END-TO-END NEURAL NETWORK BASED AUTOMATED SPEECH SCORING 翻译
端到端语音评分神经网络
-
- Abstract
- Introduction
- Previous research
- Deep Learning Based Scoring Models
-
- CNN based scoring model
- BD-LSTM based scoring model
- BD-LSTM attention scoring model
- Experiments
-
- Databases
- Conventional model
- Deep learning based models
- Results
- Conclusion
Abstract
设计了包含神经网络在内的端到端评分系统,能够自动从语言学与声学两大维度提取有用的特征。
Introduction
以前研究ASR(automatic speech recognition)用了很多CAPT(computer aided pronunciation training)的方法。基本都是用语音处理技术,韵律分析,自然语言处理技术等手动提取特征来分析。然而手动提取特征很难提取出最work的特征。后来又有人尝试用神经网络来自动学习获得最work的特征。基于此,也可以直接设计端到端的神经网络来直接给音频打分。
Previous research
打分的对象是英语的初学者,主要是从“流畅度”,“音调”,“词意”等方面评估。使用神经网络构造AM(acoustic models)也有很多,譬如DBN(deep belief network),HMM(hidden Markov models)。此前也有人使用端到端的网络来自动给文章打分,他们使用双向的RNN来学习特征。在ASAP数据集上,这些网络的效果比使用手动提取的特征(word,part of speech n-grams,phrase-structure)效果更好。还有人利用CNN+RNN混合模型来评分。CNN分析局部文本,RNN分析较大段上下文的信息。类比文章打分,也有人在语音识别上面使用类似的网络,利用频谱和韵律学测量,使用双向RNN来学习特征,但是有效性还没有被充分验证。我们构造了新的端到端模型,使用语言学特征分辨单词,使用声学特征来评分。
Deep Learning Based Scoring Models
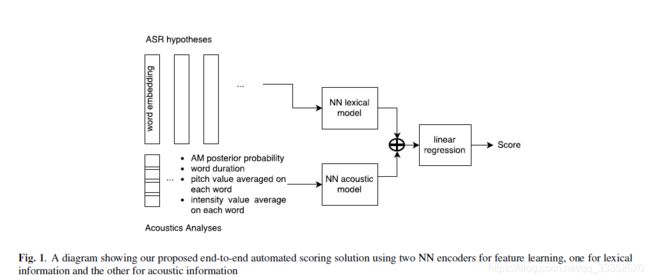
上图就是使用的模型。用两个基于神经网络的模型来学习特征,对这些特征线性使用线性回归模型来预测分数。
在语言学模型中,使用单词嵌入层(word embedding layer)将待识别的单词转化为张量(tensor).在声学模型中,使用了四种度量:1.后验概率 2.单词时长 3.音高(pitch)均值 4. 响度(intensity)均值。在两个model中使用了三种网络结构:1.一维CNN 2.基于LSTM的BD-RNN(Bi-Directional RNN using Long Short-Time Memory cells) 3.使用attention weighting scheme的BD-LSTM。
CNN based scoring model

