数据可视化(matplotlib库)知识点归纳总结及练习题
数据可视化
Pytghon有两种数据作图方案:
1.matplotlib:简单方便,适合数值作图与科学作图(论文发表)
2.pyecharts:流程略微复杂但功能强大,为交互式图形,适合项目开发和商业分析报告。
本章内容讲matplotlib作图。
pyecharts会在下一章中详细讲解
定义及用到的库
• 数据以图形图像形式表示
• 揭示隐藏的数据特征,直观传达关揵信息
• 辅助建立数据分析模型,展示分析结果
Matplotlib库:
• 专门用于开发二维(包括三维)图表的工具包
• 实现图像元素精细化控制,绘制专业的分析图表
Pandas封装了Matplotlib的主要绘图功能:
•Series和DataFrame提供绘图函数
• 简便快捷地创建标准化图表
使用时要先导入如下库:
import matplotlib.pyplot as plt
import pandas as pd
from pandas import DataFrame
重点函数参数总结归纳
obj.plot()函数内的参数:
相关不理解的参数都可在后续已运行成功的代码例子中得到充分理解,可根据后续代码自行运行查看即可,代码也会进行标注解释
x&y------看散点图处的代码
x------x轴数据,默认值为None
y------y轴数据,默认值为None
kind------绘图类型,‘line’:折线图,默认值;‘bar’:垂直柱状图;‘barh’:水平柱状图;‘hist’:直方图;箱形图;‘kde’:Kernel核密度估计图;'density’与kde相同;‘pie’:饼图;‘scatter’:散点图
注意:该参数在obj.plot或plt.plot()的函数体内均存在。
title------图形标题,字符串
color------画笔颜色。用颜色缩写,如’r’、‘b’,或者RGB值,如’#CECECE’。主要颜色缩写:‘b’:blue、‘c’:cyan、‘g’:green、‘k’:black、‘m’:magenta、‘r’:red、‘w’:white、‘y’:yellow
figsize=(6,6)------设置画布尺寸大小此处以66为例 grid–图形是否有网格,默认值为None
fontsize------坐标轴(包括x轴和y轴)刻度的字体大小。整数,默认值为None alpha–图表的透明度,值为0~1,值越大颜色越深
use_index------默认为True,用索引作为x轴刻度 linewidth–绘图线宽
linestyle------绘图线型。‘‐’:实线;‘‐‐’:破折线;‘‐.’:点画线;‘: ‘:虚线
marker------标记风格。’.’:点;‘,’:像素(极小点);‘o’:实心圈;‘v’:倒三角;‘^’:上三角;‘>’:右三角;‘<’:左三角;‘1’:下花三角;‘2’:上花三角;‘3’:左花三角;‘4’:右花三角;‘s’:实心方形;‘p’:实心五角;'‘:星形;‘h’/‘H’:竖/横六边形;’|‘:垂直线;’+':十字; ‘x’:x;‘D’:菱形;‘d’:瘦菱形
label------图解释标签
xlim和ylim------x轴、y轴的范围,二元组表示最小值和最大值
ax------ax axes对象
rot------设置x轴刻度倾斜度数
legend= False------去除图自带的label标签
subplots------是否单独显示每个columns,默认为False。设置为True时,会将每个columns的数据单独在一个子图中显示
layout------当“subplots”为True时,用于布置图片显示布局,图片按几行、几列显示,参数为元组。
sharex------仅作用于"subplots"为True时,是否允许所有的子图共用同一个X轴标签。当“ax”为None时,“sharex”默认为True;当“ax”不为None,“sharex”默认为False,此时每一个子图有自己单独的X轴标签。
sharey------当“ax”不为None或"subplots"为True是,是否允许共用一个Y轴标签,默认为False。
plt.xxx类型函数
注意:plt.plot()函数体内有label参数标签,无plt.label()函数
plt.title------设置图标题
plt.xlabel和plt.ylabel------设置x、y轴标题
plt.xlim和plt.ylim------设置x、y轴刻度范围
plt.xticks和plt.yticks------设置x、y轴刻度值
plt.legend------添加图例说明
plt.grid------显示网格线
#以下两个函数可看多子图绘制处的注释
plt.text------添加注解文字
plt.annotate------添加注释
plt.subplots_adjust(wspace,hspace)------设置子图之间的横向和纵向间距
#x、y轴刻度旋转一定的度数,此处以90°为例 plt.xticks(rotation=90)------等同于obj.plot()函数体的参数rot=90
plt.yticks(rotation=90)
Pandas快速绘图
基本步骤:
• 导入matplotlib、Pandas (导入Matplotlib用于图形显示)
• 准备数据
使用Series或DataFrame封装数据
• 绘图
调用Series.plot()或DataFrame.plot()函数完成绘图
利用DataFrame绘图
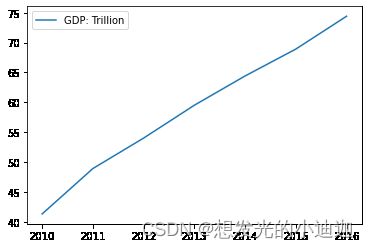
只有一组数据
import matplotlib.pyplot as plt
from pandas import DataFrame
gdp= [41.3,48.9,54.0,59.5,64.4,68.9,74.4]
data = DataFrame({'GDP: Trillion':gdp}, index=['2010','2011','2012','2013','2014','2015','2016'])
#obj.plot()函数内的参数详见ppt第四五页
data.plot()
运行结果显示:
有多组数据
import matplotlib.pyplot as plt
from pandas import DataFrame
#注意:当有多组不同的数据时
data=DataFrame([[19,68,170],[20,65,165],[21,67,167]],index=[1,2,3],columns=['age','weight','height'])
data.plot()
运行结果显示: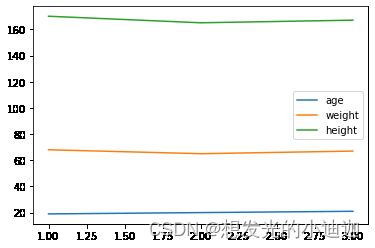
利用Series绘图
方式1:
import matplotlib.pyplot as plt
from pandas import Series
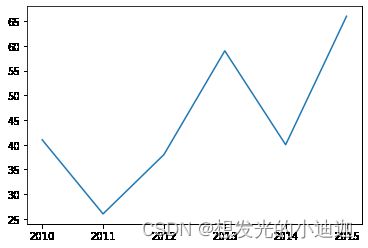
data1=Series([41,26,38,59,40,66],index= ['2010','2011','2012','2013','2014','2015'])
#obj.plot()函数体内参数详见重点函数参数总结归纳
data1.plot()
运行结果显示:
方式2:
import matplotlib.pyplot as plt
from pandas import Series
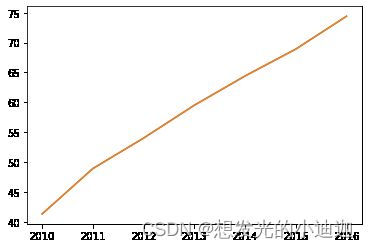
