2020数学建模E组校园供水系统智能管理
*附件是某校区水表层级关系以及所有水表四个季度的读数(以一定时间为间隔,如15分钟)与相应的用水数据。请利用这些信息和数据,建立数学模型,讨论以下问题:
1.统计、分析各个水表数据的变化规律,并给出校园内不同功能区(宿舍、教学楼、办公楼、食堂等)的用水特征。*
数据格式
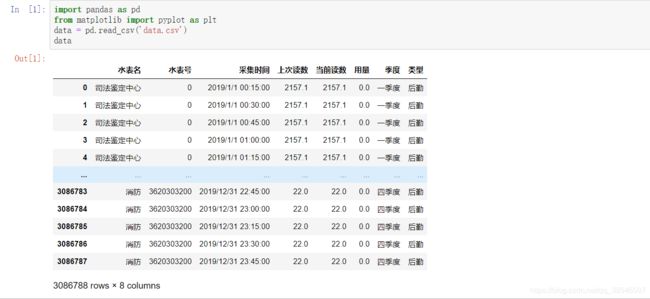
数据总共三百多万条数据,要分析的是水表的用量特征
各个区域总用水量的分析结果及代码实现

# coding: utf-8
# In[1]:
import pandas as pd
data1 = pd.read_csv('season1.csv')
data2 = pd.read_csv('season2.csv')
data3 = pd.read_csv('season3.csv')
data4 = pd.read_csv('season4.csv')
data1.head(5)
# In[2]:
data1.describe()
# In[3]:
data1.info()
# In[4]:
data1.head(5)
# In[5]:
data1.head(5)
# In[6]:
data1['水表名'].unique()
# In[7]:
lever_table = pd.read_excel("附件_水表层级.xlsx")
# In[8]:
lever_table.to_csv('lever_table.csv',index=False)
# In[9]:
level = pd.read_csv('lever_table.csv')
# In[10]:
level.head(5)
# In[11]:
level['水表名'].unique()
# In[12]:
len(level['水表名'].unique()
)
# In[13]:
len(data1['水表名'].unique())
# In[14]:
len(data2['水表名'].unique())
# In[15]:
len(data3['水表名'].unique())
# In[16]:
len(data4['水表名'].unique())
# In[17]:
data2.info()
# In[18]:
data3.info()
# In[19]:
data4.info()
# In[20]:
import numpy as np
len(data1.index)
data1['季度'] = pd.Series(["一季度" for i in range(len(data1.index))])
data1
# In[21]:
data2['季度'] = pd.Series(["二季度" for i in range(len(data2.index))])
data3['季度'] = pd.Series(["三季度" for i in range(len(data3.index))])
data4['季度'] = pd.Series(["四季度" for i in range(len(data4.index))])
# In[22]:
data4
# In[23]:
data = data1.append(data2, ignore_index=True)
data
# In[24]:
data = data.append([data3,data4],ignore_index=True)
# In[25]:
len(data['水表名'].unique())
# In[26]:
len(level['水表名'].unique())
# In[27]:
len(data1['水表名'].unique())
# In[28]:
len(data['水表号'].unique())
# In[29]:
data.head(4)
# In[30]:
level.head(4)
# In[31]:
data['水表名'].unique()
# In[32]:
len(level.index)
# In[33]:
use_water = data.groupby(by='水表名')['用量'].sum()
