深度学习(2):DenseNet与图片文字识别
目的:基于深度学习算法DenseNet对图片进行文字识别,即OCR转换为文字,并将图片进行可视化输出。
一、 DenseNet算法
DenseNet的基本思路与ResNet一致,但是它建立的是前面所有层与后面层的密集连接(dense connection),它的名称也是由此而来。DenseNet的另一大特色是通过特征在channel上的连接来实现特征重用(feature reuse)。

算法具体可以参考DenseNet算法详解_@浪里小白龙的博客-CSDN博客_densenet算法详解
二、模型训练
1.导入库
!pip install tensorflow==1.15.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
import os
import json
import threading
from keras import losses
from keras.utils import plot_model
from keras.preprocessing import image
from keras.preprocessing.sequence import pad_sequences
from keras.layers.recurrent import GRU, LSTM
from keras.layers.wrappers import Bidirectional, TimeDistributed
from keras.layers.normalization import BatchNormalization
from keras.layers.convolutional import Conv2D, MaxPooling2D, ZeroPadding2D,Conv2DTranspose
from keras.optimizers import SGD, Adam
import numpy as np
from PIL import Image
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
from keras import backend as K
from keras.layers import Input, Dense, Flatten
from keras.layers.core import Reshape, Masking, Lambda, Permute, Activation,Dropout
from keras.models import Model
from keras.callbacks import EarlyStopping, ModelCheckpoint, LearningRateScheduler, TensorBoard
from imp import reload
from keras.layers.pooling import AveragePooling2D, GlobalAveragePooling2D
from keras.layers.merge import concatenate
from keras.layers.normalization import BatchNormalization
from keras.regularizers import l2
from keras.layers.wrappers import TimeDistributed ![]()
- Batch Normalization(批归一化)为了解决在训练过程中,中间层数据分布发生改变的情况。在网络的每一层输入的时候,又插入了一个归一化层,也就是先做一个归一化处理,然后再进入网络的下一层。具体原理参考Batch Normalization(BN)超详细解析_越前浩波的博客-CSDN博客_batch normalization
- TimeDistributed顾名思义就是使用时间序列来进行一系列张量操作。怎样设计一个解决序列预测问题的多对一LSTM网络,采用TimeDistributed层。具体可以看博客如何在长短期记忆(LSTM)网络中利用TimeDistributed层---python语言_CONQUERczy的博客-CSDN博客_lstm timedistributed
- SGD(随机梯度下降)的学习原理很简单就是选择一条数据,就训练一条数据,然后修改权值。Adam(自适应动量优化)基于动量和RMSProp的微调版本,该方法是目前深度学习中最流行的优化方法,在默认情况尽量使用亚当作为参数的更新方式。具体原理参考博客SGD和Adam(转载)_Jeu的博客-CSDN博客_sgd和adam
- Reshape:参数:target_shape:目标shape,为整数的tuple,不包含样本数目的维度(batch大小)。参考Keras文档学习05.常用的网络层介绍_达瓦里氏吨吨吨的博客-CSDN博客
- Masking:使用给定的值对输入的序列信号进行“屏蔽”,用以定位需要跳过的时间步
- Permute层将输入的维度按照给定模式进行重排,例如,当需要将RNN和CNN网络连接时,可能会用到该层。
- Lambda作用:本函数用以对上一层的输出施以任何Theano/TensorFlow表达式,将任意表达式封装为 Layer 对象。
2.准备数据
#准备数据,从OSS中获取数据并解压到当前目录:
import oss2
access_key_id = os.getenv('OSS_TEST_ACCESS_KEY_ID', 'LTAI4G1MuHTUeNrKdQEPnbph')
access_key_secret = os.getenv('OSS_TEST_ACCESS_KEY_SECRET', 'm1ILSoVqcPUxFFDqer4tKDxDkoP1ji')
bucket_name = os.getenv('OSS_TEST_BUCKET', 'mldemo')
endpoint = os.getenv('OSS_TEST_ENDPOINT', 'https://oss-cn-shanghai.aliyuncs.com')
# 创建Bucket对象,所有Object相关的接口都可以通过Bucket对象来进行
bucket = oss2.Bucket(oss2.Auth(access_key_id, access_key_secret), endpoint, bucket_name)
# 下载到本地文件
bucket.get_object_to_file('data/c12/image_ocr_data.zip', 'image_ocr_data.zip') ![]()
