一、线性回归的两种实现方式:(一)keras实现
线性回归的keras实现
导入必要的模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
制作数据集
x = np.array([50, 30, 15, 40, 55, 20, 45, 10, 60, 25])
y = np.array([5.9, 4.6, 2.7, 4.8, 6.5, 3.6, 5.1, 2.0, 6.3, 3.8])
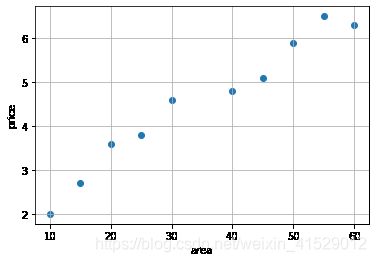
画出数据集的散点图
plt.scatter(x, y)
plt.grid(True)
plt.xlabel('area')
plt.ylabel('price')
plt.show()
数据划分
划分训练集和测试集
使用到的api:
数据划分sklearn.model_selection.train_test_split
用到的参数:
-
*arrays:输入数据集。
-
test_size:划分出来的测试集占总数据量的比例,取值0~1。
-
shuffle:是否在划分前打乱数据的顺序,默认True。
-
random_state:shuffle的随机种子,取值正整数。
返回:
- splitting:列表包含划分后的训练集与测试集。
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.3, shuffle=True, random_state=23)
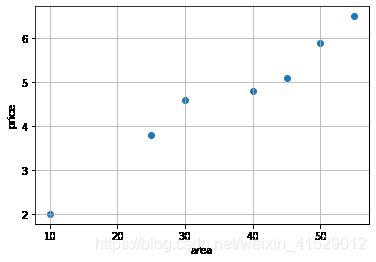
画出训练集数据的散点图
plt.scatter(x_train,y_train)
plt.grid('True')
plt.xlabel('area')
plt.ylabel('price')
plt.show()
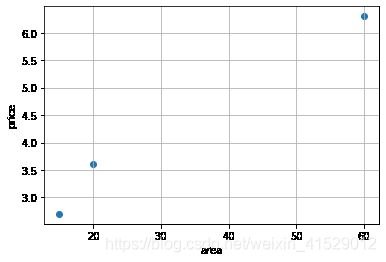
plt.scatter(x_test,y_test)
plt.grid('True')
plt.xlabel('area')
plt.ylabel('price')
plt.show()
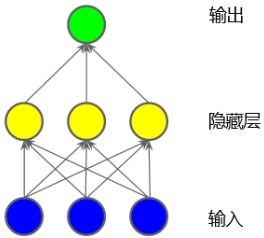
模型搭建
使用tf.keras.Sequential按顺序堆叠神经网络层,添加网络只要使用.add()函数即可。
使用到的api:
全连接操作 tf.keras.layers.Dense
用到的参数:
-
input_dim:如果是第一个全连接层,需要设置输入层的大小。
-
units:输入整数,全连接层神经元个数。
-
activation:激活函数,如果不设置,就表示不使用激活函数。
-
name:输入字符串,给该层设置一个名称。
模型设置tf.keras.Sequential.compile
用到的参数:
-
loss:损失函数,回归任务一般使用tf.keras.losses.MSE,或直接输入字符串’mse’。
更多损失函数请查看https://www.tensorflow.org/api_docs/python/tf/keras/losses -
optimizer:优化器,这里选用tf.keras.optimizers.SGD(learning_rate=1e-5), 也可以直接输入字符串"sgd"。
更多优化器请查看https://tensorflow.google.cn/api_docs/python/tf/keras/optimizers
model = Sequential()
# 全连接层
model.add(Dense(input_dim=1, units=1, name='dense'))
# 设置损失函数loss、优化器optimizer
model.compile(loss=tf.keras.losses.MSE, optimizer=tf.keras.optimizers.SGD(learning_rate=1e-5))
查看模型每层输出的shape和参数量
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 1) 2
=================================================================
Total params: 2
Trainable params: 2
Non-trainable params: 0
_________________________________________________________________
模型训练
使用到的api:
tf.keras.Sequential.fit
用到的参数:
-
x:输入数据。
-
y:输入标签。
-
batch_size:一次梯度更新使用的数据量。
-
epochs:数据集跑多少轮模型训练,一轮表示整个数据集训练一次。
-
validation_split:验证集占总数据量的比例,取值0~1。
返回:History对象,History.history属性会记录每一轮训练集和验证集的损失函数值和评价指标。
history = model.fit(x=x_train, y=y_train, batch_size=1, epochs=50, validation_split=0.2)
Train on 5 samples, validate on 2 samples
Epoch 1/50
5/5 [==============================] - 0s 26ms/sample - loss: 482.6461 - val_loss: 482.3914
Epoch 2/50
5/5 [==============================] - 0s 2ms/sample - loss: 360.0887 - val_loss: 357.5049
Epoch 3/50
5/5 [==============================] - 0s 2ms/sample - loss: 268.4071 - val_loss: 264.8373
Epoch 4/50
5/5 [==============================] - 0s 2ms/sample - loss: 200.4073 - val_loss: 195.9128
Epoch 5/50
5/5 [==============================] - 0s 2ms/sample - loss: 149.7012 - val_loss: 144.6555
Epoch 6/50
5/5 [==============================] - 0s 2ms/sample - loss: 111.6713 - val_loss: 106.6941
Epoch 7/50
5/5 [==============================] - 0s 2ms/sample - loss: 83.3859 - val_loss: 78.5178
Epoch 8/50
5/5 [==============================] - 0s 2ms/sample - loss: 62.2559 - val_loss: 57.7140
Epoch 9/50
5/5 [==============================] - 0s 2ms/sample - loss: 46.5967 - val_loss: 42.2464
Epoch 10/50
5/5 [==============================] - 0s 2ms/sample - loss: 34.8023 - val_loss: 30.8612
Epoch 11/50
5/5 [==============================] - 0s 2ms/sample - loss: 26.0726 - val_loss: 22.4354
Epoch 12/50
5/5 [==============================] - 0s 2ms/sample - loss: 19.5168 - val_loss: 16.2494
Epoch 13/50
5/5 [==============================] - 0s 2ms/sample - loss: 14.6472 - val_loss: 11.6986
Epoch 14/50
5/5 [==============================] - 0s 2ms/sample - loss: 11.0095 - val_loss: 8.3894
Epoch 15/50
5/5 [==============================] - 0s 2ms/sample - loss: 8.3121 - val_loss: 5.9693
Epoch 16/50
5/5 [==============================] - 0s 2ms/sample - loss: 6.2991 - val_loss: 4.2210
Epoch 17/50
5/5 [==============================] - 0s 2ms/sample - loss: 4.8059 - val_loss: 2.9474
Epoch 18/50
