深度学习目标检测_YOLOV1超详细解读
文章目录
- YOLO背景介绍
- YOLO的发家史
- YOLO核心思想
- YOLO实现细节
-
- P r ( O b j e c t ) Pr(Object) Pr(Object)的概率计算
- P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i ∣Object) Pr(Classi∣Object)的概率计算
- YOLO网络设计
- 归一化
- 30维向量含义
- 预测框的定位
- 再筛选bounding box
- 损失函数
-
- 由浅入深逐一解析损失函数(一):
- 由浅入深逐一解析损失函数(二):
-
- bbox损失函数:
- confidence损失函数
- 20分类损失函数
YOLO背景介绍
YOLO(You Only Look Once),经典的one-stage方法,把检测问题转化为回归问题,简单的CNN网络就搞定了,可以对视频进行实时检测,应用领域非常广。
YOLO的发家史
说起目标检测系统,就要先明白,图像识别、目标定位和目标检测的区别。图像识别也可以说成是目标分类,顾名思义,目的是为了分类出图像中的物体是什么类别。目标定位是不仅仅要识别出是一种什么物体,还要预测出物体的位置,并使用bounding box框出。目标检测就更为复杂,它可以看作是图像识别+多目标定位,即要在一张图片中定位并分类出多个物体。
目标检测对于人类来说极为简单,经过上万年的进化,人类天生具有复杂的感知与视觉系统,这是机器无可比拟的,我们可以只对图片看一眼,即分辨出物体的种类和它相应的位置,根据先前的知识进行归纳,适应不同图像环境都是人类专属技能。但是对于计算机来说,一张图片只是具有无数RGB像素点的矩阵,它本身并不知道猫狗动物,大小形状的概念,如果再给它一张具有复杂自然场景背景的图片,想要检测出物体更是难上加难。但是是问题,总会有解决的办法。问题是由人类提出来的,当然还要靠人类的智慧来处理。面对这样的计算机难题,很多研究学者蜂拥而至,从此目标检测领域变成了非常热门的研究方向,当然也诞生出了许多的解决方法。
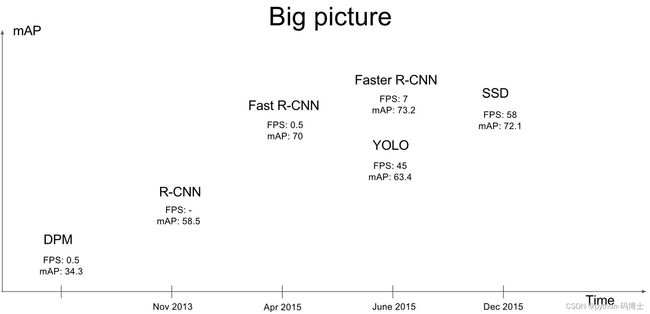
传统的目标检测方法大致分为三个步骤,先使用不同的方法(滑动窗口,区域候选)提取区域的特征图,然后再使用分类器进行识别,最后回归预测。大多数方法都较为复杂,速度较慢,训练耗时。
传统的方法可以按照检测系统分为两种:
- DPM,Deformatable Parts Models,采用sliding window检测
- R-CNN、Fast R-CNN。采用region proposal的方法,生成一些可能包含待检测物体的potential bounding box,再通过一个classifier(SVM)判断每个bbox里是否真的包含物体,以及物体的class probability。
目前深度学习相关的目标检测方法大致可以分为两派:
- 基于区域提名的(regin proposal)的,比如R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN、R-FCN。
- 基于端到端(end to end)的,无需候选区域,如YOLO、SSD。
二者发展都很迅速,区域提名准确率较好、端到端的方法速度较快。
本文着重于介绍一下目标检测系统:YOLO
YOLO核心思想
将整张图片作为网络的输入,直接在输出层对bounding box的位置和所属类别进行回归。与Faster R-CNN网络相比,虽然后者也是使用整张图片作为输入,但是它采用了RCNN那种区域预测+分类的思想,把提取proposal的步骤放在了CNN中实现,而YOLO则采用直接回归的思路,将目标定位和目标类别预测整合于单个神经网络模型中。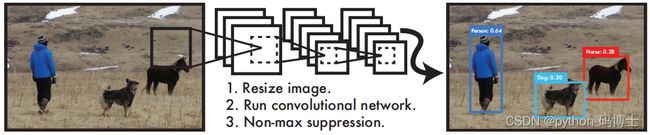
直接在输出层回归bbox的位置和所属类别。
按照 YOLO:Unified,Real-Time Object Detection 中所说,YOLO检测系统简单直接,可以看做只有三步:
-
1.输入:448 x 448 x 3,由于网络的最后需要接入两个全连接层,全连接层需要固定尺寸的输入,故需要将输入resize。
-
2.Conv + FC:主要使用1x1卷积来做channle reduction,然后紧跟3x3卷积。对于卷积层和全连接层,采用Leaky ReLU激活函数:max(x,0.1x) ,但是最后一层采用线性激活函数。