#解压缩文件
!unzip -o -q image_ocr_data.zip
3.定义工具函数
# 获取Tensorflow中Session
def get_session(gpu_fraction=1.0):
num_threads = os.environ.get('OMP_NUM_THREADS')
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=gpu_fraction)
if num_threads:
return tf.Session(config=tf.ConfigProto(
gpu_options=gpu_options, intra_op_parallelism_threads=num_threads))
else:
return tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
# 读取文件方法
def readfile(filename):
res = []
with open(filename, 'r') as f:
lines = f.readlines()
for i in lines:
res.append(i.strip())
dic = {}
for i in res:
p = i.split(' ')
dic[p[0]] = p[1:]
return dic
# 随机化选择图片
class random_uniform_num():
"""
均匀随机,确保每轮每个只出现一次
"""
def __init__(self, total):
self.total = total
self.range = [i for i in range(total)]
np.random.shuffle(self.range)
self.index = 0
def get(self, batchsize):
r_n=[]
if(self.index + batchsize > self.total):
r_n_1 = self.range[self.index:self.total]
np.random.shuffle(self.range)
self.index = (self.index + batchsize) - self.total
r_n_2 = self.range[0:self.index]
r_n.extend(r_n_1)
r_n.extend(r_n_2)
else:
r_n = self.range[self.index : self.index + batchsize]
self.index = self.index + batchsize
return r_n4.训练图片探索
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
import os
import numpy as np
import matplotlib.pyplot as plt
import random
%matplotlib inline
# 从训练图片集中随机选择18张图片的说明
directory = "./image_ocr_data/train_imgs/samples_images/"
images = random.choices(os.listdir(directory), k=18)
fig = plt.figure(figsize=(60, 10))
# 3列
columns = 6
# 3行
rows = 3
# 显示18张图片及对应图片说明
for x, i in enumerate(images):
path = os.path.join(directory,i)
img = plt.imread(path)
fig.add_subplot(rows, columns, x+1)
plt.imshow(img)
plt.show()
5.数据生成器
# 训练数据生成器,用于读取训练、测试集样本
def gen(data_file, image_path, batchsize=128, maxlabellength=10, imagesize=(32, 280)):
image_label = readfile(data_file)
_imagefile = [i for i, j in image_label.items()]
x = np.zeros((batchsize, imagesize[0], imagesize[1], 1), dtype=np.float)
labels = np.ones([batchsize, maxlabellength]) * 10000
input_length = np.zeros([batchsize, 1])
label_length = np.zeros([batchsize, 1])
r_n = random_uniform_num(len(_imagefile))
_imagefile = np.array(_imagefile)
while 1:
shufimagefile = _imagefile[r_n.get(batchsize)]
for i, j in enumerate(shufimagefile):
img1 = Image.open(os.path.join(image_path, j)).convert('L')
# 图片归一化处理
img = np.array(img1, 'f') / 255.0 - 0.5
x[i] = np.expand_dims(img, axis=2)
str = image_label[j]
label_length[i] = len(str)
input_length[i] = imagesize[1] // 8
labels[i, :len(str)] = [int(k) for k in str]
inputs = {'the_input': x,
'the_labels': labels,
'input_length': input_length,
'label_length': label_length,
}
outputs = {'ctc': np.zeros([batchsize])}
#输出已经构建好的样本输入和输出
yield (inputs, outputs)6.DenseNet网络结构定义