a中,在input层之后,加入dropout层,之后连接一个全卷积层(卷积核大小为 c o n v s i z e conv_{size} convsize-1, c o n v s i z e conv_{size} convsize, c o n v s i z e conv_{size} convsize+1以获得不同大小的感受野)。CNN后加入一个max-over-time池化层,生成的 3 ∗ c o n v n 3*conv_n 3∗convn的编码向量(encoded vector)。然后又经过一个dropout层,最终输出送入线性回归层。
BD-LSTM based scoring model
RNN模型处理的是输入的序列数据,通过递归调用迁移函数得到hidden state向量 h t h_t ht,在时间节点t下, h t h_t ht是否激活由当前输入 x t x_t xt和之前的hidden state h t − 1 h_{t-1} ht−1决定。
h t = f ( h t − 1 , x t ) \begin{aligned} h_t=f(h_{t-1},x_t) \end{aligned} ht=f(ht−1,xt)
通常来说,RNN模型在最后最有一个时间节点T时生成新的大小的向量 h T h_T hT,然后将 h T h_T hT作为下一层的输入。但是仅使用RNN可能会导致梯度消失或者梯度爆炸(exploding or vanishing gradient),也就是训练的时候梯度会指数增长或指数衰减。引入LSTM可以解决这个问题,它可以使RNN在实践中更有效。因此我们的模型中也使用了LSTM RNN模型。
LSTM单元可以看做随时间变化的向量的集合( R d R^d Rd)。其中包括:输入门 i t i_t it,遗忘门 f t f_t ft,输出门 o t o_t ot,记忆单元 c t c_t ct以及隐藏层 h t h_t ht.每一个时间节点,LSTM使用隐藏层向量h以及记忆单元向量c来控制数据更新以及输出。
i t = σ ( W i X t + U i h t − 1 + V i C t − 1 ) f t = σ ( W f X t + U f h t − 1 + V f C t − 1 ) o t = σ ( W o X t + U o h t − 1 + V o C t ) c t = f t ⊙ c t − 1 + i t ⊙ t a n h ( W c X t + U c h t − 1 ) h t = o t ⊙ t a n h ( c t ) \begin{aligned} i_t=\sigma(W_iX_t+U_ih_{t-1}+V_iC_{t-1})\\ f_t=\sigma(W_fX_t+U_fh_{t-1}+V_fC_{t-1})\\ o_t=\sigma(W_oX_t+U_oh_{t-1}+V_oC_{t})\\ c_t=f_t\odot c_{t-1}+i_t \odot tanh(W_cX_t+U_ch_{t-1})\\ h_t=o_t \odot tanh(c_t) \end{aligned} it=σ(WiXt+Uiht−1+ViCt−1)ft=σ(WfXt+Ufht−1+VfCt−1)ot=σ(WoXt+Uoht−1+VoCt)ct=ft⊙ct−1+it⊙tanh(WcXt+Ucht−1)ht=ot⊙tanh(ct)
这里面单词嵌入向量 X t X_t Xt是时间节点t的输入, σ \sigma σ是sigmoid函数, ⊙ \odot ⊙代表点乘。遗忘门 f t f_t ft控制的是储存在记忆单元里的信息会擦除多少,输入门 i t i_t it控制的是每个单元更新的程度,输出门 o t o_t ot控制的是内部记忆单元信息的输出多少。
本论文中使用的是使用LSTM的BD RNN网络。双向的网络可以利用好之前的输入与之后的输入,时刻t的隐藏层的向量由 L S T M d i m c u e LSTM^{cue}_{dim} LSTMdimcue两个维度连接在一起。这里的cue既可以是语言学(lexical)信息,也可以是声学(acoustical)信息。此外,在BD RNN前后各有一个dropout层。
BD-LSTM attention scoring model
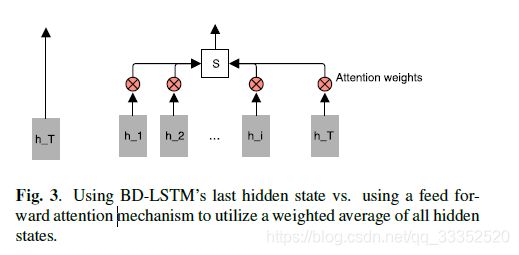
c部分使用的是带attention的BD LSTM模型。这种模型在NLP中十分有效。attention模型被放在BD RNN与其后的dropout之间。在单纯的LSTM中,决定最终输出的知识最后一个hidden状态( h T h_T hT),这就意味着前面的信息没有用上。为了克服这个限制,构造了一个简单的前馈网络模型,将之前的hidden state加权构造新的向量S。
e t = a ( h t ) , α t = e x p ( e t ) ∑ k = 1 T e x p ( e k ) , S = ∑ t = 1 T a t ∗ h t e_t=a(h_t),\alpha_t=\frac{exp(e_t)}{\sum_{k=1}^Texp(e_k)},S=\sum_{t=1}^Ta_t*h_t et=a(ht),αt=∑k=1Texp(ek)exp(et),S=∑t=1Tat∗ht
函数 a ( h t ) a(h_t) a(ht)是由 h t h_t ht决定的函数。简单的前馈网络可以看做是对输入序列自适应加权平均生成一个向量S。具体的流程如下
Experiments
Databases
选取2930个语音片段作为训练集,731个语音做验证集,1827个测试集。这些语音的打分区间是[1,4]。
Conventional model
利用SpeechRater提取特征,包括:频率,韵律,声调,重读,发音,语法,词汇。下表是这些特征的简介。

使用系数相关法在训练集上分析这些特征以及人工标注的分数之间的关系。使用了三种回归方法:Random Forest (RF), Gradient Boosting Tree (GBT), Support Vector Regression (SVR)。利用SKLL toolkit使用5倍交叉验证来确定模型的超参数。
Deep learning based models
使用Keras Python包,利用预先训练好的Glo Ve(Global Vectors for Word Representation) 词嵌入模型,嵌入向量维度设置为300。如果在Glo Ve中找不到该单词则所有参数默认设置为0.这些词向量在训练时也会微调。在声学模型中,利用Kaldi ASR的输出获得后验概率以及时长,使用Praat获取pitch(音高)以及intensity(强度)。训练网络的时候,使用Adam优化器,并且随机选取10%的训练数据early stopping来避免过拟合。使用Hyperopt Python包中的Tree Parzen Estimation (TPE) method来调整网络的超参数。训练平台是Nvidia Titan X GPU显卡。迭代100次之后,得出最佳参数.CNN中: c o n v s i z e = 4 conv_{size}=4 convsize=4(卷积核大小为3 4 5), c o n v n = 100 conv_n=100 convn=100, d p c n n 1 = 0.25 dp_{cnn1}=0.25 dpcnn1=0.25, d p c n n 2 = 0.5 dp_{cnn2}=0.5 dpcnn2=0.5。LSTM中: L S T M d i m l e x = 128 LSTM_{dim}^{lex}=128 LSTMdimlex=128, L S T M d i m a c = 32 LSTM_{dim}^{ac}=32 LSTMdimac=32, d p L S T M 1 = 0.25 dp_{LSTM1}=0.25 dpLSTM1=0.25, d p L S T M 2 = 0.5 dp_{LSTM2}=0.5 dpLSTM2=0.5。
Results

第一列是不同的网络输出,分别是基于语音特征的Conventional model,自行设计的CNN,BD-LSTM,带attention的BD-LSTM。第二列是生成的分数与人工标注分数的相关系数。不难看出,带权重的BD LSTM效果最好。这也意味着,我们需要把重点放在整段语音信号的特殊部位上,而不是对语音信号整体分析。
此外,由于使用了word embedding representations(词嵌入向量),这种表示方法本身就是优于n-grams。所以性能的提升也可能是来自于数据信息更多以及网络的结构更好。
Conclusion
设计的CNN从相关系数这个角度看,和使用人工计算的特征以及GBT回归的模型效果相近。而BD-LSTM效果更佳。未来可以尝试使用更复杂的网络来提升性能。