ECCV2018-即插即用的注意力模块《CBAM:Convolutional Block Attention Module》(含代码复现)
文章目录
-
- 原文地址
- 论文阅读方法
- 初识
- 相知
- 回顾
- 代码复现
原文地址
原文
论文阅读方法
三遍论文法
初识
注意力机制也是人类视觉系统中非常重要的策略,视觉系统对眼球接收到的图像信息进行处理,突出重要的部分,忽略不重要的部分。因此,在视觉神经网络的设计中,这也是一个值得考虑的方面。
本文主要提出了一个简单而有效的注意力模块CBAM,全称是Convolutional Block Attention Module。CBAM综合考虑了卷积特征图的两个维度:通道和空间维度。其中,通道维度主要学习的是“what to attend”,而空间维度上学习的是"where to attend",这增强了网络对重要信息的提取、强化能力。
主要操作如下图所示,给定任何一个特征图,CBAM会串行地在通道维度、空间维度上计算"Attention Map",然后将其与特征图相乘,得到细化(refine)后的输出。

相知
本节只介绍主要技术,related work和相关实验见原文
上图已经囊括了整个CBAM操作,首先对输入特征图 F F F进行运算得到1维的通道注意力图 M c M_c Mc,然后利用 M c M_c Mc与输入特征图进行像素级乘法(element-wise multiplication)。再对融合后的特征图 F ′ F' F′提取2维的空间注意力图 M s M_s Ms,同样执行像素级点乘操作,得到最终的输出特征图 F ′ ′ F'' F′′:
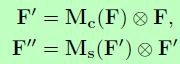
下面详细介绍通道注意力操作与空间注意力操作。
通道注意力模块
与SE-Net只使用全局平均池化提取通道注意力图不同,CBAM还使用了全局最大池化。作者认为,最大池化可以进一步获取到特征图中更具判别性的特征。如下图所示,将输入特征分别经过全局池化、最大池化后得到的特征送入同一个MLP中,得到两个相同维度的输出,然后采用像素级相加(element-wise summation),经过一个sigmoid后得到最终的通道注意力图。
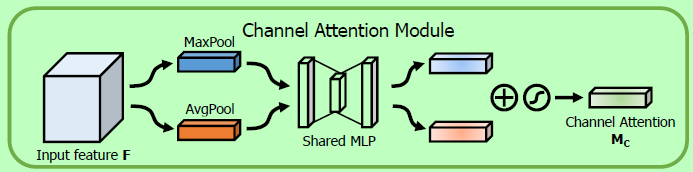
作者通过设置一个缩放量
r来控制MLP的结构(C-r-C)
空间注意力模块
与通道注意力类似,对特征图再空间维度进行分别进行平均池化与最大池化操作,然后将得到的结果进行拼接。对拼接后的特征图进行一个卷积操作,从而得到一个与原图相同空间尺寸的注意力图。经过sigmoid操作后,得到最终的空间注意力图。
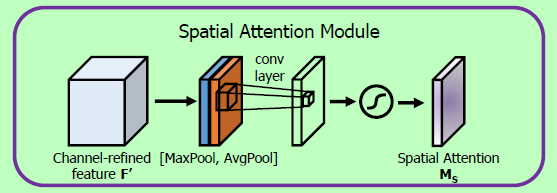
这里的卷积操作采用
7x7的卷积核
最后将通道注意力模块与空间注意力模块串行地连接在一起,构成了CBAM的最终形态。
那为啥不是并行的连接呢?为啥不是先空间注意力,再通道注意力呢?作者都做了实验,发现这种组合效果最好。
这里再贴一个图,展示作者是如何将CBAM模块用在Resnet的:
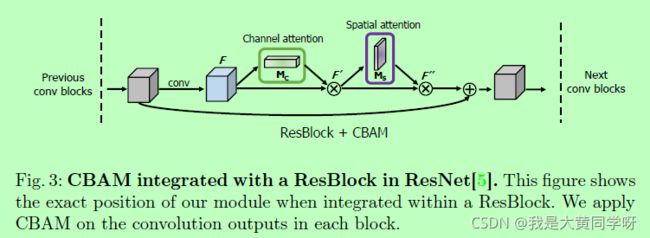
回顾
CBAM轻量级且即插即用,可以很方便地嵌入在各种CNN网络中,提升网络对判别性特征的提取能力,这使得它能够频繁出现在各大CV竞赛上的SOTA方法中。
博主在某个分类比赛上用了CBAM,发现确实有略微地提升,不同的数据集上可能表现不一致。总之,这种即插即用的模块可以很快地应用到网络中,还不用大改结构,实验一下也无妨。
代码复现
class ChannelAttention(nn.Module):
""" Channel Attention Module """
def __init__(self, in_channels, reduction_ratio=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d((1,1))
self.max_pool = nn.AdaptiveMaxPool2d((1,1))
self.mlp = nn.Sequential(
nn.Linear(in_channels, in_channels//reduction_ratio),
nn.ReLU(),
nn.Linear(in_channels//reduction_ratio, in_channels)
)
def forward(self, x):
avg_feat = self.mlp(self.avg_pool(x).flatten(1))
max_feat = self.mlp(self.max_pool(x).flatten(1))
att_feat = avg_feat + max_feat
att_weight = torch.sigmoid(att_feat).unsqueeze(2).unsqueeze(3)
return x*att_weight
class SpatialAttention(nn.Module):
""" Spatial Attention Module """
def __init__(self):
super().__init__()
self.Conv = nn.Sequential(
nn.Conv2d(2, 1, 7, stride=1, padding=3, bias=False),
nn.BatchNorm2d(1)
)
def forward(self, x):
max_feat = torch.max(x, dim=1)[0].unsqueeze(1)
mean_feat = torch.mean(x, dim=1).unsqueeze(1)
att_feat = torch.cat((max_feat, mean_feat), dim=1)
att_weight = torch.sigmoid(self.Conv(att_feat))
return x*att_weight
class CBAM(nn.Module):
""" Channel Block Attention Module """
def __init__(self, in_channels, reduction_ratio=16):
super().__init__()
self.CA = ChannelAttention(in_channels, reduction_ratio)
self.SA = SpatialAttention()
def forward(self, x):
feat = self.CA(x)
feat = self.SA(feat)
return feat