gdp0= [41.3,48.9,54.0,59.5,64.4,68.9,74.4]
data2 = Series(gdp0, index=['2010','2011','2012','2013','2014','2015','2016'])
#obj.plot()函数内的参数详见ppt第四五页,注意label参数ppt上没有
data2.plot()#等同于plt.plot(data2)
运行结果显示:
方式3:
import matplotlib.pyplot as plt
from pandas import Series
plt.figure()
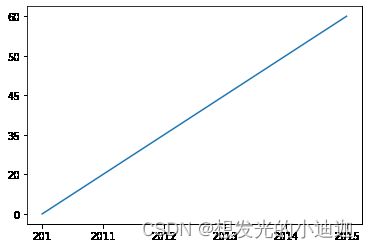
datax=['2010','2011','2012','2013','2014','2015']
datay=['0','20','35','45','50','60']
plt.plot(datax,datay)#x=datax即x轴数据y=datay即y轴数据;x轴数据与y轴数据一一对应
运行结果显示:
方式4:
import matplotlib.pyplot as plt
from pandas import Series
plt.figure()
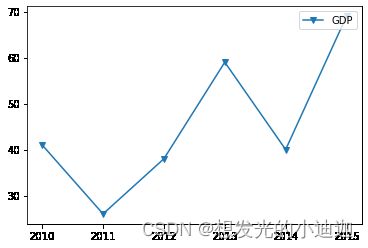
data01= [41,26,38,59,40,69]
datax1=['2010','2011','2012','2013','2014','2015']
#obj.plot()函数内的参数详见ppt第四五页,注意label参数ppt上没有,此处会直接给出解释
plt.plot(datax1,data01,marker='v',label='GDP')#datax1为x轴数据,data01为显示图像数据
#在图内加上折线的注释,必须在label='GDP'之后加上plt.legend(loc='upper right')才能显现出来,否则不不会显示出来
plt.legend(loc='upper right')
运行结果显示:
matplotlib精细绘图
以例子为基础进行理解
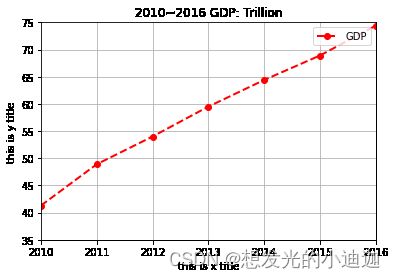
import matplotlib.pyplot as plt
#plt.figure()函数内存在参数figsize(m,n)用来定义图像的大小
plt.figure()#创建绘图对象(matplotlib的图像均位于figure对象内)
GDPdata= [41.3, 48.9, 54.0, 59.5, 64.4, 68.9, 74.4]#准备绘图的序列数据
plt.plot(GDPdata,color="red",linewidth=2,linestyle='--',marker='o',label='GDP')#绘图
#精细设置图元(给图加上标题)
plt.title('2010~2016 GDP: Trillion')#精细设置图元(即给折线图加上一个标题,注意:不能出现中文)
#给x、y轴绘图定义范围
plt.xlim(0,6)#x轴绘图范围定义为0~6
plt.ylim(35,75)#y轴绘图范围定义为35~75
#设置x、y轴刻度值
plt.xticks(range(0,7),('2010','2011','2012','2013','2014','2015','2016'))#将x轴刻度映射为字符串(即:将0~6改为2010~2016)
plt.yticks()
#给x、y轴设置标题,注意:不可出现中文
plt.xlabel('this is x title')
plt.ylabel('this is y title')
#在右上角显示图例说明(注意:必须和plt.plot()函数内的参数label一起用,否则无效)
plt.legend(loc='upper right')
#plt.text()#添加注解文字
#plt.annotate()#添加注释
plt.grid()#显示网格线
plt.show()#显示开关闭绘图(注意:做终端或脚本时必须用plt.show()显示图形,用ipython一类的编译器可以不用plt.show(),其会自动显现图形)
运行结果显示:
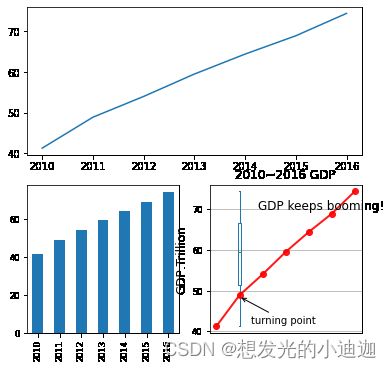
多子图绘制
以例子为基础进行理解
创建子图1用了ax1.plot(data)而不是plt.plot(data)或data.plot()的原因:详见代码创建子图1中的注释解释。
import matplotlib.pyplot as plt
from pandas import Series
fig= plt.figure( figsize= (6,6))#figsize定义图形画布大小,子图均在该画布内
data= Series( [41.3,48.9,54.0,59.5,64.4,68.9,74.4], index=['2010','2011','2012','2013','2014','2015','2016'])
#创建子图1--折线图
ax1= fig.add_subplot(2,1,1)#创建子图1
ax1.plot(data)#等同于plt.plot(data)或者data.plot()
#注意:当用ax1.plot(data)或者plt.plot(data)时,括号内不能写其他参数若加参数只能用plt.label()以plt开头的函数加,不能在
#ax1.plot(data)或者plt.plot(data)的体内加------
#创建子图2--柱状图
ax2= fig.add_subplot(2,2,3)
#use_index= True用索引作为x轴刻度,默认为True
data.plot(kind='bar',use_index= True,fontsize='small',ax=ax2)#用pandas柱状图绘图
#创建子图3--箱形图
ax3= fig.add_subplot(2,2,4)
data.plot(kind='box',fontsize='small',xticks=[],ax=ax3)#用pandas绘制箱形图
#为图增加注解、坐标轴标题
#obj.plot()函数体内参数详见pptd第四五页
data.plot(title='2010~2016 GDP',linewidth=2,marker='o',linestyle='-',color='r',grid=True,alpha=0.9)
#注解标注点
#xytext=(1.5,42)---调整标注点文字的位置
#xy=(1,48.5)---调整箭头符号的位置
plt.annotate('turning point',xytext=(1.5,42),arrowprops=dict(arrowstyle='->'),xy=(1,48.5))
#添加注解文字
plt.text(1.8, 70, 'GDP keeps booming!', fontsize=12)
plt.ylabel('GDP:Trillion', fontsize=12)
运行结果显示:
保存图表到文件
方式1:
figure.savefig(filename,dpi,bbox_inches)
方式2:
plt.savefig(filename,dpi,bbox_inches)
filename------文件路径及文件名,文件类型可以是jpg、png、pdf、svg、ps等
dpi------图片分辨率,每英寸点数,默认100
