VIRT: Improving Representation-based Models for Text Matching through Virtual Interaction
VIRT:通过虚拟交互改进基于表示的文本匹配模型
Dan Li 1 , Yang Yang 2 , Hongyin Tang 2 , Jingang Wang 2 , Tong Xu 1 , Wei Wu 2 , Enhong Chen 1 1 University of Science and Technology of China 2 Meituan lidan528@mail.ustc.edu.cn , {yangyang113,tanghongyin,wangjingang02}@meituan.com tongxu@ustc.edu.cn, weiwu30@meituan.cm, cheneh@ustc.edu.cn
摘要
随着预训练transformers的蓬勃发展,基于孪生transformer编码器的表示模型已成为高效文本匹配的主流技术。然而,与基于交互的模型相比,由于文本对之间缺乏交互,这些模型的表现严重下降。现有技术试图通过对孪生语编码表示进行额外的交互来解决这一问题,而编码过程中的交互仍然是未知的。为了解决这个问题,我们提出了一种虚拟交互机制(VIRT),通过注意力图提取将交互知识从基于交互的模型转移到孪生编码器。VIRT作为一种纯列车时间组件,可以完全保持孪生结构的高效率,并且在推理过程中不会带来额外的计算成本。为了充分利用学习到的交互知识,我们进一步设计了一种VIRT适应的交互策略。在多个文本匹配数据集上的实验结果表明,我们的方法优于最先进的基于表示的模型。此外,VIRT可以很容易地集成到现有的基于表示的方法中,以实现进一步的改进。
1引言
文本匹配旨在模型一对文本之间的语义相关性,这是各种自然语言理解应用中的一个基本问题。例如,在社区问答(CQA)(Zhou等人,2011;Patra,2017)系统中,一个关键组件是通过问题匹配从数据库中找到与用户问题相关的类似问题。类似地,对话代理(Welleck等人,2019)需要通过预测用户陈述和一些预定义假设的蕴含关系来进行逻辑推理。
最近,深度预训练transformers的广泛使用(Vaswani等人,2017年)在文本匹配任务中取得了显著进展。基于微调transformer编码器的两种范式通常被构建:基于交互的模型(即交叉编码器)和基于表示的模型(即双编码器),如图1(a)和(b)所示。基于交互的模型(例如,BERT(De-vlin等人,2019))将文本对连接为单个序列,并在文本对之间执行完全交互。虽然完全交互提供了从模型底部到顶部的丰富匹配信号,但它也带来了较高的计算成本和推理延迟,这使得它难以在实际场景中部署。例如,在一个电子商务搜索系统中,由于有数百万个好的查询对,使用基于交互的模型对这些对进行评分需要花费数十天的时间。相反,基于表示的模型(Chen等人,2020;Reimers和Gurevych,2019;Khattab和Zaharia,2020)由两个孪生编码器独立编码文本对,没有任何交互。
因此,它支持嵌入的离线计算,这大大减少了在线延迟,从而使此类模型在实践中有用。幸运的是,没有任何交互的独立编码可能会丢失匹配信号,从而导致严重的表现下降。
为了平衡效率和功效,有几项工作试图为孪生结构配备交互模块。已经提出了各种交互策略,例如注意力层(Humeau等人,2020)和transformer层(Cao等人,2020;Chen等人,2020)。然而,出于效率考虑,这些交互模型是在孪生编码器之后添加的,为了保留孪生特性,仍然忽略了孪生编码器编码过程中的交互。因此,丰富的交互信号丢失,现有的基于表示的模型在匹配精度方面仍然远远落后于基于交互的模型。
