【ICnet2018】ICNet for Real-Time Semantic Segmentation on High-Resolution Images
ICNet for Real-Time Semantic Segmentation on High-Resolution Images
用于高分辨率图像的实时语义分割的ICNet
arXiv:1704.08545v2 [cs.CV] 20 Aug 2018
文章地址:https://arxiv.org/abs/1704.08545
代码地址:https://github.com/hszhao/ICNet
摘要
在本文中,我们专注于实时语义分割的挑战性任务。它有许多实际应用,但在减少像素级标签推断的大量计算方面存在根本困难。我们提出了一个图像级联网络(ICNet),它在适当的标签指导下纳入了多分辨率的分支,以解决这一挑战。我们对我们的框架进行了深入分析,并介绍了级联特征融合单元以快速实现高质量的分割。我们的系统在单个GPU卡上产生了实时推理,并在Cityscapes、CamVid和COCO-Stuff等具有挑战性的数据集上评估了良好的质量结果。
索引项–实时、高分辨率、语义分割
1导言
语义图像分割是计算机视觉中的一项基本任务。它为图像中的所有像素预测密集的标签,并被认为是一项非常重要的任务,可以帮助深入理解场景、物体和人类。最近深度卷积神经网络(CNN)的发展在语义分割方面取得了显著的进展[1,2,3,4,5,6]。这些网络的有效性在很大程度上取决于关于深度和宽度的复杂的模型设计,它必须涉及许多操作和参数。

注释1:蓝色的是用降采样的图像测试的。推断速度是用单一网络向前报告的,而几个以mIoU为目标的方法(如PSPNet?)的准确性可能包含多尺度和翻转等测试技巧,导致更多时间。详细资料见补充材料。
基于CNN的语义分割主要利用全卷积网络(FCN)。现在人们普遍认为,结果准确性的提高几乎意味着更多的操作,特别是对于像语义分割这样的像素级预测任务。为了说明这一点,我们在图1(a)中展示了不同框架在Cityscapes[7]数据集上的准确性和推理时间。
快速语义分割的现状 与高质量语义分割的超常发展相反,沿着使语义分割快速运行而又不牺牲太多质量的研究被抛在后面。我们注意到,实际上这条工作线也同样重要,因为它可以启发或促成许多实际的任务,例如自动驾驶、机器人互动、在线视频处理,甚至是移动计算,在这些领域,运行时间成为评估系统性能的关键因素。
我们的实验表明,ResNet38[6]和PSPNet[5]的高精度方法在测试期间在一块Nvidia TitanX GPU卡上预测一幅1024×2048的高分辨率图像需要1秒左右。这些方法属于图1(a)所示的区域,准确度高,速度低。相反,最近的ENet[8]和SQ[9]的快速语义分割方法,在图中的位置完全不同。速度大大加快;但是准确率下降,最终的mIoU低于60%。这些方法位于图中的右下角阶段。
我们的重点和贡献 在本文中,我们专注于建立一个实际快速的语义分割系统,并具有适当的预测准确性。我们的方法是同类中第一个定位在图1(a)所示的右上角区域的方法,也是仅有的两种可用的实时方法之一。它在效率和准确性之间实现了适当的权衡。
与以往的架构不同,我们对速度和精度这两个看似矛盾的因素进行了综合考虑。我们首先对语义分割框架的时间预算进行了深入分析,并进行了广泛的实验来证明直观的加速策略的不足。这促使我们开发了图像级联网络(ICNet),一个具有良好质量的高效分割系统。它利用了低分辨率图像的处理效率和高分辨率图像的高推理质量。其思路是让低分辨率图像先经过完整的语义感知网络,以获得粗略的预测图。然后提出级联特征融合单元和级联标签引导策略,整合中、高分辨率特征,逐步完善粗略的语义图。我们公开了我们所有的代码和模型。我们的主要贡献和性能统计如下。
-
我们为实时语义分割开发了一个新颖独特的图像级联网络,它有效地利用了低分辨率的语义信息和高分辨率图像的细节。
-
所开发的级联特征融合单元与级联标签引导一起,能够以低计算成本逐步恢复和完善分割预测。
-
我们的ICNet实现了推理时间5倍的加速,并将内存消耗降低了5倍。它可以在高分辨率1024×2048下运行,速度为30帧/秒,同时完成高质量的结果。它在包括Cityscapes[7]、CamVid[17]和COCO-Stuff[18]在内的各种数据集上产生实时推理。
2 相关工作
传统的语义分割方法[19]采用手工制作的特征来学习表示。最近,基于CNN的方法在很大程度上提高了性能。
高质量语义分割 FCN[1]是用卷积层取代分类中最后的全连接层的先驱工作。DeepLab[2,13]和[14]使用扩张卷积来扩大密集标记的感受野。编码器-解码器结构[3,4]可以将后面几层的高级语义信息与前面几层的空间信息结合起来。在[20,21,22]中也使用了多尺度特征集合。在[2,15,16]中,条件随机场(CRF)或马尔科夫随机场(MRF)被用来模拟空间关系。Zhao等人[5]使用金字塔集合法来聚合全局和局部环境信息。Wu等人[6]采用了一个更广泛的网络来提高性能。在[11]中,一个多路径细化网络结合了多尺度图像特征。这些方法是有效的,但不包括实时推理。
