pytorch搭建训练自己数据集的模型(预处理、读取自己的图片、进行训练和测试、保存模型、加载模型和测试)
文章目录
- 第一阶段:图片预处理
-
- 代码讲解
- 第二阶段:读取图片并保存为.txt
- 第三阶段:改写Dataset,保证下阶段读取自己的数据集
- 第四阶段:读取自己的数据集并训练和测试
- 第五阶段:模型加载并进行测试
第一阶段:图片预处理
'''
获取图像的路径
获取图像的高和宽
进行循环
判断图像是否存在
'''
import os
import os.path
# import cv2
from PIL import Image
zhongyao_list=['白勺','薄荷','车前草','垂盆草','当归','何首乌','红花','金芥麦','京大戟','决明子',
'牛蒡子','千金子','瞿麦','射干','夏枯草','香加皮','萱草','洋金花','鱼腥草','紫苏']
file_path=r'/home/hsy/PycharmProjects/数据集/5月下旬调整前/'
new_dir=r'/home/hsy/PycharmProjects/数据集/5月下旬/'
def update(china_name,name):
for i in range(1, 220):
try:
img = Image.open(file_path + china_name + '/' + name +'_' + str(i) + '.jpg')
old_width = img.size[0]
old_height = img.size[1]
rate = 512 / old_height
newImg = img.resize((int(old_width * rate), 512), Image.BILINEAR)
if int(old_width*rate)!=384:
newImg=newImg.crop([int((old_width-384)/2),0,int((old_width-384)/2+384),512])
print(i, china_name, newImg.size)
newImg.save(new_dir + china_name + '/' + name + '_' + str(i) + '.jpg')
except Exception as E:
break
#
#
if __name__ == '__main__':
for i in zhongyao_list:
print(i)
#如果文件夹不存在就创建文件夹
if not os.path.isdir(new_dir+i):
os.makedirs(new_dir+i)
if i=='白勺':
update('白勺','baisao')
if i=='薄荷':
update('薄荷','bohe')
if i=='车前草':
update('车前草','cheqiancao')
if i=='垂盆草':
update('垂盆草','chuipencao')
if i=='当归':
update('当归','danggui')
if i=='何首乌':
update('何首乌','heshouwu')
if i=='红花':
update('红花','honghua')
if i=='金芥麦':
update('金芥麦','jinjiemai')
if i=='京大戟':
update('京大戟','jingdaji')
if i=='决明子':
update('决明子','juemingzi')
if i=='牛蒡子':
update('牛蒡子','niubangzi')
if i=='千金子':
update('千金子','qianjinzi')
if i=='瞿麦':
update('瞿麦','qumai')
if i=='射干':
update('射干','shegan')
if i=='夏枯草':
update('夏枯草','xiakucao')
if i=='香加皮':
update('香加皮','xiangjiapi')
if i=='萱草':
update('萱草','xuancao')
if i=='洋金花':
update('洋金花','yangjinhua')
if i=='鱼腥草':
update('鱼腥草','yuxingcao')
if i=='紫苏':
update('紫苏','zisu')
代码讲解
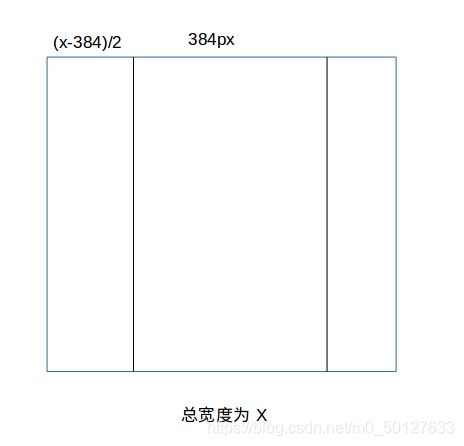
我用手机拍的照片分辨率一般为3456x4608,所以将图片缩放为384x512
newImg = img.resize((int(old_width * rate), 512), Image.BILINEAR)
if int(old_width*rate)!=384:
#将图片进行进行分割
newImg=newImg.crop([int((old_width-384)/2),0,int((old_width-384)/2+384),512])
int((old_width-384)/2的含义为

第二阶段:读取图片并保存为.txt
import os
import random
#把训练集和测试集分为8:2
train_ratio = 0.8
test_ratio = 1 - train_ratio
rootdata = '/home/hsy/PycharmProjects/数据集/5月下旬'
train_list, test_list = [], []
data_list = []
#图片的标签
class_flag = -1
'''
要取得该文件夹下的所有文件,可以使用 for(root,dirs,files) in walk(roots)函数
roots:代表需要便利的根文件夹
root: 表示正在遍历的文件夹的名字
dirs:记录正在遍历的文件夹中的文件
'''
for root, dirs, files in os.walk(rootdata):
for i in range(len(files)):
'''
os.path.join()函数:连接两个或者更多的路径名组价你
1.如果各组件首字母不包含'/',则函数会自动加上
2.如果一个组件是一个绝对路径,则在它之前的所有组件均会被舍弃
3.如果最后一个组件为空,则成一个路径以一个'/'分隔符结尾
root='/home/hsy/PycharmProjects/数据集/5月下旬/train/鱼腥草'
files[i]='yuxingcao_1.jpg'
os.path.join(root,files[i])='/home/hsy/PycharmProjects/数据集/5月下旬/train/鱼腥草/yuxingcao_1.jpg'
'''
data_list.append(os.path.join(root, files[i]))
for i in range(0, int(len(files) * train_ratio)):
train_data = os.path.join(root, files[i]) + '\t' + str(class_flag) + '\n'
train_list.append(train_data)
for i in range(int(len(files) * train_ratio), len(files)):
test_data = os.path.join(root, files[i]) + '\t' + str(class_flag) + '\n'
test_list.append(test_data)
class_flag += 1
# print(train_list)
# 将数据打乱
random.shuffle(train_list)
random.shuffle(test_list)
# 保存到txt
with open('../data/train.txt', 'w', encoding='UTF-8') as f:
for train in train_list:
f.write(train)
with open('../data/test.txt', 'w', encoding='UTF-8') as f:
for test in test_list:
f.write(test)
print(test_list)

train.txt
/home/hsy/PycharmProjects/数据集/5月下旬/瞿麦/qumai_109.jpg 16
/home/hsy/PycharmProjects/数据集/5月下旬/洋金花/yangjinhua_33.jpg 4
/home/hsy/PycharmProjects/数据集/5月下旬/萱草/xuancao_1.jpg 19
/home/hsy/PycharmProjects/数据集/5月下旬/紫苏/zisu_137.jpg 12
/home/hsy/PycharmProjects/数据集/5月下旬/香加皮/xiangjiapi_50.jpg 17
/home/hsy/PycharmProjects/数据集/5月下旬/紫苏/zisu_117.jpg 12
/home/hsy/PycharmProjects/数据集/5月下旬/紫苏/zisu_136.jpg 12
/home/hsy/PycharmProjects/数据集/5月下旬/洋金花/yangjinhua_28.jpg 4
/home/hsy/PycharmProjects/数据集/5月下旬/金芥麦/jinjiemai_107.jpg 6
/home/hsy/PycharmProjects/数据集/5月下旬/何首乌/heshouwu_42.jpg 3
.......
test.txt
/home/hsy/PycharmProjects/数据集/5月下旬/垂盆草/chuipencao_7.jpg 18
/home/hsy/PycharmProjects/数据集/5月下旬/夏枯草/xiakucao_124.jpg 2
/home/hsy/PycharmProjects/数据集/5月下旬/车前草/cheqiancao_106.jpg 8
/home/hsy/PycharmProjects/数据集/5月下旬/京大戟/jingdaji_39.jpg 7
/home/hsy/PycharmProjects/数据集/5月下旬/射干/shegan_76.jpg 5
/home/hsy/PycharmProjects/数据集/5月下旬/夏枯草/xiakucao_151.jpg 2
/home/hsy/PycharmProjects/数据集/5月下旬/牛蒡子/niubangzi_184.jpg 1
/home/hsy/PycharmProjects/数据集/5月下旬/决明子/juemingzi_100.jpg 10
/home/hsy/PycharmProjects/数据集/5月下旬/瞿麦/qumai_23.jpg 16
/home/hsy/PycharmProjects/数据集/5月下旬/紫苏/zisu_105.jpg 12
/home/hsy/PycharmProjects/数据集/5月下旬/决明子/juemingzi_92.jpg 10
/home/hsy/PycharmProjects/数据集/5月下旬/鱼腥草/yuxingcao_45.jpg 0
/home/hsy/PycharmProjects/数据集/5月下旬/紫苏/zisu_24.jpg 12
/home/hsy/PycharmProjects/数据集/5月下旬/金芥麦/jinjiemai_98.jpg 6
.......
第三阶段:改写Dataset,保证下阶段读取自己的数据集
import torch
from PIL import Image
import os
from torch.utils.data import DataLoader,Dataset
import matplotlib.pyplot as plt
from torchvision import transforms,utils,datasets
import numpy as np
#图像标准化
# transform_BN=transforms.Normalize((0.485,0.456,0.406),(0.226,0.224,0.225))
class LoadData(Dataset):
def __init__(self,txt_path,train_flag=True):
self.imgs_info=self.get_imags(txt_path)
self.train_flag=train_flag
self.transform_train=transforms.Compose([
# #随机水平翻转
# transforms.RandomHorizontalFlip(),
# #随机垂直翻转
# transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
])
self.transform_test=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
])
def get_imags(self, txt_path):
with open(txt_path,'r',encoding='UTF-8') as f:
imgs_info=f.readlines()
imgs_info=list(map(lambda x:x.strip().split('\t'),imgs_info))
return imgs_info
def __getitem__(self, index):
img_path,label=self.imgs_info[index]
img=Image.open(img_path)
img=img.convert("RGB")
if self.train_flag:
img=self.transform_train(img)
else:
img=self.transform_test(img)
label=int(label)
#返回打开的图片和它的标签
return img,label
def __len__(self):
return len(self.imgs_info)
第四阶段:读取自己的数据集并训练和测试
from torch import optim
from torch.utils.data import DataLoader
from matplotlib import pyplot as plt
import time
from data.CreateDataloader import LoadData
def load_dataset(batch_size):
train_set=LoadData("../data/train.txt",True)
test_set=LoadData("../data/test.txt",False)
train_iter=torch.utils.data.DataLoader(
dataset=train_set,batch_size=batch_size,shuffle=True,num_workers=4
)
test_iter=torch.utils.data.DataLoader(
dataset=test_set,batch_size=batch_size,shuffle=True,num_workers=4
)
return train_iter,test_iter
def get_cur_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
def learning_curve(record_train,record_test=None):
plt.style.use('ggplot')
plt.plot(range(1,len(record_train)+1),record_train,label='train acc')
if record_test is not None:
plt.plot(range(1,len(record_test)+1),record_test,label="test acc")
plt.legend(loc=4)
plt.title("learning curve")
plt.xticks(range(0,len(record_train)+1,5))
plt.yticks(range(0,101,5))
plt.xlabel("epoch")
plt.ylabel("accuracy")
plt.show()
'''
model.train()
在使用pytorch构建神经网络的时候,训练过程中会在程序上方添加一句model.train()
作用是启动batch.normalize和dropout
model.eval()
测试过程中会使用model.eval(),这时神经网络会沿用batch normalization的值,并不使用dropou
'''
def train(model,train_iter,criterion,optimizer,device,num_print,lr_scheduler=None):
model.train()
total,correct,train_loss=0,0,0
start=time.time()
for i,(inputs,labels) in enumerate(train_iter):
inputs,labels=inputs.to(device),labels.to(device)
output=model(inputs)
# print(inputs.shape)
loss=criterion(output,labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss+=loss.item()
total+=labels.size(0)
correct+=torch.eq(output.argmax(dim=1),labels).sum().item()
train_acc=100*correct/total
# print(train_acc)
if (i + 1) % num_print == 0:
print("step: [{}/{}], train_loss: {:.3f} | train_acc: {:6.3f}% | lr: {:.6f}" \
.format(i + 1, len(train_iter), train_loss / (i + 1), \
train_acc, get_cur_lr(optimizer)))
if lr_scheduler is not None:
lr_scheduler.step()
print("-----cost time:{:.4f}s----".format(time.time()-start))
# if test_iter is not None:
# record_test.append(test(model,test_iter,criterion,device))
return train_acc
def test(model, test_iter, criterion, device,test_num):
j=0
total,correct=0,0
caoyao_list = ['鱼腥草', '牛蒡子', '夏枯草', '何首乌', '洋金花', '射干', '金芥麦', '京大戟', '车前草', '千金子',
'决明子', '红花', '紫苏', '白勺', '薄荷', '当归', '瞿麦', '香加皮', '垂盆草', '萱草'
]
model.eval()
with torch.no_grad():
print("*************************test***************************")
for inputs,labels in test_iter:
inputs,labels=inputs.to(device),labels.to(device)
output=model(inputs)
loss=criterion(output,labels)
total+=labels.size(0)
# print("labels.shape",labels.shape,labels.size(0))
correct+=torch.eq(output.argmax(dim=1),labels).sum().item()
for i in range(len(labels)):
if caoyao_list[labels[i]]!=caoyao_list[output.argmax(dim=1)[i]]:
j+=1
a='['+str(test_num)+']'+'\t'+str(j)+'\t'+'正确答案:'+caoyao_list[labels[i]]+'\t'+'预测答案:'+caoyao_list[output.argmax(dim=1)[i]]+'\n'
with open('../data/ResNet18_Data_Error/8.test_data.txt', 'a', encoding='utf-8') as f:
f.write(a)
test_acc=100.0*correct/total
print("test_loss:{:.3} | test_acc:{:6.3f}%"\
.format(loss.item(),test_acc)
)
print("*************************************************************")
# model.train()
return test_acc
from model.VggNet import *
from model.VGG11 import *
from model.ResNet18 import *
batch_size=14
num_epochs=30
num_class=20
learning_rate=0.001
momentum=0.9
weight_decay=0.0005
num_print=40
test_num=0
device="cuda" if torch.cuda.is_available() else "cpu"
def main():
#这里需要更改为自己的网络模型
model=RestNet18_Net().to(device)
train_iter,test_iter=load_dataset(batch_size)
criterion=nn.CrossEntropyLoss()
optimizer=optim.SGD(
model.parameters(),
lr=learning_rate,
momentum=momentum,
weight_decay=weight_decay,
nesterov=True
)
lr_scheduler=optim.lr_scheduler.StepLR(optimizer,step_size=8,gamma=0.1)
train_acc=list()
test_acc=list()
test_num=0
for epoch in range(num_epochs):
test_num+=1
print('=================epoch:[{}/{}]======================'.format(epoch+1,num_epochs))
record_train=train(model,train_iter,criterion,optimizer,device,num_print,lr_scheduler)
record_test=test(model,test_iter,criterion,device,test_num)
train_acc.append(record_train)
test_acc.append(record_test)
print("Finished Training")
#保存训练好的模型
torch.save(model, '../save_model/ResNet18/1.pth')
torch.save(model.state_dict(), '../save_model/ResNet18/1_params.pth')
learning_curve(train_acc,test_acc)
if __name__ == '__main__':
main()
如果这段代码看不懂可以看:https://blog.csdn.net/m0_50127633/article/details/117045008,在这里我有比较详细的注释。
第五阶段:模型加载并进行测试
import torch
import torchvision
import torchvision.transforms as transforms
from PIL import Image
def pridict():
device="cuda" if torch.cuda.is_available() else "cpu"
path='../save_model/ResNet18/1.pth'
model = torch.load(path)
model=model.to(device)
model.eval()
img=Image.open('/home/hsy/PycharmProjects/数据集/5月下旬/当归/danggui_49.jpg')
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.226, 0.224, 0.225])
])
img = img.convert("RGB") # 如果是标准的RGB格式,则可以不加
img = transform(img)
img = img.unsqueeze(0)
img = img.to(device)
with torch.no_grad():
py = model(img)
'''
torch.max()这个函数返回的是两个值,第一个值是具体的value(我们用下划线_表示),第二个值是value所在的index
下划线_ 表示的就是具体的value,也就是输出的最大值。
数字1其实可以写为dim=1,这里简写为1,python也可以自动识别,dim=1表示输出所在行的最大值
'''
_,predicted = torch.max(py, 1) # 获取分类结果
#预测结果的标签
classIndex = predicted.item()
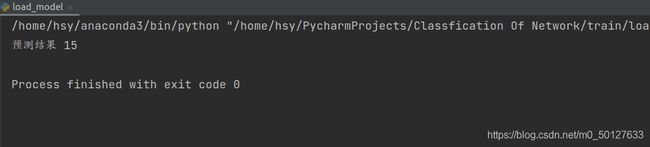
print("预测结果",classIndex)
if __name__ == '__main__':
pridict()
这是根据我自己的数据集进行写的,如果你要训练自己数据的话需要进行改写,欢迎指出不足。