在这项工作中,我们试图打破基于交互的模型和基于表示的模型之间的困境。关键思想是在基于表示的模型中整合孪生语编码过程中的交互,而不破坏孪生语结构。为此,我们提出了虚拟交互(VIRT),这是一种新的机制,将文本对交互中的知识转移到基于表示的模型的孪生编码器中。具体来说,孪生编码器通过模拟完整的交互来学习文本对之间的交互信息,并以基于交互的模型传递的知识为指导。我们将知识转移作为训练期间的注意力图提取任务来实现,在推理期间可以删除该任务,以保持孪生属性。因此我们称之为“虚拟交互”。此外,为了进一步利用孪生语编码后学习到的交互知识,我们进一步设计了一种VIRT自适应交互策略。我们基于一个基于表示的模型,即VIRT-编码器,共同实现VIRT和VIRT自适应交互策略,如图1(c)所示。
总之,我们的贡献可以总结如下:•我们提出了一种新的虚拟交互机制VIRT,通过将基于交互的模型中的注意力图提取到基于表示的模型的孪生en-coders中来整合完整交互,而无需额外的推理成本。
•大量实验表明,我们提出的VIRT编码器优于以前基于SOTA表示的模型,同时保持了推理效率。
•VIRT可以轻松集成到其他基于表示的文本匹配模型中,以进一步提高其表现。
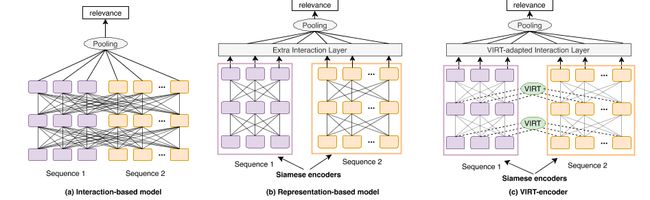
图1:说明文本匹配范例的示意图。该图将现有方法(子图(a)和(b))与拟议的模型(子图(c))进行了对比。
2相关工作
2.1文本匹配模型
文本匹配模型通常以两个文本序列作为输入,并确定其语义关系。最近,基于transformer的模型,例如BERT(Devlin等人,2019),利用自注意力在几个文本匹配任务上实现了良好的表现。作为一种典型的基于交互的模型,BERT将文本对连接为输入,并在其[CLS]输出token上构建非线性分类器,以预测匹配标签(Nogueira和Cho,2019)。然而,BERT具有较高的计算成本和推理延迟。为了满足效率要求,句子BERT(Reimers和Gurevych,2019)利用BERT作为孪生编码器来构建基于表示的模型。这种模型可以进行文本嵌入的预计算,并获得更高的推理效率,同时表现显著下降。因此,最近的许多工作都致力于提高基于表示的模型的表现。一些方法在孪生编码器之后引入交互层,可以概括为“额外交互”。
通过各种额外的交互策略对不同的文本匹配任务进行了改进,例如涉及注意力层(Humeau等人,2020),甚至引入了几个transformer层(Chen等人,2020;Cao等人,2020)。然而,编码过程中丰富的交互信息,即孪生编码器之间的交互,仍然被忽视。据我们所知,我们提出的VIRT是第一个将交互引入孪生编码器编码过程的工作。
注意,最近信息检索领域广泛采用了基于表示的模型(Khattab和Zaharia,2020;Tang等人,2021;Qu等人,2021;Xiong等人,2021)。
根据(Khattab和Zaharia,2020;Qu等人,2021)的实验结果,添加额外的交互层或构建负样本可以显著提高基于表示的模型的表现,使其在IR任务中取得比基于交互的模型更好的结果。这些结果验证了在缺乏充分交互的情况下不存在IR任务的瓶颈。相反,文本匹配任务(例如自然语言推理)需要区分更复杂的关系,这些关系最终对两个序列之间的细粒度交互信息敏感。此外,由于许多文本匹配数据通常需要详细的人类知识,因此自动构建高质量的负样本是可行的。为此,在以下几节中,我们不会将我们的模型与那些IR模型进行比较。