高效率语义分割 在物体检测中,速度成为系统设计的一个重要因素[23,24]。最近的Yolo[25,26]和SSD[27]是代表性的解决方案。相比之下,语义分割中的高速推理还没有被充分开发。ENet[8]和[28]是轻型网络。这些方法大大提高了效率,但明显牺牲了准确性。
视频语义分割 视频包含帧中的冗余信息,可以利用它们来减少计算。最近的Clockwork[29]重用了给定的稳定视频输入的特征图。深度特征流[30]是基于一个小规模的光流网络,将特征从关键帧传播到其他帧。FSO[31]通过密集的CRF应用于优化的特征进行结构化预测,以获得时间上的一致性预测。NetWarp[32]利用相邻帧的光流,在视频序列中跨时间空间翘起内部特征。我们注意到,当一个准确度高的快速图像语义分割框架出现时,视频分割也将从中受益。
3 图像级联网络
我们首先通过实验统计分析了高性能分割框架PSPNet[5]上不同组件的计算时间预算。然后,我们介绍了图2所示的图像级联网络(ICNet),以及级联特征融合单元和级联标签引导,用于快速语义分割。
3.1 速度分析
在卷积中,变换函数 Φ Φ Φ被应用于输入特征图 V ∈ R c × h × w V∈R^{c×h×w} V∈Rc×h×w,得到输出图 U ∈ R c ′ × h ′ × w ′ U∈R^{c'×h'×w'} U∈Rc′×h′×w′,其中c、h和w分别表示特征通道、高度和宽度。变换操作 Φ : V → U Φ:V→U Φ:V→U是通过应用 c ′ c' c′个三维核 K ∈ R c × k × k K∈R^{c×k×k} K∈Rc×k×k实现的,其中k×k(例如3×3)是核的空间大小。因此卷积层的总操作数 O ( Φ ) O(Φ) O(Φ)为 c ′ c k 2 h ′ w ′ c'ck^2h'w' c′ck2h′w′。输出图 h ′ h' h′和 w ′ w' w′的空间大小与输入高度相关,由参数stride s控制为 h ′ = h s h'= {h\over s} h′=sh, w ′ = w s w'={w \over s} w′=sw,使得
O ( Φ ) ≈ c ′ c k 2 h w s 2 (1) O(Φ)≈c'ck^2{hw \over s^2} \tag{1} O(Φ)≈c′ck2s2hw(1)
计算复杂性与特征图分辨率(如 h 、 w 、 s h、w、s h、w、s)、核的数量和网络宽度(如 c 、 c ′ c、c' c、c′)有关。图1(b)显示了PSPNet50中两种分辨率图像的时间成本。蓝色曲线对应的是1024×2048的高分辨率输入,绿色曲线对应的是512×1024分辨率的图像。计算量随着图像分辨率的提高而呈正比增长。对于任何一条曲线,阶段4和阶段5的特征图都具有相同的空间分辨率,即原始输入的1/8;但阶段5的计算量是阶段4的四倍。这是因为第五阶段的卷积层与输入通道 c ′ c' c′一起将核的数量增加了一倍。
3.2 网络结构
根据上述时间预算分析,我们在第5节将详细介绍的实验中采取了直观的加速策略,包括对输入进行降采样,缩小特征图和进行模型压缩。相应的结果表明,要在推理精度和速度之间保持良好的平衡是非常困难的。直观的策略可以有效地减少运行时间,同时产生非常粗略的预测图。直接将高分辨率的图像输入网络,在计算上是无法忍受的。

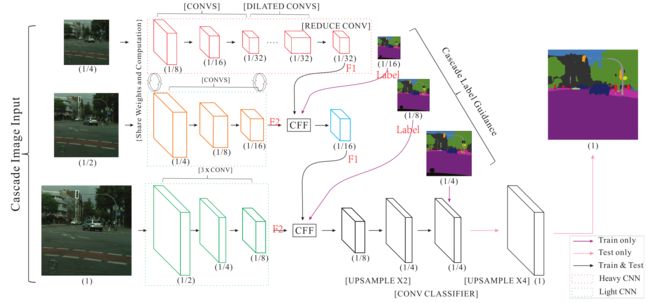
括号内的操作是突出的。底部分支中最后的×4升采样只在测试中使用。
我们提出的系统图像级联网络(ICNet)并不简单地选择这两种方式。相反,它采取级联图像输入(即低、中、高分辨率图像),采用级联特征融合单元(第3.3节),并通过级联标签指导进行训练(第3.4节)。新的架构如图2所示。全分辨率的输入图像(如Cityscapes[7]中的1024×2048)按2和4的系数下采样,形成级联输入到中分辨率和高分辨率分支。
用经典的框架如FCN直接对高分辨率的输入进行分割是很耗时的。为了克服这个缺点,我们使用低分辨率输入来进行语义提取,如图2的顶部分支所示。1/4大小的图像以8的下采样率输入PSPNet,得到1/32分辨率的特征图。为了获得高质量的分割,中等和高分辨率的分支(图2中的中间和底部)有助于恢复和完善粗略的预测。尽管在顶部分支中,一些细节被遗漏,并且产生了模糊的边界,但它已经收获了大部分语义部分。因此,我们可以安全地限制中间和底部分支的参数数量。轻量级CNN(绿色虚线框)被用于更高分辨率的分支;不同分支的输出特征图被级联特征融合单元(第3.3节)融合,并通过级联标签指导进行训练(第3.4节)。
