第五章 深度神经网络为何很难训练
原文
假设你是一名工程师,接到一项从头开始设计计算机的任务。某天,你在工作室工作,设计逻辑电路,构建 AND 门,OR 门等等时,老板带着坏消息进来:客户刚刚添加了一个奇特的设计需求:整个计算机的线路的深度必须只有两层:
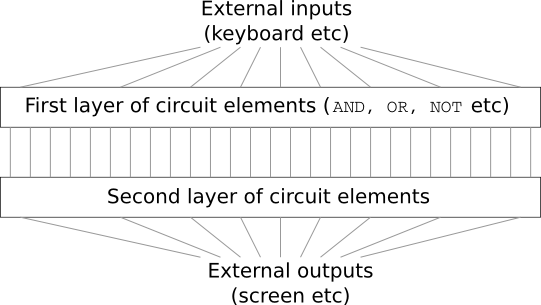
你惊呆了,跟老板说道:“这货疯掉了吧!”
老板说:“他们确实疯了,但是客户的需求比天大,我们要满足它。”
实际上,在某种程度上看,他们的客户并没有太疯狂。假设你可以使用贵重特殊的逻辑门可以 AND 起来你想要的那么多的输入。同样也能使用多值输入的 NAND 门——可以AND 多个输入然后求否定的门。有了这类特殊的门,构建出来的两层的深度的网络便可以计算任何函数。
但是仅仅因为某件事是理论上可能的,就代表这是一个好的想法。在实践中,在解决线路设计问题(或者大多数的其他算法问题)时,我们通常考虑如何解决子问题,然后逐步地集成这些子问题的解。换句话说,我们通过多层的抽象来获得最终的解答。
例如,我们来设计一个逻辑线路来做两个数的乘法。我们希望在已经有了计算两个数加法的子线路基础上创建这个逻辑线路。计算两个数和的子线路也是构建在用语两个比特相加的子子线路上的。最终的线路就长成这个样子:

最终的线路包含至少三层线路的单元。实际上,这个线路很可能会超过三层,因为我们可以将子任务分解成比上述更小的单元。但是基本思想就是这样。
因此深度线路让这样的设计过程变得更加简单。但是这对于设计本身帮助并不大。其实,数学证明对于某些函数设计的非常浅的线路可能需要指数级的线路单元来计算。例如,在1980年代早期的一系列著名的论文已经给出了计算比特的集合的奇偶性通过浅的线路来计算需要指数级的门。另一当面,如果你使用更深的线路,那么可以使用规模很小的线路来计算奇偶性:仅仅需要计算比特的对的奇偶性,然后使用这些结果来计算比特对的对的奇偶性,以此类推,构建出总共的奇偶性。深度线路这样就能从本质上获得超过浅线路的更强的能力。
到现在为止,本书讲神经网络看作是疯狂的客户。几乎我们遇到的所有的网络就只包括一层隐含神经元(另外还有输入输出层):

这些简单的网络已经非常有用了:在前面的章节中,我们使用这样的网络可以进行准确率高达 98% 的手写数字的识别!而且,直觉上看,我们期望拥有更多隐含层的神经网络能够变的更加强大:

这样的网络可以使用中间层构建出多层的抽象,正如我们在布尔线路中做的那样。例如,如果我们在进行视觉模式识别,那么在第一层的神经元可能学会识别边,在第二层的神经元可以在边的基础上学会识别出更加复杂的形状,例如三角形或者矩形。第三层将能够识别更加复杂的形状。依此类推。这些多层的抽象看起来能够赋予深度网络一种学习解决复杂模式识别问题的能力。然后,正如线路的示例中看到的那样,存在着理论上的研究结果告诉我们深度网络在本质上比浅层网络更加强大。
对某些问题和网络结构,Razvan Pascanu, Guido Montúfar, and Yoshua Bengio 在2014年的这篇文章 On the number of response regions of deep feed forward networks with piece-wise linear activations给出了证明。更加详细的讨论在Yoshua Bengio 2009年的著作 Learning deep architectures for AI 的第二部分。
那我们如何训练这样的深度神经网络呢?在本章中,我们尝试使用基于 BP 的随机梯度下降的方法来训练。但是这会产生问题,因为我们的深度神经网络并不能比浅层网络性能好太多。
这个失败的结果好像与上面的讨论相悖。这就能让我们退缩么,不,我们要深入进去试着理解使得深度网络训练困难的原因。仔细研究一下,就会发现,在深度网络中,不同的层学习的速度差异很大。尤其是,在网络中后面的层学习的情况很好的时候,先前的层次常常会在训练时停滞不变,基本上学不到东西。这种停滞并不是因为运气不好。而是,有着更加根本的原因是的学习的速度下降了,这些原因和基于梯度的学习技术相关。
当我们更加深入地理解这个问题时,发现相反的情形同样会出现:先前的层可能学习的比较好,但是后面的层却停滞不变。实际上,我们发现在深度神经网络中使用基于梯度下降的学习方法本身存在着内在不稳定性。这种不稳定性使得先前或者后面的层的学习过程阻滞。
这个的确是坏消息。但是真正理解了这些难点后,我们就能够获得高效训练深度网络的更深洞察力。而且这些发现也是下一章的准备知识,我们到时会介绍如何使用深度学习解决图像识别问题。
(消失的恋人,哦不)消失的梯度问题
那么,在我们训练深度网络时究竟哪里出了问题?
为了回答这个问题,让我们重新看看使用单一隐藏层的神经网络示例。这里我们也是用 MNIST 数字分类问题作为研究和实验的对象。
MNIST 问题和数据在这里(here )和这里( here).
这里你也可以在自己的电脑上训练神经网络。或者就直接读下去。如果希望实际跟随这些步骤,那就需要在电脑上安装 python 2.7,numpy和代码,可以通过下面的命令复制所需要的代码
git clone https://github.com/mnielsen/neural-networks-and-deep-learning.git如果你不使用 git,那么就直接从这里(here)下载数据和代码。然后需要转入 src 子目录。
接着从 python 的 shell 就可以载入 MNIST 数据:
>>> import mnist_loader
>>> training_data, validation_data, test_data = \
... mnist_loader.load_data_wrapper()然后设置我们的网络:
>>> import network2
>>> net = network2.Network([784, 30, 10])这个网络拥有 784 个输入层神经元,对应于输入图片的 28 * 28 = 784 个像素点。我们设置隐藏层神经元为 30 个,输出层为 10 个神经元,对应于 MNIST 数字 ('0', '1', ..., '9')。
让我们训练 30 轮,使用 mini batch 大小为 10, 学习率 \eta = 0.1,正规化参数 \lambda = 5.0。在训练时,我们也会在验证集上监控分类的准确度:
>>> net.SGD(training_data, 30, 10, 0.1, lmbda=5.0,
... evaluation_data=validation_data, monitor_evaluation_accuracy=True)最终我们得到了分类的准确率为 96.48%(也可能不同,每次运行实际上会有一点点的偏差)这和我们前面的结果相似。
现在,我们增加另外一层隐藏层,同样地是 30 个神经元,试着使用相同的超参数进行训练:
>>> net = network2.Network([784, 30, 30, 10])
>>> net.SGD(training_data, 30, 10, 0.1, lmbda=5.0,
... evaluation_data=validation_data, monitor_evaluation_accuracy=True)最终的结果分类准确度提升了一点,96.90%。这点令人兴奋:一点点的深度带来了效果。那么就再增加一层同样的隐藏层:
>>> net = network2.Network([784, 30, 30, 30, 10])
>>> net.SGD(training_data, 30, 10, 0.1, lmbda=5.0,
... evaluation_data=validation_data, monitor_evaluation_accuracy=True)哦,这里并没有什么提升,反而下降到了 96.57%,这与最初的浅层网络相差无几。再增加一层:
>>> net = network2.Network([784, 30, 30, 30, 30, 10])
>>> net.SGD(training_data, 30, 10, 0.1, lmbda=5.0,
... evaluation_data=validation_data, monitor_evaluation_accuracy=True)分类准确度又下降了,96.53%。这可能不是一个统计显著地下降,但是会让人们觉得沮丧。
这里表现出来的现象看起非常奇怪。直觉地,额外的隐藏层应当让网络能够学到更加复杂的分类函数,然后可以在分类时表现得更好吧。可以肯定的是,事情并没有变差,至少新的层次增加上,在最坏的情形下也就是没有影响。事情并不是这样子的。
那么,应该是怎样的呢?假设额外的隐藏层的确能够在原理上起到作用,问题是我们的学习算法没有发现正确地权值和偏差。那么现在就要好好看看学习算法本身有哪里出了问题,并搞清楚如何改进了。
为了获得一些关于这个问题直觉上的洞察,我们可以将网络学到的东西进行可视化。下面,我画出了一部分 [784, 30, 30, 10] 的网络,也就是包含两层各有 30 个隐藏神经元的隐藏层。图中的每个神经元有一个条形统计图,表示这个神经元在网络进行学习时改变的速度。更大的条意味着更快的速度,而小的条则表示变化缓慢。更加准确地说,这些条表示了 每个神经元上的dC/db,也就是代价函数关于神经元的偏差更变的速率。回顾第二章(Chapter 2),我们看到了这个梯度的数值不仅仅是在学习过程中偏差改变的速度,而且也控制了输入到神经元权重的变量速度。如果没有回想起这些细节也不要担心:目前要记住的就是这些条表示了每个神经元权重和偏差在神经网络学习时的变化速率。
为了让图里简单,我只展示出来最上方隐藏层上的 6 个神经元。这里忽略了输入层神经元,因为他们并不包含需要学习的权重或者偏差。同样输出层神经元也忽略了,因为这里我们做的是层层之间的比较,所以比较相同数量的两层更加合理啦。在网络初始化后立即得到训练前期的结果如下:
这个程序给出了计算梯度的方法generate_gradient.py. 也包含了其他一些在本章后面提到的计算方法。