5/5 [==============================] - 0s 2ms/sample - loss: 3.6838 - val_loss: 2.0340
Epoch 19/50
5/5 [==============================] - 0s 2ms/sample - loss: 2.8482 - val_loss: 1.3821
Epoch 20/50
5/5 [==============================] - 0s 2ms/sample - loss: 2.2263 - val_loss: 0.9214
Epoch 21/50
5/5 [==============================] - 0s 2ms/sample - loss: 1.7627 - val_loss: 0.6028
Epoch 22/50
5/5 [==============================] - 0s 2ms/sample - loss: 1.4170 - val_loss: 0.3803
Epoch 23/50
5/5 [==============================] - 0s 2ms/sample - loss: 1.1575 - val_loss: 0.2312
Epoch 24/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.9646 - val_loss: 0.1337
Epoch 25/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.8177 - val_loss: 0.0724
Epoch 26/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.7084 - val_loss: 0.0387
Epoch 27/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.6273 - val_loss: 0.0230
Epoch 28/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.5684 - val_loss: 0.0197
Epoch 29/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.5253 - val_loss: 0.0238
Epoch 30/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.4919 - val_loss: 0.0332
Epoch 31/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.4673 - val_loss: 0.0453
Epoch 32/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.4484 - val_loss: 0.0595
Epoch 33/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.4344 - val_loss: 0.0743
Epoch 34/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.4242 - val_loss: 0.0886
Epoch 35/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.4172 - val_loss: 0.1004
Epoch 36/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.4122 - val_loss: 0.1125
Epoch 37/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.4080 - val_loss: 0.1245
Epoch 38/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.4051 - val_loss: 0.1333
Epoch 39/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.4030 - val_loss: 0.1429
Epoch 40/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.4016 - val_loss: 0.1500
Epoch 41/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.4003 - val_loss: 0.1575
Epoch 42/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.3994 - val_loss: 0.1621
Epoch 43/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.3990 - val_loss: 0.1666
Epoch 44/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.3979 - val_loss: 0.1743
Epoch 45/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.3978 - val_loss: 0.1767
Epoch 46/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.3978 - val_loss: 0.1803
Epoch 47/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.3975 - val_loss: 0.1843
Epoch 48/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.3974 - val_loss: 0.1877
Epoch 49/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.3969 - val_loss: 0.1922
Epoch 50/50
5/5 [==============================] - 0s 2ms/sample - loss: 0.3965 - val_loss: 0.1968
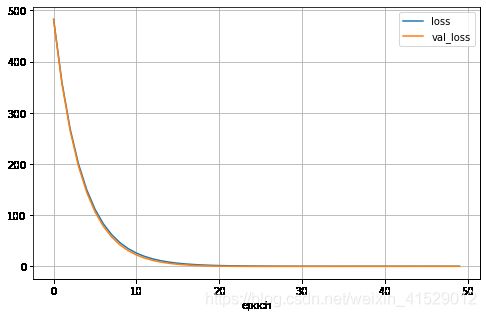
查看loss的变化趋势
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.xlabel('epoch')
plt.show()
模型验证
使用到的api:
tf.keras.Sequential.evaluate
用到的参数:
-
x:输入数据。
-
y:输入标签。
-
batch_size:一次模型验证使用的数据量。
返回:损失值
# 计算测试集的mse
loss = model.evaluate(x=x_test, y=y_test, batch_size=32)
print('Test dataset mse: ', loss)
3/3 [==============================] - 0s 13ms/sample - loss: 1.1246
Test dataset mse: 1.124564528465271
Weight=0.1257970780134201 bias=0.01565614901483059
模型预测
使用到的api:
tf.keras.Sequential.predict
用到的参数:
- x:需要做预测的数据集。
返回:预测值
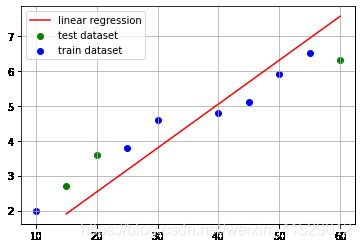
# 对测试集做预测
y_test_pred = model.predict(x=x_test)
# 画出数据集的散点图和预测直线
plt.scatter(x_test, y_test, color='g', label='test dataset')
plt.scatter(x_train, y_train, color='b',label='train dataset')
plt.plot(np.sort(x_test), y_test_pred[np.argsort(x_test)], color='r', label='linear regression')
plt.legend()
plt.grid(True)
plt.show()
预测面积为35平米的房屋租赁价格
result = model.predict(np.array([35]))
print('Renting price: {:.2f}'.format(result.item()))
Renting price: 4.42
查看线性回归模型的系数w和截距b
w, b = model.layers[0].get_weights()
print('Weight={0} bias={1}'.format(w.item(), b.item()))