2.2知识提炼
知识提炼(Hinton等人,2015;Tang等人,2019)是将知识从质量更好的教师模型转移到不太复杂的学生模型。(焦等人,2020年;桑等人,2019年;孙等人,2019年、2020年)通过提取预测logit和隐藏状态,将BERT压缩为具有更少transformer层和更小隐藏大小的微小结构。然而,在这些工作中,教师模型和学生模型都是基于交互的模型,这仍然限制了文本匹配场景的效率,尤其是在在线应用中。
为了在保持效率的同时获得更好的表现,一些研究人员尝试将知识从基于交互的模型提取到基于表示的模型。DiPair(Chen等人,2020)通过Light transformer层执行额外交互,并从基于交互的模型中提取预测的Logit。变形器(Cao等人,2020)采用多个transformer层作为额外的交互层,并从基于交互的模型中提取表示和预测的对数。
然而,这些方法仅将基于交互的模型中的logits/representation提取到基于表示的模型的额外交互层。与这些现有方法不同,VIRT从基于交互的模型中提取注意力图,并将其转换为基于表示的模型的孪生编码器的编码过程。
3方法
在本节中,我们将首先描述基于交互的模型和基于表示的模型。然后,我们将介绍虚拟交互机制(VIRT),它从基于交互的模型中提取交互知识到孪生编码器。此外,通过VIRT自适应交互策略,充分利用了学习到的交互知识。VIRT的架构如图2所示。
3.1基于交互的模型
给定两个文本序列X=[X 1;…;X m]和Y=[Y 1;…;Y n]作为输入,基于交互的模型将X和Y连接到[X;Y],并用L-层transformers编码[X;Y]:H(L)=Trm([X;Y])。transformer的每个层由两个剩余子层组成:一个多头注意力操作(MHA)(即等式1a、等式1b)和一个前馈网络(FFN)(即等式1c):
![]()
![]()
![]()
Att(·)在![]() 之后计算注意力映射
之后计算注意力映射![]()
![]() ,其中dis是隐藏状态的维数。为了便于描述,我们省略了批量大小和注意力头的维度。
,其中dis是隐藏状态的维数。为了便于描述,我们省略了批量大小和注意力头的维度。![]()
![]() 。
。
是第(l-1)层的中间表示,它对X和Y之间的交互信息进行编码。Q(l)、K(l)和V(l)是第l个层的注意力参数,从H(l)映射而来− 1) . LN(·)表示层归一化操作。
如我们所见,基于交互的模型能够通过全注意力机制将交互信息编码到X和Y的表示中。具体而言,组合表示以生成注意力图M(在等式1a中),其表示不同交互信号的权重。然后根据tom选择并融合表示,作为更新的输出表示(在等式1b中)。

图2:拟议的模型架构。左部分通过从基于交互的模型中提取注意力图来展示交互式知识转移过程。右侧部分介绍了VIRT的详细信息。
3.2基于表示的模型
与基于交互的模型不同,基于表示的模型首先通过两个独立的孪生transformer编码器(这里我们假设每个编码器有L个transformer层)分别对X和Y进行编码:![]() 和
和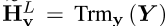 。然后,他们对孪生文编码的
。然后,他们对孪生文编码的![]() 和
和![]() 执行额外的交互。transformer的结构与基于交互的模型相同,只是注意力映射
执行额外的交互。transformer的结构与基于交互的模型相同,只是注意力映射
![]()
