如何改进yolov3_一文看懂YOLO v3
我的CSDN博客:https://blog.csdn.net/litt1e
我的公众号:工科宅生活
论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf
论文:YOLOv3: An Incremental Improvement
YOLO系列的目标检测算法可以说是目标检测史上的宏篇巨作,接下来我们来详细介绍一下YOLO v3算法内容,v3的算法是在v1和v2的基础上形成的,所以有必要先回忆:一文看懂YOLO v2,一文看懂YOLO v2。
网络结构
从这儿盗了张图,这张图很好的总结了YOLOV3的结构,让我们对YOLO有更加直观的理解。
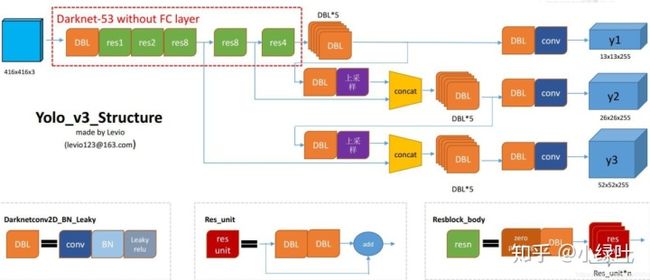
DBL:代码中的Darknetconv2d_BN_Leaky,是yolo_v3的基本组件。就是卷积+BN+Leaky relu。
resn:n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。不懂resnet请戳这儿
concat:张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
后面我们一起分析网络一些细节与难懂的地方
backbone:darknet-53
为了达到更好的分类效果,作者自己设计训练了darknet-53。作者在ImageNet上实验发现这个darknet-53,的确很强,相对于ResNet-152和ResNet-101,darknet-53不仅在分类精度上差不多,计算速度还比ResNet-152和ResNet-101强多了,网络层数也比他们少。
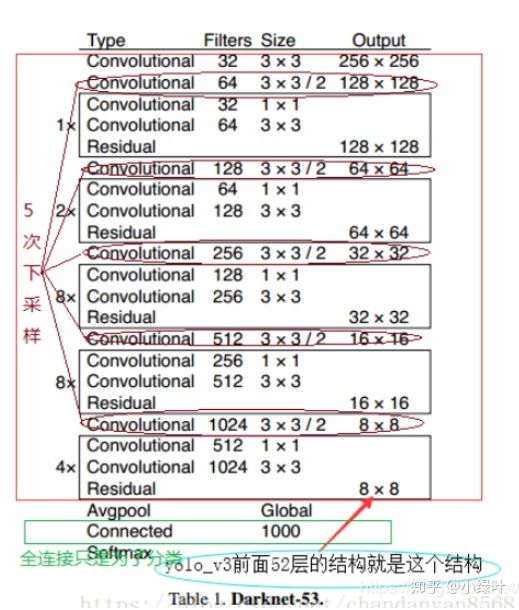
Yolo_v3使用了darknet-53的前面的52层(没有全连接层),yolo_v3这个网络是一个全卷积网络,大量使用残差的跳层连接,并且为了降低池化带来的梯度负面效果,作者直接摒弃了POOLing,用conv的stride来实现降采样。在这个网络结构中,使用的是步长为2的卷积来进行降采样。
为了加强算法对小目标检测的精确度,YOLO v3中采用类似FPN的upsample和融合做法(最后融合了3个scale,其他两个scale的大小分别是26×26和52×52),在多个scale的feature map上做检测。
作者在3条预测支路采用的也是全卷积的结构,其中最后一个卷积层的卷积核个数是255,是针对COCO数据集的80类:3*(80+4+1)=255,3表示一个grid cell包含3个bounding box,4表示框的4个坐标信息,1表示objectness score。
output
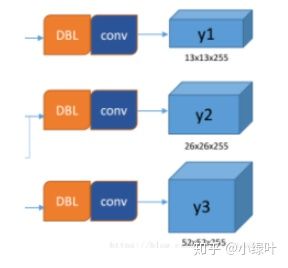
所谓的多尺度就是来自这3条预测之路,y1,y2和y3的深度都是255,边长的规律是13:26:52。yolo v3设定的是每个网格单元预测3个box,所以每个box需要有(x, y, w, h, confidence)五个基本参数,然后还要有80个类别的概率。所以3×(5 + 80) = 255。这个255就是这么来的。
