Mean Shift Segmentation Assessment for Individual Forest Tree Delineation from Airborne Lidar Data
Abstract
机载激光雷达已广泛用于森林表征,以促进森林生态和管理研究。由于森林的复杂性和多样性,随着越来越高的点密度的可用性,从机载激光雷达点云中描绘单棵树(ITD)已经成为一个流行但具有挑战性的主题。ITD的一个重要步骤是分割,为此研究了各种方法。其中,一种久经考验的图像分割方法,均值漂移,已经被直接应用到3D点上,并且已经显示出有希望的结果。然而,在核形状、适应性和权重方面,实现该算法的人之间存在差异。本文详细评估了用于机载激光雷达数据分割的均值漂移算法,以及树冠探测对分割结果有效性的影响。来自三个不同数据集的结果显示,冠状核(crown-shaped kernel)始终比其他变体产生更好的结果(高达7%),而权重和适应性并不保证改进。
Keywords: 个体树检测;3D聚类;机载激光扫描;点云
1. Introduction
森林生态系统是食物、水、木材、调节气候、洪水、水质以及生物多样性和娱乐等服务的重要提供者[1]。在当前人类发展和气候变化的条件下,森林的可持续适应和管理变得至关重要。遥感技术已广泛用于森林调查和监测,以支持森林管理[2]。在各种遥感技术中,激光扫描或光探测和测距(lidar)由于其独特的优势,即能够穿透树叶并捕捉树木结构和地面,已经引起了特别的兴趣[3]。
激光雷达已经集成到各种平台中,以在不同的尺度上研究森林,包括星载卫星(例如,全球生态系统动力学调查)[4],机载系统(例如,直升机或飞机)[5],无人驾驶飞行器(UAV)[6],地面移动平台(例如,车辆,背包,手持设备)[7],以及地面固定三脚架[8]。这些激光雷达系统中的每一个都可以生成在覆盖范围、点密度、视野和精度方面具有不同特征的点云,使它们最适合不同的用途。
机载激光雷达或机载激光扫描(ALS)系统通常由三个主要组件组成:用于绝对定位的全球导航卫星系统(GNSS)接收器、用于定位和定向的惯性测量单元,以及以3D点的形式通过距离和角度测量地面的激光扫描仪[9,10]。它们通常安装在飞机上,用于大范围覆盖,同时保持良好的(厘米)级精度。点密度取决于几个因素,如扫描仪测量速率和扫描机制、飞行高度和速度、条带宽度和条带重叠,因此它可能从每平方米少于1个点到每平方米超过50个点不等。但总的来说,随着机载激光扫描仪的发展,最大点密度越来越高。
由于点密度有限,早期研究主要集中在林分水平的特征,如机载激光雷达数据中的林冠覆盖和高度[11–13]。现在,点密度足够高,可以在每棵树上捕捉足够数量的点,因此,单棵树的检测或描绘(ITD),包括树的位置、大小、形状和数量,已经引起了相当大的关注[5,14–16]。垂直分布、地上生物量和其他次要特性可以从这些精确的划界参数中推导出来。因此,ALS越来越多地被用于景观或区域尺度的精确森林制图和监测[10]。
虽然机载激光雷达ITD是森林研究的一个重要研究课题,但由于森林结构及其组成的复杂性和异质性,它仍然是一个挑战。ITD的主要困难是树分割,这是将所有的点分割成代表单个树的簇的步骤。树木分割有两种主要策略:基于栅格和基于点[17,18]。早期的方法大多采用第一种策略,将3D点云转换为树冠高度模型(CHMs),一种光栅图像,然后使用2D图像处理技术(如局部极大值、区域生长和分水岭)检测树顶[5]。第二种策略直接基于3D点分割树[14,19]。例子包括基于规则的距离和高度阈值[16,20,21],基于体素[22],基于图[23]和基于核[24]的方法。一些人试图结合这两种策略来分别检测树顶和树干,然后在体素空间中进行分割[25]。直接基于3D点云的分割方法被证明优于基于2D光栅转换的分割方法,例如CHM,尤其是对于多层森林[14,19]。其中一种三维方法,均值漂移,一种经典的2D聚类方法,可以很容易地适用于三维场景,已经引起了直接三维点云分割的相当大的关注[24,25]。
均值漂移已成功地应用于计算机视觉和图像处理中,用于特征空间的模式搜索。该模式是密度函数的最大值,并且通过移动由核确定的加权平均值来迭代地定位,因此命名为均值移动。核可以很容易地扩展到3D中,因此可以直接从3D点计算平均值。对于不同类型的树木条件,如多层温带[24]和热带森林[26],混合物种城市树木[27]和北方针叶林[28],它已经显示出有希望的结果。然而,有一些因素需要考虑,如内核形状,大小和重量,以更好地实现它来分割树木。
由于文献中对核函数和权重的深入分析不够,本文旨在对机载激光雷达数据的ITD均值漂移算法进行详细评估,以阐明这些变化对性能的影响。
2. Related Work
