pandas学习笔记补充
有趣的故事开头都是很久很久以前,像这篇——很久很久以前,小白写了篇pandas学习笔记,这次又来补充了,主要以栗子的形式现实,那就开始吧!
再唠叨一句,pandas有两种数据结构:一维Series,二维DataFrame;
Series
是一种带有标签的一维数组对象,能保存任何数据类型,一组Series对象又包含两数组:数据和数据索引。
创建Series

可以用values获得值及值的数据类型
pandas.Series(data数据部分,index专门用于行取名,dtype…)
apples = pd.Series([3,2,0,1],index=['a','b','c','d'])#专门用于行取名
apples
#输出
a 3
b 2
c 0
d 1
dtype: int64
特殊的:如果一不小心取了重复的名字(行名)
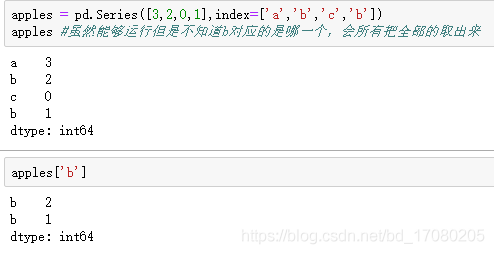
还可以通过把字典转过来的方式创建
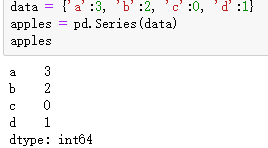
创建一样的数据值不同的数据名称

另外,如果有相同的键则重复的键相当于更新值(最近更新的值)
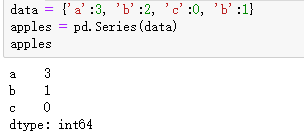
值得注意的是,名字与数据要一一对应,必须一一匹配,多了少了都不行

访问Series数据
有两种方式,通过标签下标通过标签下标访问数据 eg:apples【‘a’】或者通过位置,切片来访问
- a和c之间的所有数据都要
apples['a':'c']
#输出
a 3
b 1
c 0
dtype: int64
- 通过位置取就要严格的按照python规则顾头不顾尾
apples[:3]
#输出
a 3
b 1
c 0
dtype: int64
- 通过布尔数组来存取数据

- 通过花式下标同样需要注意两个中括号
DataFrame
由多个Series结构组成二维表格对象
pd.DataFrame(data, index行,columns列…)
创建DataFrame


访问DataFrame列
只能用名字取列,取的是列(取行有专门的函数),取出来的类型为Series,如果帮列取名字了之后,再用位置索引会报错。取多列类型是dataframe取一列是series
L = [[3,0,1],
[2,1,2],
[0,2,1],
[1,3,0]]
df = pd.DataFrame(L)
df[0]
#输出
0 3
1 2
2 0
3 1
Name: 0, dtype: int64
访问DataFrame行
通过切片进行位置切片
通过行标签进行索引