-
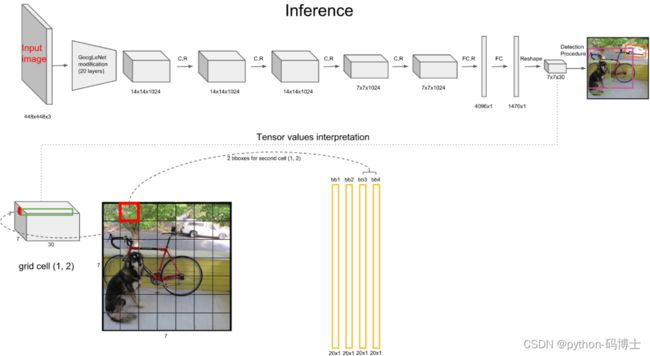
3.输出:最后一个FC层得到一个1470 x 1的输出,将这个输出reshap一下,得到 7 x 7 x 30 的一个tensor,即最终每个单元格都有一个30维的输出,代表预测结果。具体如下:
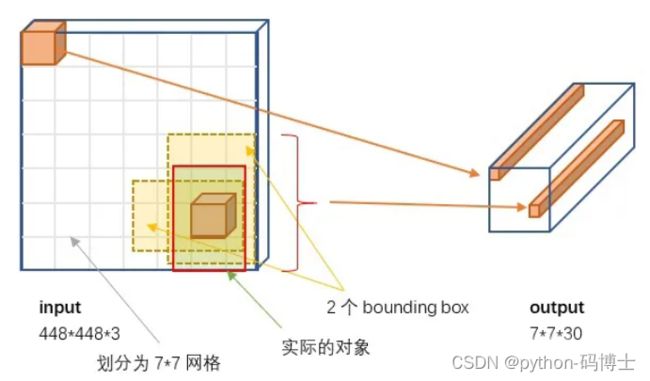
YOLO实现细节

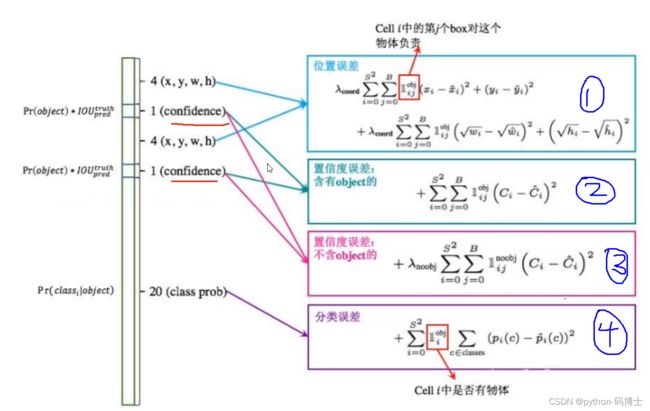
2、每个网格要预测B个bounding box,每个box除了要回归自身的位置之外,还要附带预测一个confidence值。这个值代表了所预测的bounding box中是否含有object和若有object,这个object预测得有多准的两重信息,计算方式:
P r ( O b j e c t ) ∗ I o U p r e d t r u t h Pr(Object)∗IoU^{truth}_{pred} Pr(Object)∗IoUpredtruth
- 第二项是预测的边界框和ground-truth之间的IoU值。可以计算出来
P r ( O b j e c t ) Pr(Object) Pr(Object)的概率计算
-
然后看2个bounding box的IOU,哪个比较大(更接近对象实际的bounding box),就由哪个bounding box来负责预测该对象是否存在,即该bounding box的 P r ( O b j e c t ) Pr(Object) Pr(Object)=1,同时对象真实bounding box的位置也就填入该bounding box。另一个不负责预测的bounding box的 P r ( O b j e c t ) = 0 Pr(Object)=0 Pr(Object)=0。
-
总的来说就是,与对象实际bounding box最接近的那个bounding box,其 C o n f i d e n c e = I o U p r e d t r u t h Confidence=IoU^{truth}_{pred} Confidence=IoUpredtruth该网格的其它bounding box的 C o n f i d e n c e = 0 Confidence=0 Confidence=0。
说人话:拿上面狗的图片举例子 首先将狗的图片分为7*7的网格,而红色的点所在的网格就是狗的标注框中心点所在的网格,因此这个框负责预测狗这个物体。 每个网格可以定义有几个anchor box,当然,这里是定义了2个anchor box。拿其中一个anchor box举例,经过与真实框的IOU计算之后就是回归出来的框Bounding Box(也就是网络输出的框(图中的黄色框),他与真实框和anchor box都有差距)(anchor box 的个数和大小由自己定义,写在配置文件中) 返回回来的Bounding Box携带5个值(x,y,w,h,c),(x,y)为Bounding Box的中心坐标,w,h为Bounding Box的宽和高。另外还有一个c意思就是confidence,这个值反映出了两个信息,一个是这个框的IOU比较高,也就是这个框是被筛选出来的,否则也不会返回Bounding Box对吧,另一个就是这个框预测的准确度。 至于公式可以这样理解: 如果这个网格是物体框的中心点,那当然是咱们想要的,所以为1,否则就是背景呗,背景不是我们想要的所以是0。
Bounding Box与anchor box的区别可以看看这篇文章:https://blog.csdn.net/m0_54146002/article/details/120486688
3、每个网格单元针对20种类别预测bboxes属于单个类别的条件概率 P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i ∣Object) Pr(Classi∣Object),属于同一个网格的B个bboxes共享一个条件概率。在测试时,将条件概率分别和单个的bbox的confidence预测相乘:
P r ( C l a s s i ∣ O b j e c t ) ⏞ c o n d i t i o n a l c l a s s p r o b ∗ P r ( O b j e c t ) ∗ I o U p r e d t r u t h ⏞ b b o x c o n f i d e n c e = P r ( C l a s s i ) ∗ I o U p r e d t r u t h \overbrace{Pr(Class_i ∣Object)}^{conditional{\,} class{\,} prob}∗\overbrace{Pr(Object)∗IoU^{truth}_{pred}}^{bbox{\,} confidence}=Pr(Class_i)∗IoU^{truth}_{pred} Pr(Classi∣Object) conditionalclassprob∗Pr(Object)∗IoUpredtruth bboxconfidence=Pr(Classi)∗IoUpredtruth
- P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i ∣Object) Pr(Classi∣Object) : 候选框预测为每一类的概率(for class in Class20)
- P r ( O b j e c t ) Pr(Object) Pr(Object):候选框预测到前景的概率
更深入的了解概率:https://zhuanlan.zhihu.com/p/45432367
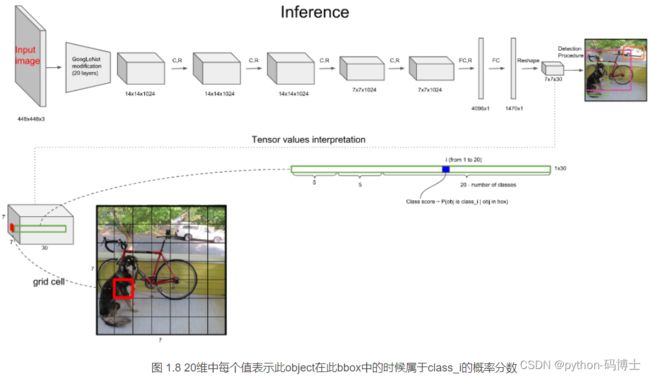
P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i ∣Object) Pr(Classi∣Object)的概率计算
即20个对象分类的概率

对于输入图像中的每个对象,先找到其中心点。比如上图中的自行车,其中心点在黄色圆点位置,中心点落在黄色网格内,所以这个黄色网格对应的30维向量中,自行车的概率1,其它对象的概率是0。所有其它48个网格的30维向量中,该自行车的概率都是0。这就是所谓的"中心点所在的网格对预测该对象负责"。狗和汽车的分类概率也是同样的方法填写。
说人话:
以狗举例,如果候选框的grid cell和标注框的grid cell是一个即都是蓝色的grid cell,那么这个网格的 P r ( 狗 ∣ O b j e c t ) = 1 Pr(狗∣Object) =1 Pr(狗∣Object)=1, P r ( 其他 19 种 ∣ O b j e c t ) = 0 Pr(其他19种∣Object) =0 Pr(其他19种∣Object)=0,如果预测框的grid cell既不是上图中的蓝色grid cell,也不是黄和粉grid cell呢?就是 P r ( 20 种 ∣ O b j e c t ) = 0 Pr(20种∣Object) =0 Pr(20种∣Object)=0呗。
4、在Pascal VOC中,YOLO检测系统的图像输入为448×448,S=7,B=2,一共有20个class(C=20),输出就是7×7×30的一个tensor。这个是怎么算出来的呢?看下面详解。
YOLO网络设计
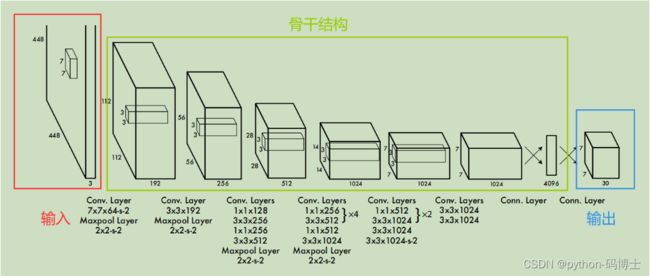
YOLO使用了24个级联卷积层和最后2个全连接层,交替的1×1卷积层降低了前面层的特征空间。在ImageNet分类任务上使用分辨率的一半(224×224输入图像)对卷积层进行预训练,然后将分辨率加倍进行目标检测。
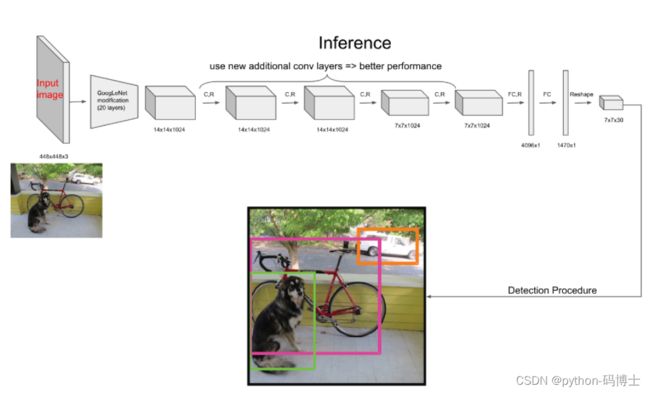
YOLO网络借鉴了GoogleNet的思想,但与之不同的是,为了更好的性能,它增加额外的4层卷积层(conv)。YOLO一共使用了24个级联的卷积层和2个全连接层(fc),其中conv层中包含了1×1和3×3两种kernel,最后一个fc全连接层后经过reshape之后就是YOLO网络的输出,是长度为S×S×(B×5+C)=7×7×30的tensor,最后经过识别过程得到最终的检测结果。
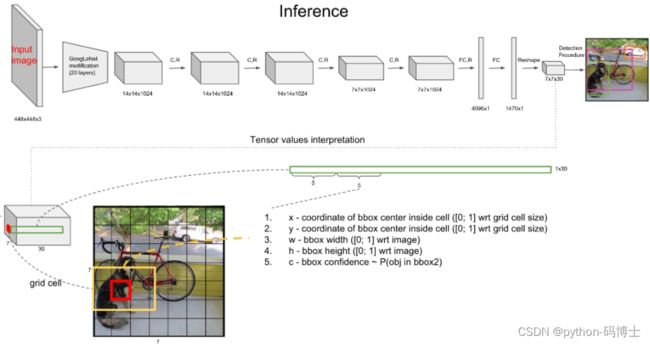
上文说到每个bounding box要预测(x,y,w,h,confidence)五个值,一张图片共分为S×S个网格,每个网格要预测出B个bounding box和一个网格负责的object的类别信息,记为C。
