Elasticsearch(三)--Metric(指标)
说明:该博客对应的Elasticsearch 的版本为7.8.0;测试工具为postman
1,概念
理解四个关键字:Metric(指标),Bucketing(桶),Matrix(矩阵),Pipeline(管道).其中Metric(指标),Bucketing(桶)应用最为广泛.文档也就是json对象
Bucket(桶): 满足特定条件的文档的集合,类似SQL中的GROUP BY语法(按照性别进行分组)
Metric(指标): 指标分析类型对桶内的文档进行聚合分析的操作),如计算最大值、最小值、平均值等等(类似于分组后计算组内的最大值与最小值)
ES聚合分析查询的一般写法
"aggs" : {
"" : {
"" : {
}
[,"meta" : { [] } ]?
[,"aggregations" : { []+ } ]? }
[,"" : { ... } ]*
}
-------#Aggregations== aggs 2,Metric(指标)详解:
前期数据的准备
POST http://localhost:9200/goods
{
"mappings":{ //映射
"properties":{ //文档的属性
"goodName":{
"type":"keyword" //类型是keyword
},
"goodCount":{
"type":"long"
},
"goodType":{
"type":"keyword"
},
"goodPrice":{
"type":"long"
}
}
}
}注意:分组操作,排序操作...对应的字段应该设为keyword
批量插入数据:
PUT http://localhost:9200/goods/_bulk
{"index":{"_index":"goods","_id":"1001"}}
{ "goodName": "手机","goodCount": 500,"goodType": "手机数码","goodPrice": 6999}
{"index":{"_index":"goods","_id":"1002"}}
{ "goodName": "电脑","goodCount": 60,"goodType": "手机数码","goodPrice": 8999}
{"index":{"_index":"goods","_id":"1003"}}
{"goodName": "耳机","goodCount": 1000,"goodType": "手机数码","goodPrice": 39}
{"index":{"_index":"goods","_id":"1004"}}
{"goodName": "男士外套","goodCount": 400,"goodType": "衣服服饰","goodPrice": 89}
{"index":{"_index":"goods","_id":"1005"}}
{"goodName": "女士内衣","goodCount": 600,"goodType": "衣服服饰","goodPrice": 139}
{"index":{"_index":"goods","_id":"1006"}}
{ "goodName": "洗洁精","goodCount": 4000,"goodType": "厨房用品","goodPrice": 9.9}
{"index":{"_index":"goods","_id":"1007"}}
{"goodName": "洗衣液","goodCount": 4500,"goodType": "厨房用品","goodPrice": 19.9}
{"index":{"_index":"goods","_id":"1008"}}
{"goodName": "炒菜锅","goodCount": 5000,"goodType": "厨房用品","goodPrice": 59.9}
{"index":{"_index":"goods","_id":"1009"}}
{"goodName": "床单","goodCount": 5000,"goodType": "床上用品","goodPrice": 70}
{"index":{"_index":"goods","_id":"1010"}}
{"goodName": "劳斯莱斯","goodCount": 30,"goodType": "汽车用品","goodPrice": 6000000}
注意:最后一行, 敲回车出来一个空行
查看是否成功:
GET /_cat/count/goods?v
2.1、单值分析,只输出一个分析结果
Min:计算从聚合文档内提取的数组的平均值
Max:计算从聚合文档内提取的数组的最大值
avg,计算从聚合文档内提取的数组的平均值
sum,计算从聚合文档内提取的数组的总和
Cardinality:唯一值(不重复的字段有多少相当于sql中的distinct)
value_count用于统计从字段中取值的总数,类似于SQL中的count
top hits:分桶后获取该桶内匹配前n的文档列表(可以先排序再匹配)
2.1.1.avg
POST http://localhost:9200/goods/_search?size=0[1]
{
"size":0,[2]
"aggs":{
"avg_price":{ //聚合的名字(自定义)
"avg":{ //聚合类型
"field":"goodPrice" //聚合的字段
}
}
}
}运行结果
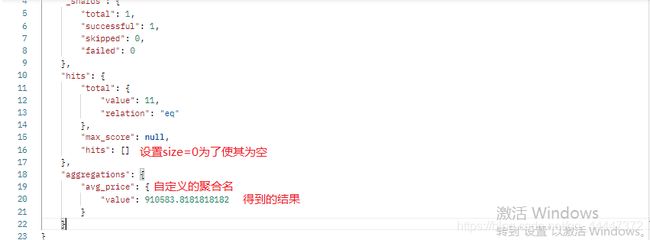
注意:[1],[2]任意一种方式都可以目的是为了去掉聚合的原文档.