仅用X(或Y)单独计算:

![]()
是从H̃(l)映射的注意力参数− 1) x(或H̃(l− 1) y)。与基于交互的模型相比,编码过程中X和Y之间没有交互。
在基于表示的模型中,X和Y之间的细粒度交互信息将丢失,从而导致表现下降。
3.3虚拟交互
如前所述,基于表示的模型的主要缺点是在单独编码两个输入序列时缺乏交互。直观上,基于交互的模型通过MHA机制执行交互,如(等式1a,等式1b)。M(l)通过对应于X和Y的表示来计算。与基于交互的模型相比,基于表示的模型仅通过x(或y)单独计算M̃(l)x(或M̃(l)y)。在接下来的部分中,我们将首先详细说明这两种模型在MHA操作方面的差异。接下来,我们介绍了VIRT机制,该机制可以在不增加额外推理成本的情况下改进基于表示的模型。
我们首先在基于交互的模型中分解MHA操作,如图2(b)中的蓝色注意力图所示。具体来说,在基于交互的模型中,第l个层的输入表示,即H(l− 1) 在等式1a中,可以分解为X部分和Y部分。
我们在
![]()
和
![]()
之后重写
![]()
,其中H(l− 1) x对应于x和H(l)的表示− 1) y对应于y的表示。基于此,注意力参数也可以重写为X部分(表示为Q(l)X和K(l)X)和Y部分(根据等式1a表示为![]() 和
和![]() )的组合,softmax(·)操作之前的最终注意力分数(表示为S(l))可以分解为以下分区矩阵:
)的组合,softmax(·)操作之前的最终注意力分数(表示为S(l))可以分解为以下分区矩阵:

,其中![]() 和
和![]() (或
(或![]() 和
和
![]() )是注意力从
)是注意力从
![]()
或![]()
映射的参数S(l)的四个分割矩阵块遵循
![]()
2,。
![]() ,其等效于以下表达式:
,其等效于以下表达式:

尤其是![]() 和
和![]() 是仅在X或Y中执行的MHA操作,其对应于等式2中基于表示的模型中的MHA操作。
是仅在X或Y中执行的MHA操作,其对应于等式2中基于表示的模型中的MHA操作。![]() 和
和![]() 是指基于交互的模型中X和Y之间的交互,它们负责用交互信息丰富表示。然而,它们在基于表示的模型中缺失(如图2(b)中缺失的注意力图所示),从而导致这两种模型之间的表现差距。
是指基于交互的模型中X和Y之间的交互,它们负责用交互信息丰富表示。然而,它们在基于表示的模型中缺失(如图2(b)中缺失的注意力图所示),从而导致这两种模型之间的表现差距。
通过上述分析,可以将基于表示的模型的缺失交互提取为X和Y之间的MHA操作。为了恢复这种缺失的交互,我们让基于表示的模型模拟等式4中的交互,使用等式2中的注意力参数如下:

,其中![]() 表示
表示![]() 参与
参与![]() 生成的注意力图,
生成的注意力图,![]() 表示
表示![]() 参与
参与![]() 生成的注意力图。
生成的注意力图。
这两个额外的注意力图表示基于表示的模型中缺失的交互信号,该模型负责在以下操作中更新表示。由于我们希望提高基于表示的模型向基于交互的模型的表现,我们建议将缺失的注意力图与其在基于交互的模型中已经存在的对应物对齐。基于交互的模型中的注意力图可以引导表示
![]()
朝着交互丰富的方向进化,就好像表示在编码过程中相互交互一样。通过这种方式,我们在交互过程中提取知识,并将其转移到双编码器中,而不需要任何额外的推理计算成本。这就是为什么我们称这种机制为“虚拟交互”。