该网络是随机初始化的,因此看到了神经元学习的速度差异其实很大。而且,我们可以发现,第二个隐藏层上的条基本上都要比第一个隐藏层上的条要大。所以,在第二个隐藏层的神经元将学习得更加快速。这仅仅是一个巧合么,或者第二个隐藏层的神经元一般情况下都要比第一个隐藏层的神经元学习得更快?
为了确定我们的猜测,拥有一种全局的方式来比较学习速度会比较有效。我们这里将梯度表示为

在第 l 层的第 j 个神经元的梯度。我们可以将 \delta^1 看做是一个向量其中元素表示第一层隐藏层的学习速度,\delta^2 则是第二层隐藏层的学习速度。接着使用这些向量的长度作为全局衡量这些隐藏层的学习速度的度量。因此,||\delta^1|| 就代表第一层隐藏层学习速度,而||\delta^2|| 就代表第二层隐藏层学习速度。
借助这些定义,在和上图同样的配置下,||\delta^1|| = 0.07而||\delta^2|| = 0.31,所以这就确认了之前的疑惑:在第二层隐藏层的神经元学习速度确实比第一层要快。
如果我们添加更多的隐藏层呢?如果我们有三个隐藏层,比如说在一个 [784, 30, 30, 10] 的网络中,那么对应的学习速度就是 0.012, 0.060, 0.283。这里前面的隐藏层学习速度还是要低于最后的隐藏层。假设我们增加另一个包含 30 个隐藏神经元的隐藏层。那么,对应的学习速度就是:0.003, 0.017, 0.070, 0.285。还是一样的模式:前面的层学习速度低于后面的层。
现在我们已经看到了训练开始时的学习速度,这是刚刚初始化之后的情况。那么这个速度会随着训练的推移发生什么样的变化呢?让我们看看只有两个隐藏层。学习速度变化如下:
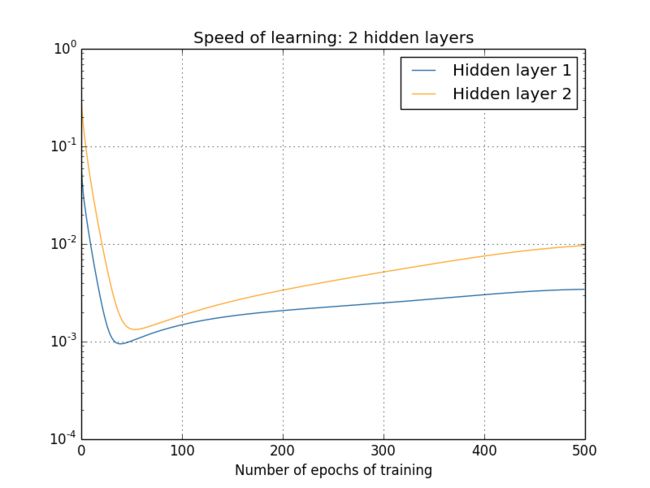
为了产生这些结果,我在 1000 个训练图像上进行了 500 轮 batch 梯度下降。这和我们通常训练方式还是不同的——我没有使用 minibatch,仅仅使用了 1000 个训练图像,而不是全部的 50,000 幅图。我并不是想做点新鲜的尝试,或者蒙蔽你们的双眼,但因为使用 minibatch 随机梯度下降会在结果中带来更多的噪声(尽管在平均噪声的时候结果很相似)。使用我已经确定的参数可以对结果进行平滑,这样我们可以看清楚真正的情况是怎样的。
如图所示,两层在开始时就有着不同的速度。然后两层的学习速度在触底前迅速下落。在最后,我们发现第一层的学习速度变得比第二层更慢了。
那么更加复杂的网络是什么情况呢?这里是一个类似的实验,但是这次有三个隐藏层([784, 30, 30, 30, 10]):

