属性再进行处理。虽然本质上属性的取值是连续的,但对于有限的采样数据它是离散的,如果有N条样本,那么我们有N-1种离散化的方法:<=vj的分到左子树,>vj的分到右子树。计算这N-1种情况下最大的信息增益率。另外,对于连续属性先进行排序(升序),只有在决策属性(即分类发生了变化)发生改变的地方才需要切开,这可以显著减少运算量。经证明,在决定连续特征的分界点时采用增益这个指标(因为若采用增益率,splittedinfo影响分裂点信息度量准确性,若某分界点恰好将连续特征分成数目相等的两部分时其抑制作用最大),而选择属性的时候才使用增益率这个指标能选择出最佳分类特征。
在C4.5中,对连续属性的处理如下:
1、对特征的取值进行升序排序
2、两个特征取值之间的中点作为可能的分裂点,将数据集分成两部分,计算每个可能的分裂点的信息增益(InforGain)。优化算法就是只计算分类属性发生改变的那些特征取值。
3、选择修正后信息增益(InforGain)最大的分裂点作为该特征的最佳分裂点
4、计算最佳分裂点的信息增益率(Gain Ratio)作为特征的Gain Ratio。注意,此处需对最佳分裂点的信息增益进行修正:减去log2(N-1)/|D|(N是连续特征的取值个数,D是训练数据数目,此修正的原因在于:当离散属性和连续属性并存时,C4.5算法倾向于选择连续特征做最佳树分裂点)
3、叶子裁剪
分析分类回归树的递归建树过程,不难发现它实质上存在着一个数据过度拟合问题。在决策树构造时,由于训练数据中的噪音或孤立点,许多分枝反映的是训练数据中的异常,使用这样的判定树对类别未知的数据进行分类,分类的准确性不高。因此试图检测和减去这样的分支,检测和减去这些分支的过程被称为树剪枝。树剪枝方法用于处理过分适应数据问题。通常,这种方法使用统计度量,减去最不可靠的分支,这将导致较快的分类,提高树独立于训练数据正确分类的能力。
决策树常用的剪枝常用的简直方法有两种:预剪枝(Pre-Pruning)和后剪枝(Post-Pruning)。预剪枝是根据一些原则及早的停止树增长,如树的深度达到用户所要的深度、节点中样本个数少于用户指定个数、不纯度指标下降的最大幅度小于用户指定的幅度等。预剪枝的核心问题是如何事先指定树的最大深度,如果设置的最大深度不恰当,那么将会导致过于限制树的生长,使决策树的表达式规则趋于一般,不能更好地对新数据集进行分类和预测。除了事先限定决策树的最大深度之外,还有另外一个方法来实现预剪枝操作,那就是采用检验技术对当前结点对应的样本集合进行检验,如果该样本集合的样本数量已小于事先指定的最小允许值,那么停止该结点的继续生长,并将该结点变为叶子结点,否则可以继续扩展该结点。
后剪枝则是通过在完全生长的树上剪去分枝实现的,通过删除节点的分支来剪去树节点,可以使用的后剪枝方法有多种,比如:代价复杂性剪枝、最小误差剪枝、悲观误差剪枝等等。后剪枝操作是一个边修剪边检验的过程,一般规则标准是:在决策树的不断剪枝操作过程中,将原样本集合或新数据集合作为测试数据,检验决策树对测试数据的预测精度,并计算出相应的错误率,如果剪掉某个子树后的决策树对测试数据的预测精度或其他测度不降低,那么剪掉该子树。
(四)决策树python版实现
训练集:
+ View Code
测试集:
| 1 2 3 4 5 6 7 |
|
code:

1 #!/usr/bin/python
2 import sys
3 import copy
4 import math
5 import getopt
6
7 def usage():
8 print '''Help Information:
9 -h, --help: show help information;
10 -r, --train: train file;
11 -t, --test: test file;
12 '''
13
14 def getparamenter():
15 try:
16 opts, args = getopt.getopt(sys.argv[1:], "hr:t:k:", ["help", "train=","test=","kst="])
17 except getopt.GetoptError, err:
18 print str(err)
19 usage()
20 sys.exit(1)
21
22 sys.stderr.write("\ntrain.py : a python script for perception training.\n")
23 sys.stderr.write("Copyright 2016 sxron, search, Sogou. \n")
24 sys.stderr.write("Email: [email protected] \n\n")
25
26 train = ''
27 test = ''
28 for i, f in opts:
29 if i in ("-h", "--help"):
30 usage()
31 sys.exit(1)
32 elif i in ("-r", "--train"):
33 train = f
34 elif i in ("-t", "--test"):
35 test = f
36 else:
37 assert False, "unknown option"
38
39 print "start trian parameter \ttrain:%s\ttest:%s" % (train,test)
40
41 return train,test
42
43 def loaddata(file):
44 fin = open(file,'r')
45 data = []
46 while 1:
47 dataline = []
48 line = fin.readline()
49 if not line:
50 break
51 ts = line.strip().split('\t')
52 for temp in ts:
53 dataline.append(temp.strip())
54 data.append(dataline)
55 return data
56
57 def majorityCnt(classList):
58 classCnt = {}
59 for cls in classList:
60 if not classCnt.has_key(cls):
61 classCnt[cls] = 0
62 classCnt[cls] += 1
63
64 SortClassCnt = sorted(classCnt.iteritems(),key=lambda d:d[1],reverse=True)
65 return SortClassCnt[0][0]