虽然顶层分支是基于完整的分割骨架,但输入的分辨率很低,导致计算量有限。即使是有50多层的PSPNet,对于Cityscapes中的大型图像,推理时间和内存也是18ms和0.6GB。由于权重和计算(17层)可以在低级和中级分支之间共享,构建融合图只花了6ms。底层分支的层数更少。虽然分辨率很高,但推理只需要9毫秒。架构的细节在补充文件中介绍。有了所有这三个分支,我们的ICNet成为一个非常高效和内存友好的架构,可以实现高质量的分割。
3.3 级联特征融合
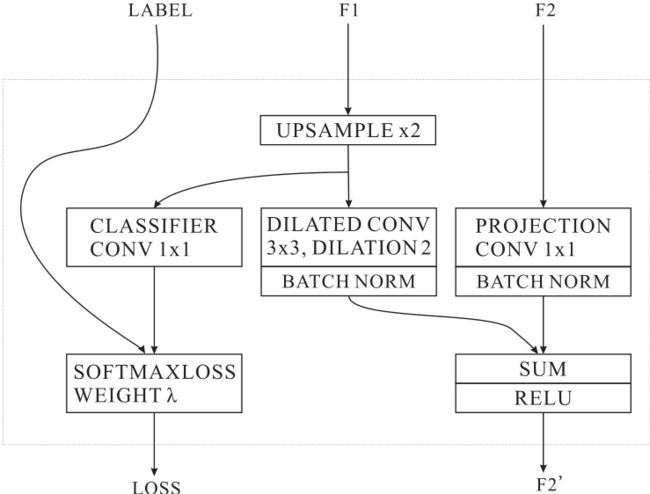
为了结合来自不同分辨率输入的级联特征,我们提出了一个级联特征融合(CFF)单元,如图3所示。该单元的输入包含三个部分:两个特征图 F 1 F_1 F1和 F 2 F_2 F2,尺寸分别为 C 1 × H 1 × W 1 C_1×H_1×W_1 C1×H1×W1和 C 2 × H 2 × W 2 C_2×H_2×W_2 C2×H2×W2,以及一个分辨率为 1 × H 2 × W 2 1×H_2×W_2 1×H2×W2的地面真实标签。 F 2 F_2 F2的空间大小是 F 1 F_1 F1的两倍。
我们首先通过双线性插值对 F 1 F_1 F1进行上采样率2,得到与 F 2 F_2 F2相同的空间尺寸。然后,应用内核大小为 C 3 × 3 × 3 C_3×3×3 C3×3×3和扩张2的扩张卷积层来细化上采样的特征。得到的特征大小为 C 3 × H 2 × W 2 C_3 × H_2 × W_2 C3×H2×W2。这个扩张卷积层结合了几个原本相邻的像素的特征信息。与去卷积相比,上采样后的扩张卷积只需要小的内核,就能获得相同的感受野。为了保持相同的感受区,去卷积需要的核大小比扩张卷积的上采样要大(即7×7对3×3),这导致了更多的计算。
对于特征 F 2 F_2 F2,利用核大小为 C 3 × 1 × 1 C_3×1×1 C3×1×1的投影卷积来投影 F 2 F_2 F2,使其具有与 F 1 F_1 F1的输出相同的通道数。然后,如图3所示,使用两个批处理归一化层来归一化这两个处理过的特征。接着是一个逐元的 " s u m sum sum"层和一个 " R e L U ReLU ReLU"层,我们得到融合的特征 F 2 ′ F'_2 F2′,即 C 3 × H 2 × W 2 C_3 × H_2 × W_2 C3×H2×W2。为了加强对 F 1 F_1 F1的学习,我们在 F 1 F_1 F1的升采样特征上使用了一个辅助标签指导。
3.4 级联标签指导
为了加强每个分支的学习程序,我们采用了级联标签指导策略。它利用不同尺度(如 1 / 16 、 1 / 8 1/16、1/8 1/16、1/8和 1 / 4 1/4 1/4)的地面真实标签来指导低、中和高分辨率输入的学习阶段。给定 T T T个分支(即 T = 3 T=3 T=3)和 N N N个类别。在分支 t t t中,预测的特征图 F t F^t Ft具有空间大小 Y t × X t Y_t×X_t Yt×Xt。在位置 ( n , y , x ) (n,y,x) (n,y,x)的值为 F n , y , x t F_{n,y,x}^t Fn,y,xt。二维位置 ( y , x ) (y,x) (y,x)对应的地面真实标签为 n ^ \hat n n^。为了训练ICNet,我们在每个分支中附加加权的softmax交叉熵损失,并加上相关的损失权重 λ t λ_t λt。因此,我们最小化损失函数 L L L,定义为
L = − ∑ t = 1 T λ t 1 y t x t ∑ y = 1 y t ∑ x = 1 x t log e F n ^ , y , x t ∑ n = 1 N e F n , y , x t (2) L = - \sum\limits_{t = 1}^{\rm T} {{\lambda _t}{1 \over {{y_t}{x_t}}}} \sum\limits_{y = 1}^{{y_t}} {\sum\limits_{x = 1}^{{x_t}} {\log {{{e^{F_{\hat n,y,x}^t}}} \over {\sum\nolimits_{n = 1}^N {{e^{F_{n,y,x}^t}}} }}} } \tag{2} L=−t=1∑Tλtytxt1y=1∑ytx=1∑xtlog∑n=1NeFn,y,xteFn^,y,xt(2)
在测试阶段,简单地放弃低、中引导操作,其中只保留高分辨率分支。这种策略使梯度优化更加平滑,便于训练。由于每个分支都有更强大的学习能力,最终的预测图不会被任何单一的分支所支配。
4 结构比较和分析
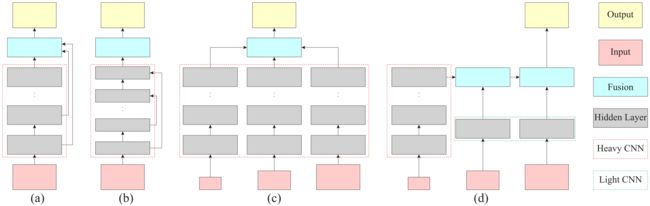