2.1.2.min
POST http://localhost:9200/goods/_search?size=0
{
"aggs":{
"min_price":{ //聚合的名字
"min":{ //聚合的类型
"field":"goodPrice" //聚合的字段
}
}
}
}运行结果

2.1.3.max
POST http://localhost:9200/goods/_search?size=0
{
"aggs":{
"max_price":{ //聚合的名字(自定义)
"max":{ //聚合的类型
"field":"goodPrice" //聚合的字段
}
}
}
}运行结果
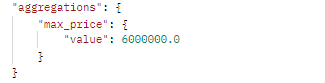
2.1.4.sum
POST http://localhost:9200/goods/_search?size=0
{
"aggs":{
"sum_price":{ //聚合的名字
"sum":{ //聚合的类型
"field":"goodPrice" //聚合的字段
}
}
}
}2.1.5.cardinality
- cardinality聚集的算法使用极小内存实现统计结果的基本准确。所以cardinality在数据量极大的情况下是不能保证完全准确的
POST http://localhost:9200/goods/_search?size=0
{
"aggs":{
"cardinality_price":{
"cardinality":{
"field":"goodType"
}
}
}
}运行结果

cardinality,count(distinct),5%的错误率,性能在100ms左右
1、precision_threshold优化准确率和内存开销
GET /tvs/sales/_search
{
"size" : 0,
"aggs" : {
"distinct_brand" : {
"cardinality" : {
"field" : "brand",
"precision_threshold" : 100
}
}
}
}如果brand的unique value,在100个以内,小米,长虹,三星,TCL,HTL。。。
cardinality几乎保证100%准确,但是cardinality算法,会占用precision_threshold * 8 byte 内存消耗,100 * 8 = 800个字节,占用内存很小。。。而且unique value如果的确在值以内,那么可以确保100%准确
设置的是100但是有数百万的unique value,错误率在5%以内precision_threshold,值设置的越大,占用内存越大,1000 * 8 = 8000 / 1000 = 8KB,可以确保更多unique value的场景下,100%的准确
unique value,10000,precision_threshold=10000,10000 * 8 = 80000个byte,80KB
2、HyperLogLog++ (HLL)算法性能优化
cardinality底层算法:HLL算法,HLL算法会对所有的uqniue value取hash值,通过hash值近似去求distcint count
默认情况下,发送一个cardinality请求的时候,会动态地对所有的field value,取hash值;
优化:将取hash值的操作,前移到建立索引的时候
PUT /tvs/
{
"mappings": {
"sales": {
"properties": {
"brand": {
"type": "text",
"fields": {增加一个子字段,类型是murmur3,在建立索引的时候就会将hash值算出来
"hash": {
"type": "murmur3"
}
}
}
}
}
}
}GET /tvs/sales/_search
{
"size" : 0,
"aggs" : {
"distinct_brand" : {
"cardinality" : {//通过hash子字段计算cardinality
"field" : "brand.hash",
"precision_threshold" : 100
}
}
}
}
2.1.6 value_count
- 统计从字段中取值的总数,类似于SQL中的count
POST /kibana_sample_data_flights/_search?filter_path=aggregations
{
"aggs": {
"total_country": {
"value_count": {
"field": "DestCountry"
}
}
}
}
//返回结果
{
"aggregations" : {
"total_country" : {
"value" : 13059
}
}
}
2.2,多值分析,输出多个结果
Stats:统计,请求后会直接显示多种聚合的结果
extended_stats:同上
