(CVPR 2019) 3D-SIS: 3D Semantic Instance Segmentation of RGB-D Scans
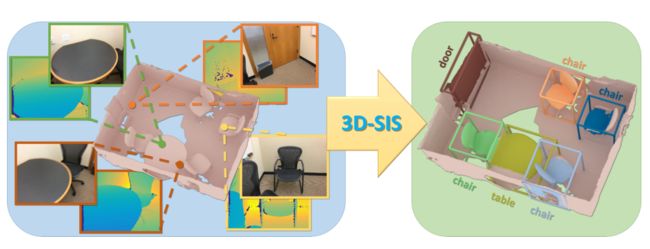
图 1:3D-SIS对RGB-D扫描数据执行3D实例分割,学习将2D RGB输入特征与3D扫描几何特征联合融合。结合能够在测试时对全3D扫描进行推理的全卷积方法,我们实现了对目标边界框、类标签和实例掩码的准确推理。
Abstract
我们介绍了3D-SIS,这是一种用于在商品RGB-D 扫描中进行3D语义实例分割的新型神经网络架构。我们方法的核心思想是联合学习几何和颜色信号,从而实现准确的实例预测。我们观察到大多数计算机视觉应用程序都有可用的多视图RGB-D输入,而不是仅在2D帧上运行,我们利用它来构建3D实例分割方法,有效地将这些多模式输入融合在一起。我们的网络通过基于3D重建的姿势对齐将2D图像与体积网格相关联来利用高分辨率RGB输入。对于每幅图像,我们首先通过一系列2D卷积为每个像素提取2D特征;然后我们将生成的特征向量反向投影到3D网格中的相关体素。这种2D和3D特征学习的组合允许比最先进的替代方案具有更高的精度目标检测和实例分割。我们在合成和真实世界的公共基准测试中展示了结果,在真实世界数据上实现了超过13的mAP改进。
1. Introduction
语义场景理解对许多现实世界的计算机视觉应用至关重要。它是实现交互性的基础,这是室内和室外环境中机器人的核心,如自动驾驶汽车、无人机和辅助机器人,以及即将到来的使用移动和AR/VR设备的场景。在所有这些应用中,我们不仅需要单幅图像的语义推理,更重要的是,还需要理解3D环境中目标空间关系和布局。
随着最近深度学习的突破和卷积神经网络的日益突出,计算机视觉社区近年来在分析图像方面取得了巨大进展。具体来说,我们看到语义分割[19,13,21],目标检测[11,26]和语义实例分割[12]任务的快速进展。这些令人印象深刻的作品的主要焦点在于分析来自单一图像的视觉输入;然而,在许多真实世界的计算机视觉场景中,我们很少发现自己处于这样的单图像设置中。相反,我们通常会记录RGB输入序列的视频流,或者在许多机器人和AR/VR应用中,我们使用激光雷达或RGB-D相机等3D传感器。
特别地,在语义实例分割的上下文中,如果必须在一系列RGB输入帧中找到实例关联,那么在单个图像上独立运行方法是非常不利的。相反,我们的目标是推断作为语义3D地图一部分的目标的空间关系,从所有输入视图和传感器数据联合学习空间一致的语义标签和底层3D布局的预测。这个目标也可以被视为类似于传统的传感器融合,但用于从多个输入进行深度学习。
我们相信,来自SLAM和视觉里程计的稳健对齐和跟踪的RGB帧,甚至深度数据,在这方面提供了一个独特的机会。这里,我们可以利用输入帧之间的给定映射,从而从所有输入模态联合学习特征。在这项工作中,我们特别关注预测RGB-D扫描中的3D语义实例,其中我们捕获一系列RGBD输入帧(例如,来自Kinect传感器),计算6DoF刚性姿态,并重建3D模型。我们的方法的核心是从投影到3D中的颜色特征和来自3D扫描的带符号距离场的几何特征中学习3D域中的语义特征。这是通过一系列3D卷积和ResNet块实现的。从这些语义特征,我们获得锚边界框proposal。我们使用新的3D区域提议网络(3D-RPN)和3D感兴趣区域池层(3D-RoI)来处理这些proposal,以推断目标边界框位置、类别标签和每个体素实例掩码。为了从RGB帧中共同学习,我们利用了它们相对于体积网格的姿态对齐。我们首先运行一系列2D卷积,然后将结果特征反投影到3D网格中。在3D中,我们然后在由边界框回归、对象分类和语义实例掩码损失约束的端到端训练中加入2D和3D特征。
我们的架构是全卷积的,使我们能够在一次拍摄中有效地推断大型 3D 环境的预测。与对单个 RGB 图像进行操作的最先进方法(例如 Mask R-CNN [12])相比,我们的方法由于联合特征学习而实现了更高的准确性。
总而言之,我们的贡献如下:
-
我们提出了第一种利用几何和 RGB 输入联合2D-3D端到端特征学习的方法,用于3D目标边界框检测和3D扫描语义实例分割。
-
我们利用全卷积 3D 架构对场景部分进行实例分割训练,但在大型 3D 环境中进行单次推理。
-
我们的表现明显优于最先进的技术,在真实世界数据上将 mAP 提高了 13.5。
2. Related Work
2.1. Object Detection and Instance Segmentation
随着卷积神经网络架构的成功,我们现在已经看到2D图像中的对象检测和语义实例分割取得了令人印象深刻的进展[11,27,18,26,16,12,17]。值得注意的是,Ren等人[27]引入了锚机制来预测区域中的目标,并在对目标类型进行联合分类的同时回归相关的2D边界框。Mask R-CNN[12]通过预测每像素目标实例掩码,将这项工作扩展到语义实例分割。检测的另一个方向是流行的Yolo工作[26],它也在图像的网格单元上定义锚。
随着越来越多的视频和RGB-D数据变得可用,2D目标检测和实例分割方面的这一进展激发了3D领域中的目标i检测和分割工作。Song等人提出了滑动形状,通过手工特征设计从单个RGB-D帧输入中预测3D目标边界框[30],然后将该方法扩展到对学习到的特征进行操作[31]。后一个方向利用RGB帧输入来提高检测到的目标的分类精度;与我们的方法相比,对于联合特征学习,在RGB和几何图形之间没有显式的空间映射。Frustum PointNet[22]采用了另一种方法,在该方法中,检测在2D帧中进行,然后反投影到3D中,最终的边界框预测从3D中提炼。Wang等人[35]将他们SGPN方法基于来自PointNet++变体的语义分割。他们通过引入类似于全景分割背后的思想的相似性矩阵预测,将实例分割公式化为语义分割点云上的聚类问题[15]。与这些方法相反,我们明确地将多视图RGB输入与3D几何图形进行映射,以便以端到端的方式联合推断3D实例分割。
2.2. 3D Deep Learning
近年来,我们看到3D深度学习的发展取得了令人瞩目的进展。类似于2D域,可以在体积网格上定义卷积运算符,例如将表面表示嵌入为隐式符号距离场 [4]。随着3D形状数据库[36、3、32]和带注释的 RGB-D数据集[29、1、5、2]的可用性,这些网络架构现在被用于3D目标分类[36、20、24、28] 、语义分割[5、34、6],以及目标或场景补全[8、32、9]。体积网格的另一种表示是流行的基于点的体系结构,例如PointNet[23]或PointNet++ [25],它们利用更高效但结构较少的3D表面表示。还提出了多视图方法来利用RGB或RGB-D视频信息。 Su等人提出了第一个通过2D预测视图池进行目标分类的多视图架构 [33],Kalogerakis等人最近提出了一种通过将预测的2D置信度图投影到3D形状来进行形状分割的方法,这是然后通过CRF[14]进行汇总。我们的方法将许多这些想法结合在一起,利用整体3D表示的力量以及来自 2D 信息的特征,通过它们的显式空间映射将它们组合起来。
3. Method Overview
我们的方法以端到端的方式在每个体素的基础上推断3D目标边界框位置、类标签和语义实例掩码。为此,我们提出了一种神经网络,可以从几何和RGB输入中共同学习特征。在下文中,我们将边界框回归和目标分类称为目标检测,将每个目标的语义实例掩码分割称为掩码预测。
在第4节中,我们首先介绍我们的方法所使用的数据表示和训练数据。这里,我们考虑来自SUNCG [32]的合成地面真实数据,以及来自ScanNetV2 [5]的人工注释的真实世界数据。在第5节中,我们介绍了3D-SIS方法的神经网络结构。我们的架构由几个部分组成;一方面,我们有一系列在扫描的3D数据的体素网格空间中操作的3D卷积。另一方面,我们学习2D特征,我们将这些特征反投影到体素网格中,在那里我们结合这些特征,从而从几何和RGB数据中联合学习。这些特征用于检测目标实例;也就是说,通过3D-RPN回归关联的边界框,并且为3D-ROI汇集层之后的每个目标预测类别标签。对于每个检测到的目标,来自2D颜色和3D几何形状的特征被转发到每个体素的实例掩模网络中。以端到端的方式训练检测和每体素实例掩模预测。在第6节中,我们描述了我们方法的训练和实施细节,在第7节中,我们评估了我们的方法。
4. Training Data
Data Representation 我们使用截断符号距离场(TSDF)表示来编码3D扫描输入的重建几何形状。TSDF存储在截断了3个体素的规则体积网格中。除了这个3D几何图形,我们还输入空间相关的RGB图像。这是可行的,因为我们知道基于来自相应3D重建算法的6自由度(DoF)姿态的每个图像像素与3D场景网格中的体素之间的映射。
对于训练数据,我们将每个3D扫描细分为4.5m × 4.5m × 2.25m的块,每个块使用96 × 96 × 48体素的分辨率(每个体素存储一个TSDF值);在我们的实验中,为了训练,我们将每个块中分辨率为328×256像素的5个RGB图像相关联,其中训练图像是基于该区域内实例的平均体素到像素覆盖而选择的。
我们的架构是完全卷积的(见第5节),这使得我们可以在整个场景中一次性运行我们的方法进行推理。这里,xy体素分辨率是从给定测试场景的空间范围中获得的。体素网格的z(高度)固定为48个体素(大约是一个房间的高度),体素大小也固定为4.69cm3。此外,在测试时,我们使用所有可用的RGB图像进行推断。为了评估我们的算法,我们使用来自合成和真实世界RGB-D扫描数据集的训练、验证和测试数据。
Synthetic Data 对于综合训练和评估,我们使用SUNCG [32]数据集。我们遵循公共训练/val/测试划分,使用5519个训练、40个验证和86个测试场景(选择总体积< 600m3的测试场景)。从训练和验证场景中,我们提取了97,918个训练组块和625个验证组块。每个块平均包含大约4.3个目标实例。在测试时,我们获取86个测试场景的完整扫描数据。
为了从这些合成场景中生成部分扫描数据,我们虚拟地渲染它们,存储RGB和深度帧。轨迹是按照[9]的虚拟扫描方法生成的,但适用于提供更密集的相机轨迹,以更好地模拟现实世界的扫描场景。基于这些轨迹,我们然后通过体积融合生成部分扫描作为TSDFs,并基于相机姿态定义训练数据RGB到体素网格图像关联。我们使用23个类类别进行实例分割,由它们的NYU40类标签定义;这些类别是为最常出现的目标类型选择的,忽略了没有明确定义实例的墙和楼板类别。
Real-world Data 为了在真实场景中训练和评估我们的算法,我们使用了ScanNetV2 [5]数据集。该数据集包含1513个场景的RGB-D扫描,包括大约250万个RGB-D帧。使用BundleFusion [7]重建扫描图;6自由度姿态对准和重建模型都是可用的。此外,每次扫描包含3D网格上手动注释的目标实例分割掩码。从这些数据中,我们导出了3D边界框,我们将其用作我们的3D区域提议的约束。
我们遵循最初由ScanNet分别提出的1045(训练)、156 (val)、312(测试)场景的公共训练/val/测试分割。从训练场景中,我们提取了108241个组块,从验证场景中,我们提取了995个组块。请注意,由于扫描网络数据集中可用的火车扫描数量较少,我们将训练扫描增加到每个有4次旋转。我们采用与ScanNet benchmark建议的相同的18类标签集进行实例分割。
请注意,只要语义 RGB-D 实例标签可用,我们的方法就与相应的数据集无关。
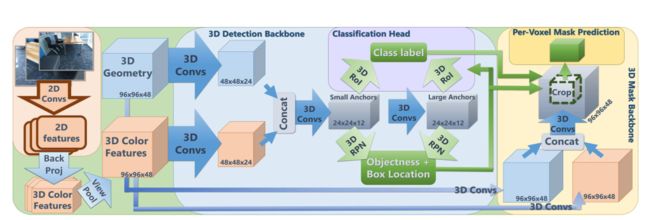
图 2:3D-SIS 网络架构。我们的架构由 3D 检测和 3D mask管道组成。 3D 几何和 2D 彩色图像都作为输入,用于联合学习语义特征以进行目标检测和实例分割。从 3D 检测主干,颜色和几何特征用于通过 3D-RPN 和 3D-RoI 层提出目标边界框及其类标签。除了 3D 检测结果之外,mask backbone还使用颜色和几何特征来预测 3D 边界框内的每个体素实例 mask。
5. Network Architecture
我们的网络架构如图 2 所示。它由两个主要组件组成,一个用于检测,一个用于每个体素实例掩模预测;这些管道中的每一个都有自己的特征提取主干。两个主干都由一系列 3D 卷积组成,将 3D 扫描几何结构和反向投影的 RGB 颜色特征作为输入。我们在第 5.1 节详细介绍了 RGB 特征学习,在第 5.2 节详细介绍了特征主干。然后,将学习到的检测和掩模主干的 3D 特征分别输入到分类和体素实例掩模预测头中。
该网络的目标检测组件包括检测主干、预测边界框位置的3D区域提议网络(3D-RPN)以及跟随分类头的3D感兴趣区域(3D-RoI)汇集层。检测中枢输出输入到3D-RPN和3D-RoI的特征,以分别预测边界框位置和目标类别标签。3D-RPN通过将预定义的锚与ground-truth目标注释相关联来训练;在这里,每个anchor损失定义了给定锚点是否存在目标。如果是,第二个损失使3D目标边界框回归;如果不是,则不考虑额外损失。此外,我们对每个3D边界框的对象类进行分类。对于每体素实例掩码预测网络(参见第5.4节),我们使用输入颜色和几何图形以及预测的边界框位置和类标签。剪切的特征通道用于创建具有用于n个语义类别标签的n个通道的掩模预测,并且使用先前预测的类别标签从这些通道中选择最终的掩模预测。我们使用二进制交叉熵损失来优化实例掩模预测。注意,我们端到端地联合训练主干、边界框回归、分类和每个体素掩模预测;参见第6节了解更多详情。在下文中,我们描述了架构设计的主要组件,有关确切过滤器尺寸等的更多详细信息,我们参考了补充材料。
5.1. Back-projection Layer for RGB Features
为了联合学习 RGB 和几何特征,可以简单地为每个体素分配一个 RGB 值。然而,在实践中,由于内存限制,RGB 图像分辨率明显高于可用的 3D 体素分辨率。这种 2D-3D 分辨率不匹配会使从每个体素颜色中学习变得相当低效。受 Dai 等人[6] 的语义分割工作的启发,我们利用一系列 2D 卷积来总结图像空间中的 RGB 信号。然后我们定义一个反投影层并将这些特征映射到相关的体素网格之上,然后将其用于目标检测和实例分割。
为此,我们首先预训练一个基于 ENet 架构的 2D 语义分割网络 [21]。 2D 架构将单个 256 × 328 RGB 图像作为输入,并使用 NYUv2 40 标签集对语义分类损失进行训练。从这个预训练网络中,我们从编码器中提取具有 128 个通道的 32 × 41 维特征编码。使用相应的深度图像、相机内在特性和 6DoF 姿势,然后我们将这些特征中的每一个反向投影回体素网格(仍然是 128 个通道);投影是从 2D 像素到 3D 体素。为了组合来自多个视图的特征,我们通过对所有可用的 RGB 图像进行逐元素最大池化来执行视图池化。
对于训练,体素体积固定为 96 × 96 × 48 体素,从而在 3D 中产生 128 × 96 × 96 × 48 反向投影 RGB 特征网格;在这里,我们为每个训练块使用 5 个 RGB 图像(图像选择基于平均 3D 实例覆盖)。在测试时,体素网格分辨率是动态的,由环境的空间范围决定;在这里,我们使用所有可用的 RGB 图像。投影特征的网格由一组 3D 卷积处理,随后与几何特征合并。
在 ScanNet [5] 中,提供了相机位姿和内在函数;我们直接将它们用于我们的反投影层。对于SUNCG [32],外部和内部由虚拟扫描路径给出。请注意,我们的方法与使用的 2D 网络架构无关。
5.2. 3D Feature Backbones
为了联合学习用于实例检测和分割的几何和 RGB 特征,我们提出了两个 3D 特征学习主干。第一个骨干生成用于检测的特征,并将 3D 几何和反向投影的 2D 特征作为输入(参见第 5.1 节)。
在通过连接将它们连接在一起之前,几何输入和 RGB 特征都使用 3D ResNet 块进行对称处理。然后我们应用 3D 卷积层将空间维度减少 4 倍,然后是 3D ResNet 块(例如,对于 96 × 96 × 48 的输入训练块,我们获得大小为 24 × 24 × 12 的特征).然后我们应用另一个 3D 卷积层,保持相同的空间维度,以提供具有更大感受野的特征图。我们在这两个特征图上定义锚点,将锚点分为“小”和“大”锚点(小锚点<1m3),小锚点与较小感受野的第一个特征图相关联,大锚点与第二个特征图相关联更大的感受野。为了选择锚点,我们在前 10k 个块中的ground-truth 3D 边界框上应用 k-means 算法 (k=14)。然后将这两个级别的特征图用于目标检测的最后步骤:3D 边界框回归和分类。
实例分割主干也将 3D 几何和反向投影的 2D CNN 特征作为输入。几何和颜色特征首先用两个 3D 卷积独立处理,然后按通道级联并用另外两个 3D 卷积处理以产生掩码特征图预测。请注意,对于掩码主干,我们通过所有卷积保持相同的空间分辨率,我们发现这对于获得体素实例预测的高精度至关重要。掩码特征图预测用作输入以预测最终实例掩码分割。
与单一骨干网相比,我们发现这种双骨干网结构更容易收敛并产生明显更好的实例分割性能(有关骨干网训练方案的更多详细信息,请参见第 6 节)。
5.3. 3D Region Proposals and 3D-RoI Pooling for Detection
我们的 3D 区域提议网络 (3D-RPN) 从检测主干获取输入特征来预测和回归 3D 目标边界框。从检测主干中,我们获得了小型和大型锚点的两个特征图,它们分别由 3D-RPN 处理。对于每个特征图,3D-RPN 使用 1 × 1 × 1 卷积层将通道维度降低到 2 × N anchors 2 \times N_{\text {anchors }} 2×Nanchors ,其中 N anchors = ( 3 , 11 ) N_{\text {anchors }}=(3,11) Nanchors =(3,11)分别用于小锚点和大锚点。这些代表正负每个锚点的目标性分数。我们根据它们的目标分数对这些区域提议应用非最大抑制。然后 3D-RPN 使用另一个 1×1×1 卷积层来预测 6 × N anchors 6 \times N_{\text {anchors }} 6×Nanchors 的特征图,它将 3D 边界框位置表示为 ( Δ x , Δ y , Δ z , Δ w , Δ h , Δ l ) \left(\Delta_x, \Delta_y, \Delta_z, \Delta_w, \Delta_h, \Delta_l\right) (Δx,Δy,Δz,Δw,Δh,Δl), 在等式1中定义。
为了在训练期间确定每个锚点的真实目标性和关联的3D 边界框位置,我们执行锚点关联。锚通过它们的IoU与ground truth边界框相关联:如果 IoU > 0.35,我们认为锚是正的(并且它将回归到关联的框),如果 IoU < 0.15,我们认为锚是正的否定(并且它不会回归到任何box)。我们使用两类交叉熵损失来衡量目标性,对于边界框回归,我们使用 Huber 损失来预测 ( Δ x , Δ y , Δ z , Δ w , Δ h , Δ l ) \left(\Delta_x, \Delta_y, \Delta_z, \Delta_w, \Delta_h, \Delta_l\right) (Δx,Δy,Δz,Δw,Δh,Δl)对数ground truth box 和 anchors 的比率 ( Δ x g t , Δ y g t , Δ z g t , Δ w g t , Δ h g t , Δ l g t ) \left(\Delta_x^{g t}, \Delta_y^{g t}, \Delta_z^{g t}, \Delta_w^{g t}, \Delta_h^{g t}, \Delta_l^{g t}\right) (Δxgt,Δygt,Δzgt,Δwgt,Δhgt,Δlgt), 其中
Δ x = μ − μ anchor ϕ anchor Δ w = ln ( ϕ ϕ anchor ) ( 1 ) \Delta_x=\frac{\mu-\mu_{\text {anchor }}}{\phi_{\text {anchor }}} \quad \Delta_w=\ln \left(\frac{\phi}{\phi_{\text {anchor }}}\right) \quad\quad\quad\quad(1) Δx=ϕanchor μ−μanchor Δw=ln(ϕanchor ϕ)(1)
其中 μ \mu μ是框的中心点, ϕ \phi ϕ是框的宽度。
使用预测的边界框位置,我们可以从全局特征图中裁剪出相应的特征。然后我们使用我们的 3D 感兴趣区域 (3D-RoI) 池化层将这些裁剪后的特征统一到相同的维度。这个 3D-RoI 池化层通过最大池化操作将裁剪后的特征图池化为 4 × 4 × 4 块。然后将这些特征块线性化以输入目标分类,这是使用 MLP 执行的。
5.4. Per-V oxel 3D Instance Segmentation
我们使用单独的掩模主干执行实例掩模分割,与检测主干类似,将 3D 几何和投影 RGB 特征作为输入。但是,对于掩模预测,3D 卷积保持相同的空间分辨率,以保持空间对应使用原始输入,我们发现它可以显着提高性能。然后,我们使用来自 3D-RPN 的预测边界框位置从掩码主干中裁剪出相关的掩码特征,并使用 3D 卷积计算最终掩码预测,以将 n 个语义类标签的特征维数降低到 n;最终掩码预测是预测目标类别c的第 c 个通道。在训练期间,由于来自检测管道的预测可能是错误的,我们只训练其预测边界框与ground truth边界框重叠至少 0.5 IoU的预测。 mask targets被定义为ground truth box和proposed box重叠区域的ground-truth mask。
8. Conclusion
在这项工作中,我们介绍了3D-SIS,一种用于RGB-D扫描的3D语义实例分割的新方法,它以端到端的方式进行训练,以检测目标实例并推断每个体素的3D语义实例分割。我们的方法的核心是使用商品RGB-D传感器记录的多视图RGB-D输入,从RGB和几何数据中联合学习特征。该网络是完全卷积的,因此可以在大型3D环境中一次有效运行。与通常在单个RGB帧上操作的现有最先进的方法相比,我们实现了明显更好的3D检测和实例分割结果,在mAP上提高了13倍以上。我们相信,这对于广泛的计算机视觉应用来说是一个重要的见解,因为它们中的许多现在都捕捉多视图RGB和深度流;例如自动驾驶汽车、AR/VR应用等。
论文链接:https://openaccess.thecvf.com/content_CVPR_2019/papers/Hou_3D-SIS_3D_Semantic_Instance_Segmentation_of_RGB-D_Scans_CVPR_2019_paper.pdf
References