bbox_inches------图表需要保存的部分,设置为tight可以剪除当前图表周围的空白部分
#保存文件的代码需要写在plt.show()之前
fig.savefig('E:\2010-2012GDP.jpg',dpi=400,bbox_inches='tight')
思考与练习1
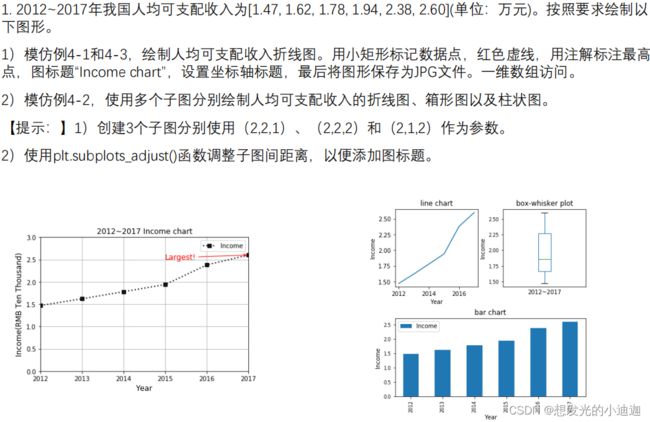
第一题第一问:
方式1:
import matplotlib.pyplot as plt
plt.figure()#创建绘图对象
salary= [1.47, 1.62, 1.78, 1.94, 2.38, 2.60]
plt.plot(salary,color='black',linestyle=':',marker='s',label='Income')
plt.legend(loc='upper right')
#对x轴进行年份范围设置
plt.xlim(0,5)
plt.xticks(range(0,6),['2012','2013','2014','2015','2016','2017'])
#对y轴进行范围设置
plt.ylim(0.0,3.0)
plt.annotate('Largest!',xy=(5,2.60),xytext=(3.0,2.58),arrowprops=dict(arrowstyle='->',color='r'),color='r')
plt.xlabel('Year')
plt.ylabel('Income(RMB Ten Thousand)')
plt.title('2012~2017 Incomechart')
plt.grid()
#保存为JPG文件(注意:保存为文件时,函数必须在plt.show()函数之前)
plt.savefig('E:\2012~2017Incomechart.jpg',dpi=500,bbox_inches='tight')
plt.show()
方式2:
import matplotlib.pyplot as plt
from pandas import Series
salary= Series([1.47, 1.62, 1.78, 1.94, 2.38, 2.60], index=['2012', '2013', '2014', '2015', '2016', '2017'])
salary.plot(kind= 'line', linestyle=':', marker= 's', color= 'black', xlabel='Year', ylabel= 'Income(RMB)', label= 'Income', title= '2012~2017 Income chart', xlim= (0,5), ylim= (0.0, 3.0), grid= True)
plt.legend(loc='upper right')
plt.annotate('Largest!', xytext= (3.5,2.50), arrowprops= dict(arrowstyle= '->', color= 'r'), xy= (5,2.60), color= 'r')
plt.savefig('E:\2012~2017Incomechart.jpg',dpi=500,bbox_inches='tight')
第一题第二问:
import matplotlib.pyplot as plt
from pandas import Series
fig= plt.figure(figsize=(6,6))
data= Series([1.47, 1.62, 1.78, 1.94, 2.38, 2.60],index=['2012','2013','2014','2015','2016','2017'])
#创建子图1--折线图
ax1= fig.add_subplot(2,2,1)
ax1.plot(data)
plt.yticks([1.50,1.75,2.00,2.25,2.50])
plt.xticks(['2012','2014','2016'])
plt.ylabel('Income')
plt.title('line chart')
#创建子图2--箱形图
ax2=fig.add_subplot(2,2,2)
#注意:xlabel作为参数卸写在obj.plot()函数体内是不会呈现在图中的
#参数xticks=[]是为了让箱形图x轴下方为空白(什么也没有),后期可利用plt.xlabel()对x轴下方添加x轴标题
data.plot(kind='box',title='bos-whisker plot',fontsize='small',xticks=[])
#此处用data.plot()而不用plt.plot()或者ax1.plot()的原因请看多子图绘制中的注释
plt.yticks([1.50,1.75,2.00,2.25,2.50])
plt.xlabel('2012~2017')
plt.ylabel('Income')
#创建子图3--柱状图
ax3=fig.add_subplot(2,1,2)
data.plot(kind='bar',use_index=True,label='Income',title='bar chart')
plt.legend(loc='upper left')
#设置x轴刻度的旋转度数,默认为90°
plt.xticks(rotation = 90)
plt.xlabel('Year')
plt.ylabel('Income')
#添加图形标题也可以是plt.title()函数
#plt.title('bar chart')
#设置各个子图之间的间距
plt.subplots_adjust(wspace=0.3,hspace=0.3)
#保存为.jpg文件(注意:保存为文件时,函数必须在plt.show()函数之前)
plt.savefig('E:\Incomechart.jpg',dpi=500,bbox_inches='tight')
plt.show()
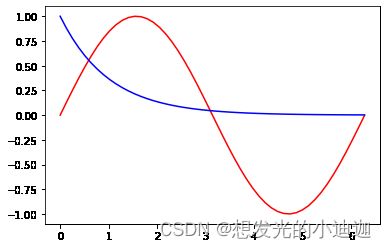
认识基本图形
函数绘图
需引入numpy库
绘制y=sin(x)和y=e(-x)的函数图 e的-x次幂
import matplotlib.pyplot as plt
import numpy as np
"""
np.linspace(start,end,num,endpoint,dtype)
从x=0开始到6.28结束一共赋予x50个数字,
这50个数字取值范围为0~6.28
num缺省为50
endpoint:决定终止值(stop参数指定)是否被包含在结果数组中,缺省为True
dtype暂时不用管,基本用不到
"""
x=np.linspace(0,6.28,50)#x从0到6.28取值50个数
y=np.sin(x)#计算y=sin(x)数组
plt.plot(x,y,color='r')#红色绘制y=sin(x)图
plt.plot(x,np.exp(-x),c='b')#蓝色绘制y=exp(-x)
运行结果显示:
散点图绘制
方法一:
DataFrame.plot(kind=’scatter’,x,y,title,grid,xlim,ylim,label,s…)
x------DataFrame中x轴对应的数据列名
y------DataFrame中y轴对应的数据列名
label------图例标签
s------设置点的大小,eg:s=8
注意:x、y对应的数据列必须均是数!