同样,前面的隐藏层要比后面的隐藏层学习的更慢。最后一个实验,就是增加第四个隐藏层([784, 30, 30, 30, 30, 10]),看看这里会发生什么:
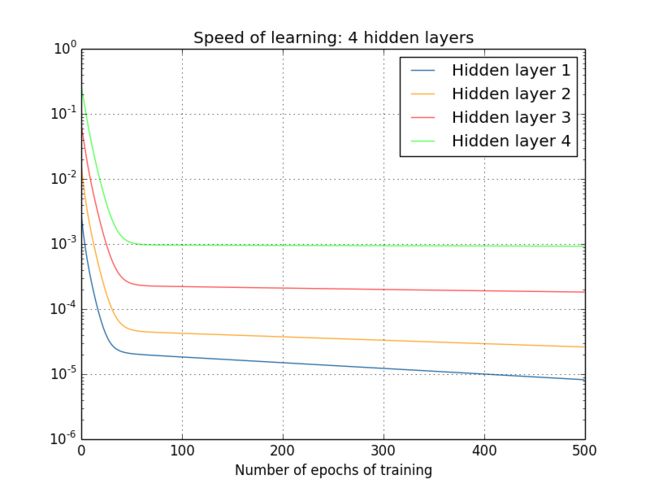
同样的情况出现了,前面的隐藏层的学习速度要低于后面的隐藏层。这里,第一层的学习速度和最后一层要差了两个数量级,也就是比第四层慢了100倍。难怪我们之前在训练这些网络的时候遇到了大麻烦!
现在我们已经有了一项重要的观察结果:至少在某些深度神经网络中,在我们在隐藏层 BP 的时候梯度倾向于变小。这意味着在前面的隐藏层中的神经元学习速度要慢于后面的隐藏层。这儿我们只在一个网络中发现了这个现象,其实在多数的神经网络中存在着更加根本的导致这个现象出现的原因。这个现象也被称作是 消失的梯度问题(vanishing gradient problem)。
为何消失的梯度问题会出现呢?我们可以通过什么方式避免它?还有在训练深度神经网络时如何处理好这个问题?实际上,这个问题是可以避免的,尽管替代方法并不是那么有效,同样会产生问题——在前面的层中的梯度会变得非常大!这也叫做 爆炸的梯度问题(exploding gradient problem),这也没比消失的梯度问题更好处理。更加一般地说,在深度神经网络中的梯度是不稳定的,在前面的层中或会消失,或会爆炸。这种不稳定性才是深度神经网络中基于梯度学习的根本问题。这就是我们需要理解的东西,如果可能的话,采取合理的步骤措施解决问题。
一种有关消失的(不稳定的)梯度的看法是确定这是否确实是一个问题。此刻我们暂时转换到另一个话题,假设我们正要数值优化一个一元的函数 f(x)。如果其导数 f'(x) 很小,这难道不是一个好消息么?是不是意味着我们已经接近极值点了?同样的方式,在深度神经网络中前面隐藏层的小的梯度是不是表示我们不需要对权重和偏差做太多调整了?
当然,实际情况并不是这样的。想想我们随机初始网络中的权重和偏差。在面对任意的一种任务,单单使用随机初始的值就能够获得一个较好的结果是太天真了。具体讲,看看 MNIST 问题的网络中第一层的权重。随机初始化意味着第一层丢失了输入图像的几乎所有信息。即使后面的层能够获得充分的训练,这些层也会因为没有充分的信息而很难识别出输入的图像。因此,在第一层不进行学习的尝试是不可能的。如果我们接着去训练深度神经网络,我们需要弄清楚如何解决消失的梯度问题。
什么导致了消失的梯度问题?也就是在深度神经网络中的所谓的梯度不稳定性
为了弄清楚为何会出现消失的梯度,来看看一个极简单的深度神经网络:每一层都只有一个单一的神经元。下图就是有三层隐藏层的神经网络:

