深度学习:zero-shot-learning(二)LDF_cvpr2018
https://blog.csdn.net/cp_oldy/article/details/81607884
https://baijiahao.baidu.com/s?id=1596522553301644906&wfr=spider&for=pc
https://blog.csdn.net/cp_oldy/article/details/82183813
通常而言,见过和没见过的类别都要提供类别描述信息(比如用户定义的属性标注、类别的文本描述、类别名的词向量等);某些描述信息是各个类别共有的。这些描述信息通常被称为辅助信息或语义表征。在本研究中,我们关注的是使用属性的 ZSL 的学习。
经典方法:
 map seen ->unseen
map seen ->unseen
典型 ZSL 方法的一个通用假设是:存在一个共有的嵌入空间,其中有一个映射函数,,定义这个函数的目的是对于见过或没见过的类别,衡量图像特征 φ(x) 和语义表征 ψ(y) 之间的相容性(compatibility)。W 是所要学习的视觉-语义映射矩阵。现有的 ZSL 方法主要侧重于引入线性或非线性的建模方法,使用各种目标和设计不同的特定正则化项来学习该视觉-语义映射,更具体而言就是为 ZSL 学习 W。
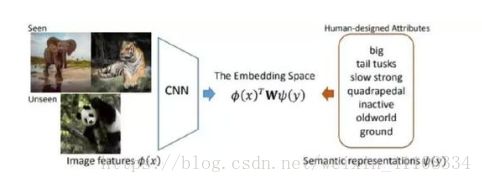
到目前为止,映射矩阵 W 的学习(尽管对 ZSL 很重要)的主要推动力是视觉空间和语义空间之间对齐损失的最小化。但是,ZSL 的最终目标是分类未见过的类别。因此,视觉特征 φ(x) 和语义表征 ψ(y) 应该可以被区分开以识别不同的目标。不幸的是,这个问题在 ZSL 领域一直都被忽视了,几乎所有方法都遵循着同一范式:1)通过人工设计或使用预训练的 CNN 模型来提取图像特征;2)使用人类设计的属性作为语义表征。这种范式存在一些缺陷。
第一,图像特征 φ(x) 要么是人工设计的,要么就是来自预训练的 CNN 模型,所以对零样本识别任务而言可能不具有足够的表征能力。尽管来自预训练 CNN 模型的特征是学习到的,然而却受限于一个固定的图像集(比如 ImageNet),这对于特定 ZSL 任务而言并不是最优的。
第二,用户定义的属性 ψ(y) 是语义描述型的,但却并不详尽,因此限制了其在分类上的鉴别作用。也许在 ZSL 数据集中存在一些预定义属性没有反映出来的鉴别性的视觉线索,比如河马的大嘴巴。另一方面,如图 1 所示,「大」、「强壮」和「大地」等被标注的属性是很多目标类别都共有的。这是不同类别之间的知识迁移所需的,尤其是从见过的类别迁移到没见过的类别时。但是,如果两个类别(比如豹和虎)之间共有的(用户定义的)属性太多,它们在属性向量空间中将难以区分。
第三,现有 ZSL 方法中的低层面特征提取和嵌入空间构建是分开处理的,并且通常是独立进行的。因此,现有研究中很少在统一框架中考虑这两个组分
《Discriminative Learning of Latent Features for Zero-Shot Recognition》cvpr 2018
使用鉴别性特征实现零样本识别:在学习了已定义标签的同时,学习了隐含属性。
隐形属性 latent attribute
零样本学习(ZSL)的目标是通过学习图像表征和语义表征之间的嵌入空间来识别未曾见过的图像类别。多年以来,在已有的研究成果中,这都是学习对齐视觉空间和语义空间的合适映射矩阵的中心任务,而学习用于 ZSL 的鉴别性表征的重要性却被忽视了。在本研究中,我们回顾了已有的方法,并表明了为 ZSL 的视觉和语义实例学习鉴别性表征的必要性。我们提出了一种端到端的网络,能够做到:
1)通过一个缩放网络自动发现鉴别性区域;
2)在一个为用户定义属性和隐含属性引入的扩增空间中学习鉴别性语义表征。我们提出的方法在两个有挑战性的 ZSL 数据集上进行了大量测试,实验结果表明我们提出的方法的表现显著优于之前最佳的方法。(facenet 鉴别性三联子)
1、Introduction
已有方案的缺点(drawbacks):
1,在映射前,抽取图像的特征,传统的用预训练模型等方法仍不是针对ZSL特定抽取特征的最优解。
2,现有的都是学习用户定义属性,而忽略了隐含表示。
3,低层次信息和空间是分离训练的,没有大一统的框架。
本文便是对应着解决了以上问题。
贡献:
- 一种级联式放大机制,可用于学习以目标为中心的区域的特征。我们的模型可以自动识别图像中最具鉴别性的区域,然后在一个级联式的网络结构中将其放大以便学习。通过这种方式,我们的模型可以专注于从以目标为焦点的区域中学习特征。
- 一种用于联合学习隐含属性和用户定义的属性的框架。我们将隐含属性的学习问题形式化为了一个类别排序问题,以确保所学习到的属性是鉴别性的。同时,在我们模型中,鉴别性区域的发掘和隐含属性的建模是联合学习的,这两者会互相协助以实现进一步的提升。
- 一种用于 ZSL 的端到端网络结构。所获得的图像特征可以调整得与语义空间更加兼容,该空间中既包含用户定义的属性,也包含隐含的鉴别性属性。
———————————————————————————————Our Method - Latent Discriminative Features Learning(LDF)
-