为了实现VIRT,我们采用了知识提取技术,其中一个基于训练的交互的模型被视为教师,一个需要训练的基于表示的模型被视为学生。根据等式4,S(l)x→ y和S(l)y→ x对应于基于交互的模型中x和Y之间的交互。它们可以直接从softmax(·)之前的注意力分数中获得:S(l)x→ y是S(l)的前m行和后n列部分,S(l)y→ x对应于最后n行和前m列。我们直接挑选这两个切片,再加上软最大操作,从基于交互的模型中形成引导注意力图:
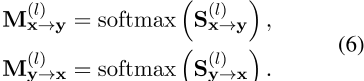
![]() 进一步作为监督交互知识转移,以引导VIRT,即基于表示的模型中的等式5。具体来说,目标是最小化
进一步作为监督交互知识转移,以引导VIRT,即基于表示的模型中的等式5。具体来说,目标是最小化![]() 和
和
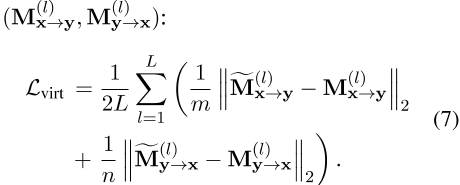
之间所有注意力头部的L2距离。注意,我们在训练阶段仅将等式7作为优化目标,并在推理过程中删除。这保留了基于表示的模型的孪生特性,同时不会带来额外的推理成本。
3.4 VIRT自适应交互
通过VIRT,交互知识可以深入到基于表示的模型的每个编码层中。然而,在孪生编码后,最后一个层的表示,即![]() ,仍然无法相互看到,因此缺乏明确的交互。为了充分利用学习到的交互知识,我们进一步设计了一种适应VIRT的交互策略,该策略在VIRT学习到的注意力图的指导下融合了
,仍然无法相互看到,因此缺乏明确的交互。为了充分利用学习到的交互知识,我们进一步设计了一种适应VIRT的交互策略,该策略在VIRT学习到的注意力图的指导下融合了![]() 。
。
具体来说,我们按照等式5中的过程在![]() 和
和![]() 之间执行VIRT适应的交互。生成的注意力图公式如下:
之间执行VIRT适应的交互。生成的注意力图公式如下:

,其中池(·)表示平均池操作。
等式8采用与VIRT相同的交互策略,并进一步利用学习到的注意力图来明确更新表示。最后,我们利用简单融合来预测匹配标签
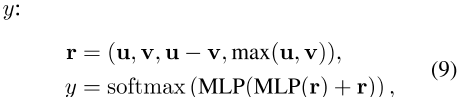
,其中(,)是串联操作,MLP表示多层感知器。训练的总体目标是最小化特定于任务的监督损失(即交叉熵损失)L任务和L virt:
![]()
的组合,其中α是衡量虚拟交互影响的超参数。
值得注意的是,VIRT是一种通用策略,可用于增强任何基于表示的匹配模型,如实验所示。
4个实验
4.1数据集
为了全面评估所提出的VIRT机制的有效性,我们在三种数据集上进行了广泛的实验,包括三个句子-句子匹配任务(MNLI、QQP、RTE)、一个问答任务(BoolQ)和两个真实世界的查询通道匹配任务(Q2P、Q2A)。
MNLI(Williams等人,2017年)是一个包含433k个句子对的大规模个性化分类数据集。目的是预测一对句子之间的关系,如蕴涵、中性或矛盾。
RTE(Bentivogli等人,2009年)数据集来自一系列关于文本含义的年度竞赛。目的是预测给定的假设是否由给定的前提引起。
QQP(Iyer等人,2019)是一个大规模句子相似性数据集,由来自Quora的40000多个潜在重复问题对组成。任务是确定这两个问题是否具有相同的含义。
BoolQ(Clark等人,2019)是一个回答是/否问题的数据集,包含15942个示例,其中的任务是对给定的问题和文档对回答是/否。
Q2P 1是一个二进制分类任务,源自MSMARCO通道排名数据(Nguyen等人,2016),包含110k个查询通道对。
给定(查询,文章)对,目标是预测文章是否包含查询的答案。原始数据集不包含标记的负样本。对于每个查询,我们从BM25检索到的前100篇文章中抽取负文章。
