PoseGait:A model-based gait recognition method with body pose and human prior knowledge
Related work
-
基于外观的识别方法:
常见的输入数据形式最常见的是GEI。对GEI的处理方式一般为:
- 1)从视频中提取人体轮廓;
- 2)通过轮廓对齐和平均计算步态能量图像GEI;
- 3)然后计算两个GEIs之间的相似关系
也有直接使用剪影的方法,如Gaitset。
但是基于外观的识别方法主要的挑战是 角度 / 载荷 / 衣物 / 遮挡 等,它们会改变人的轮廓。
- 基于模型的方法
先建立人体的模型,根据输入数据得到模型参数,而后对模型参数变化进行分类。
难点在人体模型的定位精度以及计算量。
对人体模型的抽象方式和特征表达:
- [1] by Nixon 一个简单的棍模型来模拟腿,然后用一个清晰的钟摆运动来模拟腿在走路时的运动。将频率分量作为步态特征进行识别。
- Wang et al. [3] 认为关节角度的时域变化可以用于识别。提出多连接刚体模型,将刚体分为14个部分,每个部分通过一个关节连接。
- Feng等人 [12] 从人体关节提取时间特征,使用从RGB图像而非剪影中提取的人体关节热图来描述人体姿态
- Kastanio- tis等人[13] 使用来自低成本Kinect传感器的骨架数据。但是监控常见的还是RGB图像
PoseGait
认为3D的姿态信息比轮廓信息维度更低且更加紧凑。
使用了四种特征(3D姿态+关节角度+肢体长度+关节动态,其中后三种是handcrafted),拼接之后作为输入数据(在输入之前拼接)。
-
人体姿势特征
图片是2D的,所以进行特征点定位和姿态估计的时候,先得到2D的模型
1.二维模型的获取
文章使用的是OpenPose [6] .它可以从二维的图片/视频中得到18个关节点:
鼻、颈以及左右的肩、肘、腕、髋、膝、踝、眼、耳

为了防止目标与摄像机距离对结果的影响,会进行归一化:
- 颈部和臀部之间的距离被视为单位长度。
- 臀部的位置是在左臀点和右臀点的中心。
- 颈部位于平面坐标系的原点。
换算方法:

2. 三维模型的获取
当视图被改变时,2D的姿态也会发生巨大的变化。所以它对试点的变化是不稳健的。解决方法是从二维姿态来估计三维姿态。[18]的独特优势在于它可以从单幅图像中估计出三维姿态,特别是通过人体约束得到的二维姿态。
2维向3维的转化方法:在[18]中,输入数据应该是14个关节的位置。openpose给出的是18个,故将头部的各点进行平均作为头部坐标。
视角归一化:将x方向设置为受试者的正面方向,将y方向设置为由左肩和右肩定义的身体一侧,将z方向设置为与地面垂直的方向。将三维位姿在该三维空间中旋转并归一化。
-
时空特征
基于先验知识的特征减轻深度神经网络的任务。受特征关节的启发,设计了三种附加的时空位姿特征:
- 关节角,即某些关节处变化的角度;
- 肢体长度,人体静态测量;
- 关节运动,用动态特征来描述运动模式。
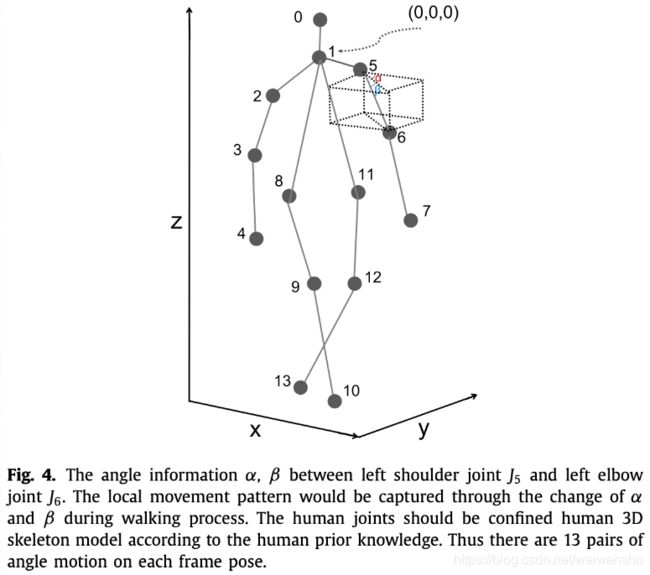
1.关节角度
下肢关节角度的变化有利于步态识别。
三维角度的计算方法:
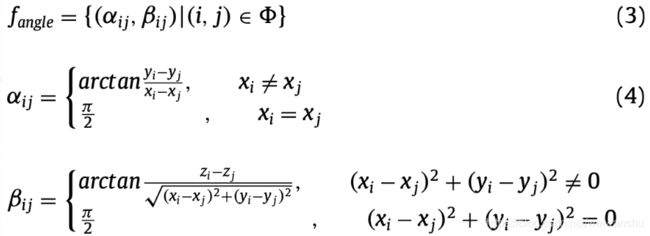
2.支干长度
肢体长度是两个相邻关节之间的距离。对载荷、角度、衣着不敏感
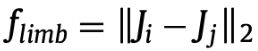
每个人体骨骼模型有13个静态肢体长度。
3.关节动态
利用帧间差异来获取动态信息。关节运动由两个相邻帧之间的差来定义,帧c和帧c+1:

-
特征拼接
这四个向量可以连接成一个长向量来表示姿势、运动和静态身体测量。不同帧的特征向量可以组合在一起形成特征矩阵,如图5所示。
但是因为动态信息 f_motion是两帧差分得到的,所以数量会少于其他三个,解决办法是用一个零向量使矩阵完备。

-
网络结构
由于特征是逐帧提取的,并且是序列数据,因此对序列数据采用RNN[23]和LSTM[24]的方法是合理的。
有两种损耗,Softmax Loss 和 center loss。
- Softmax Loss 可以将输入分为不同的类别。这意味着softmax的损失会扩大类间差异。
- center loss 可以通过最小化类内变化来保持不同类的特征可分离。

λ = 0.008


实验
实验数据和设置:
-
CASIA B步态数据集
这个数据集比较熟悉了。
训练集:前62名受试者,
测试集:其余受试者。
受试者测试方法:gallery集由每个受试者的前4个正态行走序列组成
probe集由其余序列组成

对比实验:SPAE[8]和GaitGAN[34]
-
CASIA E步态数据集
是由中国科学院和Watrix公司共同开发的最新步态数据集。该数据集包含1014名受试者,比CASIA b大得多。与其他超过1000名受试者的步态数据集不同,步态数据是从13个不同视角收集的。视图从0到180,在水平方向上有15个间隔。每个受试者有6个序列。分别为正常步行(NM)、带包步行(BG)和穿外套步行(CL)的2个序列。正在处理隐私问题,稍后会发布数据集。
实验设置类似于在CASIA B。
训练集:CASIA E数据集的前507名受试者,和被放入
测试集:剩下507名受试者。测试集,有两种类型的设置。
- 对于相同视点条件下的正常行走,同一视点上只有两个正常行走序列。gallery为第一个正常行走序列,probe为第二个正常行走。
- 在第二种设置中,将前2个正常行走序列放入gallery中,将其余行走序列放入probe中。
