Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
研究摘要
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text. To address these differences, we propose a hierarchical Transformer whose representation is computed with Shifted windows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO testdev) and semanticsegmentation (53.5 mIoU on ADE20Kval). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and +2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones. The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures.
为了使Transformer模型能适应自然语言处理领取与计算机视觉领取之间的差异,论文提出了一种新的计算机视觉的通用骨干,称为Swin Transformer,为了解决这些差异,作者提出了一种借助Shifted windows进行计算的分层级的Transformer模型。窗口移动方案通过限制自注意计算,提高了计算效率移窗方案通过将自注意计算限定在非重叠的局部窗口,同时允许跨窗口连接,从而提高了效率。这种层次结构具有在不同尺度上建模的灵活性,并且具有与图像大小相关的线性计算复杂性。
源码地址
Code is available at https://github.com/microsoft/Swin-Transformer.
论文解读
The code shown below is is not identical to the author’s source code.
Introduction
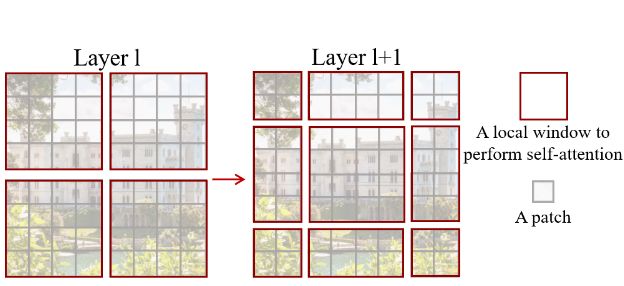
与自然语言处理领域相比,计算机视觉领域需要克服的差异主要包括尺度scale问题和高分辨率问题,为了作者提出了一个分层级的新模型,称为Swin Transformer。Swin Transformer通过从较小的patch开始,逐步合并较深的相邻patch来构造分层表示变压器层。在Swin Transformer中,自注意力机制只在非重叠窗口内进行局部计算,而划分的图像的每个窗口中的补丁数量又是固定的,因此计算复杂度与图像大小成线性关系。

Swin Transformer的一个关键设计元素是Shifted window,在连续的自注意层之间,它的窗口分区会进行移动,移动的窗口桥接了前一层的窗口,跨越上一层先前窗口的边界,提供了它们之间的连接,从而产生新的窗口,显著增强了建模能力。
Overall Architecture
Swin Transformer的整体架构如下图所示。

在Swin Transformer中,首先利用输入的图像生成token序列,并利用线性嵌入层将其投影到任意维度C,再利用Swin Transformer Block对其进行特征变换。随着网络层次的深入,token序列的数量会在patch merging layer层被减少,并相应扩增输出维度,再应用Swin Transformer Block进行特征变换。
class PatchMerging(nn.Module):
"""
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x
Swin Transformer Block与普通ViT的Block基本相同,但其中的标注多头注意力MSA被替换成了基于Shifted window的模块。
class WindowAttention(nn.Module):
"""
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
Self-attention in non-overlapped windows
在标准的ViT中,自注意力机制需要计算一个token和其他所有token之间的关系,而在非重叠窗口的自注意力机制中,只需要在图像分割的局部窗口内计算自注意力机制,对于一张包含h×w个patch的图像,二者的计算复杂度为

其中是hw的二次方,而后者当M固定时是线性的。
# computation of MSA: 4×hw×C^2 + 2×(hw)^2×C
# (hw×C) @ (C×C) -> hw(C^2)
q, k, v = nn.Linear(dim, dim, bias=qkv_bias)(x)
# (hw×C) @ (C×hw) -> ((hw)^2)C
attn = ((q @ k.transpose(-2, -1)) * self.scale).softmax(dim=-1)
# (hw×hw) @ (hw×C) -> ((hw)^2)C
x = (attn @ v).transpose(1, 2)
# (hw×C) @ (C×C) -> hw(C^2)
output = Concat(head1, ..., headh) @ WO
# computation of W-MSA: 4hw(C^2) + 2(M^2)hwC
# 4×hw×C^2 + 2×(hw)^2×C
# h = M, w = M -> 4(MC)^2 + 2(M^4)C
window_output = MultiHeadAttention(x)
# window_num = (h/M)×(w/M) -> (h/M)×(w/M)×(4(MC)^2 + 2(M^4)C) = 4hw(C^2) + 2(M^2)hwC
Shifted window partitioning
为了弥补非重叠窗口策略提升计算效率的同时带来的不同窗口之间的信息传递的隔绝,作者有提出了一个基于Shifted window的划分策略。假设每个窗口的尺寸为M,则在下一个模块时,将窗口移位M/2, M/2个像素,移位之后产生了新的配置,跨越先前窗口的边界,实现了不同窗口之间的信息传递,具体变换规则如下。

其中W-MSA和SW-MSA是基于移动窗口划分配配置的MSA模块,它们是成对使用的。
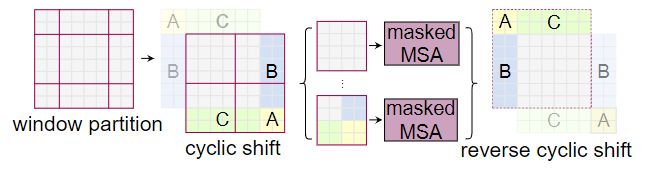
Efficient batch computation for shifted configuration
移动窗口分区的一个问题是,它将导致窗口数从(h/M)×(w/M)增加到(h/M+1)×(w/M+1),且一种一些窗口小于M×M。对此作者以提出了一种通过循环向左上方向进行移动的进行弥补,使窗口能由不相邻的子窗口组成,从而使窗口分区数量保持一致。
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C) # (B * W_num , window_size, window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # (B, H', W', C)
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
为了防止非临近区域合并进行自注意力机制计算引起的信息紊乱,作者设计了masked MSA,通过设置蒙板来隔绝不同区域之间的信息。
if self.shift_size > 0:
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # (nW, window_size, window_size, 1)
mask_windows = mask_windows.view(-1, self.window_size * self.window_size) # (nW, window_size * window_size)
# (nW, 1, window_size * window_size) - # (nW, window_size * window_size, 1)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2) # # (nW, window_size * window_size, window_size * window_size)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
Relative position bias
Swin Transformer在计算Self-attention时,同样包含一个相对位置偏执B。
![]()
class RelativePositionBias(nn.Module):
def __init__(self, window_size, num_heads):
super().__init__()
self.window_size = window_size
self.num_relative_distance = (2 * window_size[0] - 1) * (2 * window_size[1] - 1)
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros(self.num_relative_distance, num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(window_size[0])
coords_w = torch.arange(window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += window_size[1] - 1
relative_coords[:, :, 0] *= 2 * window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
# trunc_normal_(self.relative_position_bias_table, std=.02)
def forward(self):
relative_position_bias = \
self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1],
self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
return relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
# attn = q @ k.transpose(-2, -1)
attn = attn + relative_position_bias.unsqueeze(0)