现在我们说明ICNet与现有的语义分割级联架构的区别。以前的语义分割系统的典型结构如图4所示。我们提出的ICNet(图4(d))在本质上与其他系统不同。鉴于高分辨率的输入,以前的框架都有相对密集的计算。而在我们的级联结构中,只有最低分辨率的输入被送入重型CNN,并大大减少了计算量,以获得粗略的语义预测。高分辨率的输入被设计为逐步恢复和完善关于模糊边界和缺失细节的预测。因此,它们由轻量级的CNN处理。新引入的级联特征融合单元和级联标签引导策略整合了中、高分辨率的特征,逐步完善了粗略的语义图。在这种特殊的设计中,ICNet实现了高效率的推理和合理质量的分割结果。
5 实验评估
我们的方法对高分辨率的图像是有效的。我们在三个具有挑战性的数据集上评估了该架构,包括图像分辨率为1024×2048的城市场景理解数据集Cityscapes[7]、图像分辨率为720×960的CamVid[17]以及图像分辨率高达640×640的东西理解数据集COCO-Stuff[18]。COCO-Stuff和VOC2012[35]和ADE20K[36]的物体/场景分割数据集之间有一个明显的区别。在后两个数据集中,大多数图像都是低分辨率的(例如,300 × 500),已经可以快速处理。而在COCO-Stuff中,大多数图像都比较大,因此更难达到实时性能。
在下文中,我们首先展示了直观的加速策略和它们的缺点,然后通过定量和视觉分析揭示了我们的改进。
5.1 实施细节
我们基于平台Caffe[37]进行实验。所有的实验都是在装有Maxwell TitanX GPU卡的工作站上进行的,在CUDA 7.5和CUDNN V5下。我们的测试只使用一块卡。为了测量前向推理时间,我们使用时间测量工具 “Caffe time”,并将重复迭代次数设置为100,以消除测试过程中的意外错误。批量归一化层中的所有参数都被合并到相邻的前向卷积层中。
对于训练的超参数,迷你批次大小被设置为16。基础学习率为0.01,采用功率为0.9的 "聚 "学习率策略,同时将Cityscapes的最大迭代次数设置为30K,CamVid为10K,COCO-Stuff为30K。动量为0.9,权重衰减为0.0001。数据增量包含随机镜像和0.5到2之间的rand调整。根据经验,在公式(2)中, λ 1 λ_1 λ1和 λ 2 λ_2 λ2的辅助损失权重被设定为0.4, λ 3 λ_3 λ3的辅助损失权重被设定为1,如[5]所采用。在评估中,使用了类的平均交集(mIoU)和网络前进时间(Time)。
5.2 城市景观
我们首先将我们的框架应用于最近的城市场景理解数据集Cityscapes[7]。这个数据集包含高分辨率的1024×2048的图像,这对快速语义分割是一个很大的挑战。它包含5000张精细注释的图像,分为训练、验证和测试集,分别有2975张、500张和1525张图像。密集的注释包含30个常见的类别,如道路、人物、汽车等。其中19个被用于训练和测试。
直观加速 根据公式(1)中显示的时间复杂度,我们从三个方面进行直观加速,即对输入进行降采样,对特征进行降采样,以及对模型进行压缩。

下采样输入 图像分辨率是影响运行速度的最关键因素,正如第3.1节所分析的。一个简单的方法是使用小分辨率的图像作为输入。我们测试以1/2和1/4的比例对图像进行下采样,并将得到的图像输入PSPNet50。我们直接将预测结果上采样到原始尺寸。根据经验,这种方法有几个缺点,如图5所示。在缩放比为0.25的情况下,虽然推理时间减少了很多,但预测图非常粗糙,与高分辨率的预测相比,遗漏了很多小而重要的细节。在缩放比为0.5的情况下,与0.25的情况相比,预测恢复了更多信息。不幸的是,离摄像机较远的人和交通灯仍然丢失,而且物体的边界也很模糊。更糟糕的是,对于一个实时系统来说,运行时间仍然太长。

下采样特征 除了直接对输入图像进行下采样,另一个简单的选择是在推理过程中对特征图进行大比例的下采样。FCN[1]对其进行了32次降采样,DeepLab[2]对其进行了8次降采样。我们用1:8、1:16和1:32的下采样比例测试PSPNet50,结果显示在表1的左边。较小的特征图可以产生更快的推理,但代价是牺牲了预测精度。损失的信息主要是包含在低层的细节。另外,即使在比例1:32下产生的最小的特征图,系统在推理中仍然需要131ms。
模型压缩 除了上述两种策略外,另一种降低网络复杂性的自然方法是在每一层中修剪内核。由于需求量大,压缩模型在近年来成为一个活跃的研究课题。解决方案[38,39,40,41]可以使一个复杂的网络在用户控制的精度降低下减少到一个较轻的网络。我们在我们的分割模型上采用了最近在[41]中提出的有效分类模型压缩策略。对于每个过滤器,我们首先计算核 l 1 − n o r m l_1-norm l1−norm的总和。然后,我们将这些总和的结果按降序排序,只保留最重要的结果。令人失望的是,鉴于表1右边列出的压缩模型,这个策略也不符合我们的要求。即使只保留四分之一的内核,推理时间仍然太长。同时,相应的mIoU低得令人难以忍受–它已经不能为许多应用产生合理的分割。
sub4"、"sub24 "和 "sub124 "分别代表低、中、高分辨率分支的预测结果。
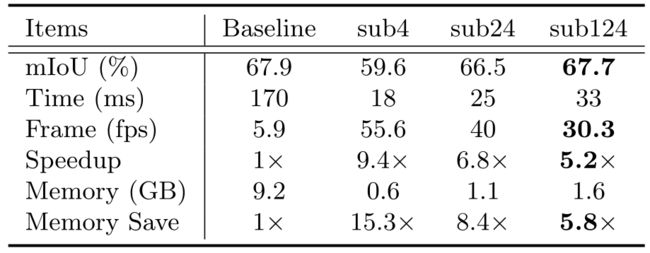