由 Fukunaga 和 Hostetler [29] 提出,将原始均值漂移算法应用于聚类和数据噪声过滤。 Cheng [30] 进一步证明它对聚类和全局优化是有效的。然后它被广泛用作特征空间图像分割的鲁棒方法[31]。此外,它被广泛用于非刚性目标的实时跟踪[32]。由于其在图像分割方面的明显进步,均值偏移很快被应用于遥感图像[33-35]。例如,Huang 和 Zhang [33] 使用具有自适应带宽的均值偏移来通过支持向量机 (SVM) 提取基于对象的高维高光谱图像城市分类特征。
Maschler 等人 [36] 两次将均值偏移应用于机载高光谱图像:首先区分矮树和高树,其次分割单个树冠,对温带森林进行分类。
Melzer [37] 率先采用 Mean Shift 进行 ALS 点云分割,通过该方法可以区分城市地区的电力线和植被。 Yao 等人 [38] 将均值漂移与归一化切割相结合,对城市地区的 3D 机载激光雷达数据进行分割和分类。 Lee 等人 [39] 使用均值漂移分割从综合机载激光雷达点云和航空正射影像中提取海岸线。
表 1 列出了机载激光雷达数据中树木分割均值漂移的用法,以及研究中使用的设置。 Ferraz 等人 [40] 首先使用均值偏移在 3D 中对森林垂直结构进行分层。选择以圆柱形实现的 Epanechnikov 内核,并凭经验选择三个离散的内核带宽将森林分层为三层。然后使用该算法提取单个树 [24]。由于内核形状和水平分量与垂直分量之间的比率是固定的,因此只有一个参数需要调整,即内核带宽。 Ferraz 等人 [26] 随后采用该方法检测热带森林内不同层的个体树冠。基于先前的方法,自适应均值偏移 3D 分割 (AMS3D) 使用定义树高和树冠之间关系的异速生长函数提出了宽度和深度。带宽模型自适应异速生长函数;例如,它会随着内核在更高的树上向上移动而增加。
表 1 列出了机载激光雷达数据中树木分割均值漂移的用法,以及研究中使用的设置。 Ferraz 等人 [40] 首先使用均值偏移在 3D 中对森林垂直结构进行分层。选择以圆柱形实现的 Epanechnikov 内核,并凭经验选择三个离散的内核带宽将森林分层为三层。然后使用该算法提取单个树 [24]。由于内核形状和水平分量与垂直分量之间的比率是固定的,因此只有一个参数需要调整,即内核带宽。 Ferraz 等人 [26] 随后采用该方法检测热带森林内不同层的个体树冠。基于先前的方法,自适应均值偏移 3D 分割 (AMS3D) 使用定义树高和树冠之间关系的异速生长函数提出了宽度和深度。带宽模型自适应异速生长函数;例如,它会随着内核在更高的树上向上移动而增加。
表 1. 报告的用于树分割的均值漂移的变化。

Yao 等人 [41] 还使用具有水平高斯分布的圆柱核来使用固定带宽提取点的局部密集模式。那些局部模式被有意地过度分割,并且特征是从那些分割的集群中导出的,然后通过测量集群在空间分布和特征方面的相似性,通过归一化切割进行分组。对该方法进行了进一步研究,以估计温带森林中 5 m 以下的再生覆盖率 [42]。圆柱形内核的半径和高度均独立设置,并进一步测试了半径和高度的灵敏度。
除了森林树木,均值漂移算法也被 Xiao 等人应用于城市树木 [27]。为了适应一般的树形,树冠模型,即 Pollock 模型,可以从圆锥体到椭圆体变化, 被提议作为均值偏移核。此外,采用连续自适应均值漂移 (CamShift) 概念,假设较高的树木具有较宽的树冠,并且会受益于更大的带宽。因此,带宽被设置为以恒定比率连续适应树高,这对树的大小、形状和物种不敏感,正如实验中发现的那样。
Hu等人[43]进一步证明了自适应均值漂移对个体树识别的优势。不是使用异速生长函数,而是首先通过固定带宽均值偏移对点进行粗略分割,并通过在不同高度的多层上生长的迭代区域来估计树冠大小。然后,在第二轮均值偏移分割中,使用不同的树冠大小来指导内核带宽。与之前的研究一样,选择了球形内核而不是圆柱形内核。通过首先检测树干来改进分割和定位结果,以补充自适应均值偏移分割 [44]。
除了单色波长激光雷达点,该算法也被 Dai 等人[28] 用于多光谱机载激光雷达数据,他们首先只在空间域对树木进行分割,然后使用 SVM 检测那些被欠分割的,然后考虑到多光谱域,通过第二轮均值偏移分割对其进行细化。圆柱核遵循与[24]中相同的设计,除了在核的较高点上增加了额外的权重,引导核向上移动。
总之,均值漂移算法一直是一种流行且有效的方法,用于从不同类型森林的机载激光雷达数据中分割单株树木。然而,在内核形状、内核大小的适应性和权重方面存在差异。因此,本文将着重于对算法进行系统评估,以更好地了解不同配置和数据条件下的性能。
3. Materials and Methods
从原始机载激光扫描数据中描绘单个林木的完整工作流程如图 1 所示。首先,对原始点云进行预处理以准备分割。对地面点进行分类,然后对地上点进行归一化以避免影响从分割步骤中的地形起伏。此外,1 m 以下的点被认为是噪声,因此被过滤掉。接下来,使用基于点的分割方法均值偏移将整个点云分割成单独的树。本文将重点介绍使用均值漂移评估树木分割,这是影响后续树木参数提取的重要步骤。其他代表性方法,例如标记控制的分水岭分割 [15],也用于比较。然后对于每个段,提取树参数,例如位置 (x, y)、高度 (h)、最长树冠传播 (l) 和最长树冠交叉传播 (l’)。最后,根据现场测量验证提取,以便评估均值漂移算法变体的准确性。
图 1. 根据机载光探测和测距(激光雷达)数据描绘单个林木的工作流程。
3.1. Test Data
本研究使用三种类型的地块来测试树木分割方法:a) 综合生成的混合落叶林地,b) 单一栽培针叶林,c) 两个混合针叶树种和落叶树种的森林地块。
合成数据集(图2)由开源软件HELIOS [45]模拟。使用合成数据的主要优势包括:a)准确了解树木位置和树冠参数,b)控制树木的数量和种类。将四个物种,黑tupelo (Nyssa sylvatica Marshall)、檫木(Sassafras albidum)、柽柳(Larix laricina (Du Roi) K.Koch)和垂柳(Salix babylonica L .),输入到RIEGL LMS-Q780模拟器中,以模拟随机位于100m×100m正方形(1公顷)上的50棵树。它们的高度分别为27.891米、24.351米、22.116米和13.599米。
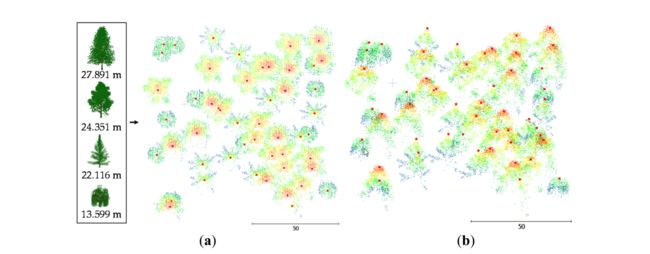
图 2. HELIOS 模拟的合成数据(以米为单位)。 (a) 鸟瞰图的树模型和模拟数据,(b) 透视图。总共有 50 棵树,有四种不同高度的树。红点代表树顶
除了合成数据外,实验还使用了位于伊丽莎白女王森林公园(英国阿伯福伊尔)的单一栽培种植园的机载激光扫描 (ALS) 数据集(每平方米 8.4 个点)(图 3(a))。这些数据由英国自然环境研究委员会机载研究机构于 2014 年 8 月使用徕卡 ALS50 扫描仪收集。该地块种植于 1965 年,由黑松 (Pinus contorta Dougl.) 组成。树木参数,包括 45 棵树的位置和高度,在实地活动期间进行了调查。树的位置由树底部的全站仪测量,而高度则使用顶点测压计 [46] 测量。记录的平均树高为 16.18 米,标准偏差为 2.12 米。请注意,整个地块包含的树木要多得多,但仅测量了覆盖不同树木大小和密度的这个子集以进行验证。理想情况下,如果采用有效的树木勾画方法,只需对一小块地块进行地面测量以验证该方法并选择参数或配置,然后将其应用于整个区域而无需进一步调整参数。
除了合成数据之外,实验还使用了位于伊丽莎白女王森林公园(英国阿伯福伊尔)的单一种植林的机载激光扫描(ALS)数据集(每平方米8.4个点)(图3(a))。这些数据是由英国自然环境研究委员会机载研究设施在2014年8月使用徕卡ALS50扫描仪收集的。该地块种植于1965年,由黑松组成。).在实地调查期间,调查了树木参数,包括45棵树的位置和高度。通过全站仪在树的底部测量树的位置,同时使用顶点高度计测量树的高度[46]。记录的平均树高为16.18米,标准偏差为2.12米。请注意,整个地块包含更多的树木,但只测量了覆盖不同树木大小和密度的子集进行验证。理想情况下,给定一个有效的树木描绘方法,只需要对一小块地进行地面测量,以验证该方法并选择参数或配置,然后将其应用于整个区域,无需进一步调整参数。
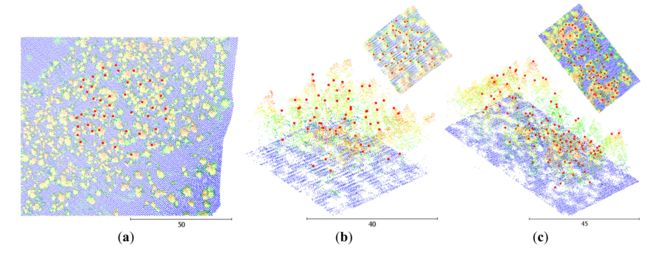
图3。实验数据(单位为米)。(A)英国苏格兰阿伯福伊尔森林的一块土地。(b)来自国际基准的图B1。(c )根据国际基准描绘B2。红点代表地面测量的树顶
两个地块的最终数据(地块 B1 图 3b 和 B2 图 3c,每平方米约 8 个点)取自国际基准 [22]。它们都有混合物种,包括挪威云杉 (Picea abies L.)、欧洲赤松 (Pinus sylvestris L.)、绒毛桦 (Betula sp. L.) 和白杨 (Populus tremula L.)。地块 B1 主要由挪威云杉 (80%) 组成,平均树高为 16.8 m,标准差为 6.4 m。地块 B2 有大约 55% 的挪威云杉,平均树高为 16.1 m,标准差为 7.31 m。两个地块都有多个冠层,即主导、共同主导、中间和抑制。 ALS 数据是在 2004 年 6 月使用 Optech 2033 机载扫描仪收集的。使用地面激光扫描仪 (TLS) Faro LS880HE 收集现场测量值。树木的位置和高度是根据 TLS 数据手动测量的。
3.2. Methods
3.2.1. Pre-processing
树上的点的Z坐标还包含地形的海拔,当参数与树的高度相关时,地形的海拔会影响分割。常见的程序是相对于地面标准化高程。机载光探测和测距(lidar)数据的地面分类是一个经过充分研究的主题[47],有专有和免费的开源软件可用于地面过滤。这里采用lastools(https://rapidlasso.com/lastools/)来识别地面点,这些地面点用于归一化其他点,以便树的底部处于零高度,并且Z坐标对应于树的高度。经过地面过滤后,可以在地面上观察到额外的点,这些点是由林下植被(如草或小灌木)产生的。由于这些点不是感兴趣的,并且会影响分割,因此应用1 m的缓冲区来过滤掉这些点,如Wang等人所建议的[22]。这个高度缓冲区可以根据所研究森林的垂直结构而变化。如果林下植被更高,更大的缓冲区可能更合适[28]。剩余的点被认为是在感兴趣的树上,并且将被分割。
3.2.2. Mean Shift Segmentation
均值偏移已广泛用于特征空间中的图像聚类,可以是多维的。本节将解释均值偏移对 3D 点云分割的不同适应。给定 n 个点 x i \mathrm{x}_{\mathrm{i}} xi 的激光雷达数据, i = 1 , … , n i=1, \ldots, n i=1,…,n在 3D 空间中,均值偏移向量可以导出为多元核密度估计器的梯度,如下所示:

其中 g(−) 定义内核配置文件,h 是确定内核大小的带宽参数。向量 vh(x) 是加权平均值之间的差值,使用核作为权重,点 x 是核的中心,指向密度最大增加的方向,因此密度的模式可以通过用向量翻译内核(窗口)来迭代地达到。 [30,31] 可以参考更多细节。该算法已根据内核形状、大小和权重进行调整,以最适合树分割。
核形状:3D中最简单的核形状是球体[42],它适应不同的形状以更好地分割树,例如圆柱体[24]。 Pollock 模型也被用作内核,因为该模型代表可以通过额外参数 [27] 调整的冠形。
该模型定义如下:
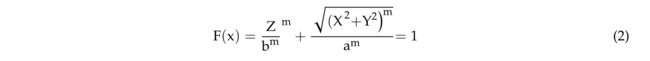
其中 x = (X, Y , Z) 相对于模型中心,a 是冠圆在 XY 平面上的半径,b 是沿 Z 轴的半径,m 是冠形参数。当m = 1时,模型是一个圆锥体,当m增加到2时,它变成一个椭球体。将测试这三种内核形状,球体,圆柱体和Pollock模型,以确定它们对树分割的影响。
内核大小:已经表明,可以使用不同的内核大小来分割不同大小和树冠不同层的树[24],但内核大小的设置大多是基于反复试验的。 Cylinder 和 Pollock 模型内核分别具有两个沿水平轴和垂直轴的带宽/大小参数 (a, b)。最常见的是,两个带宽参数 b/a 之间的比率在移位过程中保持固定,并且只调整一个。另一种方法是根据树的高度调整内核大小,假设较高的树有利于较大的内核,而较短和较小的树有利于较小的内核。这种方法被称为连续自适应均值偏移(Camshift)[27]。在测试中,内核大小(带宽)在两个方面进行测试,即,(1)水平带宽的影响(a ∈ [2, 3, 4, 5, 6, 7, 8, 9]),以及两个带宽参数之间的比率 (b/a ∈ [1, 1.5, 2, 2.5, 3]),以及 (2) 内核是否连续适应树的高度(Y 或 N)。
内核权重:除了内核的形状之外,还可以对内核应用不同的加权策略,包括 XY 平面中的权重、Z 中的权重,或者只是没有任何权重的扁平内核。水平内核权重,例如高斯函数 [24],将更多的权重放在中心点上,这意味着内核倾向于更少地移动,这将导致更多的孤立点作为独立的集群。垂直内核权重,例如内核中较高点的权重,将导致内核向上移动以收敛于树的顶部 [28]。 Pollock 核的垂直高度权重 Z − Z min Z max − Z min \frac{\mathrm{Z}-\mathrm{Z}_{\min }}{\mathrm{Z}_{\max }-\mathrm{Z}_{\min }} Zmax−ZminZ−Zmin和水平高斯权重的组合可以表示如下:
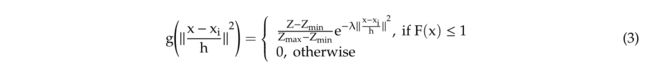
其中,对于 XY 中的正态分布权重,λ 设置为 0.5,对于仅在身高中的权重,λ 设置为 0。由于树的主导方向是沿垂直轴的,因此高度加权应有助于水平分离树。因此,它将与高斯权重和平核(无权重)进行比较,以测试其对分割的影响。
除了内核配置之外,在实现用于分割的均值偏移算法时,一种严格但耗时的做法是计算每个点的偏移。另一种做法是随机选择种子点来计算偏移。在移动过程中被内核覆盖的所有其他点将被分配与种子点相同的模式/簇。这两个实现也将进行速度和准确性评估测试。
3.2.3. Other Segmentation Methods
为了进行比较,还实施了 Dalponte 等人 [49] 的更新方法。考虑到相邻像素的垂直高度差,使用移动窗口来定位局部最大值,而不是使用分水岭,然后将其用作区域增长的“初始区域”。最终区域由凸包近似,并被视为树冠。此外,对[22]中的基准数据提出的基于点的方法进行了测试,以进行进一步比较。首先对点云进行体素化,并提出一些结构元素用于树顶检测,这些结构元素受基于树木形态特征的某些规则约束。
3.2.4. Tree Crown Parameter Extraction
四个树冠参数(位置、高度、最长树冠传播和最长树冠交叉传播)在每个研究的处理变体之后为分段树提取。可以简单地从最高点取高度 [26]。将从分割点中提取树冠位置以评估分割步骤。
识别树冠位置有两种主要策略。第一种是简单地将最高点的位置作为树的位置,这是基于树的顶部就是树所在的假设。当一棵树有明显的峰顶并且笔直直立时,这通常是正确的。第二种策略是在 2D 或 3D 中将几何形状拟合到牙冠上的点,这应该对异常值更稳健。为了识别树冠位置和传播,首先通过计算二维中所有树点周围的凸包来确定树冠底部。凸包上点的平均高度可以认为是冠高[27]。然后可以通过对这些点拟合椭圆来确定冠部位置、最长传播和最长交叉传播,其中椭圆中心是冠部位置,两个半轴代表两个冠部传播。本文将评估这两种策略,以研究冠参数提取对分割验证的影响。
3.3. Validation and Assessment Criteira
在实践中,通常通过检查分割树的位置来验证分割。这就是为什么还研究了树定位方法的影响。除了水平位置外,树木的高度也会受到分割的影响,尤其是当树冠是多层的或分割方法是 3D 时。因此,将从分段树冠中提取的树顶(由位置和高度组成)与地面测量值进行了比较。尽管分割是在点级别处理的,但验证是在对象级别进行的。
为了确定一棵树是过度分割还是分割不足,遵循 [22] 提出的标准。一般来说,如果从地面测量的树顶在 3D 中的某个范围(例如 2 m)内只有一个分段树顶,则该分段被认为是正确的(标记为匹配)。如果在此范围内有多个线段或没有线段,则树要么被过度分割,要么被分割不足。当所有被测试的树都具有 ground truth 时,例如在模拟数据中,精度、召回率和 F1-score 可以计算如下:

其中TP(True Positive)为匹配数,FP(False Positive)为评估范围内或评估范围外的过分割数,FN(False Negative)为欠分割数。
水平位置精度和高度精度由均方根误差 (RMSE) 评估,均方根误差分别根据检测到的树顶和地面测量值之间的水平和垂直距离计算得出。
4. Experiments and Results
4.1. Results of Simulated Data
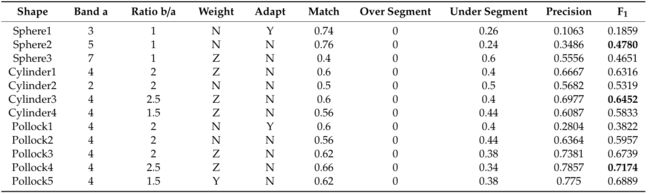
进行了大量实验以测试均值漂移方法的不同配置和参数。由于参数设置有许多可能的组合,因此报告了产生更好结果的组合。模拟数据的分割结果如表 2 所示。球核的最终 F1 分数通常低于其他两种核形状,圆柱形和波洛克形。这两个内核的最佳结果都在 b/a = 2.5、高度加权、内核不自适应、带宽 a = 4 的配置下。一般来说,Pollock 模型内核在两者匹配方面产生了更好的结果(回忆一下) 和精度,导致更高的 F1 分数。根据测试,性能最好的 Pollock 模型冠参数为 1.5,无论其他参数的设置如何,这意味着该参数只需要测试一次。
表 2. 模拟数据在各种设置下使用均值漂移的树分割结果。测试了三种内核形状:球形、圆柱形和波洛克模型,通过改变水平带宽a、垂直带宽比b/a、XY、Z或None中的权重、自适应性(Y或N).列出了较高的匹配、过分割、欠分割、精度和 F1 分数的结果。每个内核的最高 F1 分数以粗体突出显示。
在树冠是否被椭圆定位的条件下,采用表现最好的内核 Cylinder3 和 Pollock4 提取树冠参数。此外,还提供了从其他比较方法生成的片段中提取的冠参数以供比较。结果如图 4 所示,其中真正的树顶标记为红色点,检测到的树顶为蓝色。可以看出,对于大多数树木,可以在附近找到检测到的树顶,同时使用 Cylinder 内核(图 4a)和 Pollock 内核(图 4b)。但是,很少有树木没有检测到附近的树顶。主要原因是模拟树的位置是随机的,在这种情况下,树之间的间隙可能比真实树图中的小得多。树冠缠绕在一起,因此很难分开。分水岭方法产生更糟糕的结果(图 4c),因为靠近的树木聚集在一起。当两种方法的核和搜索半径都设置得较小时,可以获得更高的匹配率(召回率),但这会导致更多的错误检测,从而降低 Precision 和最终的 F1-score。
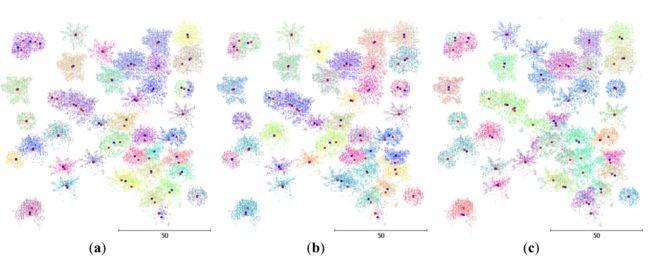
图 4. 三种方法模拟数据的分割和树顶检测结果(以米为单位):(a) Mean shift with Cylinder kernel; (b) 使用 Pollock 核的均值漂移; (c ) 标记控制的分水岭法。红色点表示真正的树顶,蓝色点表示检测到的树顶。
树冠参数提取结果如表 3 所示。当使用 Pollok 核通过顶点(而不是树冠拟合的椭圆中心)定位树冠时,实现了最高的匹配率和均值偏移精度。冠定位结果之间存在明显差异,最高点的位置更高。这是因为模拟的树模型是完全直立的,所以最高点就是真正的树顶所在的位置。树木位置的 RMSE (RMSE_xy) 的方差相当小,但树高的 RMSE (RMSE_h),当位于拟合树冠中心时,与最高点相比更大,而树冠分布的 RMSE ( RMSE_l 和 RMSE_l’) 较小。这意味着那些额外匹配的树具有精确的树高估计,但树冠分布不太精确。比较的区域增长方法显示出最好的精度和召回(匹配),因此总体 F1 分数最高。位置和高度的差异具有相似的幅度,但树冠传播要差得多,因为它仅近似于平均树冠直径,这与最长的树冠传播不同。
表 3. 模拟数据的树顶检测结果。使用椭圆中心 (Center) 或顶点 (Top),与分水岭 (Mk+WS)、区域增长 (RegGrow) 和基于体素的规则 (Vox + Relu)方法。最佳结果以粗体突出显示。检测到的树冠的位置、高度和蔓延的精度分别由 RMSE 表示

4.2. Results of Aberfoyle Forest
Aberfoyle 森林的树木分割结果如表 4 所示。请注意,地面测量的树木并未涵盖数据中的所有树木,只能确定匹配率(召回率)。因此,没有给出精度和 F1-Score。精度与错误检测有关,可以反映过度分割。 Cylinder 和 Pollock 内核都实现了最佳匹配率。 Sphere 内核产生的匹配率略低,但分割不足率也较低。 Cylinder 和 Pollock 内核在内核大小自适应高度的设置下都产生了相似的结果,无论是否对高度加权,这与模拟数据不同。所以重量对这个特定数据的影响不是很大,这可能是由于地面测量不太准确。请注意,带宽值也不同于我们对模拟数据的带宽值,因此应测试每个数据集的最佳设置。
表 4. Aberfoyle 森林在各种设置下使用均值漂移的树木分割结果。

同样,性能最佳的 Cylinder 和 Pollock 内核用于提取树冠参数。 Cylinder 和 Pollock 核的匹配率非常相似,但 Cylinder 核(图 5a)产生的树比 Pollock 核(图 5b)多得多。一些检测到的点彼此太近而不能成为单独的树,这是由于广泛的分支和分散的点造成的。分水岭方法(图 5c)产生的树木较少;可以看出,许多树梢没有被检测到。

图 5. 三种方法对 Aberfoyle 森林的分割和树顶检测结果(以米为单位):(a) Mean shift with Cylinder kernel; (b) 使用 Pollock 核的均值漂移; © 标记控制分水岭法。红色点表示真正的树顶,蓝色点表示检测到的树顶。
从数量上看,如表 5 所示,当冠位于 Cylinder 和 Pollock 内核的拟合椭圆中心时,均值偏移实现了最高匹配率,这与模拟数据相矛盾。正如模拟数据所解释的那样,如果树木是单层的、完全笔直的并且噪音较少,则最高点能更好地代表树顶。对于真实的树图,这些条件不成立,因此树冠拟合给出了更好的结果。值得注意的是,ground truth 是在树底测量的,但真实的树木通常有一定的倾斜度,因此会影响树冠位置的评估。当冠居中时,过分割率和分割不足率也较低。在均值偏移模型中,树位置的最小 RMSE (RMSE_xy) 来自树冠居中时的 Pollock 内核,这也产生了较小的树高 RMSE (RMSE_h)。这同样适用于 Cylinder 内核。与其他方法相比,图 5c 中反映的最低匹配率是从分水岭方法中获得的。此外,与 Cylinder 内核和比较方法相比,Pollock 内核生成最低的冠价差 RMSE(RMSE_l 和 RMSE_l’)。
表 5. Aberfoyle 森林的树冠检测结果。与分水岭 (Mk+WS)、区域生长 (RegGrow) 和基于体素的规则 (Vox+Relu) 相比,最好的 Cylinder 和 Pollock 内核设置经过测试以使用椭圆中心 (Center) 或顶点 (Top) 提取冠部位置规则)方法。最佳结果以粗体突出显示。检测到的树顶的位置、高度和树冠分布的准确性分别由 RMSE 与ground truth相比显示。

4.3. Results of Benchmark Data
两个基准图([22] 中的 B1 和 B2)的分割结果如表 6 所示。由于ground truth并未涵盖地块中的所有树木,因此只能确定匹配率(召回率)。因此,没有提供精度和 F1-Score。
表 6. 基准图在各种设置下使用均值偏移的树分割结果。

对于图 B1,当内核具有自适应性时,Sphere 内核产生与 Cylinder 内核相似的匹配结果。然而,当内核被设置为固定时,它们都被 Pollock 内核超越。对于图 B2,Sphere 核产生的匹配率与 Pollock 核一样好,优于 Cylinder 核。 Pollock 内核在非自适应(固定)情况下(例如对于模拟数据)对这两个图都表现最佳。请注意,为两个图生成更好结果的带宽值略有不同。尽管如此,表现最佳的 Pollock 内核具有相同的带宽、比率和适应性设置。 Z 中的加权对结果的影响不一致,因为与没有加权相比,匹配率会增加和减少。两个地块的 Pollock 模型树冠参数根据经验设置为 2。这意味着相同的参数设置可以应用于两个地块,这表明参数设置适用于其自己地块之外的更大区域。
图 6 描绘了分割结果和检测到的树顶(蓝点)以及ground truth(红点)。使用 Cylinder 和 Pollock 内核的均值偏移方法能够检测不同层的树顶。 Pollock 内核比 Cylinder 内核检测到更多的树顶,并且两个地块的匹配率更高,同时保持较低的过分割率。分水岭方法能够检测到一些优势树和大约一半的共同优势树,但不能检测到中间树或被抑制的树。它还显示出在数据边缘检测不到树木的趋势。最终检测到的树木数量甚至低于作为树木子集的地面实况。
在两种定位策略下,将树冠位置和高度与ground truth进行比较,以证明对树木分割评估的影响。最终的分割和验证结果如表 7 所示。以拟合椭圆为中心的树冠提高了两个图中两个内核的树冠匹配率。分水岭和区域生长方法的匹配率相当低,这是由于地块是多层的,而基于栅格的方法捕获较低层的能力较差。无论树冠是否局部化,均值偏移方法的位置 (RMSE_xy) 和高度 (RMSE_h) 的 RMSE 略有不同,它们通常优于两种基于栅格的方法。
表 7. 基准图的树顶检测结果。与分水岭 (Mk+WS) 和区域生长 (RegGrow) 方法相比,使用椭圆中心 (Center) 或顶点 (Top) 来测试最佳核设置以提取树冠。最佳结果以粗体突出显示。检测到的树顶的位置和高度的准确性分别通过与地面实况(RMSE_xy、RMSE_h)相比的均方根误差显示
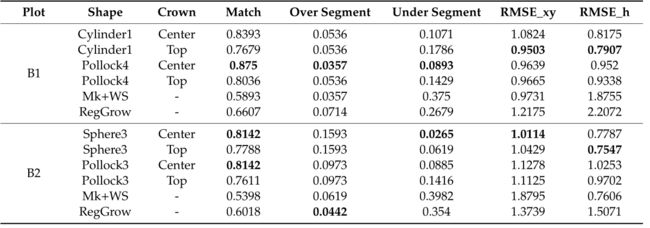
图 6. 基准图的分割和树顶检测结果(前两行:图 B1,后两行:图 B2)来自三种方法(以米为单位):(a,d)使用圆柱核的均值偏移; (b,e) 使用 Pollock 内核的均值偏移; (c,f) 标记控制的分水岭法。红色点表示真正的树顶,蓝色点表示检测到的树顶。
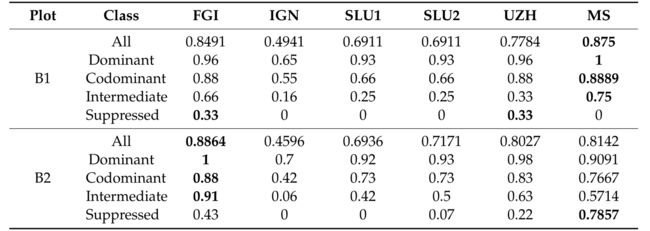
如 [22] 中所示,在基准数据上测试了更多的个体树描绘方法。与其他方法的比较如表 8 所示。均值偏移在图 B1 中表现最好,但在图 B2 中优于 FGI 方法。
表 8. 与 [22] 中的方法相比,基准图的均值偏移 (MS) 树检测结果。
4.4. Computing Costs
单个地块的计算时间并不显着,但对于具有更高激光雷达点密度的更大研究区域,计算时间可以成为选择分割方法时考虑的因素。Aberfoyle plot 用于测试分割速度,因为它具有最大的覆盖范围(106 m x 88 m),树木更多,点密度更高。记录了在每个点和随机种子点上使用固定和自适应内核进行迭代的均值偏移的计算成本。此外,还记录了分水岭和区域生长方法的计算时间以供比较。
表 9 显示了在 64 位笔记本电脑系统上使用 Intel Core i7-6700HQ CPU 在 MATLAB R2018a 中运行的均值偏移和分水岭的计算时间,以及在 R 中的区域增长。当内核设置为自适应时,时间加倍。此外,当为每个单独的点计算偏移时,成本大约高出八倍。使用不同的内核形状和权重时也存在细微差异,但与报告的设置相比可以忽略不计。选择随机种子点时,每次运行的分割结果都会有所不同。平均而言,匹配率比在每个点上计算的匹配率低 5% 到 10%。分水岭方法虽然产生最低的匹配结果,但明显快于均值漂移。区域增长方法的性能始终优于分水岭方法,并且花费的时间稍长,但仍然比均值漂移快得多。
表 9. 与分水岭和区域增长相比,当核对于随机种子点或每个点是固定的 (MS_fix) 或自适应的 (MS_adaptive) 时,均值偏移的计算时间(以秒为单位)。

5. Discussion
均值漂移算法在三个不同的机载激光雷达数据集上进行了测试。生成最佳结果的设置在数据中略有不同。然而,可以根据测试提出某些建议。
作为内核的 Pollock 模型为所有三个数据集产生了最好的结果。这证明了这样的假设,即整合冠形的内核将有助于冠分割。虽然还有一个参数需要调整,即冠形,但只需要在一个数据子集上测试一次,即使数据是混合物种。例如,对于基准数据,为同一森林中的两个地块设置了相同的树冠形状 (m = 2)。 Cylinder kernel 也为所有测试数据产生了良好的结果,类似于之前研究中展示的结果 [26,28]。有两个要测试的内核带宽参数(a 和 b),如果比率 (b/a) 是预定义的 [24],它们可以减少到一个。球形内核是最简单的,但除了基准图 B2 之外,它产生的结果最差。鉴于 Cylinder 内核并不复杂,建议首先尝试直接使用 Cylinder。 Pollock 内核将是首选,因为它可以通过稍微多一些参数调整来获得更好的结果。
使内核适应树冠大小被认为是均值漂移的有效改进。但是,是否使内核连续自适应(例如树高)取决于结果所证明的数据。考虑到连续自适应会花费两倍的计算时间,而且不一定产生更好的结果,建议使用固定内核。这种适应性是基于较高的树木具有较大的树冠尺寸的假设,这对于混合物种森林可能并非如此。一种可能的改进是使内核适应个体树冠大小而不是高度。已经尝试从异速生长近似值 [26] 或冠检测 [42] 中提取冠尺寸的信息。在这两种情况下,内核都适应了额外步骤生成的目标冠尺寸。
在某些情况下,垂直方向的加权被证明是有益的,但并非总是如此。核中较高的点具有较高的权重,这有助于核向上移动,从而使移位可以收敛到树的顶部。本文将权重归一化为[0, 1],因此最高点的权重为1,最低点的权重为0。可以设计其他类型的权重策略,例如[28]中的权重策略。水平面上的加权并没有像假设的那样改善结果,因此没有在表中列出。高斯函数对中心点附近的点(即均值)施加更大的权重,而对核边界附近的点施加更小的权重,因此如果中心区域之外的点不够多,核就不太可能发生偏移的内核。因此,在对每个特定数据实施之前,应进一步研究高度或 XY 平面的加权。
评估冠定位是因为冠顶用于验证分割结果。冠顶可以简单地由分段冠的最高点决定。但是树木的位置可能不准确,因为真实的树木通常不会完全笔直向上。另一种方法是用椭圆拟合分段的牙冠,并以椭圆中心作为牙冠位置。在这方面结果各不相同。当简单地使用最高点作为树顶时,模拟数据的结果显示出明显的优势,提供更好的分割结果和更低的 RMSE,而 Aberfoyle 数据的结果则相反,当用椭圆拟合树冠时,更好的分割结果和更低的 RMSE .这是因为第一个模拟数据是完全直立的树木,树冠几乎对称,而第二个模拟数据来自人工林,其中大多数树木自然倾斜,并且具有更多样化的树冠结构。基准数据在拟合树冠时也显示出更好的分割结果,因此建议对真实森林进行树冠检测树冠拟合。当冠位置的准确地面真实情况可用时,可以进一步评估定位精度本身,这可能很难通过现场测量或其他传感技术 [50]。
比较标记控制的分水岭方法在模拟数据上表现良好,精度特别高。同样,基于栅格的区域增长方法对模拟数据产生了最好的结果。然而,两种基于点的方法都优于两者。对于这样一个简单的单层图,基于栅格的方法有望获得良好的性能。然而,它显然难以处理更自然的数据,尤其是多层基准图。优点是它们非常快,因此对于结构不那么复杂的森林仍然值得尝试。尽管本文的重点是对 mean shift 方法本身的全面评估,但与其他基于栅格和点的方法的比较证明了这种评估的价值,因为 mean shift 能够产生有竞争力的结果。
ITD 的均值偏移分割还有其他可能的改进。例如,Pollock 模型冠参数可以根据先验知识或其他数据源的分类进行自适应。基于栅格的方法可以与均值偏移相结合,以近似估计树冠大小,然后将其输入内核。此外,可以采用分层方法,类似于 [28],其中数据在两轮中通过均值偏移进行分割。第一轮将原始数据分割成看似合理的个体树。然后使用预训练的分类器来检测过度分割和欠分割的树,这些树通过第二轮均值偏移分割进行细化,并使用从分类中得出的适当参数设置。由于这些方法需要均值漂移算法以外的额外步骤,因此它们被认为超出了本文的范围,本文重点关注方法本身的评估。
6. Conclusions
本文对机载激光雷达数据中单个树木描绘的均值漂移算法进行了全面的性能评估。考虑的三个主要因素是内核形状、内核大小适应性和内核权重。他们在三个不同的数据集、一个模拟数据、一个英国森林数据和一个来自芬兰的基准数据中进行了评估。
结果表明,用作均值漂移核的 Pollock 模型可以改进分割,尽管有一些参数需要微调。另一方面,在其他研究中常用的 Cylinder 内核可以在保持简单性的同时产生良好的结果。连续自适应策略适用于某些数据,但由于冠结构的复杂性可能不可靠,同时也很耗时。建议针对不同的数据集测试高度加权,而应谨慎进行水平加权。最后,验证结果可能会受到地面实况质量的影响,因为无论是地面调查还是其他数据源都很难确定真正的树冠位置。
通过与标记控制分水岭和区域生长这两种基于栅格的方法进行比较,证明了均值漂移的有效性,这两种方法在单层数据上表现良好,并且速度非常快。在未来的工作中,将研究通过引入额外的步骤(例如集成基于点和基于栅格的方法)来进一步改进分割工作流程。
论文链接:https://www.mdpi.com/2072-4292/11/11/1263/pdf?version=1559037802