Notation:
FNet (The Image Feature Network) :图像特征网络,提取图像特征;
ZNet(The Zoom Network): 缩放网络,定位最具判别性的区域并将其放大;
ENet(The Embedding Network): 嵌入网络,用于构建视觉信息和语义信息关联在一起的嵌入空间,将图像特征映射到另一个空间。
-
对于第一个尺度,FNet 的输入是原始尺寸的图像,ZNet 负责生成放大后的区域。然后到第二个尺度,放大后的图像区域成为 FNet 的输入,以获得更具鉴别性的图像特征
-
我们提出的隐含鉴别性特征(LDF)学习模型的框架。从粗略到精细到图像表征被同时投射到用户定义的属性和隐含属性中。用户定义的属性通常是不同类别共有的,而隐含属性是为区分而通过调整类别间或类别中的距离而学习到的。(triple )
-
问题
1. ZNet是如何定位判别性区域的?下面我们先介绍各个子网络
FNet
FNet的目标就是提取图像特征。文章选择了已有的VGG19/GoogleNet。
ZNet
动机
已有研究表明对目标的区域进行学习,有利于图像级的目标分类。受此启发,我们假设图像中存在判别性区域有助于ZSL。ZNet的目标是定位到能够增强我们提取的特征的辨识度的区域,这个区域同时也要与某一个我们已经定义好了的属性对应。
- ZNet的输入是FNet的最后一个卷积层的输出。
- 在这里运用某个已有的激活函数方法,将我们定位好了的区域提取出来,即将裁剪操作在网络中直接实现。
- 将ZNet的输出与输入图像 origin img做按像素的矩阵乘法element-wise的乘法。
- 最后,将region zoom 到与original img相同的尺寸。将区域放大到与输入图像相同的尺寸。
-
如图2所示,再将ZNet的输出输入到另一个FNet(第一个FNet的拷贝)
ENet
ENet的目的是学习一个能够将视觉和语义信息关联起来的嵌入空间。
-
这里作者提出了一个score用于衡量img feature和attribute space的相似性(兼容性)
-
作者提出了一个兼容性得分。
-
s=
-
其中,ϕ(x)是FNet输出的d维的图像表示,ay是注释属性向量。
-
Enet将img feature映射到2k dim的空间中,1k是对应于已经定义了的label,并用softmax loss。 另1k则是对应潜藏属性,为了使这些特征discriminative,作者使用了triplet loss。
兼容性得分的物理意义是什么?
答:衡量一张图像在属性空间的投影和类别的定义/隐含属性之间的相似性(兼容性)。
Enet将图像特征映射到2k维度的空间中。其中,1k维对应于用户定义属性(UA),并用softmax loss;另1k维则是对应隐含属性,为了使这些特征具有判别性,作者使用了triplet loss。
为什么UA是softmax loss,而LA是triplet loss?
答:Ua是已见类的属性标签,隐含属性是没有实际属性。如何学习2k维属性的?
答:学习一个W,通过调整网络中的参数。
Reference
1.论文地址
2.论文笔记1 - 知乎
3.论文笔记2 - RexKing6’s Note
4.论文笔记3 - 雪花新闻
5.什么是 One/zero-shot learning?
Q&A
1. 隐含特征的“特征”指的是图像/视觉特征吗?
这里的特征,我理解包含两方面,一个是隐含的视觉特征,一个是隐含的属性特征。
2. [4.1] Fnet对性能的提升有多大?
从表1中的,自对比实验看,有4%的提升(AwA数据集)和9%的提升(CUB数据集)。
3. [4.2] ZNet是如何使得到的区域,既有判别性,又有语义信息?
直观想法:目标区域期望包含一些背景信息来增强属性嵌入。
具体做法:
4. [4.2] 为什么使用两个堆叠的全连接层?
有激活函数,所以是非线性
5. [4.2] 逐元素乘法的作用?
6. [4.3] ZNet是如何使得到的区域,既有判别性,又有语义信息?
目标中心区域+背景
7. [Table 1] VGG比GoogLeNet好?
8. [Appendices] AU→T和 AS→T是怎么计算的?
原文:AU→T indicates the accuracies of classifying test images from unseen classes into the joint label space
是如何计算的?
9. 实验中,cZSL设定下MCAMCA在50%左右,为什么gZSL中的MCAtMCAt只有不到20%?
重点详解
1、网络结构流程

从 fnet znet enet 称为一次 one-scale network
从 fnet znet fnet znet --- enet 称为两次 即有后文的
two-scale network

1、faature fnet 提取特征 n维向量,送入znet 提取【zx zy zs】 正方形中心 x y 轴 和长度
(后文提到用fast rcnn 之类的提取特征的方法在本文中没有直接做回归来的准确度高,所以本文用回归的方法)
![]()
2、想在原图中crop原图,获取区域zoom图像,但是不可偏导,为了使得end-to-end 所以采用

获得图后,使得与原图一样大小,采用双线性插值运算 znet。
双线性插值运算
3、如何得到 预测LA
两个损失函数 att lat

例如:
训练集 30类 att 30维根据softmax loss 训练获得
训练集 30类 lat 30维根据 triplet loss 训练获得
测试集 10类 att 30维同样可以得出参数
测试集 10 lat 则30维,则根据计算得出,假定训练集合测试集的att 存在一定的关系W,则训练集合测试的lat 也存在这样的关系W。


4、triplet loss
欧式距离
Triplet Loss翻译为三元组损失,其中的三元也就是如下图的Anchor、Negative、Positive,如下图所示通过Triplet Loss的学习后使得Positive元和Anchor元之间的距离最小,而和Negative之间距离最大。其中Anchor为训练数据集中随机选取的一个样本,Positive为和Anchor属于同一类的样本,而Negative则为和Anchor不同类的样本
这也就是说通过学习后,使得同类样本的positive样本更靠近Anchor,而不同类的样本Negative则远离Anchor。