级联分支 我们对级联分支进行消融研究,结果见表2。我们的基线是半压缩的PSPNet50,推理时间为170ms,mIoU降低到67.9%。他们表明,在保持适当的分割质量的条件下,模型压缩几乎没有机会实现实时性能。基于这个基线,我们在不同的分支上测试我们的ICNet。为了显示所提出的级联框架的有效性,我们将低、中、高分辨率分支的输出表示为 “sub4”、"sub24 "和 “sub124”,其中数字代表使用的信息。设置’sub4’只使用具有低分辨率输入的顶部分支。'sub24’和’sub124’分别包含顶部两个和所有三个分支。
我们在Cityscapes的验证集上测试这三种设置,并在表2中列出结果。只用低分辨率的输入分支,虽然运行时间很短,但结果质量下降到59.6%。使用两个和三个分支,我们将mIoU分别提高到66.5%和67.7%。运行时间只增加了7ms和8ms。请注意我们的分割质量几乎与基线保持一致,但速度却快了5.2倍。内存消耗也明显减少了5.8倍。
核3×3、5×5和7×7的去卷积操作代替 "双线性上采样+扩展卷积"。
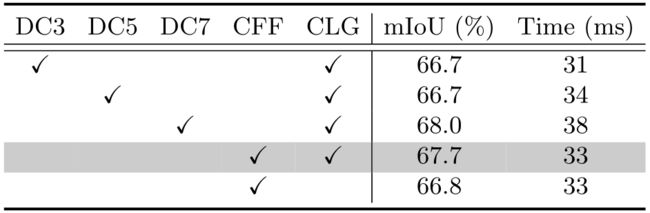
级联结构 我们还对级联特征融合单元和级联标签引导进行了消融研究。结果显示在表3中。与具有3×3和5×5核的解卷积层相比,在推理效率相似的情况下,级联特征融合单元获得了更高的mIoU性能。与具有较大内核(7×7)的去卷积层相比,mIoU性能接近,而级联特征融合单元产生更快的处理速度。如果没有级联标签引导,性能会下降很多,如最后一行所示。

注释3: 单个网络转发花费1288ms(使用TitanX Maxwell,Pascal为680ms),而旨在提升性能的mIoU测试(81.2% mIoU)花费51.0s。
方法比较 我们最后列出我们提出的ICNet在Cityscapes测试集上的mIoU性能和推理时间。它在Cityscapes的训练集和验证集上进行了90K次迭代训练。结果包括在表4中。其他方法的报告的mIoUs和运行时间显示在官方的Cityscapes领导板上。为了公平起见,我们不包括没有报告运行时间的方法。其中许多方法可能采用了耗时的多尺度测试来获得最佳结果质量。
我们的ICNet产生的mIoU为69.5%。它甚至在数量上优于几个不关心速度的方法。它比ENet[8]和SQ[9]高约10个点。用精细和粗略的数据进行训练可以将mIoU的性能提高到70.6%。ICNet是在1024×2048分辨率的图像上采用30fps的方法,只使用一块TitanX GPU卡。视频实例可以通过link访问。
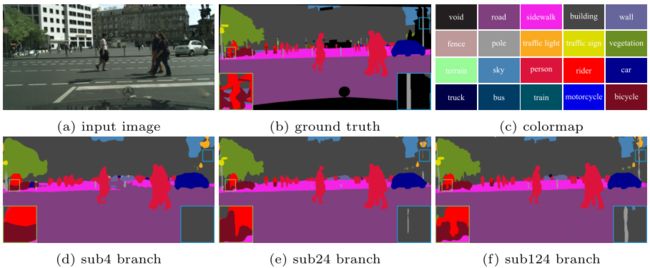

视觉改进 图6和图7显示了ICNet在城市景观上的视觉结果。通过建议的渐进式特征融合步骤和级联式标签指导结构,我们产生了不错的预测结果。有趣的是,"sub4 "分支的输出已经可以捕获大部分有语义的物体。但由于低分辨率的输入,预测结果是粗略的。它漏掉了一些小尺寸的重要区域,如电线杆和交通标志。
在中分辨率信息的帮助下,许多这些区域被重新估计并恢复,如 "sub24 "分支所示。值得注意的是,离摄像机较远的物体,如一些人,仍然没有找到,物体边界模糊不清。采用全分辨率输入的’sub124’分支有助于完善这些细节–该分支的输出无疑是最好的。这表明我们的不同分辨率信息在这个框架中得到了适当的利用。
定量分析 为了进一步了解每个分支的精度增益,我们对基于连接部件的预测标签图进行定量分析。对于每个连接区域Ri,我们计算其包含的像素数,表示为Si。然后,我们计算相应地图中正确预测的像素数为si。因此,Ri中的预测区域精度pi为si/Si。根据区域大小Si,我们将这些区域投射到一个具有区间K的直方图H上,并将所有相关区域精度pi的平均值作为当前bin的值。
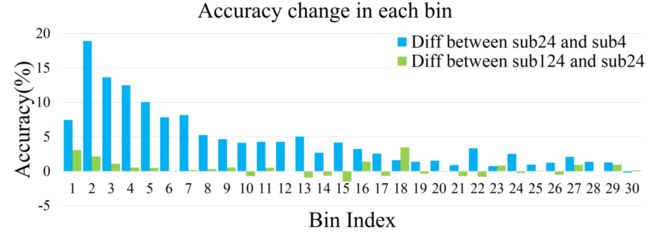
在实验中,我们将直方图的bin大小设定为30,间隔K设定为3,000。因此,它涵盖了1到90K之间的区域大小Si。我们忽略了大小超过90K的区域。图8显示了每个bin中的准确度变化。蓝色直方图代表 "sub24 "和 "sub4 "之间的差异,而绿色直方图显示 "sub124 "和 "sub24 "之间的差异。对于这两张直方图来说,巨大的差异主要是在区域大小较小的前仓。这表明像交通灯和电线杆这样的小区域物体在我们的框架中可以得到很好的改善。前面的变化是大的正数,证明’sub24’可以在’sub4’的基础上恢复很多小物体的信息。与’sub24’相比,'sub124’也非常有用。
5.3 CamVid
CamVid[17]数据集包含从高分辨率视频序列中提取的图像,分辨率高达720×960。为了便于与之前的工作进行比较,我们采用了Sturgess等人[42]的分割方法,将数据集分为367张、100张和233张图像,分别用于训练、验证和测试。11个语义类别被用于评估。