# In[34]:
use_water.sort_values(ascending=False)
# In[35]:
use_water.plot.hist()
# In[36]:
list_table_name = list(data['水表名'].unique())
list_table_name
# In[37]:
list_home = []
list_teaching_build = []
list_teacher_build = []
for name in list_table_name.copy():
if name.find("学生宿舍") != -1 or name.find("留学生楼") != -1:
list_home.append(name)
list_table_name.remove(name)
list_home
# In[38]:
list_table_name
for name in list_table_name.copy():
if name.find("XX") != -1 and name.find("楼") != -1:
print(name)
list_teaching_build.append(name)
list_table_name.remove(name)
list_teaching_build
# In[39]:
list_table_name
for name in list_table_name.copy():
if name.find("XX") != -1 and name.find("花") == -1:
list_teacher_build.append(name)
list_table_name.remove(name)
list_teacher_build
# In[40]:
list_agritural = []
for name in list_table_name.copy():
if name.find("养殖") != -1 or name.find("养鱼") != -1 or name.find("大棚")!=-1 or name.find("花")!=-1:
list_agritural.append(name)
list_table_name.remove(name)
list_agritural
# In[41]:
for name in list_table_name.copy():
if name.find("楼")!= -1:
list_teaching_build.append(name)
list_table_name.remove(name)
list_table_name
# In[42]:
list_backup = list_table_name
name_list = data['水表名'].tolist()
name_list
type_list = []
for name in name_list:
if name in list_backup:
type_list.append("后勤")
elif name in list_agritural:
type_list.append("农业")
elif name in list_home:
type_list.append('宿舍')
elif name in list_teacher_build:
type_list.append("活动地方")
else:
type_list.append('教学楼')
type_list
# In[43]:
data['类型'] = pd.Series(type_list)
data
# In[44]:
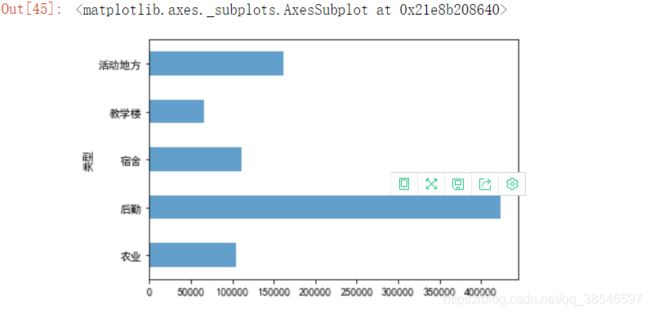
type_sum = data.groupby(by='类型')['用量'].sum()
# In[45]:
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
type_sum.plot.barh(alpha=0.7)
# In[48]:
df_group_two = data.groupby(by=['类型'])
from matplotlib import pyplot as plt
i = 0