这里,w_1, w_2, ... 是权重,而 b_1, b_2, ... 是偏差,C 则是某个代价函数。回顾一下,从第 j 个神经元的输出 a_j = \sigma(z_j),其中 \sigma 是通常的 sigmoid 函数,而 z_j = w_j * a_j-1 + b_j是神经元的带权输入。我已经在最后表示出了代价函数 C 来强调代价是网络输出 a_4 的函数:如果实际输出越接近目标输出,那么代价会变低;相反则会变高。
现在我们要来研究一下关联于第一个隐藏神经元梯度 dC/db_1。我们将会计算出dC/db_1 的表达式,通过研究表达式来理解消失的梯度发生的原因。
开始就简单地给出 dC/db_1 的表达式。初看起来有点复杂,但是其结构是相当简单的,我一会儿会解释。下图给出了具体的表达式:

dC/db_1
表达式结构如下:对每个神经元有一个 \sigma'(z_j) 项;对每个权重有一个 w_j 项;还有一个 dC/da_4项,表示最后的代价函数。注意,我已经将表达式中的每个项置于了对应的位置。所以网络本身就是表达式的解读。
你可以直接认可这个表达式,直接跳到该表达式如何关联于小时的梯度问题的。这对理解没有影响,因为实际上上面的表达式只是前面对于BP 的讨论的特例。但是也包含了一个表达式正确的解释,所以去看看那个解释也是很有趣的(也可能更有启发性吧)。
假设我们对偏差 b_1 进行了微小的调整 \Delta b_1。这会导致网络中剩下的元素一系列的变化。首先会对第一个隐藏元输出产生一个 \Delta a_1 的变化。这样就会导致第二个神经元的带权输入产生 \Delta z_2 的变化。从第二个神经元输出随之发生 \Delta a_2 的变化。以此类推,最终会对代价函数产生 \Delta C 的变化。这里我们有:

这表示我们可以通过仔细追踪每一步的影响来搞清楚 dC/db_1 的表达式。
现在我们看看 \Delta b_1 如何影响第一个神经元的输出 a_1 的。我们有 a_1 = \sigma(z_1) = \sigma(w_1 * a_0 + b1),所以有
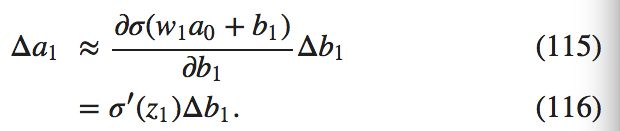
\sigma'(z_1) 这项看起很熟悉:其实是我们上面关于 dC/db_1 的表达式的第一项。直觉上看,这项将偏差的改变 \Delta b_1 转化成了输出的变化 \Delta a_1。\Delta a_1 随之又影响了带权输入 z_2 = w_2 * a_1 + b_2:

将 \Delta z_2 和 \Delta a_1 的表达式组合起来,我们可以看到偏差 b_1 中的改变如何通过网络传输影响到 z_2的:
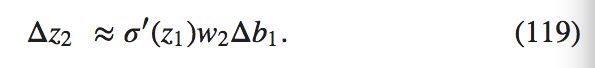
现在,又能看到类似的结果了:我们得到了在表达式 dC/db_1 的前面两项。以此类推下去,跟踪传播改变的路径就可以完成。在每个神经元,我们都会选择一个 \sigma'(z_j) 的项,然后在每个权重我们选择出一个 w_j 项。最终的结果就是代价函数中变化 \Delta C 的相关于偏差 \Delta b_1 的表达式:

除以 \Delta b_1,我们的确得到了梯度的表达式:

为何出现梯度消失:现在把梯度的整个表达式写下来:

除了最后一项,该表达式是一系列形如 w_j \sigma'(z_j) 的乘积。为了理解每个项的行为,先看看下面的sigmoid 函数导数的图像:

该导数在 \sigma'(0)=1/4 时达到最高。现在,如果我们使用标准方法来初始化网络中的权重,那么会使用一个均值为 0 标准差为 1 的高斯分布。因此所有的权重通常会满足 |w_j| < 1。有了这些信息,我们发现会有 w_j \sigma'(z_j) < 1/4。并且在我们进行了所有这些项的乘积时,最终结果肯定会指数级下降:项越多,乘积的下降的越快。**这里我们敏锐地嗅到了消失的梯度问题的合理解释。
更明白一点,我们比较一下 dC/db_1 和一个更后面一些的偏差的梯度,不妨设为 dC/db_3。当然,我们还没有显式地给出这个表达式,但是计算的方式是一样的。

两个表示式有很多相同的项。但是 dC/db_1 还多包含了两个项。由于这些项都是 < 1/4 的。所以 dC/db_1 会是 dC/db_3 的 1/16 或者更小。这其实就是消失的梯度出现的本质原因了。
当然,这里并非严格的关于消失的梯度微调的证明而是一个不太正式的论断。还有一些可能的产生原因了。特别地,我们想要知道权重 w_j 在训练中是否会增长。如果会,项 w_j \sigma'(z_j) 会不会不在满足之前 w_j \sigma'(z_j) < 1/4 的约束。事实上,如果项变得很大——超过 1,那么我们将不再遇到消失的梯度问题。实际上,这时候梯度会在我们 BP 的时候发生指数级地增长。也就是说,我们遇到了梯度爆炸的问题。
梯度爆炸问题:现在看看梯度爆炸如何出现的把。这里的例子可能不是那么自然:固定网络中的参数,来确保产生爆炸的梯度。但是即使是不自然,也是包含了确定会产生爆炸梯度(而非假设的可能)的特质的。
共两个步骤:首先,我们将网络的权重设置得很大,比如 w_1 = w_2 = w_3 = w_4 = 100。然后,我们选择偏差使得 sigma'(z_j) 项不会太小。这是很容易实现的:方法就是选择偏差来保证每个神经元的带权输入是 z_j = 0(这样 sigma'(z_j) = 1/4)。比如说,我们希望 z_1 = w_1 * a_0 + b_1。我们只要把 b_1 = -100 * a_0 即可。我们使用同样的方法来获得其他的偏差。这样我们可以发现所有的项 w_j * \sigma'(z_j)都等于 100*1/4 = 25。最终,我们就获得了爆炸的梯度。
不稳定的梯度问题:根本的问题其实并非是消失的梯度问题或者爆炸的梯度问题,而是在前面的层上的梯度是来自后面的层上项的乘积。当存在过多的层次时,就出现了内在本质上的不稳定场景。唯一让所有层都接近相同的学习速度的方式是所有这些项的乘积都能得到一种平衡。如果没有某种机制或者更加本质的保证来达成平衡,那网络就很容易不稳定了。简而言之,真实的问题就是神经网络受限于不稳定梯度的问题。所以,如果我们使用标准的基于梯度的学习算法,在网络中的不同层会出现按照不同学习速度学习的情况。
练习
- 在我们对于消失的梯度问题讨论中,使用了
|\sigma'(z) < 1/4|这个结论。假设我们使用一个不同的激活函数,其导数值是非常大的。这会帮助我们避免不稳定梯度的问题么?
消失的梯度问题普遍存在:我们已经看到了在神经网络的前面的层中梯度可能会消失也可能会爆炸。实际上,在使用 sigmoid 神经元时,梯度通常会消失。为什么?再看看表达式 |w\sigma'(z)|。为了避免消失的梯度问题,我们需要 |w\sigma'(z)| >= 1。你可能会认为如果 w 很大的时候很容易达成。但是这比看起来还是困难很多。原因在于,\sigma'(z) 项同样依赖于 w:\sigma'(z) = \sigma'(w*a+b),其中 a 是输入的激活函数。所以我们在让 w 变大时,需要同时不让 \sigma'(w*a+b) 变小。这将是很大的限制了。原因在于我们让 w 变大,也会使得 w*a + b 变得非常大。看看 \sigma' 的图,这会让我们走到 \sigma' 的两翼,这里会去到很小的值。唯一避免发生这个情况的方式是,如果输入激活函数掉入相当狭窄的范围内(这个量化的解释在下面第一个问题中进行)。有时候,有可能会出现。但是一般不大会发生。所以一般情况下,会遇到消失的梯度。
问题
- 考虑乘积
|\w\sigma'(wa+b)|。假设有|\w\sigma'(wa+b)| >= 1。(1) 这种情况只有在|w| >= 4的时候才会出现。(2) 假设|w| >= 4,考虑那些满足|\w\sigma'(wa+b)| >= 1的输入激活a集合。证明:满足上述条件的该集合能够充满一个不超过