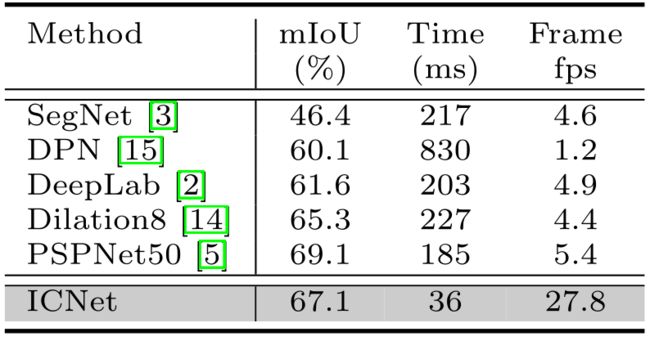
测试结果列于表5,我们的基础模型是没有压缩的PSPNet50。在这种高分辨率下,ICNet的推理速度比其他方法快得多,实时速度达到27.8fps,比第二种方法快5.7倍,比基本模型快5.1倍。除了高效率外,它还完成了高质量的分割。视觉结果在补充材料中提供。
5.4 COCO-Stuff
COCO-Stuff[18]是最近基于MS-COCO[43]的标记数据集,用于上下文的东西分割。我们按照[18]中的分法对ICNet进行评估,即9K图像用于训练,另外1K用于测试。这个数据集对于多个类别来说要复杂得多–多达182个类别被用于评估,包括91个事物和91个东西类别。
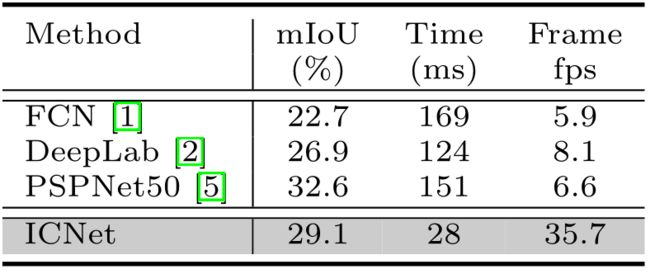
表6显示了测试的结果。ICNet在普通事物和东西的理解方面的表现仍然令人满意。它比现代的分割框架,如FCN和DeepLab,更加有效和准确。与我们的基线模型相比,它实现了5.4倍的速度提升。视觉预测在补充材料中提供。
6 结论
我们已经提出了一个实时语义分割系统ICNet。它采用了有效的策略来加速网络推理的速度而不牺牲很多性能。主要的贡献包括在多个分辨率下保存操作的新框架和强大的融合单元。
我们相信速度和准确性的最佳平衡使我们的系统非常重要,因为它可以使许多其他需要快速场景和物体分割的任务受益。它大大增强了语义分割在其他学科中的实用性。
References
- Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: CVPR. (2015)
- Chen, L., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Semantic image segmentation with deep convolutional nets and fully connected crfs. ICLR (2015)
- Badrinarayanan, V., Kendall, A., Cipolla, R.: Segnet: A deep convolutional encoder-decoder architecture for image segmentation. arXiv:1511.00561 (2015)
- Noh, H., Hong, S., Han, B.: Learning deconvolution network for semantic segmentation. In: ICCV. (2015)
- Zhao, H., Shi, J., Qi, X., Wang, X., Jia, J.: Pyramid scene parsing network. In:CVPR. (2017)
- Wu, Z., Shen, C., van den Hengel, A.: Wider or deeper: Revisiting the resnet model for visual recognition. arXiv:1611.10080 (2016)
- Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R.,Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In: CVPR. (2016)
- Paszke, A., Chaurasia, A., Kim, S., Culurciello, E.: Enet: A deep neural network architecture for real-time semantic segmentation. arXiv:1606.02147 (2016)
- Treml, M., Arjona-Medina, J., Unterthiner, T., Durgesh, R., Friedmann, F., Schuberth, P., Mayr, A., Heusel, M., Hofmarcher, M., Widrich, M., Nessler1, B., Hochreiter, S.: Speeding up semantic segmentation for autonomous driving. NIPS Workshop (2016)
- Wang, P., Chen, P., Yuan, Y., Liu, D., Huang, Z., Hou, X., Cottrell, G.W.: Understanding convolution for semantic segmentation. arXiv:1702.08502 (2017)
- Lin, G., Milan, A., Shen, C., Reid, I.D.: Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In: CVPR. (2017)