plt.figure(figsize=(25, 35), dpi=100)
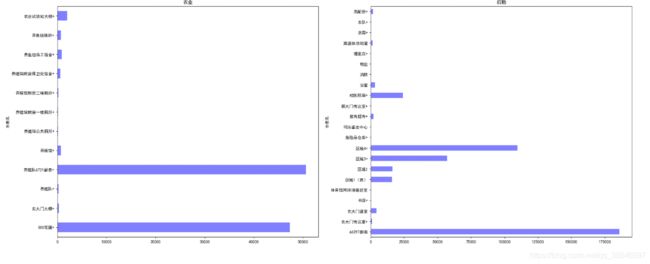
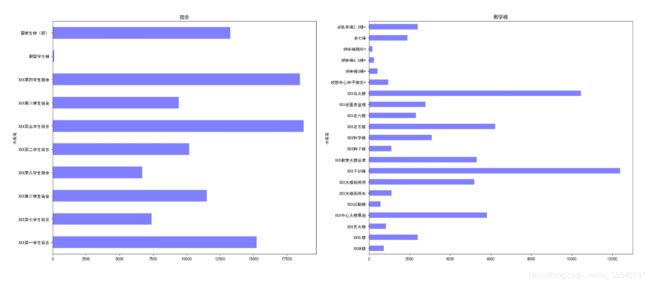
for types ,group in df_group_two:
i += 1
plt.subplot(3,2,i)
group.groupby(by='水表名').sum()["用量"].plot.barh(title=types,color='blue',alpha=.5)
plt.show()
# In[50]:
pd.read_csv('data.csv')
# In[49]:
# 判断用电层次关系
总用水量随着季度月份天时间的变化结果及代码实现
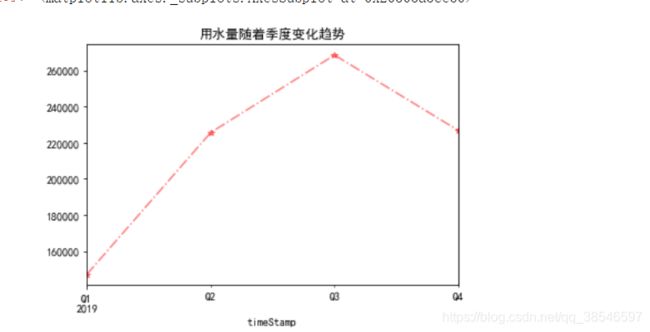
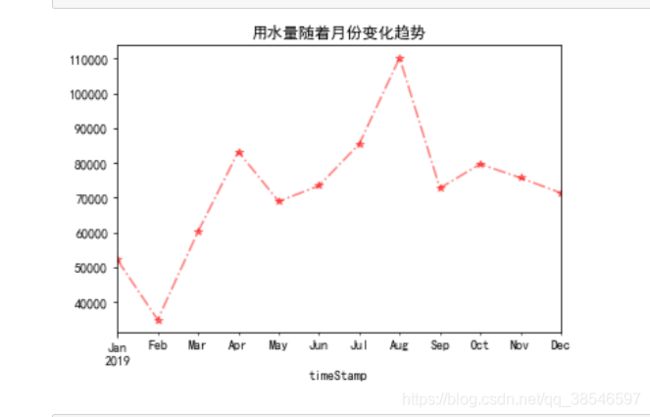

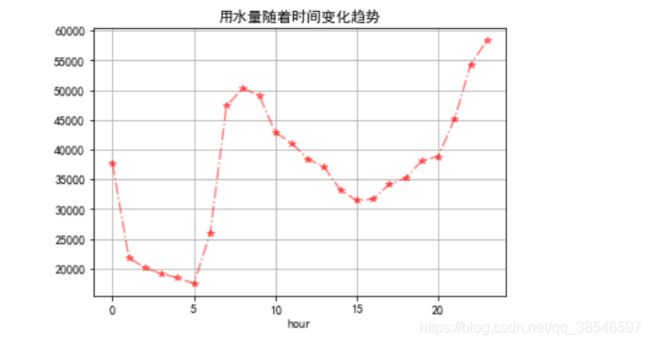
不同区域用水量随着季度月份天和时间的变化
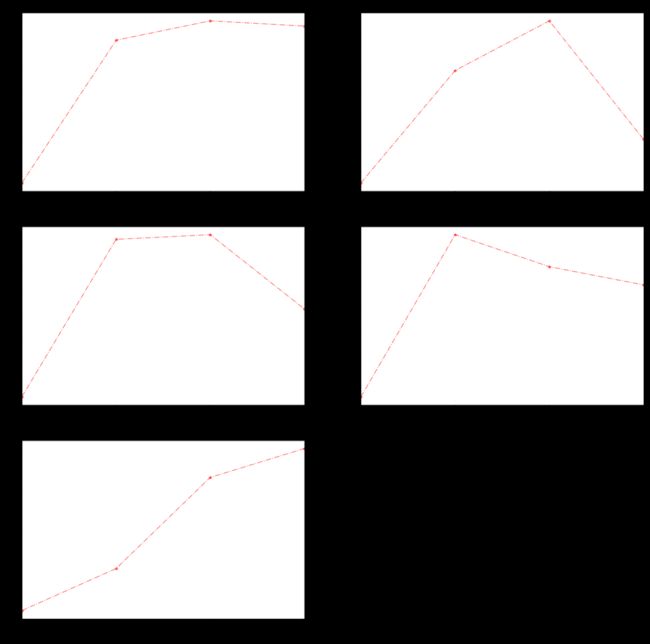
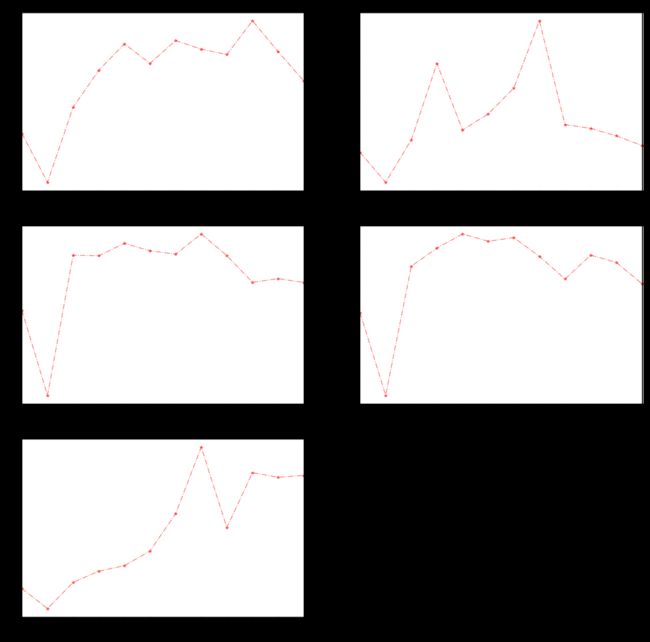
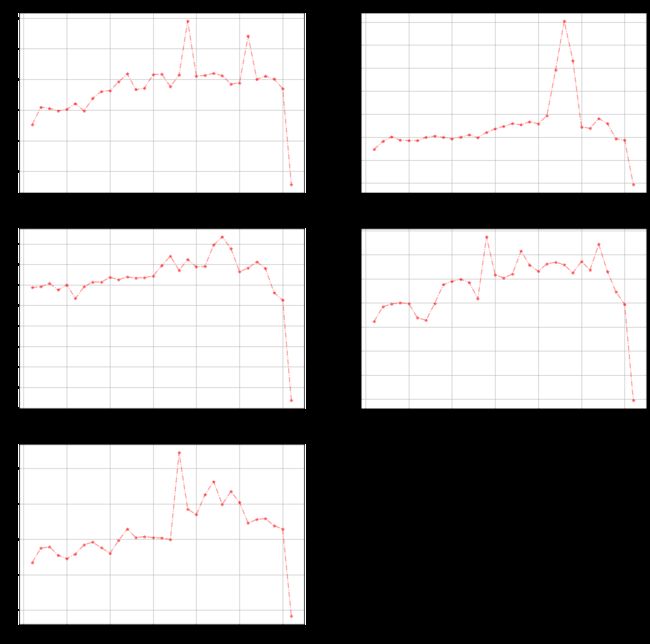
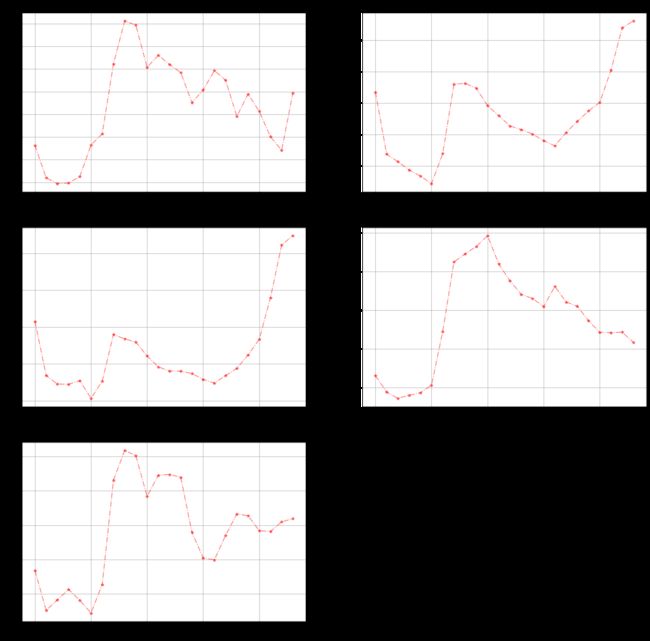
# coding: utf-8
# In[1]:
import pandas as pd
from matplotlib import pyplot as plt
data = pd.read_csv('data.csv')
data
#
# data['timeStamp'] = pd.to_datetime(data['采集时间'])
# data.set_index("timeStamp", inplace=True)
# data_month = data.resample("M",closed="right",label='right',loffset='-1')
# data_month
# for name,group in data_month:
# print("*"*30)
# print(name)
# print(group)
# print("*"*30)
# In[2]:
data['timeStamp'] = pd.to_datetime(data['采集时间'])
data.set_index("timeStamp", inplace=True)
data_quarter = data.resample("Q")
data_quarter
for name,group in data_quarter:
print("*"*30)
print(name)
print(group)
print(""*30)
# In[3]:
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
data_quarter.sum()["用量"].plot.line(style="r*-.",alpha=0.5,title="用水量随着季度变化趋势")
# In[4]:
data_month = data.resample('M').sum()["用量"].plot.line(style="r*-.",alpha=0.5,title="用水量随着月份变化趋势")
# In[5]:
for datatime in data.index:
print(datatime.month)
datatime.hour
break;
# In[6]:
data['hour'] = pd.to_datetime(data['采集时间']).dt.hour
data['day'] = pd.to_datetime(data['采集时间']).dt.day
# In[7]:
data.groupby(by='hour').sum()['用量'].plot.line(style="r*-.",alpha=0.5,title="用水量随着时间变化趋势")
plt.grid()
# In[8]:
data.groupby(by='day').sum()['用量'].plot.line(style="r*-.",alpha=0.5,title="用水量随着天变化趋势")
plt.grid()
# In[9]:
# 不同区域用水特征
# 不同区域随着季度用水变化
i = 0
plt.figure(figsize=(20, 20), dpi=100)
for index,group in data.groupby(by='类型'):
i += 1
plt.subplot(3,2,i)
group.resample("Q").sum()['用量'].plot.line(style="r*-.",alpha=0.5,title="{}用水量随着季度变化趋势".format(index))
plt.show()
# In[10]:
# 不同区域随着月份用水变化
i = 0
plt.figure(figsize=(20, 20), dpi=100)
for index,group in data.groupby(by='类型'):
i += 1
plt.subplot(3,2,i)
group.resample("M").sum()['用量'].plot.line(style="r*-.",alpha=0.5,title="{}用水量随着月份变化趋势".format(index))
plt.show()
# In[11]:
# 不同区域随着每月的天数用水变化
i = 0
plt.figure(figsize=(20, 20), dpi=100)
for index,group in data.groupby(by='类型'):
i += 1
plt.subplot(3,2,i)
group.groupby(by='day').sum()['用量'].plot.line(style="r*-.",alpha=0.5,title="{}用水量随着天数变化趋势".format(index))
plt.grid()
plt.show()
# In[12]:
# 不同区域随着每天的时辰用水变化
i = 0
plt.figure(figsize=(20, 20), dpi=100)
for index,group in data.groupby(by='类型'):
i += 1
plt.subplot(3,2,i)
group.groupby(by='hour').sum()['用量'].plot.line(style="r*-.",alpha=0.5,title="{}用水量随着时辰变化趋势".format(index))
plt.grid()
plt.show()
# In[15]:
# 判断周末和非周末用水量变化
weekday = []
for datatime in pd.to_datetime(data['采集时间']):
if datatime.weekday()!=5 and datatime.weekday()!=6:
weekday.append(0)
else :
weekday.append(1)
weekday
# In[16]:
len(weekday)
# In[17]:
data['weekday'] = pd.Series(weekday)
data
# In[18]:
data.info()
# In[19]:
data.head(5)
# In[20]:
pd.to_csv('data1.csv',index=False)
# In[21]:
data.to_csv('data1.csv',index=False)
分析周末与工作日不同区域用水变化结果及代码实现


# coding: utf-8
# In[1]:
import pandas as pd
import matplotlib.pyplot as plt
data1 = pd.read_csv('data1.csv')
data1.head(5)
# In[2]:
coll_time = pd.to_datetime(data1['采集时间'])
# In[3]:
weekday = []
for time in coll_time:
if time.weekday() != 5 and time.weekday()!=6:
weekday.append(0)
else:
weekday.append(1)
weekday
# In[4]:
data1['weekday'] = weekday
# In[5]:
data1.head(5)
# In[6]:
set(weekday)
data1['timeStamp'] = pd.to_datetime(data1['采集时间'])
data1.set_index("timeStamp", inplace=True)
data1
# In[7]:
# 根据不同weekday画图
from matplotlib import pyplot as plt
i = 0
plt.figure(figsize=(20, 20), dpi=100)
plt.rcParams['font.sans-serif'] = ['SimHei']
for index1, group1 in data1.groupby(by='类型'):
i = i + 1
plt.subplot(3,2,i)
for index2, group2 in group1.groupby(by='weekday'):
if index2==1:
group2.resample('M').mean()["用量"].plot.line(style="*-.",alpha=0.8,title="{}用水量随着月份变化趋势".format(index1),label='周末')
else:
group2.resample('M').mean()["用量"].plot.line(style="*-.",alpha=0.8,title="{}用水量随着月份变化趋势".format(index1),label='工作日')
plt.legend()
# break
# In[8]:
i = 0
plt.figure(figsize=(20, 20), dpi=100)
for index1, group1 in data1.groupby(by='类型'):
i = i + 1
plt.subplot(3,2,i)
for index2, group2 in group1.groupby(by='weekday'):
if index2==1:
group2.groupby(by='hour').mean()["用量"].plot.line(style="*-.",alpha=0.8,title="{}用水量随着时辰变化趋势".format(index1),label='周末')
else:
group2.groupby(by='hour').mean()["用量"].plot.line(style="*-.",alpha=0.8,title="{}用水量随着时辰变化趋势".format(index1),label='工作日')
plt.grid()
plt.legend()
# In[9]:
data1['time'] = pd.to_datetime(data1['采集时间']).dt.time
i = 0
plt.figure(figsize=(20, 20), dpi=100)
for index1, group1 in data1.groupby(by='类型'):
i = i + 1
plt.subplot(3,2,i)
for index2, group2 in group1.groupby(by='weekday'):
if index2==1:
group2.groupby(by='time').mean()["用量"].plot.line(style="*-.",alpha=0.8,title="{}用水量随着时间变化趋势".format(index1),label='周末')
else:
group2.groupby(by='time').mean()["用量"].plot.line(style="*-.",alpha=0.8,title="{}用水量随着时间变化趋势".format(index1),label='工作日')
plt.grid()
plt.legend()
# In[13]:
data1.to_csv('data2.csv',index=False)