下面我们具体看看y1,y2,y3是如何而来的。
网络中作者进行了三次检测,分别是在32倍降采样,16倍降采样,8倍降采样时进行检测,这样在多尺度的feature map上检测跟SSD有点像。在网络中使用up-sample(上采样)的原因:网络越深的特征表达效果越好,比如在进行16倍降采样检测,如果直接使用第四次下采样的特征来检测,这样就使用了浅层特征,这样效果一般并不好。如果想使用32倍降采样后的特征,但深层特征的大小太小,因此yolo_v3使用了步长为2的up-sample(上采样),把32倍降采样得到的feature map的大小提升一倍,也就成了16倍降采样后的维度。同理8倍采样也是对16倍降采样的特征进行步长为2的上采样,这样就可以使用深层特征进行detection。
作者通过上采样将深层特征提取,其维度是与将要融合的特征层维度相同的(channel不同)。如下图所示,85层将13×13×256的特征上采样得到26×26×256,再将其与61层的特征拼接起来得到26×26×768。为了得到channel255,还需要进行一系列的3×3,1×1卷积操作,这样既可以提高非线性程度增加泛化性能提高网络精度,又能减少参数提高实时性。52×52×255的特征也是类似的过程。

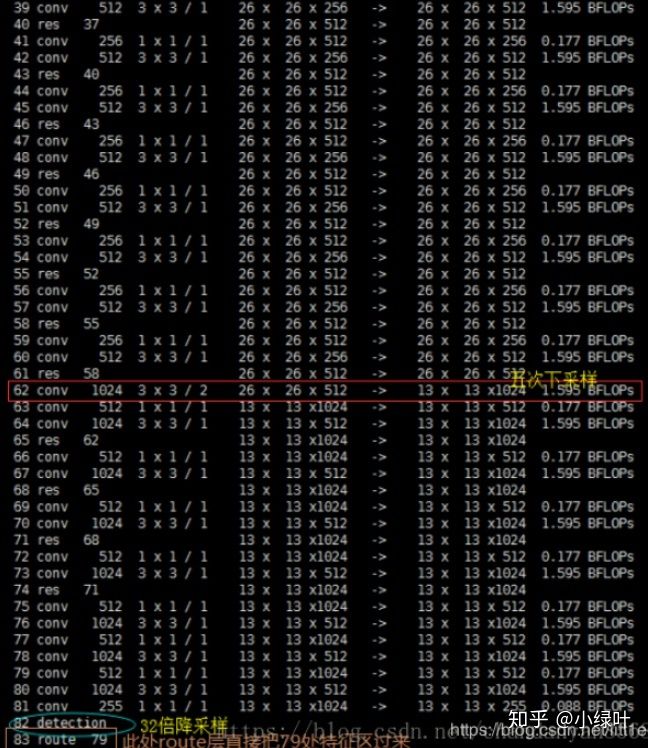
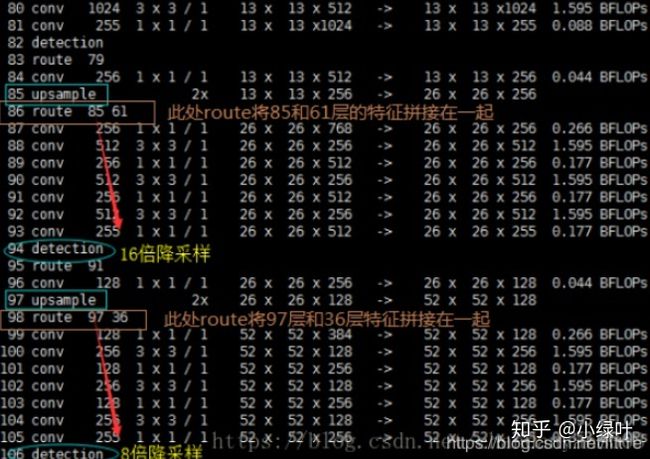
从图中,我们可以看出y1,y2,y3的由来。
Bounding Box
YOLO v3的Bounding Box由YOLOV2又做出了更好的改进。在yolo_v2和yolo_v3中,都采用了对图像中的object采用k-means聚类。 feature map中的每一个cell都会预测3个边界框(bounding box) ,每个bounding box都会预测三个东西:(1)每个框的位置(4个值,中心坐标tx和ty,,框的高度bh和宽度bw),(2)一个objectness prediction ,(3)N个类别,coco数据集80类,voc20类。
三次检测,每次对应的感受野不同,32倍降采样的感受野最大,适合检测大的目标,所以在输入为416×416时,每个cell的三个anchor box为(116 ,90); (156 ,198); (373 ,326)。16倍适合一般大小的物体,anchor box为(30,61); (62,45); (59,119)。8倍的感受野最小,适合检测小目标,因此anchor box为(10,13); (16,30); (33,23)。所以当输入为416×416时,实际总共有(52×52+26×26+13×13)×3=10647个proposal box。

感受一下9种先验框的尺寸,下图中蓝色框为聚类得到的先验框。黄色框式ground truth,红框是对象中心点所在的网格。

这里注意bounding box 与anchor box的区别:
Bounding box它输出的是框的位置(中心坐标与宽高),confidence以及N个类别。
anchor box只是一个尺度即只有宽高。
LOSS Function
YOLOv3重要改变之一:No more softmaxing the classes。
YOLO v3现在对图像中检测到的对象执行多标签分类。
早期YOLO,作者曾用softmax获取类别得分并用最大得分的标签来表示包含再边界框内的目标,在YOLOv3中,这种做法被修正。
softmax来分类依赖于这样一个前提,即分类是相互独立的,换句话说,如果一个目标属于一种类别,那么它就不能属于另一种。
但是,当我们的数据集中存在人或女人的标签时,上面所提到的前提就是去了意义。这就是作者为什么不用softmax,而用logistic regression来预测每个类别得分并使用一个阈值来对目标进行多标签预测。比阈值高的类别就是这个边界框真正的类别。
用简单一点的语言来说,其实就是对每种类别使用二分类的logistic回归,即你要么是这种类别要么就不是,然后便利所有类别,得到所有类别的得分,然后选取大于阈值的类别就好了。
logistic回归用于对anchor包围的部分进行一个目标性评分(objectness score),即这块位置是目标的可能性有多大。这一步是在predict之前进行的,可以去掉不必要anchor,可以减少计算量。
如果模板框不是最佳的即使它超过我们设定的阈值,我们还是不会对它进行predict。不同于faster R-CNN的是,yolo_v3只会对1个prior进行操作,也就是那个最佳prior。而logistic回归就是用来从9个anchor priors中找到objectness score(目标存在可能性得分)最高的那一个。logistic回归就是用曲线对prior相对于 objectness score映射关系的线性建模。
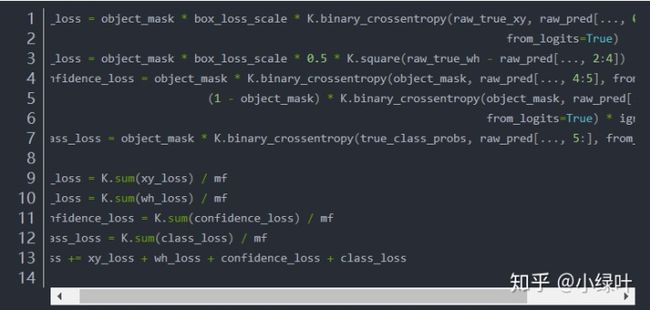
以上是一段keras框架描述的yolo v3 的loss_function代码。忽略恒定系数不看,可以从上述代码看出:除了w, h的损失函数依然采用总方误差之外,其他部分的损失函数用的是二值交叉熵。最后加到一起。那么这个binary_crossentropy又是个什么玩意儿呢?就是一个最简单的交叉熵而已,一般用于二分类,这里的两种二分类类别可以理解为"对和不对"这两种。
参考文章:
https://towardsdatascience.com/yolo-v3-object-detection-53fb7d3bfe6b
https://blog.csdn.net/yanzi6969/article/details/80505421
https://blog.csdn.net/chandanyan8568/article/details/81089083
https://blog.csdn.net/leviopku/article/details/82660381
https://blog.csdn.net/u014380165/article/details/80202337