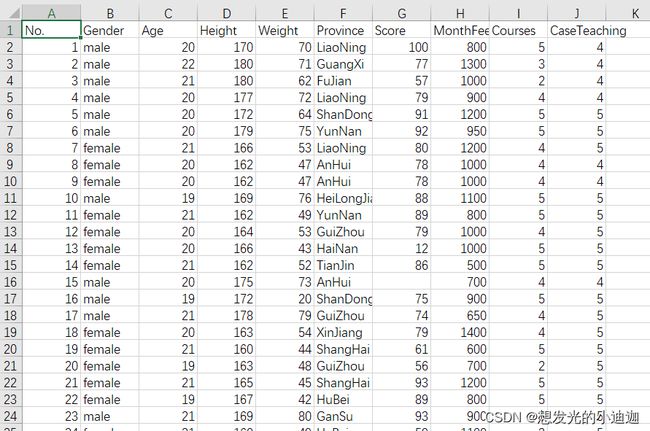
students.csv文件部分内容如下:
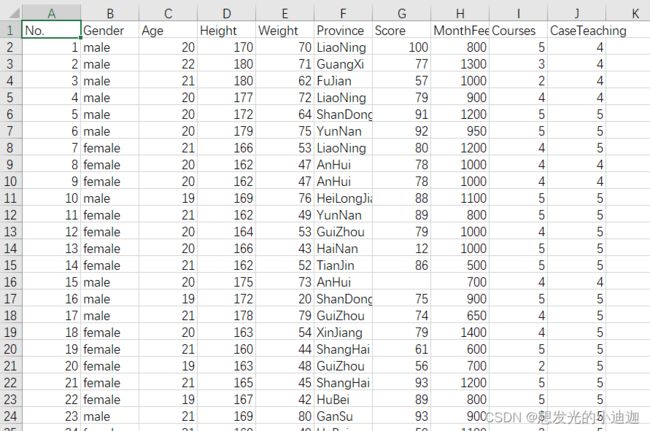
import matplotlib.pyplot as plt
import pandas as pd
stdata= pd.read_csv('E:\data\students.csv')
#Height、Weight都必须是数时才可以用x='Height', y= 'Weight'来引入作为x、y轴数据
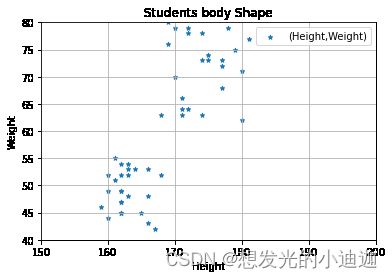
stdata.plot(kind='scatter',x='Height', y= 'Weight',title='Students body Shape', label='(Height,Weight)', marker='*', grid= True, xlim=[150,200],ylim=[40,80])
运行结果显示:
方法二
DataFrame.plot.scatter(x,y,title, grid,xlim,ylim,label,…)
注意:与方法一不同的是:将kind='scatter’这个内置参数提到外面变为函数DataFrame.plot.scatter
import matplotlib.pyplot as plt
import pandas as pd
stdata= pd.read_csv('E:\data\students.csv')
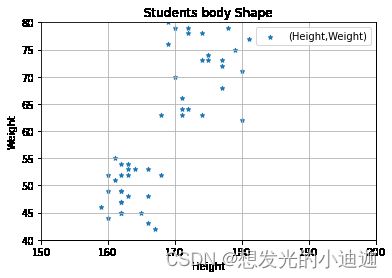
stdata.plot.scatter(x='Height', y= 'Weight',title='Students body Shape', marker='*',grid= True, xlim=[150,200],ylim=[40,80],label='(Height,Weight)')
运行结果显示:
分组散点图
作用:清晰显示数据聚集特性
注意:用plt.scatter(),若用DataFrame.scatter()或者DataFrame.plot.scatter()则男女生不会再同一个图中显示
通过例子详细理解:
例题:绘制散点图观察学生身高和体重之间的关系
students.csv文件部分内容如下:
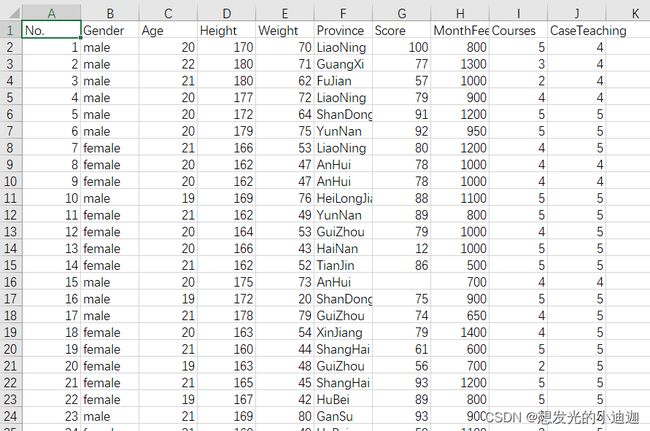
import matplotlib.pyplot as plt
import pandas as pd
stdata= pd.read_csv('E:\data\students.csv')
data1=stdata[stdata['Gender']=='male']
data2=stdata[stdata['Gender']=='female']
plt.figure()
plt.scatter(data1['Height'],data1['Weight'],c='r',marker='s',label='Male')
plt.scatter(data2['Height'],data2['Weight'],c='b',marker='^',label='Female')
#共同使用的一些信息就单独拿出来写,可以不作为plt.scatter()函数的参数
plt.ylim(40,80)
plt.title('Students Body Shape')
plt.xlabel('Weight')
plt.ylabel('Height')
plt.grid()
plt.legend(loc='upper right')
运行结果显示:
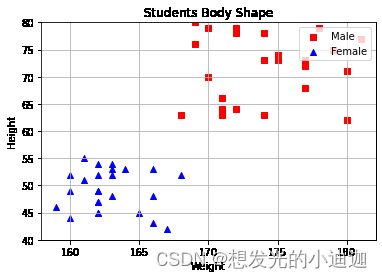
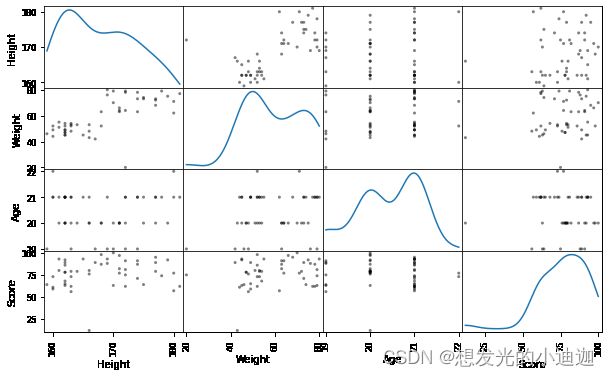
散点图矩阵
作用:同时观察多组数据之间的关系
pd.plotting.scatter_matrix(data,diagnoal,…)
data------包含多列数据的DataFrame对象
diagonal------对角线上的图形类型,有’kde’(曲线图),‘hist’(直方图)两种 通常放置该列数据的密度图或直方图
figsize=(浮点型,浮点型) ------设置图像大小
grid------显示网格
ax------Matplotlib轴对象,可选
marker------详见文章开头obj.plot()参数marker
students.csv文件部分内容如下:
import matplotlib.pyplot as plt
import pandas as pd
#导入.csv文件
stdata= pd.read_csv('E:\data\students.csv')
#准备数据
data=stdata[['Height','Weight','Age','Score']]
#绘图c即color
pd.plotting.scatter_matrix(data,diagonal='kde',c='k',figsize=(10.0,6.0))
运行结果显示:
柱状图
Series.plot(kind,xerr,yerr,stacked,…)
DataFrame.plot(kind,xerr,yerr,stacked,…)
kind------bar–垂直柱状图 barh–水平柱状图
xerr,yerr------x、y轴向误差线 需要用到标准差std定义误差线
stacked------是否为堆叠图,默认为False
rot------刻度标签旋转度数,值为0~360
注意:均值需引入numpy库。标准差–np.std()
垂直柱状图
kind=‘bar’
水平柱状图
kind= ‘barh’
通过例子理解:
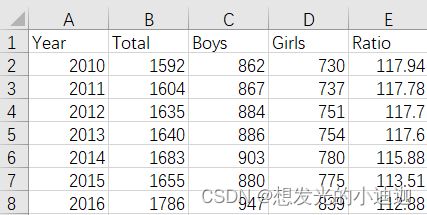
例题:从population.csv文件中读取人口数据,绘制各性别的出生人口比较图。
population.csv文件内容如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#读取.csv文件,index_col=0--选取csv文件中位置下标为0的那一列作为行索引
data=pd.read_csv('E:\data\Population.csv',index_col='Year')
#将data中索引为'Boys','Grils'的这两列赋给data1(注意:自动会将行索引带上一起赋给data1)
data1=data[['Boys','Girls']]
#axis=0一般最好不要省略
mean=np.mean(data1,axis=0)#按列分别计算男生和女生的均值
std=np.std(data1,axis=0)#计算标准差
#创建图
fig=plt.figure(figsize=(6,2))#设置图片的大小(即一块画布大小)
plt.subplots_adjust(wspace=0.6)#设置各个子图之间的间距
#绘制均值的垂直和水平柱状图,标准差使用误差线来表示
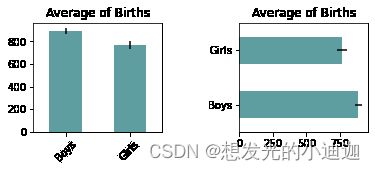
#子图1
ax1=fig.add_subplot(1,2,1)
mean.plot(kind='bar',yerr=std,color='cadetblue',title='Average of Births',rot=45)
#子图2
ax2=fig.add_subplot(1,2,2)
mean.plot(kind='barh',xerr=std,color='cadetblue',title='Average of Births')
#注意:两个子图均不用ax.plot()或者plt.plot()的原因请看多子图绘制的注释
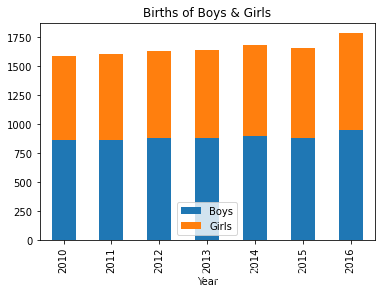
#绘制复式柱状图和堆叠柱状图
data1.plot(kind='bar',stacked=False,title='Births of Boys & Girls')
data1.plot(kind='bar',stacked=True,title='Births of Boys & Girls')
运行结果显示:
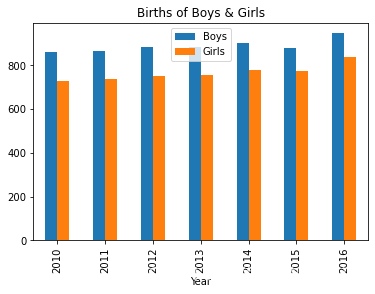
折线图
折线图–不需要kind='line’参数,默认即为折线图
用线条描述事物的发展变化及趋势:
(1)普通折线图:横纵坐标轴上都是用算术刻度
(2)半对数折线图:横纵坐标分别使用算术刻度与对数刻度
半对数折线图使用条件:
(1)比较的两种或多种事物的数据值域相差较大
(2)指标“相对增长量”的变化关系
注意:绘制半对数折线图需要在plot函数中设置参数logx或logy为True。即logx=True或logy=True
GDP.csv文件内容如下:
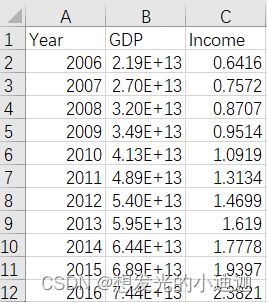
import pandas as pd
import matplotlib.pyplot as plt