- Pohlen, T., Hermans, A., Mathias, M., Leibe, B.: Full-resolution residual networks for semantic segmentation in street scenes. In: CVPR. (2017)
- Chen, L., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. arXiv:1606.00915 (2016)
- Yu, F., Koltun, V.: Multi-scale context aggregation by dilated convolutions. ICLR(2016)
- Liu, Z., Li, X., Luo, P., Loy, C.C., Tang, X.: Semantic image segmentation via deep parsing network. In: ICCV. (2015)
- Zheng, S., Jayasumana, S., Romera-Paredes, B., Vineet, V., Su, Z., Du, D., Huang,C., Torr, P.H.S.: Conditional random fields as recurrent neural networks. In: ICCV.(2015)
- Brostow, G.J., Fauqueur, J., Cipolla, R.: Semantic object classes in video: A high-definition ground truth database. Pattern Recognition Letters (2009)
- Caesar, H., Uijlings, J., Ferrari, V.: Coco-stuff: Thing and stuff classes in context.arXiv:1612.03716 (2016)
- Liu, C., Yuen, J., Torralba, A.: Nonparametric scene parsing via label transfer.TPAMI (2011)
- Chen, L., Yang, Y., Wang, J., Xu, W., Yuille, A.L.: Attention to scale: Scale-aware semantic image segmentation. In: CVPR. (2016)
- Hariharan, B., Arbel´ aez, P.A., Girshick, R.B., Malik, J.: Hypercolumns for object segmentation and fine-grained localization. In: CVPR. (2015)
- Xia, F., Wang, P., Chen, L., Yuille, A.L.: Zoom better to see clearer: Human and object parsing with hierarchical auto-zoom net. In: ECCV. (2016)
- Girshick, R.: Fast R-CNN. In: ICCV. (2015)
- Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: Towards real-time object detection with region proposal networks. In: NIPS. (2015)
- Redmon, J., Divvala, S.K., Girshick, R.B., Farhadi, A.: You only look once: Unified,real-time object detection. In: CVPR. (2016)
- Redmon, J., Farhadi, A.: YOLO9000: better, faster, stronger. In: CVPR. (2017)
- Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S.E., Fu, C., Berg, A.C.: Ssd:Single shot multibox detector. In: ECCV. (2016)
- Romera, E., Alvarez, J.M., Bergasa, L.M., Arroyo, R.: Efficient convnet for real time semantic segmentation. In: Intelligent Vehicles Symposium (IV). (2017)