66
67 def calcShannonEnt(trainData):
68 numEntries = len(trainData)
69 labelDic = {}
70 for trainLine in trainData:
71 currentLabel = trainLine[-1]
72 if not labelDic.has_key(currentLabel):
73 labelDic[currentLabel] = 0
74 labelDic[currentLabel] += 1
75
76 shannonEnt = 0.0
77 for key,value in labelDic.items():
78 prob = float(value)/numEntries
79 shannonEnt -= prob * math.log(prob,2)
80 return shannonEnt
81
82 def splitData(trainData,index,value):
83 subData = []
84 for trainLine in trainData:
85 if trainLine[index]==value:
86 reducedFeatVec = []
87 for i in range(0,len(trainLine),1):
88 if i==index:
89 continue
90 reducedFeatVec.append(trainLine[i])
91 subData.append(reducedFeatVec)
92 return subData
93
94 def chooseBestFeature(trainData):
95 numFeatures = len(trainData[0])-1
96 baseEntropy = calcShannonEnt(trainData)
97 bestInfoGain = 0.0
98 bestFeature = -1
99 for i in range(0,numFeatures,1):
100 currentFeature = [temp[i] for temp in trainData]
101 uniqueValues = set(currentFeature)
102 newEntropy = 0.0
103 splitInfo = 0.0
104 for value in uniqueValues:
105 subData = splitData(trainData,i,value)
106 prob = float(len(subData))/len(trainData)
107 newEntropy += prob * calcShannonEnt(subData)
108 splitInfo -= prob * math.log(prob,2)
109 infoGain = (baseEntropy - newEntropy) / splitInfo
110 if infoGain > bestInfoGain :
111 bestInfoGain = infoGain
112 bestFeature = i
113 return bestFeature
114
115 def CreateTree(trainData):
116 classList = [temp[-1] for temp in trainData]
117 classListSet = set(classList)
118 if len(classListSet)==1:
119 return classList[0]
120 if len(trainData[0])==1:
121 return majorityCnt(classList)
122
123 bestFeature = chooseBestFeature(trainData)
124 myTree = {bestFeature:{}}
125 featureValues = [example[bestFeature] for example in trainData]
126 uniqueValues = set(featureValues)
127 for value in uniqueValues:
128 myTree[bestFeature][value] = CreateTree(splitData(trainData, bestFeature, value))
129 return myTree
130
131 def classify(testData,dTrees):
132 index = int(dTrees.keys()[0])
133 secondDict = dTrees[index]
134 testValue = testData[index]
135 for key in secondDict.keys():
136 if testValue==key:
137 if type(secondDict[key]).__name__=='dict':
138 secondTest = copy.deepcopy(testData)
139 del secondTest[index]
140 classLabel = classify(secondTest,secondDict[key])
141 else:
142 classLabel = secondDict[key]
143 return classLabel
144
145 def TestFunc(testData,dTrees):
146 for temp in testData:
147 classLabel = classify(temp,dTrees)
148 print "%s\t%s" % (temp,classLabel)
149
150 def main():
151 #set parameter
152 train,test = getparamenter()
153
154 #load train data
155 trainData = loaddata(train)
156 testData = loaddata(test)
157
158 #create Decision Tree
159 dTrees = CreateTree(trainData)
160 print dTrees
161
162 #test Decision Tree
163 TestFunc(testData,dTrees)
164
165 if __name__=="__main__":
166 main()