data0= pd.read_csv('E:\data\GDP.csv',index_col='Year')
#绘制GDP和Income的折线图
#use_index=True--用索引作为x轴刻度
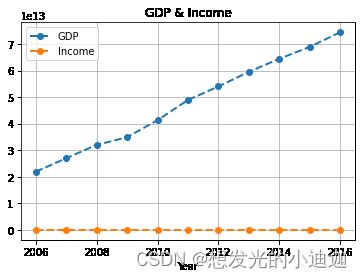
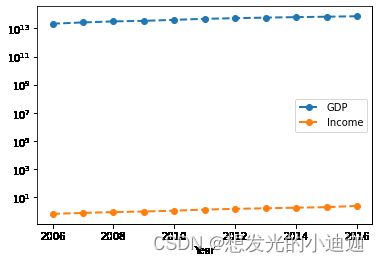
data0.plot(title='GDP & Income',linewidth=2,marker='o',linestyle='dashed',grid=True,use_index=True)
#绘制GDP和Income的对半数折线图
data0.plot(logy=True,linewidth=2,marker='o',linestyle='dashed')
运行结果显示为:
直方图
描述总体的频数分布情况
将横坐标按区间个数等分
每个区间上长方形的高度表示该区间样本的频率,面积表示频数
Series.plot(kind=’hist’,bins,normed,…)
bins------横坐标区间个数
normed------是否标准化直方图,默认值为False
注意:normed已经不能在使用,改为density即可
students.csv文件的部分内容如下:
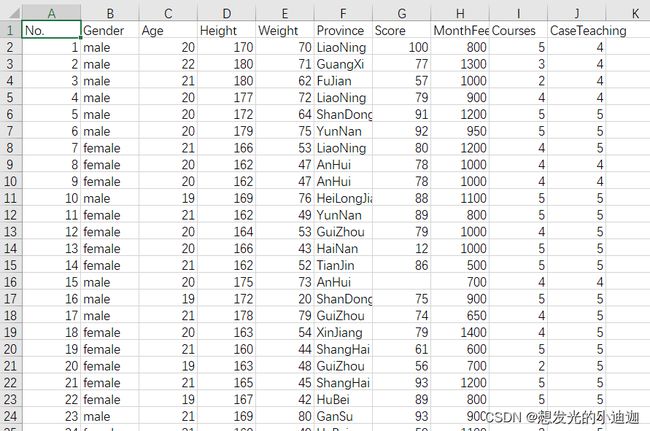
import pandas as pd
import matplotlib.pyplot as plt
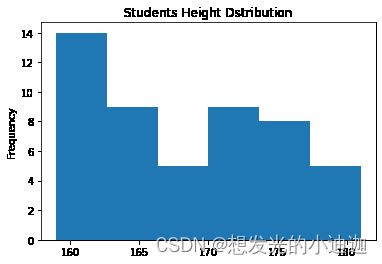
#绘制身高分布直方图
stada1=pd.read_csv('E:\data\students.csv')
stada1['Height'].plot(kind='hist',bins=6,title='Students Height Dstribution')
运行结果显示:
密度图:
作用:
(1)模拟真实的概率分布曲线
(2)与标准化的直方图一起绘制,对比
Series.plot(kind=’kde’,style,…)
style–风格字符串,包括颜色和线型,如’ko-',‘r-’
注意:style相当于linestyle和color的合并,用的时候可以不用style,用linestyle和color即可。
import pandas as pd
import matplotlib.pyplot as plt
#绘制身高分布标准化直方图和身高密度图
stada2=pd.read_csv('E:\data\students.csv')
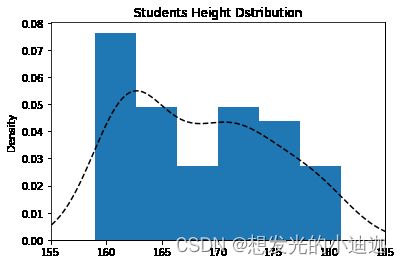
stada2['Height'].plot(kind='hist',bins=6,density=True,title='Students Height Dstribution')
stada2['Height'].plot(kind='kde',title='Students Height Dstribution', xlim=[155,185],style = 'k--')
运行结果显示:
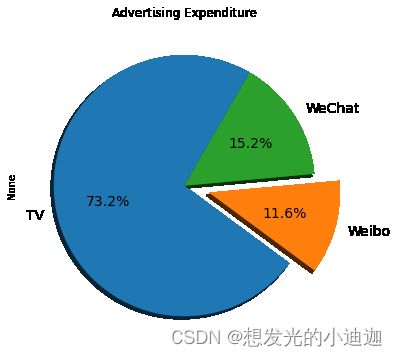
饼图(扇形图)
作用:描述总体的样本值构成比
Series.plot( kind=‘pie’, explode,shadow,startangle,autopct,…)
explode------列表,表示各扇形块离开中心的距离
shadow------扇形块是否有阴影,默认False
autopct------百分比格式,可用format字符串或者format function,'%1.1f%%'指小数点前后各1位(不足空格补齐)
startangle------起始绘制角度,默认图是从x轴正方向逆时针画起,如设定=90则从y轴正方向画起;
advertising.csv文件部分内容如下:
import pandas as pd
import matplotlib.pyplot as plt
#注意:引入.csv文件时,若文件内内容太多用\引入
data01 = pd.read_csv('E:\data/advertising.csv')
piedata=data01[['TV','Weibo','WeChat']]
datasum=piedata.sum()#对每一列进行求和计算,默认为axis=0--按列