则输出为S ∗ S ∗ ( 5 ∗ B + C ) SS(5*B+C)S∗S∗(5∗B+C)的tensor张量,(x,y)表示bounding box相对于网格单元的边界的offset,归一化到(0,1)范围之内,而w,h表示相对于整个图片的预测宽和高,也被归一化到(0,1)范围内。c代表的是object在某个bounding box的confidence。
使用下图更形象的说明,7×7×30的Tensor中的一个1×1×30的前10维的所代表的含义。
归一化
下面解释如何将预测坐标的x,y用相对于对应网格的offset归一化到0-1和w,h是如何利用图像的宽高归一化到0-1之间。
每个单元格预测的B个(x,y,w,h,confidence)向量,假设图片为S×S个网格,S=7,图片宽为wi 高为hi :
1.(x,y)是bbox的中心相对于单元格的offset
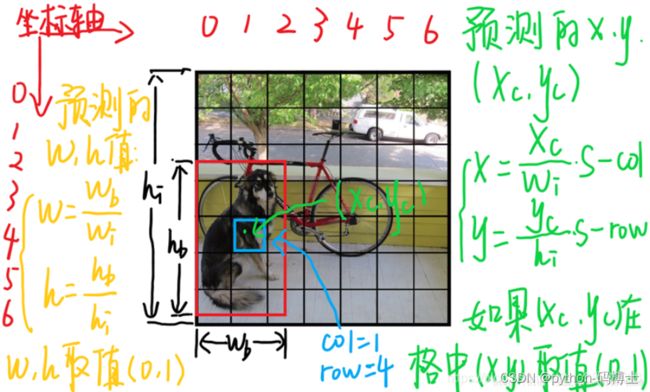
对于下图中蓝色单元格,坐标为(xcol=1,yrow=4),假设它的预测输出是红色框bbox,设bbox的中心坐标为(xc,yc),那么最终预测出来的(x,y)是经过归一化处理的,表示的是相对于单元格的offset,公式:
x = x c w i ∗ S − x c o l , y = y c h i ∗ S − y r o w x=\frac{x_c}{w_i}*S-x_{col},y=\frac{y_c}{h_i}*S-y_{row} x=wixc∗S−xcol,y=hiyc∗S−yrow
2.(w,h)是bbox相对于整个图片的比例
预测的bbox的宽高为wb, hb,(w,h)表示的是bbox相对于整张图片的占比,公式:
w = w b w i = , y = h b h i w=\frac{w_b}{w_i}=,y=\frac{h_b}{h_i} w=wiwb=,y=hihb
如果还不理解,可以看这里
前面说了,共有7x7=49个“grid cell”,而每个“grid cell”有两个“bounding box”,负责预测“ground truth”的位置和类别。因此,最后的30实际上是由5x2+20组成的。
第一个5,分别是x,y,w,h,c。其中:
x,y是指“bounding box”的预测框的中心坐标相较于该“bounding box”归属的“grid cell”左上角的偏移量,在0-1之间。如下图所示
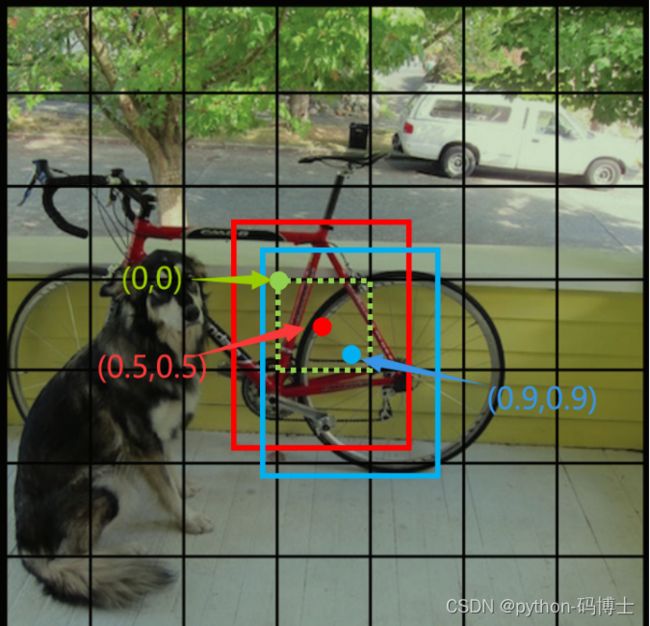
在上图中,绿色虚线框代表grid cell,绿点表示该grid cell的左上角坐标,为(0,0);
红色和蓝色框代表该grid cell包含的两个bounding box,红点和蓝点表示这两个boung box的中心坐标。有一点很重要,bound box的中心坐标一定在该grid cell内部,因此,红点和蓝点的坐标可以归一化在0-1之间。再上图中,红点的坐标为(0.5,0.5),即x=y=0.5,蓝点的坐标为(0.9,0.9),即x=y=0.9。
w和h是指该bound box的宽和高,但也归一化到了0-1之间,表示相较于原始图像的宽和高(即448个像素)。比如该bounding box预测的框宽是44.8个像素,高也是44.8个像素,则w=0.1,h=0.1。
比如对于下面的这个例子:

红框的x=0.8,y=0.5,w=0.1,h=0.2。
那么,最后的c表示什么呢?c是置信度,表示的实际含义是:该bounding box 中含有目标的概率,在论文中表示为:

那么这个c实际是怎么求出来的呢?作者用bounding box与ground truth的IOU来代替c,即作者的思想是:用bounding box与ground truth的重合程度,来表示该bounding box中含有目标的概率,这显然是符合直觉的,也是说得通的。上面图片中的Pr(Object)非0即1,若ground truth的中心点落入该grid cell中,则Pr(Object)=1,否则Pr(Object)=0。
所以,对于一个bounding box,有x,y,w,h,c这五个参数,前四个参数而已确定bounding box的方框,最后的c可以该bounding box 中含有目标的概率。而对于一个grid cell有两个bounding box,因此是5x2。
OK,至此已经解释清楚了30=5x2 + 20中的前半部分,那么后面的20又是什么?
