多智能体强化学习——值分解方法代码流程
主要参考:
官方库:https://github.com/oxwhirl/pymarl/
大佬实现的库:https://github.com/starry-sky6688/StarCraft/
大佬的库通俗易懂
但大佬的库由于框架结构的问题,没实现double q 。
我加了一下,貌似没啥大区别;另外貌似不是很适合MPE环境...... 难顶
maddpg永远滴神
主要代码流程:
①main.py
将配置参数输入进程序 my_main(_run, _config, _log)
设置随机种子,开始运行run.py
②run.py
一大堆配置属性,进程序run_sequential(args=args, logger=logger)
③run_sequential(args, logger)
1.注册runner:默认为episode_runner
2.配置replaybuffer
3.注册controller:默认是basic_controller
4.注册learner:默认是q_learner
5.进入主循环while runner.t_env <= args.t_max
④主循环
1. episode_batch = runner.run(test_mode=False) 获取经验样本
1.reset、初始化隐藏层,进入episode循环
2.将state、avail_actions、obs放入batch中
3.计算动作,注意如果self.args.obs_last_action和self.args.obs_agent_id 为true则会
拼接至inputs中
4.env.step 获取reward、terminated,连同actions送入batch中
5.不停循环,直到terminated,batch中存了整个episode的经验
6.循环结束,把最后的state、avail_actions、obs以及action送入batch
ex7:如果是test_mode 则会log
2.把一个episode的经验样本 insert进replay buffer
3.如果已经够采样数量了,则开始训练(q_learner 训练)
1.取的数据最大长度是terminated的后一个(即包含了last_date)
但rewards、terminated之类的只到 最大长度的前一个
并且训练时候要的动作是不包含了last_action的
所以

实际上 假设一个episode长度为25
则obs、state有26(初始状态)
reward、actions、terminated有25 这些其实都不是和obs、state对应的
而mask是对应的mask[:, 0] 对应obs0
mask[:, 24] 对应obs25
terminated[:, 0] 对应obs1
terminated[:, 24] 对应obs26 所以mask这样计算
avail_actions 就是26个 后面计算时候有用
2.初始化hidden、for循环计算一个episode的agent动作

注意如果self.args.obs_last_action和self.args.obs_agent_id 为true则会
拼接至inputs中
t=0时拼接0,其他拼接t-1

算出的mac_out 有26个 包括last_data
所以去掉最后一个
![]()
3.target_out 也类似,只是去掉第一个

4.如果double q
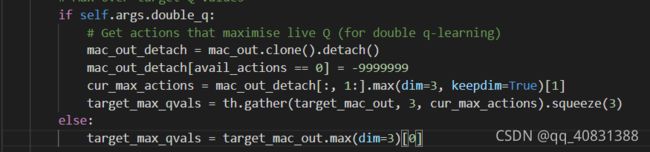
注意这边也是cur_mac_out 去掉了第一个
5.mix局部q到全局q

注意state一个去掉最后一个、一个去掉第一个
6.然后就是计算td_error 在mask掉填充的数据,开始训练
7.如果到了update_target时update,到了log就log
4.到了eval就eval,到了save就save,到了log就log