Paste_Image.png
宽度的区间。(3) 数值上说明上述表达式在|w| ~= 6.9时候去的最高值约0.45。所以即使每个条件都满足,我们仍然有一个狭窄的输入激活区间,这样来避免消失的梯度问题。 - 幺神经元:考虑一个单一输入的神经元,
x,对应的权重w_1,偏差b,输出上的权重w_2。证明,通过合理选择权重和偏差,我们可以确保w_2 \sigma(w_1*x +b)~=x for x \in [0, 1]。这样的神经元可用来作为幺元试用,输出和输入相同(成比例)。Hint:可以重写x = 1/2 + \Delta,可以假设w_1很小,和在w_1 * \Delta使用 Taylor 级数展开。
在更加复杂网络中的不稳定梯度
现在已经研究了简单的网络,每一层只包含一个神经元。那么那些每层包含很多神经元的更加复杂的深度网络呢?

实际上,在这样的神经网络中,同样的情况也会发生。在前面关于 BP 的章节中,我们看到了在一个共 L 层的第 l 层的梯度:

这里 \Sigma'(z^l)是一个对角矩阵,每个元素是对第 l 层的带权输入 \sigma'(z)。而 w^l 是对不同层的权值矩阵。\nbala_a C 是对每个输出激活的偏导数向量。
这是更加复杂的表达式。不过,你仔细看,本质上的形式还是很相似的。主要是包含了更多的形如 (w^j)^T \Sigma' (z^j) 的对 (pair)。而且,矩阵 \Sigma'(z^j) 在对角线上的值挺小,不会超过 1/4。由于权值矩阵 w^j 不是太大,每个额外的项 (w^j)^T \sigma' (z^l) 会让梯度向量更小,导致梯度消失。更加一般地看,在乘积中大量的项会导致不稳定的梯度,和前面的例子一样。实践中,一般会发现在 sigmoid 网络中前面的层的梯度指数级地消失。所以在这些层上的学习速度就会变得很慢了。这种减速不是偶然现象:也是我们采用的训练的方法决定的。
深度学习其他的障碍
本章我们已经聚焦在消失的梯度上,并且更加一般地,不稳定梯度——深度学习的一大障碍。实际上,不稳定梯度仅仅是深度学习的众多障碍之一,尽管这一点是相当根本的。当前的研究集中在更好地理解在训练深度神经网络时遇到的挑战。这里我不会给出一个详尽的总结,仅仅想要给出一些论文,告诉你人们正在寻觅探究的问题。
首先,在 2010 年 Glorot 和 Bengio 发现证据表明 sigmoid 函数的选择会导致训练网络的问题。特别地,他们发现 sigmoid 函数会导致最终层上的激活函数在训练中会聚集在 0,这也导致了学习的缓慢。他们的工作中提出了一些取代 sigmoid 函数的激活函数选择,使得不会被这种聚集性影响性能。
第二个例子,在 2013 年 Sutskever, Martens, Dahl 和 Hinton 研究了深度学习使用随机权重初始化和基于 momentum 的 SGD 方法。两种情形下,好的选择可以获得较大的差异的训练效果。
这些例子告诉我们,“什么让训练深度网络非常困难”这个问题相当复杂。本章,我们已经集中于深度神经网络中基于梯度的学习方法的不稳定性。结果表明了激活函数的选择,权重的初始化,甚至是学习算法的实现方式也扮演了重要的角色。当然,网络结构和其他超参数本身也是很重要的。因此,太多因子影响了训练神经网络的难度,理解所有这些因子仍然是当前研究的重点。尽管这看起来有点悲观,但是在下一章中我们会介绍一些好的消息,给出一些方法来一定程度上解决和迂回所有这些困难。
原文链接:http://www.jianshu.com/p/917f71b06499
著作权归作者所有,转载请联系作者获得授权,并标注“简书作者”。