YOLOV1是在PASCAL VOC数据集上训练的,该数据集上有20个类别,因此这里的20表示的是条件概率:在该grid cell包含目标的条件下,该目标是某种类别的概率。在论文中作者用Pr(Classi | Object)表示。因为有20个类别,所以有20个条件概率。
这就是7x7x30中的30表示的具体含义。
另外,因为c表示的是该方框中存在目标的概率,后面的20表示的是条件概率:在该grid cell包含目标的条件下,该目标是某种类别的概率。所以用c乘以条件概率就可以得到全概率,如下图所示。全概率就表示该方框中包含目标的概率。

30维向量含义
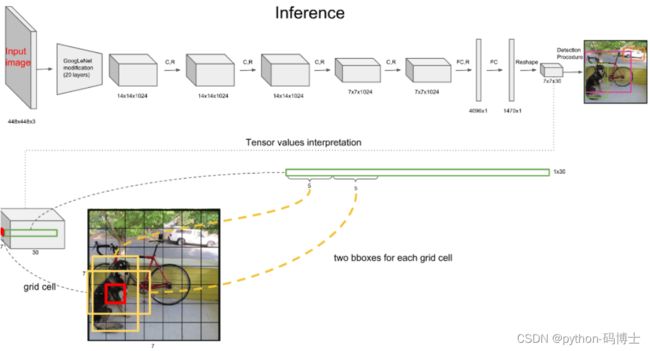
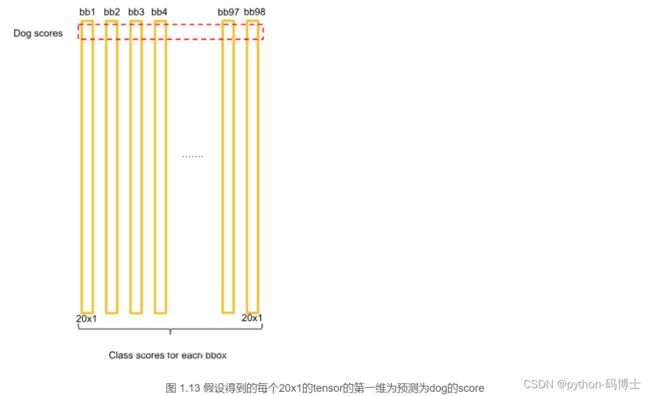
每个grid cell对应的两个bounding box的5个值在tensor中体现出来,组成前十维。后面二十维代表属于每一个类别的概率。
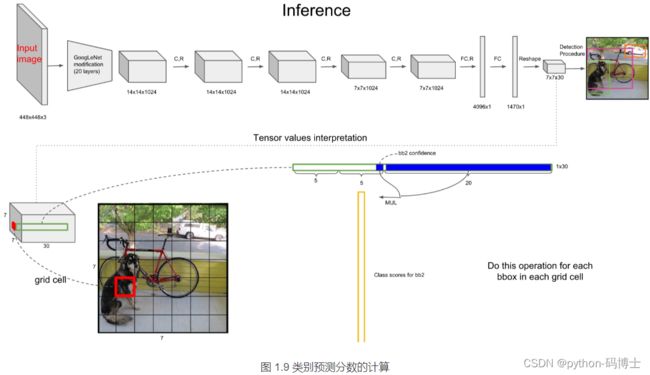
如上式所述,每个网格预测的类别概率乘以每个bbox的预测confidence,得到每个bbox的class-specific confidence score分数。对每个格子的每一个bounding box进行此运算,最后会得到7×7×2=98个scores,设置一个阈值,滤掉得分低的bboxes,对保留的bboxes进行NMS(Non Maximum Suppression)处理,最终得到目标检测结果。
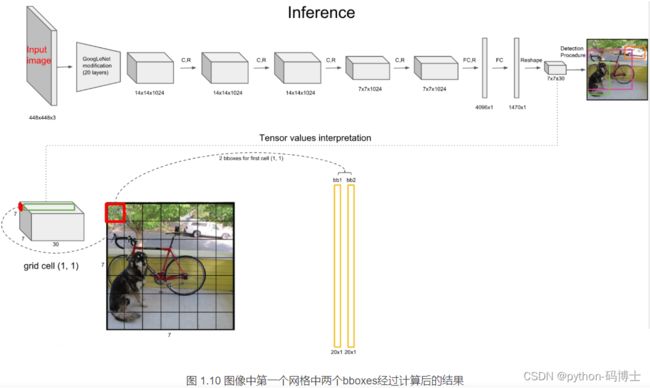

预测框的定位

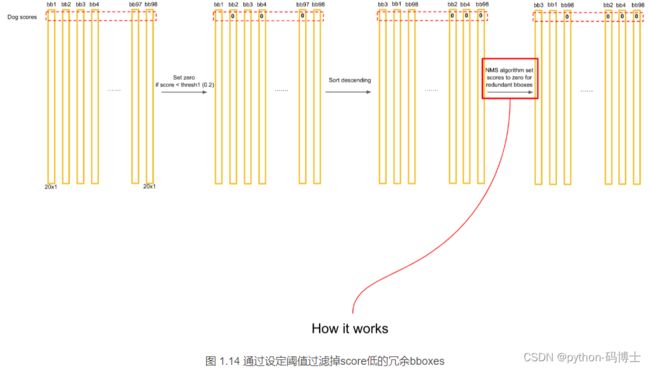


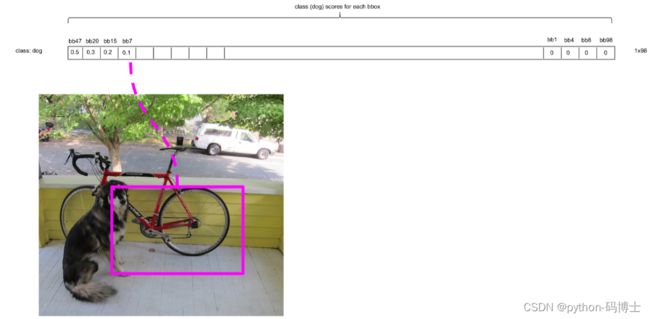
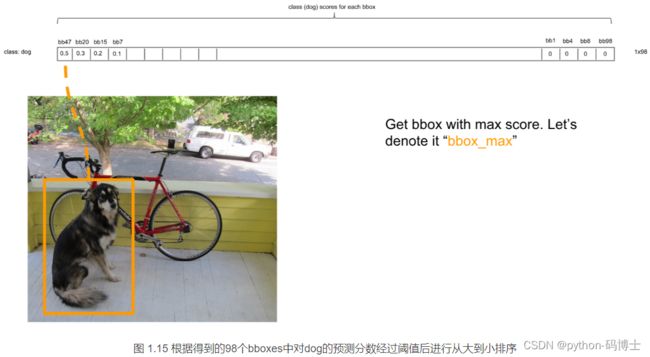
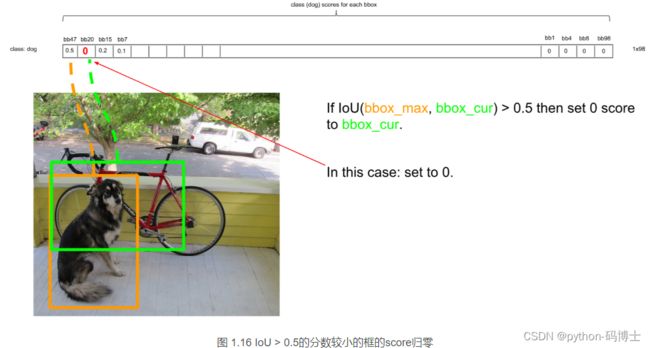