datasum.plot(kind='pie',figsize=(6,6),title='Advertising Expenditure',fontsize=14, explode=[0,0.2,0],shadow=True,startangle=60, autopct='%1.1f%%')
运行结果显示:
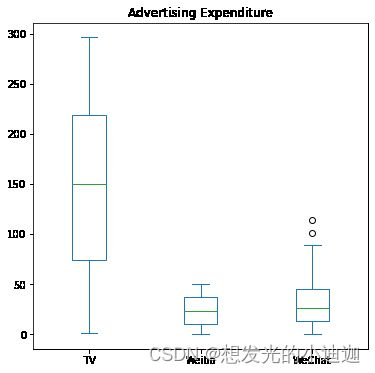
箱形图
方式一
Series.plot(kind=‘box’, …)
import pandas as pd
import matplotlib.pyplot as plt
data02=pd.read_csv('E:\data/advertising.csv')
advdata=data02[['TV','Weibo','WeChat']]
#绘制各类经费投入的箱形图
advdata.plot(kind='box',figsize=(6,6),title='Advertising Expenditure')
运行结果显示:
方式二
DataFrame.boxplot( by, …)
by------用于分组的列名
DataFrame对象要包括绘制列和分组列(用于分组的列名)详见例子
import pandas as pd
import matplotlib.pyplot as plt
data03=pd.read_csv('E:\data\students.csv')
#Gender为分组列,Score为绘制列
asd= data03[['Gender','Score']]
#by='Gender'---将所有数据根据男女进行划分并呈现出来
"""
若不加figsize=(6,6)来调整画布大小,则该箱形图最上方的文字会叠到一块
"""
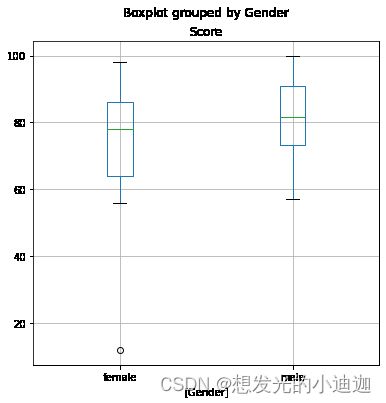
asd.boxplot(by='Gender',figsize=(6,6))
运行结果显示:
思考与练习2
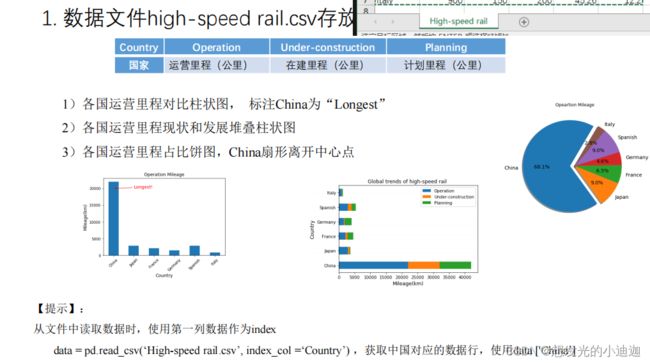
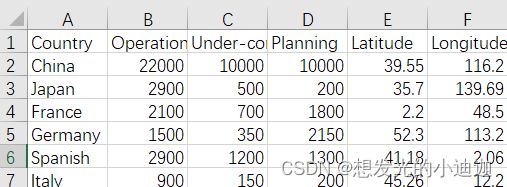
High-speed rail.csv文件内容如下:
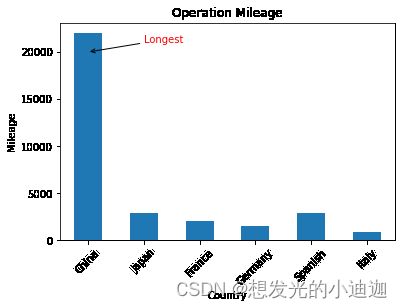
第一题第(1)(2)问
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
data0=pd.read_csv('E:\data\High-speed rail.csv',index_col=0)
data0['Operation'].plot(kind= 'bar', use_index= True, ylabel= 'Mileage', title= 'Operation Mileage', rot= 45)
plt.annotate('Longest', xytext= (1,21000), arrowprops= dict(arrowstyle='->'),xy= (0,20000), color= 'r')
data1= data0[['Operation', 'Under-construction', 'Planning']]
#'Mileage(km)'利用参数加不上,所以用了plt.xlabel()
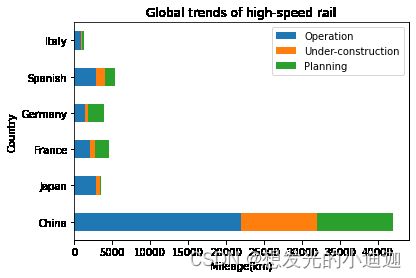
data1.plot(kind= 'barh', stacked= True, title= 'Global trends of high-speed rail')
plt.xlabel('Mileage(km)')
运行结果显示为:
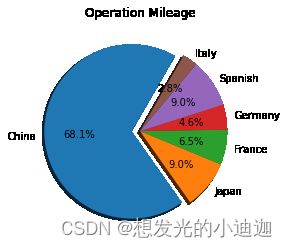
第一题第(3)问
#不与前两个图写在一块的原因:该饼图会与第二个图的图形重合致使第二个图显示不出来
#解决方案:
# 1.可以将前两个图写在一个区域,饼图单独再开一个代码行写(此处采用了第一种方案)
# 2.设置一块画布,将三个图均匀分布在画布中
piedata=data0['Operation']
piedata.plot(kind='pie',shadow=True,startangle=60,autopct='%1.1f%%',explode=[0.1,0,0,0,0,0],ylabel='',title='Operation Mileage')
运行结果显示为:
课后作业
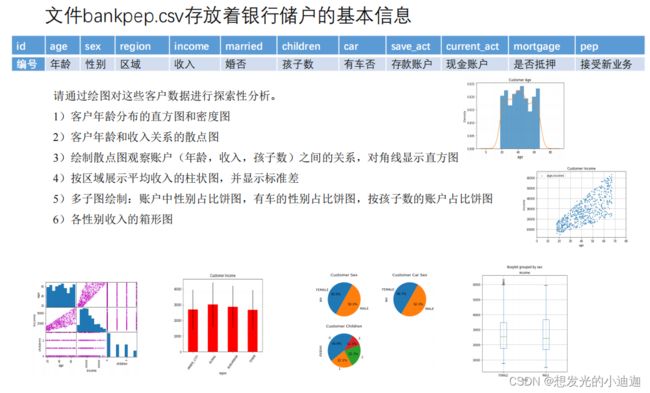
bankpep.csv文件部分内容如下:
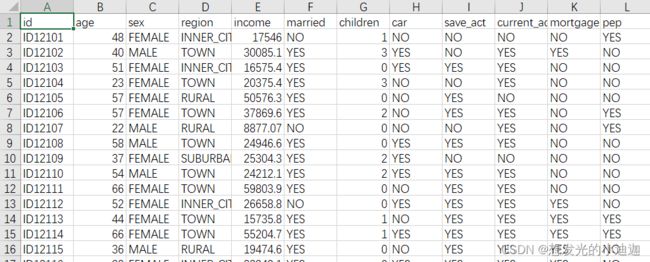
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
data= pd.read_csv('E:\data/bankpep.csv')
#(1)
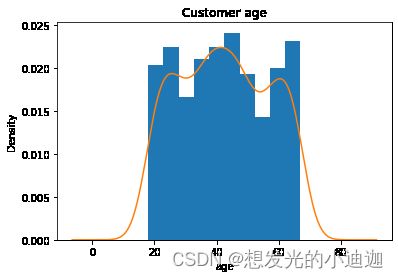
data['age'].plot(kind= 'hist', bins= 10, density= True)
data['age'].plot(kind= 'kde')
plt.title('Customer age')
plt.xlabel('age')
plt.ylabel('Density')
plt.show()
#(2)
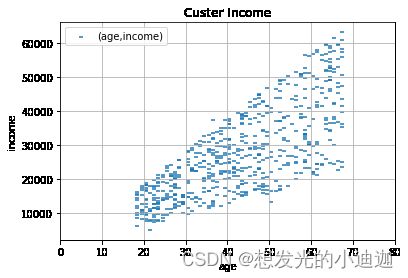
data.plot.scatter(x='age', y='income', marker= True, grid= True, xlim= [0,80],label= '(age,income)', title= 'Custer Income')
#(3)
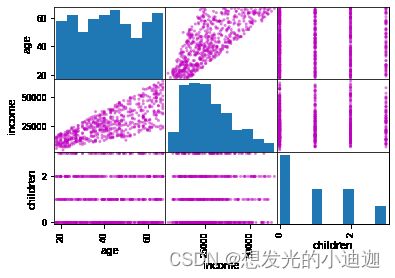
pd.plotting.scatter_matrix(data[['age', 'income', 'children']], diagonal= 'hist', color= 'm')
运行结果显示为:
#(4)
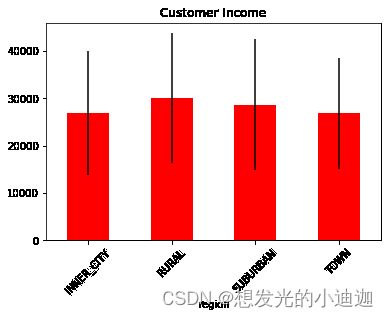
grouped= data.groupby('region')
mean= grouped.aggregate({'income': np.mean}, axis= 0)
std= grouped.aggregate({'income': np.std}, axis=0)
#legend= False------去除图自带的label标签
mean.plot(kind= 'bar', yerr= std, color= 'r', rot= 45, title= 'Customer Income', legend= False)
运行结果显示为:
#(5)
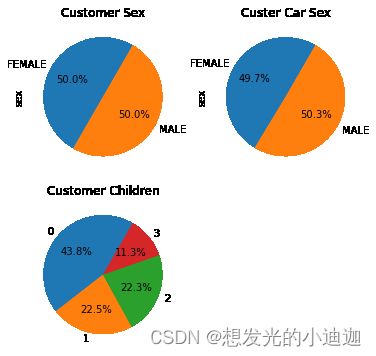
#子图1的数据
sex_grouped= data.groupby('sex')#将表根据sex性别进行分组
data1= sex_grouped['sex'].count()#统计不同性别的人数
#子图2的数据
data2= data[data['car']== 'YES']#将表根据有车进行分组
car_grouped= data2.groupby('sex')#统计有车的男女的个数
data3= car_grouped['sex'].count()
#子图3的数据
children_grouped= data.groupby('children')#将表根据孩子数量进行分组
data4= children_grouped['children'].count()#统计不同孩子个数的人数
#画布大小
fig= plt.figure(figsize= (6,6))
#创建子图1:
ax1= fig.add_subplot(2,2,1)
data1.plot(kind= 'pie',shadow= False, startangle= 60, autopct= '%1.1f%%', title= 'Customer Sex')
#创建子图2:
ax2= fig.add_subplot(2,2,2)
data3.plot(kind= 'pie', shadow= False, startangle= 60, autopct= '%1.1f%%', title= 'Custer Car Sex')
#创建子图3:
ax3= fig.add_subplot(2,2,3)
data4.plot(kind= 'pie', shadow= False, startangle= 60, autopct= '%1.1f%%', title= 'Customer Children', ylabel= '')
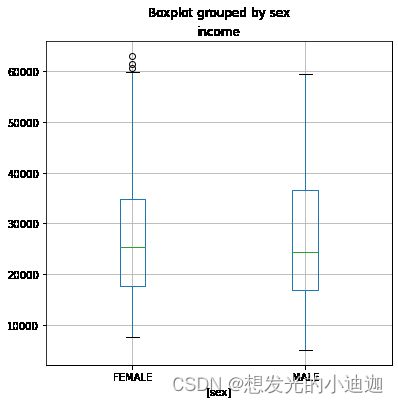
#(6)
#若无figsize=(6,6)则箱形图的两个标题则会叠到一块
data5= data[['sex', 'income']]
data5.boxplot(by= 'sex', figsize=(6,6))
运行结果显示为: