Large Dual Encoders Are Generalizable Retrievers
Large Dual Encoders Are Generalizable Retrievers(arXiv)
原文地址:https://arxiv.org/pdf/2112.07899.pdf
Motivation
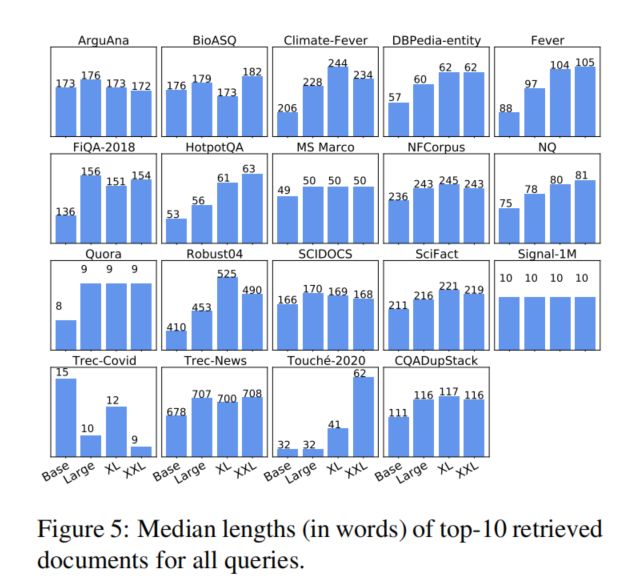
之前的研究发现,在一个领域上训练的双塔模型通常不能泛化到其他领域的检索任务。一种普遍的看法是双塔模型的bottleneck layer (点积操作层) 太过受限以至于双塔模型不能成为有好的领域外泛化能力的检索模型。本文通过 固定bottleneck向量大小,增加双塔模型的容量 来挑战这种看法。(模型的容量增大,但是query和document的交互依然只是通过点积操作)。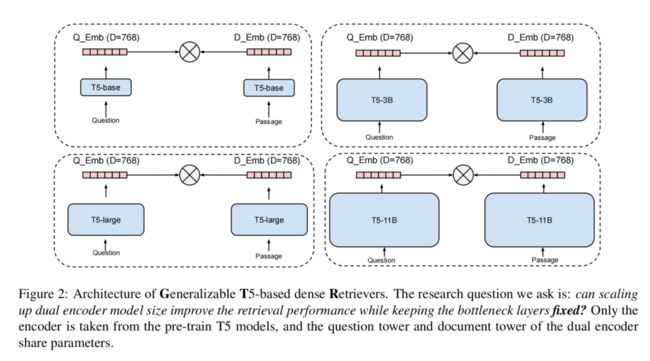
Generalizable T5 Retriever (GTR)
T5 dual encoder
因为T5模型方便使用,并且具有参数量从数百万到数十亿级别的不同版本,所以本文使用预训练完成的T5模型作为主干encoder。
对于给定的样例集 D = { ( q i , p i + ) } D = \{(q_i, p_i^+)\} D={(qi,pi+)},其中 q i q_i qi 是输入问题, p i + p_i^+ pi+ 是一个相关的文档。首先将问题和文档输入到T5的encoder中,将encoder的mean pooling作为输出。在本文的所有实验中,输出向量维度均为768。
本文使用in-batch sampled softmax loss来训练模型:
L = e s i m ( q i , p i + ) / τ ∑ j ∈ β e s i m ( q i , p i + ) / τ \mathcal{L} = \frac{e^{sim(q_i, p_i^+)/\tau}}{\sum_{j\in\beta}e^{sim(q_i, p_i^+)/\tau}} L=∑j∈βesim(qi,pi+)/τesim(qi,pi+)/τ
其中,相似度评分函数 s i m sim sim是cos相似度。 β \beta β 是mini-batch中的样例, τ \tau τ 是softmax温控(本文设置为0.01)。
本文还应用了双向的in-batch sampled softmax loss,即同时计算问题到文档匹配和文档到问题匹配的loss。
Multi-stage training
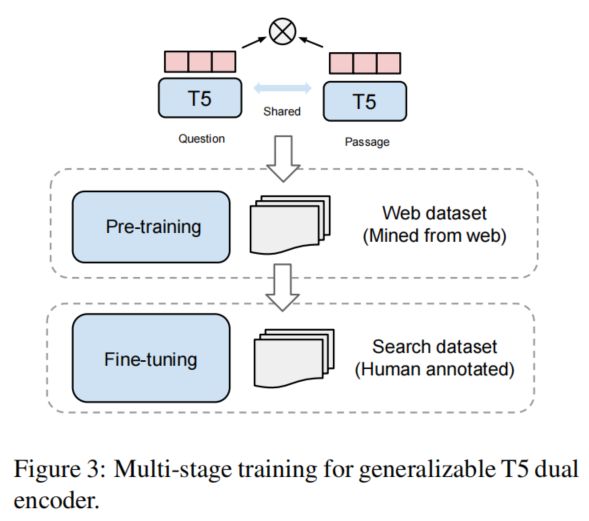
GTR在网络上挖掘的语料上进行预训练,在检索数据集上进行fine-tuning。网络上挖掘的预料包含了大量的半结构化数据对(如问答对、对话等等),这些数据很容易收集但经常不是被很好地标注过。而检索数据集被人为标注过,质量很高但是不易得到。
在预训练阶段,我们使用T5模型来初始化双塔模型,然后在网络上收集到的问答对数据上进行训练。我们使用T5 encoder的mean pooling结果来编码问题和文档。
fine-tuning阶段的目标是使用高质量的检索语料库让模型学习更好地匹配通用查询和文档,因此本文考虑了两个数据集:MS Marco和NQ。
Experiments
Training Data
Community QA
从网络上收集的输入-相应对和问答对,共20亿数据用来预训练双塔模型。
MS Marco
包含了532K个查询-文档对,考虑用来做fine-tuning。
NQ
包含了130K个查询-文档对,考虑用来做fine-tuning。
Configurations
本文使用了不同大小的T5模型:Base, Large, XL, XXL (仅使用T5的encoder部分)
模型的参数量如表1所示:

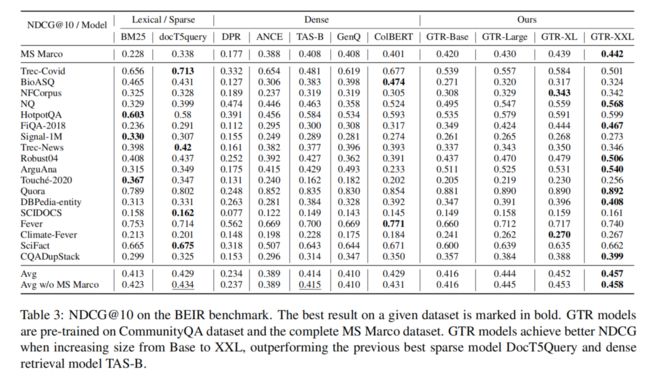
Results

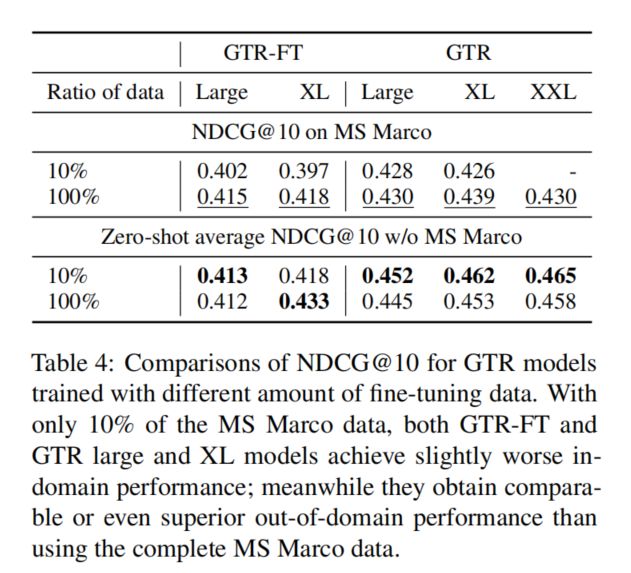
Ablation Study
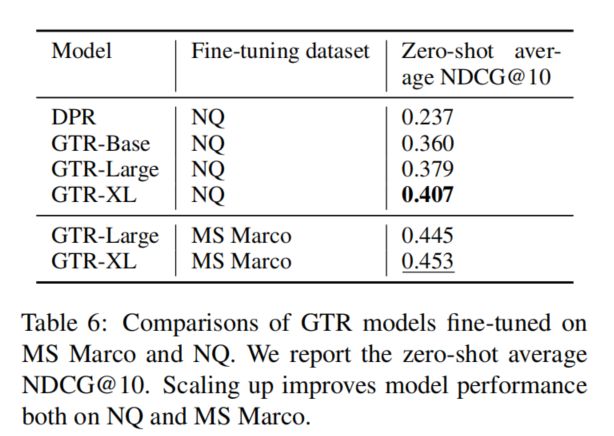
GTR both fine-tune and pre-training
GTR-FT fine-tune only
GTR-PT pre-training only