最后得到第一个为最大的score值,找出针对dog这个种类预测出的对应框,记为bbox_max。然后将它与其他分数较低的但不是0的框作对比,这种框记为bbox_cur。将bbox_max和bbox_cur分别做IoU计算,如果 IoU(bbox_max, bbox_cur) > 0.5,那么将bbox_cur对应的score设为0。例如:
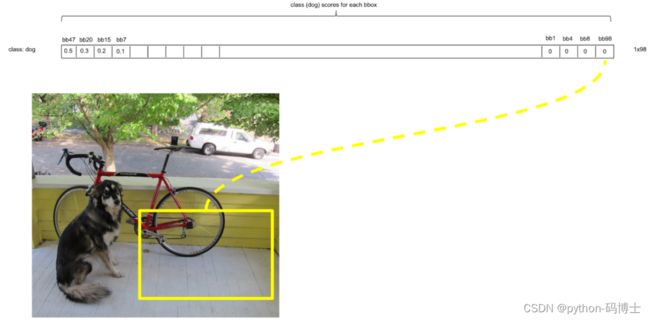
然后接着遍历下一个score,如果它不是最大的且不为0,就和最大的score对应的框座IoU运算,若结果大于0.5则,同上。否则它的score不变,继续处理下一个bbox_cur……直到最后一个score,如图:
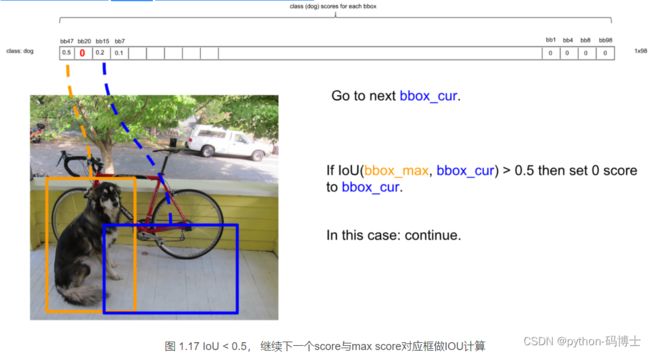
计算完一轮之后,假如得到score序列:0.5、0、0.2、0.1 … 0、0、0、0
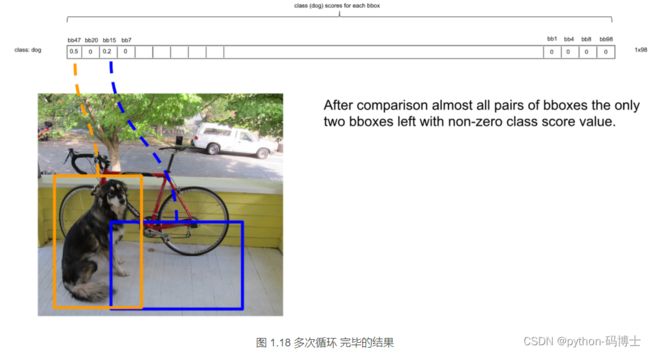
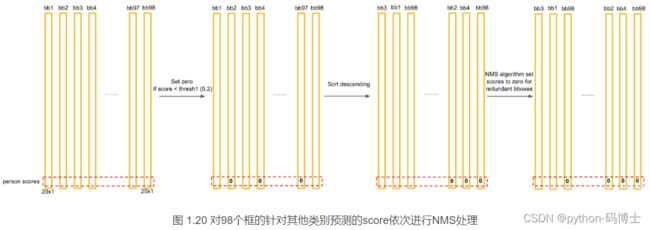
那么进行下一轮循环,从0.2开始,将0.2对应的框作为bbox_max,继续循环计算后面的bbox_cur与新的bbox_max的IoU值,大于0.5的设为0,小于0.5的score不变。再这样一直计算比较到最后一个score。
得到新的的score序列为:0.5、0、0.2、0 … 0、0、0、0
即最后只得到两个score不为0的框,如图:

再筛选bounding box
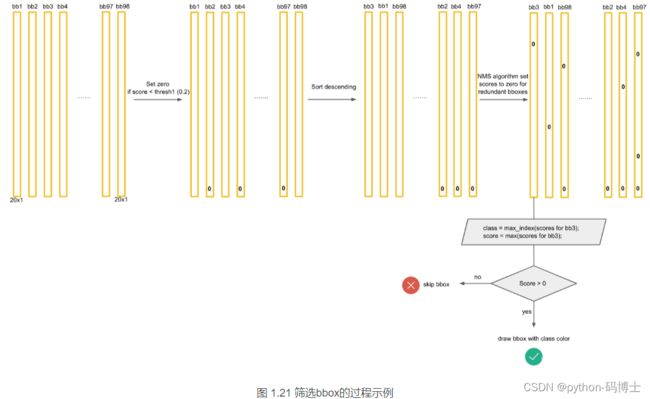
经过这些NMS算法的处理,会出现很多框针对某个class的预测的score为0的情况。
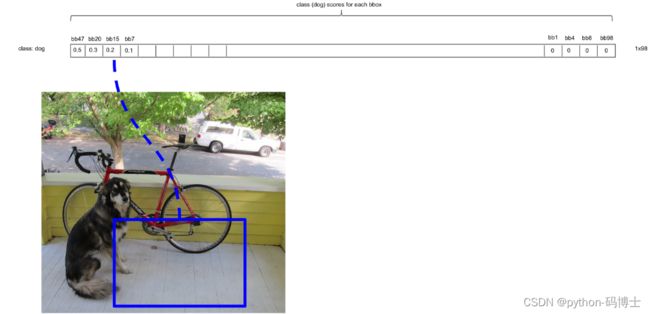
最后,针对每个bbox的20×1的张量,对20种class的预测score进行判断。例如,
1)先取出针对bbox3的所有20个scores,按照类别的默认顺序找出score最大的那个score的index索引号(根据此index可以找出所属的类别)记为class;
2)然后找出bbox3的最大score分数,记为score。
3)判断score是否大于0,如果是,就在图像中画出标有class的框。否则,丢弃此bbox。
