机器学习——模型评估、优化、诊断
1.模型评估
数据集的70%数据放入训练集,30%的数据放入测试集
线性回归的训练测试过程

首先通过最小化代价函数J(w,b)来拟合参数
然后要知道这个模型做得如何,计算J_test(w,b)去检验,这里不包括正则化项,这样就能知道算法学习得怎么样
最后是训练误差,这是一个衡量你的学习算法在训练集上表现的指标
选择模型
将数据分成三个不同的子集:训练集(60%),交叉验证集(the cross-validation set) ,还有测试集(20%)。交叉验证集是一个额外的数据集, 我们将使用它来检查或信任检查不同模型的有效
性或准确性。
使用这三个公式计算训练误差、交叉验证误差和测试误差,然而通常这些项都不包括正则化项,它包含在训练对象中
在选择模型时
观察哪个模型(架构)的交叉验证错误最低,而判断泛化能力则使用测试集,可以使用Jcv (交叉验证集)来评估神经网络的性能,关于分类问题,Jcv可以是样本的百分比,计算算法错误分类的交叉验证样本的比例,选择交叉验证误差最低的模型
2.Bias and variance(使用偏差和方差对模型进行诊断)
Jtrain表现偏差性,Jcv表现方差,横轴表示阶数
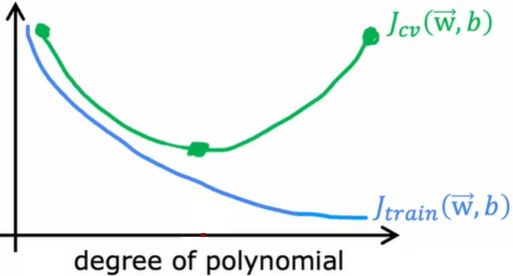
高偏差意味着算法在训练集上表现不好,高方差意味着算法在交叉验证集的表现比训练集上的差得多
正则化对偏差和方差的影响(Regularization and bias/variance)
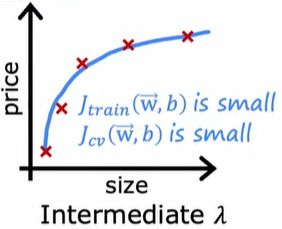 如果你想为正则化参数λ找到一个合适的值,可以使用交叉验证。即模型确定之后对于正则化应该如何选择合适的λ,类似于使用交叉验证来选择多项式的次数。
如果你想为正则化参数λ找到一个合适的值,可以使用交叉验证。即模型确定之后对于正则化应该如何选择合适的λ,类似于使用交叉验证来选择多项式的次数。
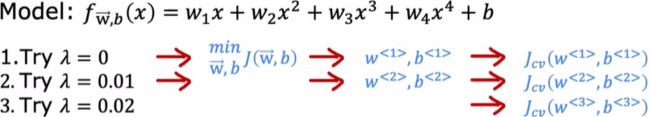
J_train误差和交叉验证误差随着参数的函数变化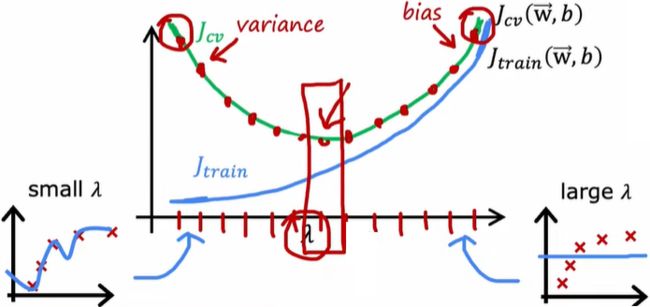
训练集误差和交叉验证误差的差判断是否有高方差
3.学习曲线(Learning curves)
学习曲线(Learning curves)是一种帮助你了解学习算法性能如何的方式,曲线随着经验的数量(算法所拥有的训练样本数)发生变化。
学到的模型更好,交叉验证误差就会减少,完美地拟合训练样本只会随着样本增加变得越来越难。交叉验证误差通常会比训练误差高,因为你调整参数去拟合训练集,是希望在训练集上的性能得到提升,或者当m (样本数)很小的时候,训练集1的表现至少比交叉验证集的好。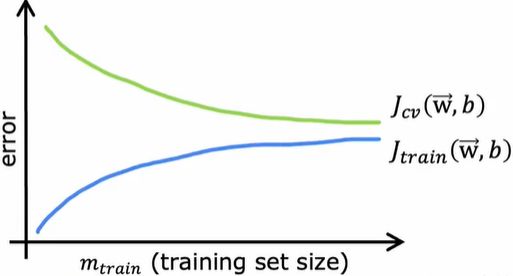
高偏差情况(欠拟合)
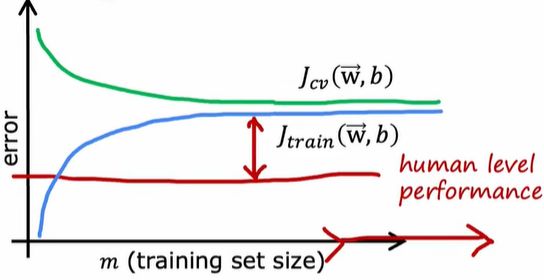
如果一个学习算法有很高的偏差,获得更多的训练数据本身不会有多大帮助,因为曲线趋于平坦
高方差情况(过拟合)

可以通过扩大训练集来降低交叉验证误差,从而让你的算法表现得越来越好
绘制学习曲线缺点
使用不同大小的子集训练多种不同的模型是需要昂贵算力的,所以实际中这并不常见。
4.方法总结
- Get more training examples(扩大训练集)——>fixes high variance(高方差问题)
- Try smaller sets of features(更小的特征集)——>fixes high variance(高方差问题,模型不会那么复杂,方差不会那么高,如果怀疑你的算法有很多无关或没有帮助的特征,那么消除或减少特征的数量会有助于使模型不那么容易过拟合)
- Try getting additional features(增加额外的特征)——>fixes high bias(高偏差问题)
- Try adding polynomial features(添加多项式特征
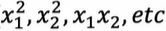 )——>fixes high bias(高偏差问题)
)——>fixes high bias(高偏差问题) - Try decreasing λ(减小λ)——>fixes high bias(减小λ意味着对正则化参数的值更小了,多关注前一项,以期算法在训练集上做得更好)
如果存在高方差问题:
1.获取更多的数据
2.简化模型(用更小的特征集)
3.增大λ(使算法很难适应非常复杂的曲线)
如果存在高偏差问题:
1.增加特征
2.添加多项式特征
3.减少正则化参数
通过缩小训练集来解决高偏差问题实际上并没有用
5.神经网络提供了一种新的方法来解决高偏差和高方差
如果神经网络足够大,几乎总是可以很好地拟合训练集
首先训练模型,看他在训练集上是否表现良好,可以通过计算J_train, 看看它是否偏高,减少偏差的一种方法就是使用更大的神经网络
在它在训练集中表现良好之后,看它在交叉验证集上是否做得好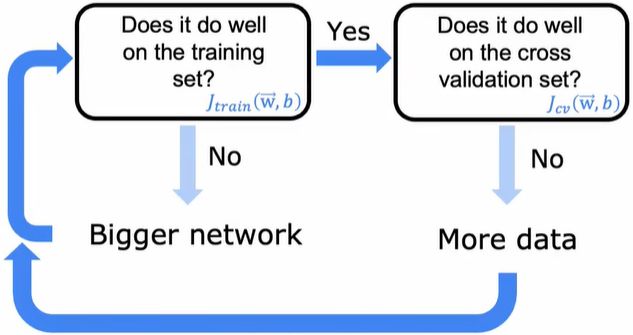
只要适当正则化,一个更大的网络准确度不受影响,一个经过精心选择的正则化的大型神经网络通常表现得和小的一样好或更好
6.误差分析(Error analysis)
诊断模型时,偏差和方差排第一,误差分析排第二
误差分析过程(error analysis process)是指人工检查出错的样本,并试图找出算法出错的地方。
偏差方差分析可以告诉你收集更多数据是否有帮助,通过误差分析判断缺少哪方面数据,或哪方面不准确

7.有效添加数据(Adding data)
由误差分析获得需要的数据
专注于获得预测不准确方面的数据
数据增强(Data augmentation)
(modifying an existing training example to create a new training example)用一个已有的训练例子来创建一个新的训练例子
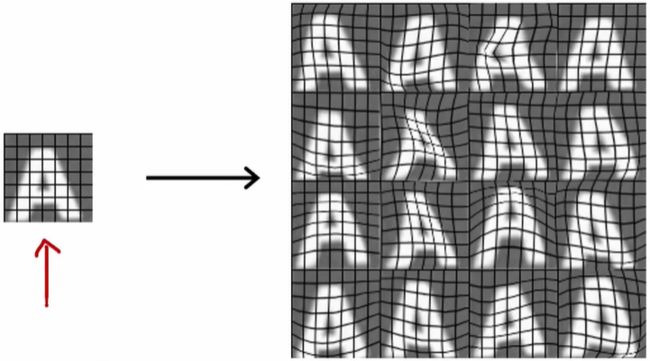

对于纯粹随机的无意义的噪声数据通常没有帮助
数据合成(Data synthesis)
创建全新的示例(using artificial data inputs to create a new training example)
常用于计算机视觉中


8.迁移学习(transfer learning)
从完全不同的几乎没有关联的任务中获取数据
复制网络,改变输出层

对于小的训练集,使用选项一,只训练输出层,稍微大一点的训练集使用选项二,训练所有的参数
首先在大型数据集上进行训练,然后在较小的数据集上进一步参数调优, 这两个步骤被称为监督预训练(supervised pretraining)
最重要的一步是监督预训练,那就是当你在一个非常大的数据集 上训练神经网络,比如一百万张和任务不太相关的图像上。
第二步称为微调(fine tuning),即使用你已经初始化的或从预训练获取到的参数,然后运行梯度下降,进一步的微调权重,以适应手写数字识别的特定程序。
即可以下载别人可能花了数周时间训练的神经网络,然后用自己的输出层替换原有的输出层
为什么能利用识别猫、狗、车、人获得的参数来帮助你识别像手写数字这样不同的东西呢?
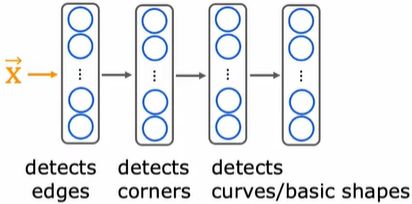
通过学习检测大量不同的图像,你在教神经网络学习检测边缘、角落和基本形状。
预训练条件限制:对于预训练和微调这两步,图像类型x必须是相同的(输入和预期输出的图像尺寸是相同的)
迁移学习步骤总结:
1. Download neural network parameters pretrained on a large dataset with same input type (e.g., images, audio, text) as your application (or train your own).第1步是下载带有参数的神经网络,这些参数已经在与算法相同输入类型的大型数据集上预先训练过了。
2.Further train (fine tune) the network on your own data.根据自己的数据进一 步训练或微调网络
9.机器学习项目的周期(Full cycle of a machine learning project)
在部署之后要确保可以实时监控系统的性能以及准确度

10. 误差度量(Error metrics for skewed datasets)精确率Precision
与召回率recall
用于当正负样本的比例非常倾斜

高精度意味着,如果算法诊断来访者患有罕见疾病,且大多数来访者确实患有这种病,那么我们说诊断是准确的。[精度: 预测为正的样本中有多少是真的预测正确了(找得对) ]
高召回意味着,已知来访者患有这种罕见的疾病,且算法能在很大程度上诊断出他们患有这种疾病。[召回:样本中的正例有多少被预测正确了(找得全) ]
评估一个包含罕见类的学习算法的性能一个有用的方法是构造一个混淆矩阵
如果算法一直打印0,则这两个量的分子都是0
当有一个倾斜数据集时,确保精确度和召回率都是比较高的值
精确度和召回率的权衡
假设我们想预测y = 1,只有在我们非常确信的情况下才会判定惠有这种罕见疾病,我们的理念是每当我们预测来访者患病了,我们可能要送他们进行治疗,这种治疗可能是昂贵的。如果患病的后果不那么严重,即使不采取积极治疗,那么只在我们十分有把握的情况下预测y = 1。在这种情况下,我们可以选择设置一个更高的阈值,只有当f (x)大于等于0.7时,我们才能预测y = 1,也就是说,我们预测y = 1时至少要有70%的把握,而不是50%的把握。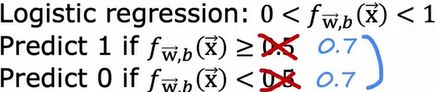
这两个数必须是相同的,因为取决于它是大于等于还是小于你预测的这个数(1或0),只有在非常自信的情况下才会预测y= 1,这意味着精度会增加。因为只要你预测y= 1,也就说明你有更有把握是对的,所以提高阈值会导致更高的精度,但它也会导致更低的召回,因为我们现在预测的次数变少了,所以在所有的患者中,我们能正确诊断出患病的人会更少。另一方面,假设我们不想漏掉太多罕见病的病例,所以在怀疑患病时预测y = 1,可能是这样的:治疗不会是高风险/太痛苦/昂贵的,但不治疗疾病会给患者带来更糟糕的后果。当怀疑患病的时候,我们就预测他患病,这样降低阈值,在这种情况下,只要你认为疾病存在的概率为30%或更高,你就会预测为1。只有当你非常确定疾病不存在时,你才会预测为0。
对于大多数算法程序而言,你最终要做的就是手动选择一 个阈值来权衡精度和召回率。如果你想自动权衡精度和召回率,而不是自己挑个值,这里还有另一个指标叫,F1评分(F1 score),
它可以自动结合精度和召回率,帮你选择最佳权衡值。F1分数是一 种结合P和R (精度和召回率)的方法,但它更强调这两值中较小的那个。因为事实证明,如果个算法的精度很低或召回率很低,那么算法就没那么有用。 这个方程也被称为P和R的调和均值,调和平均数是一种取平均值的方法,它更强调较小的值。
这个方程也被称为P和R的调和均值,调和平均数是一种取平均值的方法,它更强调较小的值。