Q2A来自真实世界的电子商务数据集,其中包含580 K个查询广告对。
给定(查询,广告)对,目标是预测广告和查询之间的相关性。
4.2基线
我们采用了几种最先进的基于表示的匹配模型进行比较,如下所示。
孪生BERT是一种孪生架构,使用预先训练的BERT分别生成两个输入的嵌入。将两个序列的合并输出嵌入连接起来,以给出最终预测。
DeFormer(Cao等人,2020)是一种基于BERT分解的模型,它将完全自注意力分解为BERT的下层中的两个独立自注意力,而上层保持完全自注意力的原点。
DiPair(Chen等人,2020)是一种用于文本匹配的基于表示的快速提取模型。它通过Light transformer层执行额外的交互,该层与来自最后一个编码器层的截断嵌入输出进行馈送。
Poly编码器(Humeau等人,2020)是一种基于表示的成对文本匹配模型,它利用注意力机制在孪生编码器之后执行额外的交互。

表1:六个数据集的表现结果。变形器*表示原始设置,包含9个下层和3个上层,其结果取自原始纸张。变形器*的效率几乎与实际使用失败的BERT基相同。因此,具有11个下部层和1个上部层的变形器被设置为基线。VIRT编码器是我们提出的基于表示的模型,它融合了VIRT和VIRT自适应交互。注意,我们只报告了浮点运算和推断延迟的在线部分,因为基于表示的嵌入可以离线计算,而更关心的是真实场景中的在线延迟。由于这六个数据集上的模型采用类似的输入设置,我们报告了BoolQ上的失败和推断延迟,并忽略了其他五个。

表2:不同部件的消融分析。VIRT编码器代表了我们提出的框架。没有VIRT意味着删除等式7的优化目标。w/o VIRT-A意味着在等式8中移除VIRT适应的交互,并使用简单融合表示最后一个层,如等式9所示。
4.3实验装置
4.3.1 VIRT设置
我们使用BERT-base(Devlin等人,2019)作为VIRT的编码器主干。参数用预训练的基于伯特的模型(未分类)初始化。我们在Trm x(·)和Trm y(·)之间共享所有参数。我们还将伯特基作为基于交互的模型,该模型首先在上述数据集上进行微调,并在将交互知识转移到基于表示的模型时固定不变。预测层的BERT库池策略固定为均值池(而不是[CLS]),因为我们观察到BERT库和所有基于VIRT增强表示的模型都具有更好的表现。
4.3.2实施细节
所有基线均使用预先训练的BERT基参数初始化,并进行微调以在验证集上获得最佳结果。值得注意的是,我们将所有模型的transformer层总数固定为12,以进行公平比较,尽管一些基线,如DiPair(Chen等人,2020),以表现为代价,采用更少的层来实现极端效率。选择X和Y的前8个和前16个输出token嵌入作为DiPair的输入,这是其论文中报告的最佳设置。多边形编码器中的上下文向量数为360。对于MNLI和QQP,我们使用GLUE基准2上的标准分区和度量。对于RTE和BoolQ,我们遵循SuperGLUE 3。对于Q2P和Q2A,我们使用AUC-ROC作为评估指标,从MSMARCO通道排名数据和真实电子商务数据构建数据集。我们分割了10%的训练集,用于调整这些任务中的超参数,并报告了原始开发分割的结果。
我们使用Tensorflow 1实现所有模型。在特斯拉V100 GPU(32GB内存)上为15。六项任务的训练epochs分别设置为5、30、5、30、5、5。我们将批量设置为28。学习速率设置为5 e− 5,预热比设置为0。1.所有模型均通过Adam优化器进行优化,β1=0。9 , β 2 = 0 . 999,=1 e− 8.
为了测量在线推理延迟,我们在RTX 2080ti GPU上运行推理,批量大小设置为28。
4.4主要结果
不同方法的表现如表1所示。BERT-base作为一种强大的基于交互的模型,显示了其有效性。与BERT相比,孪生语BERT的表现显著下降。与孪生BERT相比,变形器、DiPair和多边形编码器实现了相当大的改进。最后,我们提出的VIRT编码器实现了最佳的表现,优于所有基于表示的基线,甚至与基于交互的BERT模型相比具有竞争力。这证明VIRT能够近似基于交互的模型的深度交互建模能力。
我们进一步比较了不同模型的浮点运算4(每秒浮点运算)和BoolQ数据集上的推断延迟,这也列于表1中。根据结果,与基于交互的模型相比,所有基于表示的模型都显示出显著的加速。加速主要得益于孪生编码器,该编码器支持对-fline进行嵌入计算。孪生语BERT的推理速度最快,但却有严重的表现偏差。由于额外交互层的计算复杂性,变形器和Dipair获得相对较高的浮点。Dipair在交互层之前将序列截断到更少的长度,这在在线延迟方面产生了极好的加速。Poly编码器显著提高了表现,但计算量略有增加。与所有基线相比,我们的模型在保持高效率的同时,在表现方面显示出优越性。

表3:VIRT应用于不同基于表示的模型的表现增益。↑ 表示VIRT带来的表现增益,而-表示平坦效应。
4.5消融研究
表2显示了我们提出的VIRT以及VIRT适应的相互作用的贡献。在不使用VIRT或VIRT自适应交互的情况下,表现的下降表明了这两种架构的有效性。对于MNLI和RTE,由于删除VIRT适应的交互而导致的表现下降更为严重。一个潜在的原因是MNLI和RTE是自然语言推理任务,需要更细粒度的匹配信号,并且严重依赖于显式交互。对于QQP、BoolQ和Q2A,VIRT适应的交互作用影响较小。然而,VIRT仍然带来了实质性的改进,这进一步验证了合并交互的有效性。
4.6对所有基于表示的模型的好处
为了验证所提出的VIRT的通用性,我们进一步将其导入到上述基于表示的模型中。我们将等式7中的优化目标应用于不同的基线,结果如表3所示。根据结果,我们可以观察到VIRT可以很容易地集成到其他基于表示的文本匹配模型中,以进一步提高表现。
结合表2的结果,我们还可以发现VIRT编码器从VIRT中获益最为显著。这表明,将VIRT合并到基于表示的模型中的最佳方法是执行与VIRT一致的额外交互。
5结论
基于表示的模型由于效率高而被广泛应用于文本匹配任务中,而基于交互的模型由于缺乏交互而执行不足。以前的工作经常引入额外的交互层,而孪生编码器中的交互仍然缺失。在本文中,我们提出了一种虚拟交互(VIRT)机制,该机制可以通过从基于交互的模型中提取注意力图到基于表示的模型的孪生编码来近似交互建模能力,而无需额外的推理成本。所提出的VIRT编码器采用VIRT以及VIRT自适应交互策略,在多个文本匹配任务上实现了现有基于表示的模型中最先进的表现。
此外,VIRT对现有的基于表示的模型进行了进一步改进。
参考文献
Luisa Bentivogli, Ido Dagan, Hoa Trang Dang, Danilo Giampiccolo, and Bernardo Magnini. 2009. The fifth pascal recognizing textual entailment challenge. In In Proc Text Analysis Conference (TAC’09 .
Qingqing Cao, Harsh Trivedi, Aruna Balasubrama- nian, and Niranjan Balasubramanian. 2020. De- former: Decomposing pre-trained transformers for faster question answering . In Proceedings of the 58th Annual Meeting of the Association for Compu- tational Linguistics, ACL 2020, Online, July 5-10, 2020 , pages 4487–4497. Association for Computa- tional Linguistics.
Jiecao Chen, Liu Yang, Karthik Raman, Michael Ben- dersky, Jung-Jung Yeh, Yun Zhou, Marc Najork, Danyang Cai, and Ehsan Emadzadeh. 2020. Dipair: Fast and accurate distillation for trillion-scaletext matching and pair modeling. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings , pages 2925–2937.
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. Boolq: Exploring the surprising difficulty of natural yes/no questions . In proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Lin- guistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages 2924–2936, Min- neapolis, Minnesota. Association for Computational Linguistics.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding . In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages 4171–4186, Minneapolis, Minnesota. association for Computational Linguistics.
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 .
Samuel Humeau, Kurt Shuster, Marie-Anne Lachaux, and Jason Weston. 2020. Poly-encoders: Architec- tures and pre-training strategies for fast and accurate multi-sentence scoring . In 8th International conference on Learning Representations, ICLR 2020, Ad- dis Ababa, Ethiopia, April 26-30, 2020 . OpenRe- view.net.