如图:
接下来进行下一个bbox的筛选,如图,则是bbox1,流程同上。一直到最后一个bbox97,
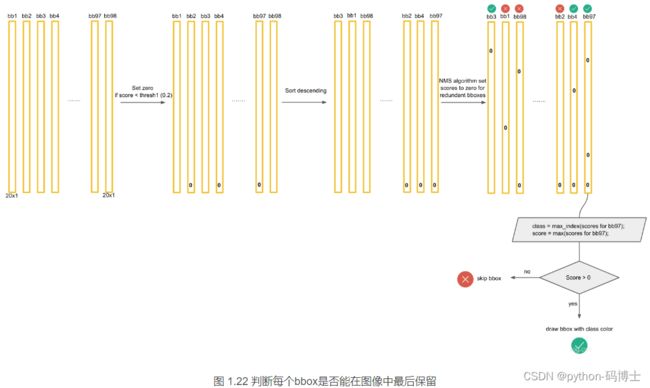
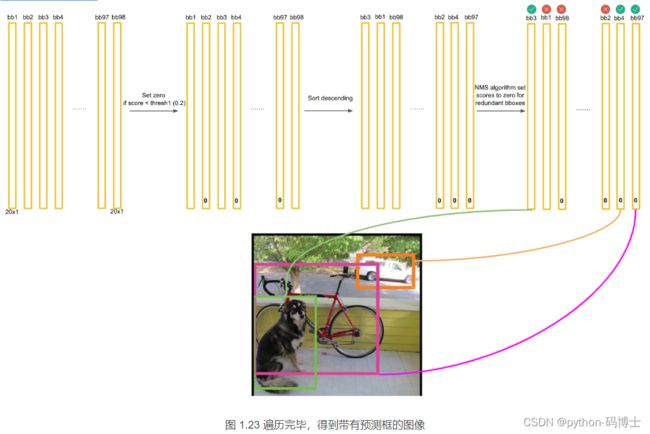
最后得到的框如图:
损失函数
由浅入深逐一解析损失函数(一):
1.bbox损失函数
bbox的四个指标(x,y,w,h)要计算与真实框的损失
2.confidence损失函数
分前景和背景两种情况:
- 一种是预测中心点落在标注框的中心网格中,也就是这个框负责预测这个物体。
- 另一种是预测中心点为未落在标注框的中心网格中,也就是这个框负责预测背景。
3.20分类损失函数
计算每一个类别的预测值和真实值之间的损失
4.最后将所有损失函数加在一起就是我们的loss。
由浅入深逐一解析损失函数(二):
bbox损失函数:

- λcoord:8维的localization error和20维的classification error同样重要显然是不合理的,毕竟最后是要加在一起的,应该更重视8维的坐标预测,所以作者给这个损失前加了个权重,记为:λcoord,在Pascal VOC训练中取5。
- ∑ i = 0 s 2 \sum_{i=0}^{s^2} ∑i=0s2:对于ss也就是77的每一个grid cell都要计算
- ∑ j = 0 B \sum_{j=0}^{B} ∑j=0B:有两个bounding box,每一个都要计算
- I i j o b j I{^{obj}_{ij}} Iijobj:当前网格不是有2个预测框吗,每一个都会和标注框算一个IOU,IOU大的设置为1,小的设置为0。
- [ ( x i − x ^ ) 2 + ( y i − y ^ ) 2 ] [(x_i-\hat{x})^2+(y_i-\hat{y})^2] [(xi−x^)2+(yi−y^)2]:预测框的中心点(x,y)与标注框的中心点 ( x ^ , y ^ ) (\hat{x},\hat{y}) (x^,y^)的位置差距。
值得注意的是为什么计算宽高的差距时要加上根号呢?
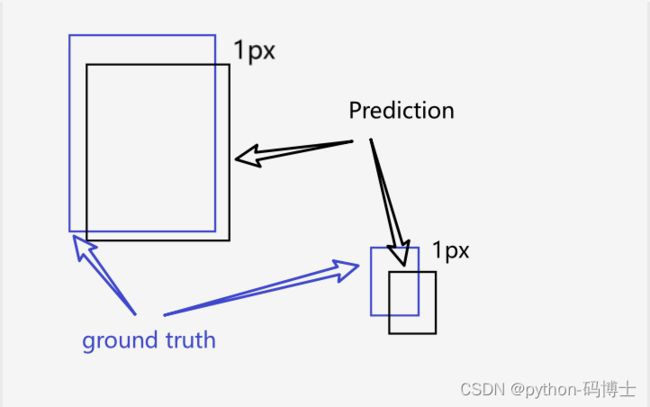
我们看上面这张图,同样是差距1px,大图像感觉就无所谓,而小图像却差之毫厘谬以千里。因此我们加上一个根号。接着看
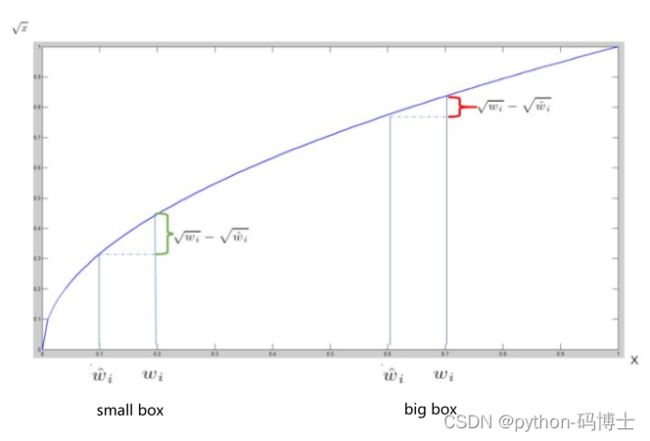
从开方函数图像很容易就知道对于较大的bbox来说两者之差是会被慢慢缩小的,即惩罚力度没有小bbox这么大。
confidence损失函数
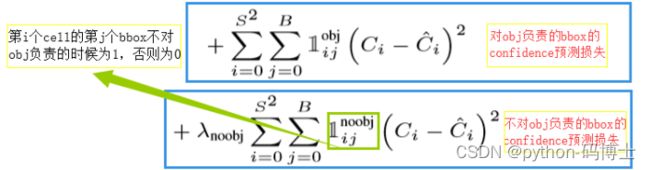
- C i 与 C i ^ C_i与\hat{C_i} Ci与Ci^:当预测为一个前景的时候,我们希望它的置信度为1,当预测为背景的时候我们希望它的置信度为0,但是这样可能吗?别忘了我们还有一个预测框与标注框的IOU没用上,于是就出现了置信度Ci和IOU( C i ^ \hat{C_i} Ci^)之间的计算。也就是当这个框的IOU值大于0.5的时候,我就觉得这个框是在预测前景,此时的置信度为1,但是又没有和标注框完全重合,所以置信度的值越接近IOU的值越好。
- 对于不存在object的bbox的confidence loss,赋予了更小的损失权重,记为 λ n o o d e \lambda_{noode} λnoode。在Pascal VOC中取0.5。若没有任何物体中心落入边界框中,则 C i ^ \hat{C_i} Ci^=0,此时我们希望预测含有物体的置信度 C i C_i Ci越小越好。然而,大部分bbox中都没有object,积少成多,造成loss的第2部分与第3部分的不平衡,因此,在loss的三部分增加权重 λ n o o d e \lambda_{noode} λnoode=0.5。
20分类损失函数
- C i C_i Ci:预测的该种类的概率,还是我们的老演员狗,也就是说当这个grid cell 是我们的狗标注框的中心grid cell时,这个式子的值就等于 1 ∗ I o U p r e d t r u t h 1*IoU^{truth}_{pred} 1∗IoUpredtruth,因为这个框被选出来了,所以 P r ( O b j e c t ) Pr(Object) Pr(Object)已经等于1了,计算 P r ( C l a s s i ) ∗ I o U p r e d t r u t h Pr(Class_i)∗IoU^{truth}_{pred} Pr(Classi)∗IoUpredtruth就完了。其他的非标注框中心grid cell的就全都是0。
P r ( C l a s s i ∣ O b j e c t ) ⏞ c o n d i t i o n a l c l a s s p r o b ∗ P r ( O b j e c t ) ∗ I o U p r e d t r u t h ⏞ b b o x c o n f i d e n c e = P r ( C l a s s i ) ∗ I o U p r e d t r u t h \overbrace{Pr(Class_i ∣Object)}^{conditional{\,} class{\,} prob}∗\overbrace{Pr(Object)∗IoU^{truth}_{pred}}^{bbox{\,} confidence}=Pr(Class_i)∗IoU^{truth}_{pred} Pr(Classi∣Object) conditionalclassprob∗Pr(Object)∗IoUpredtruth bboxconfidence=Pr(Classi)∗IoUpredtruth - C i ^ \hat{C_i} Ci^:该种类的真实概率呗,只要这个grid cell 是我们狗标注框的中心grid cell,就为1,其他类别的或者背景的grid cell到这里只能挨一巴掌,所以就是0。