【笔记】【机器学习基础】1.7 鸢尾花分类
1.7 鸢尾花分类
问题背景:鸢尾花有三个品种 1.setosa 2.versicolor 3.virginica
目标:构建模型,从已知数据中预测新的鸢尾花的品种(三分类问题)
监督学习问题:从已知到未知
类别:可能的输出(花的品种)
标签:单个数据点的预期输出是这个花的品种
一、数据集
iris对象是一个Bunch对象,有点像字典,有键值对
from sklearn.datasets import load_iris
#load_iris返回的iris对象是一个Bunch对象,有点像字典,有键值对
iris_datasets=load_iris()
print("Key of iris_datasets:\n{}".format(iris_datasets.keys()))
out:
![]()
结果可知,iris对象中的key有
‘data’, ‘target’, ‘frame’, ‘target_names’, ‘DESCR’, ‘feature_names’, ‘filename’, ‘data_module’
- DESCR键对应的值是数据的简要说明
- target_names对应的是一个字符串数组,里面包含了我们要预测的花的品种(0表示setosa,1表示versicolor,2表示virginica)
- feature_names对应的是一个字符串列表,对每一个特征进行说明
- data里面是花萼的长度宽度和花瓣的长度宽度的测量数据,数据格式全部为Numpy数组。在data中每一行对应一朵花,每一列代表的是每一朵花的四个测量数据
- target数组包含的是每朵花测量过后的品种,也是一个numpy数组。target是数组每朵花对应其中一个数据(0~2整数表示品种)
#DESCR键对应的值是数据的简要说明,可以自己去查看。
print(iris_datasets['DESCR'])
#target_names对应的是一个字符串数组,里面包含了我们要预测的花的品种
print(iris_datasets['target_names'])
#feature_names对应的是一个字符串列表,对每一个特征进行说明
print(iris_datasets["feature_names"])
#相对应的数据都包含data和target中。data里面是花萼的长度宽度和花瓣的长度宽度的测量数据,数据格式全部为Numpy数组。
print(type(iris_datasets['data']))
print(type(iris_datasets['target']))
#在data中每一行对应一朵花,每一列代表的是每一朵花的四个测量数据
print(iris_datasets['data'].shape)#(150,4)
#可以看出,数组中包含了150朵花的测量数据。在机器学习中的个体叫做样本(sample),其属性叫做特征(feature)。data数组的形状(shape)
#是样本乘以特征数。这是scikit-learn中的约定,你的数据形状始终遵循这个约定。
#下面我们看看前五个样本的特征值:
print("前五个样本特征值:\n{}".format(iris_datasets['data'][:5]))
#从数据中我们发现花瓣的宽度全部都是0.2cm,第一朵花的花萼最长5.1cm。
# target数组包含的是每朵花测量过后的品种,也是一个numpy数组。
print("Type of target \n{}".format(type(iris_datasets['target'])))
#target是数组每朵花对应其中一个数据
print("Shape of target :\n{}".format(iris_datasets['target'].shape))
#但是品种被转化为0,1,2 三个数字对用的品种。0代表setosa,1代表 versicolor ,2代表virginica 三个前面说道的鸢尾花分为的三个类别
print("Target: \n{}".format(iris_datasets['target']))
部分结果:

二、模型评估:训练数据与测试数据
检测模型泛化能力==能否在新数据上正确预测
新数据:将带标签的数据分为训练数据和测试数据
训练数据 / 训练集(training data/set) :用于构建模型
测试数据 / 测试集 / 留出集(test data/set hold-on set):用于评估模型性能
scikit-learn中train_test_split函数
功能:利用伪随机数生成器将数据集打乱并进行拆分,将75%的行数据及标签作为训练集,剩下25%作为测试集。(常用比例3:1)
数据用X表示(二维数组(矩阵)),标签用y表示(一维数据(向量))
保证运行同一函数得到相同的输出,利用random_state参数指定随机数生成器的种子
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
iris_datasets=load_iris()
X_train,X_test,y_train,y_test=train_test_split(iris_datasets['data'],iris_datasets['target'],random_state=0)
#train_test_split函数的输出X_train,X_test,y_train,y_test,都是numpy数组。X_train包含75%行数据,X_test剩下的25%
print('X_tarin shape: {}'.format(X_train.shape))
print('y_tarin shape: {}'.format(y_train.shape))
print('X_test shape: {}'.format(X_test.shape))
print('y_test shape: {}'.format(y_test.shape))