Shankar Iyer, Nikhil Dandekar, , and Ko- rnl Csernai. 2019. Quora question pairs. https://www.quora.com/q/quoradata/ .
Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. 2020. Tinybert: Distilling BERT for natural language understanding . In Findings of the Association
for Computational Linguistics: EMNLP 2020, online Event, 16-20 November 2020 , volume EMNLP 2020 of Findings of ACL , pages 4163–4174. association for Computational Linguistics.
Omar Khattab and Matei Zaharia. 2020. Colbert: efficient and effective passage search via contextual- ized late interaction over bert. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval , pages 39–48.
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. MS MARCO: A human generated machine reading comprehension dataset . In Proceedings of the Workshop on Cognitive Computation: integrating neural and symbolic approaches 2016 co- located with the 30th Annual Conference on Neu- ral Information Processing Systems (NIPS 2016), Barcelona, Spain, December 9, 2016 , volume 1773 of CEUR Workshop Proceedings . CEUR-WS.org.
Rodrigo Nogueira and Kyunghyun Cho. 2019. passage re-ranking with bert. arXiv preprint arXiv:1901.04085 .
Barun Patra. 2017. A survey of community question answering. arXiv preprint arXiv:1705.04009 .
Yingqi Qu, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Wayne Xin Zhao, Daxiang Dong, Hua Wu, and Haifeng Wang. 2021. Rocketqa: An optimized training approach to dense passage retrieval for open- domain question answering . In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics:
Human Language Technologies, NAACL-HLT 2021, Online, June 6-11, 2021 , pages 5835–5847. association for Computational Linguistics.
Nils Reimers and Iryna Gurevych. 2019. Sentence- bert: Sentence embeddings using siamese bert- networks. arXiv preprint arXiv:1908.10084 .
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108 .
Siqi Sun, Yu Cheng, Zhe Gan, and Jingjing Liu. 2019. Patient knowledge distillation for bert model com- pression. arXiv preprint arXiv:1908.09355 .
Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou. 2020. Mobilebert: a compact task-agnostic bert for resource-limited de- vices. arXiv preprint arXiv:2004.02984 .
Hongyin Tang, Xingwu Sun, Beihong Jin, Jingang Wang, Fuzheng Zhang, and Wei Wu. 2021. improving document representations by generating pseudo query embeddings for dense retrieval. In proceedings of the 59th Annual Meeting of the Association
for Computational Linguistics and the 11th international Joint Conference on Natural Language Pro- cessing, ACL/IJCNLP 2021, (Volume 1: Long Pa- pers), Virtual Event, August 1-6, 2021 , pages 5054– 5064. Association for Computational Linguistics.
Raphael Tang, Yao Lu, Linqing Liu, Lili Mou, Olga Vechtomova, and Jimmy Lin. 2019. Distilling task- specific knowledge from bert into simple neural net- works. arXiv preprint arXiv:1903.12136 .
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. arXiv preprint arXiv:1706.03762 .
Sean Welleck, Jason Weston, Arthur Szlam, and Kyunghyun Cho. 2019. Dialogue natural language inference. In Proceedings of the 57th Annual meeting of the Association for Computational Linguistics , pages 3731–3741.
Adina Williams, Nikita Nangia, and Samuel R Bow- man. 2017. A broad-coverage challenge corpus for sentence understanding through inference. arXiv preprint arXiv:1704.05426 .
Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul N. Bennett, Junaid Ahmed, and Arnold Overwijk. 2021. Approximate nearest neighbor negative contrastive learning for dense text re- trieval . In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021 . OpenReview.net.
Guangyou Zhou, Li Cai, Jun Zhao, and Kang Liu. 2011. Phrase-based translation model for question retrieval in community question answer archives. In proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , pages 653–662.