- Shelhamer, E., Rakelly, K., Hoffman, J., Darrell, T.: Clockwork convnets for video semantic segmentation. In: ECCV Workshop. (2016)
- Zhu, X., Xiong, Y., Dai, J., Yuan, L., Wei, Y.: Deep feature flow for video recog nition. In: CVPR. (2017)
- Kundu, A., Vineet, V., Koltun, V.: Feature space optimization for semantic video segmentation. In: CVPR. (2016)
- Gadde, R., Jampani, V., Gehler, P.V.: Semantic video cnns through representation warping. In: ICCV. (2017)
- Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: MICCAI. (2015)
- Ghiasi, G., Fowlkes, C.C.: Laplacian pyramid reconstruction and refinement for semantic segmentation. In: ECCV. (2016)
- Everingham, M., Gool, L.J.V., Williams, C.K.I., Winn, J.M., Zisserman, A.: The pascal visual object classes VOC challenge. IJCV (2010)
- Zhou, B., Zhao, H., Puig, X., Fidler, S., Barriuso, A., Torralba, A.: Semantic
understanding of scenes through the ADE20K dataset. arXiv:1608.05442 (2016) - Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J., Girshick, R.B., Guadarrama, S., Darrell, T.: Caffe: Convolutional architecture for fast feature embedding.In: ACM MM. (2014)
- Iandola, F.N., Moskewicz, M.W., Ashraf, K., Han, S., Dally, W.J., Keutzer, K.:Squeezenet: Alexnet-level accuracy with 50x fewer parameters and <1mb modelsize. arXiv:1602.07360 (2016)
- Han, S., Mao, H., Dally, W.J.: Deep compression: Compressing deep neural networkwith pruning, trained quantization and huffman coding. In: ICLR. (2016)
- Han, S., Pool, J., Narang, S., Mao, H., Tang, S., Elsen, E., Catanzaro, B., Tran,J., Dally, W.J.: DSD: regularizing deep neural networks with dense-sparse-densetraining flow. In: ICLR. (2017)
- Li, H., Kadav, A., Durdanovic, I., Samet, H., Graf, H.P.: Pruning filters for efficientconvnets. In: ICLR. (2017)
- Sturgess, P., Alahari, K., Ladicky, L., Torr, P.H.: Combining appearance andstructure from motion features for road scene understanding. In: BMVC. (2009)
- Lin, T., Maire, M., Belongie, S.J., Hays, J., Perona, P., Ramanan, D., Doll´ ar, P.,Zitnick, C.L.: Microsoft coco: Common objects in context. In: ECCV. (2014)