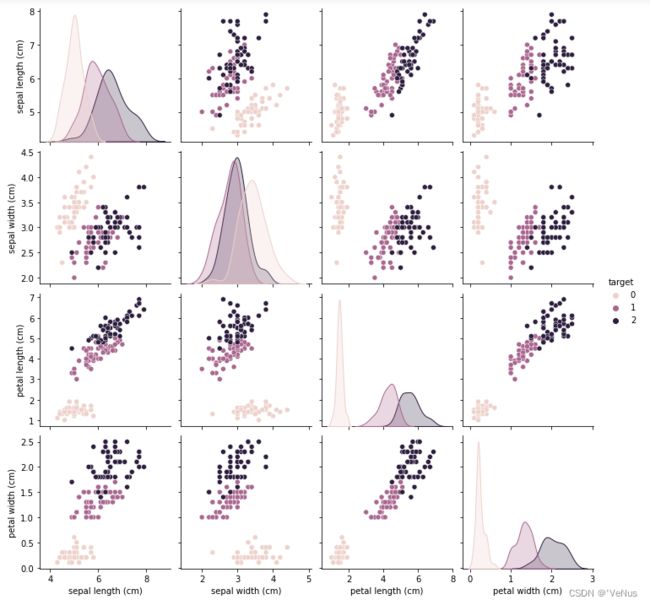
三、检查数据
对数据进行划分后,在构建机器学习模型前检查数据,看需要的数据是否包含在数据中
绘制相关的散点矩阵图查看特征(多于3个的特征)
from sklearn.datasets import load_iris
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#利用X_train中的数据创建DataFrame
#利用iris_datasets.feature_names中的字符串对数据进行标记
iris=load_iris()
iris_dataframe=pd.DataFrame(iris.data,columns=iris.feature_names)
iris_dataframe['target']=iris.target
#利用DataFrame创建散点矩阵图,按y_tarin上色
grr=sns.pairplot(iris_dataframe,size=2.5,hue='target')
plt.show()
四、构建模型:KNN
使用k近邻算法
原理:构建模型只用保存训练集。当对一个新的数据做出预测的时候,会找出距离训练集最近的相似的点,然后将找到的数据点的标签赋值给这个新的数据点。
scikit-learn中所有的机器学习都在各自的类中实现,这些类被称为Estimator类。k邻近分类算法是在neighbors模块中的KNeighborsClassifier类中实现。我们需要将这个类实例化成一个对象,然后才能使用模型。
KNeighborsClassifier最重要的参数就是邻居的数目,这里我们设为1
knn对象对算法进行了封装,包括了训练数据构建模型的算法,也包括了对新数据点预测的算法。它还包括了算法从训练数据中提取的信息。
#对于KNeighborsClassifier来说里面只有训练集
from sklearn.neighbors import KNeighborsClassifier
#knn对象对算法进行了封装,包括了训练数据构建模型的算法,也包括了对新数据点预测的算法。它还包括了算法从训练数据中提取的信息。
#对于KNeighborsClassifier来说里面只有训练集
knn=KNeighborsClassifier(n_neighbors=1)
想要基于训练集来构建模型,需要调用knn对象的fit方法,输入参数X_train和y_train,都是numpy数组,前面的是训练数据后面的是训练标签:
knn.fit(X_train,y_train)
print(knn)
#KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
#metric_params=None, n_jobs=None, n_neighbors=1, p=2,
#weights='uniform')
fit方法返回的是knn对象本身并做原处修改,所以我们得到的分类器的字符串的表示。我们看到了构建模型是需要的参数。
五、预测
输入新的数据,放入二维numpy数组中的一行(scikit-learn的输入数据必须是二维数组)中并计算shape。
X_new=np.array([[5,2.9,1,0.2]])
print(X_new.shape)
调用knn对象的predict方法进行预测:
import numpy as np
#所以我们预测的这朵新花属于类别0,也就是属于setosa品种
X_new=np.array([[5,2.9,1,0.2]])
prediction=knn.predict(X_new)
print(prediction)
print('prediction target name:{}'.format(iris_datasets['target_names'][prediction]))
六、评估模型
把测试集拿来进行评估,来衡量这个模型的优劣。
精度就是品种正确的花所占的比例。
y_pred=knn.predict(X_test)
print("测试集的预测:\n{}".format(y_pred))
#测试集的精确
print("测试集的精度:\n{}".format(np.mean(y_pred==y_test)))
#还可以使用knn的score方法进行精度的预测
print("测试集精度:\n{}".format(knn.score(X_test,y_test)))

测试集的精度达到97%,说明预测97%正确。