percentiles:默认按照[1,5,25,50,75,95,99]的顺序从小到大累计并返回对应的值其中的[1,5,25,50,75,95,99]都为百分比,查出来对应的为文档值(goodPrice值)w1-w7;占比1%的文档的goodPrice值<=w1(如果w1是12,个索在整引中的文档有1%的文档的goodPrice值<=12)
Percentile_ranks:通过文档值求百分比,"percents" : [95, 99, 99.9],其中的[95, 99, 99.9]为文档对应的goodPrice值,查出来的是w1-w3百分比:goodPrice值小于95的文档占比为W1;小于99的文档占比为W3
2.2.1,stats
POST http://localhost:9200/goods/_search?size=0
{
"aggs":{
"stats_price":{
"stats":{
"field":"goodPrice"
}
}
}
}运行结果
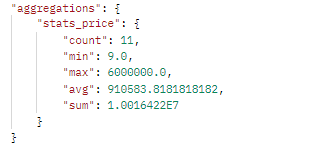
2.2.2,percentiles
POST http://localhost:9200/goods/_search?size=0
2.2.2.1 (不指定分位值)
{
"aggs": {
"goodPrice_outlier": {
"percentiles": {
"field": "goodPrice", 对该字段进行聚合
"keyed":false //默认情况下,keyed标志设置为true,它将唯一
//的字符串键与每个存储桶相关联,并将范围作为哈希而不是数组返回。
}
}
}
}运行结果
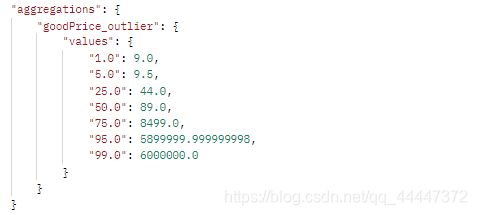
2.2.2.1 (指定分位值)
{
"size": 0,
"aggs": {
"goodPrice_outlier": {
"percentiles": {
"field": "goodPrice",
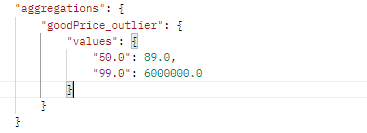
"percents" : [50, 99], //占比为50%的文档的goodPrice<=查出来的数;
//占比为99%的文档的goodPrice<=查出来的数;
"keyed": false
}
}
}
}运行结果
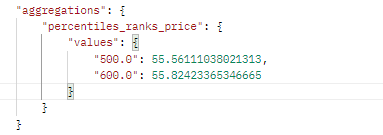
2.2.3,percentile_ranks
POST http://localhost:9200/goods/_search?size=0
{
"aggs":{
"percentiles_ranks_price":{
"percentile_ranks":{
"field":"goodPrice",
"values" : [500, 600] //小于500的文档占比为xx%,
//小于600的文档占比为xx%
}
}
}
}运行结果
SLA:就是你提供的服务的标准
我们的网站的提供的访问延时的SLA,确保所有的请求100%,都必须在200ms以内,大公司内,一般都是要求100%在200ms以内
如果超过1s,则需要升级到A级故障,代表网站的访问性能和用户体验急剧下降
需求:在200ms以内的,有百分之多少,在1000毫秒以内的有百分之多少,percentile ranks metric
percentile ranks,其实比pencentile还要常用
//percentile的优化
GET /website/logs/_search
{
"size": 0,
"aggs": {
......
},
"aggs": {
"latency_percentile_ranks": {
"percentile_ranks": {
"field": "latency",
"values": [
200,
1000
],
"compression": 100
}
}
}
}
}
}使用的是TDigest算法,用很多节点来执行百分比的计算,近似估计,有误差,节点越多,越精准
通过compression控制
限制节点数量最多 compression(默认100) * 20 = 2000个node去计算
越大,占用内存越多,越精准,性能越差
一个节点占用32字节,100 * 20 * 32 = 64KB
如果你想要percentile算法越精准,compression可以设置的越大
2.2.4,top_hits
POST http://localhost:9200/goods/_search?size=0
{
"aggs": {
"top_tags": { //聚合的名字
"terms": { //聚合的类型(分组)
"field": "goodType", //对"goodType"字段进行分组
"size": 3 //分桶后只显示文档数量前3的桶
},
"aggs": {
"top_sales_hits": { //聚合的名字
"top_hits": { //聚合的类型
"sort": [ //对每个桶内的goodPrice降序排列
{
"goodPrice": {
"order": "asc" //降序
}
}
],
"size" : 1 //取桶内的匹配的一个
}
}
}
}
}
}运行结果