# 定义卷积块
def conv_block(input, growth_rate, dropout_rate=None, weight_decay=1e-4):
x = BatchNormalization(axis=-1, epsilon=1.1e-5)(input)
x = Activation('relu')(x)
x = Conv2D(growth_rate, (3,3), kernel_initializer='he_normal', padding='same')(x)
if(dropout_rate):
x = Dropout(dropout_rate)(x)
return x
# 定义dense块
def dense_block(x, nb_layers, nb_filter, growth_rate, droput_rate=0.2, weight_decay=1e-4):
# 定义dense块中多个卷积层
for i in range(nb_layers):
cb = conv_block(x, growth_rate, droput_rate, weight_decay)
# 连接卷积层
x = concatenate([x, cb], axis=-1)
nb_filter += growth_rate
return x, nb_filter
# 定义块直连
def transition_block(input, nb_filter, dropout_rate=None, pooltype=1, weight_decay=1e-4):
x = BatchNormalization(axis=-1, epsilon=1.1e-5)(input)
x = Activation('relu')(x)
x = Conv2D(nb_filter, (1, 1), kernel_initializer='he_normal', padding='same', use_bias=False,
kernel_regularizer=l2(weight_decay))(x)
if(dropout_rate):
x = Dropout(dropout_rate)(x)
if(pooltype == 2):
x = AveragePooling2D((2, 2), strides=(2, 2))(x)
elif(pooltype == 1):
x = ZeroPadding2D(padding = (0, 1))(x)
x = AveragePooling2D((2, 2), strides=(2, 1))(x)
elif(pooltype == 3):
x = AveragePooling2D((2, 2), strides=(2, 1))(x)
return x, nb_filter
# 定义densenet网络
def dense_cnn(input, nclass):
_dropout_rate = 0.2
_weight_decay = 1e-4
_nb_filter = 64
# conv 64 5*5 s=2
x = Conv2D(_nb_filter, (5, 5), strides=(2, 2), kernel_initializer='he_normal', padding='same',
use_bias=False, kernel_regularizer=l2(_weight_decay))(input)
# 64 + 8 * 8 = 128
x, _nb_filter = dense_block(x, 8, _nb_filter, 8, None, _weight_decay)
# 128
x, _nb_filter = transition_block(x, 128, _dropout_rate, 2, _weight_decay)
# 128 + 8 * 8 = 192
x, _nb_filter = dense_block(x, 8, _nb_filter, 8, None, _weight_decay)
# 192 -> 128
x, _nb_filter = transition_block(x, 128, _dropout_rate, 2, _weight_decay)
# 128 + 8 * 8 = 192
x, _nb_filter = dense_block(x, 8, _nb_filter, 8, None, _weight_decay)
x = BatchNormalization(axis=-1, epsilon=1.1e-5)(x)
x = Activation('relu')(x)
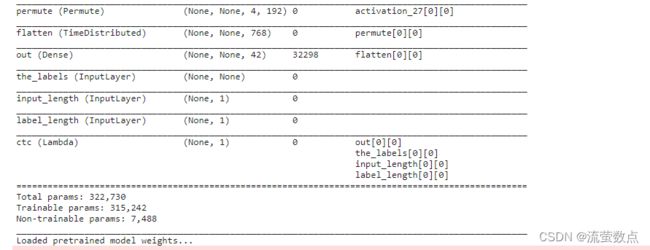
x = Permute((2, 1, 3), name='permute')(x)
x = TimeDistributed(Flatten(), name='flatten')(x)
y_pred = Dense(nclass, name='out', activation='softmax')(x)
return y_pred
7.损失函数
模型的损失函数采用ctc(Connectionist Temporal Classification),其定义代码如下:
# 损失函数定义
def ctc_lambda_func(args):
y_pred, labels, input_length, label_length = args
return K.ctc_batch_cost(labels, y_pred, input_length, label_length)8.模型定义
# 模型定义
def get_model(img_h, nclass):
input = Input(shape=(img_h, None, 1), name='the_input')
# 网络结构定义
y_pred = dense_cnn(input, nclass)
# 输入层定义
labels = Input(name='the_labels', shape=[None], dtype='float32')
input_length = Input(name='input_length', shape=[1], dtype='int64')
label_length = Input(name='label_length', shape=[1], dtype='int64')
# 损失函数定义
loss_out = Lambda(ctc_lambda_func, output_shape=(1,), name='ctc')([y_pred, labels, input_length, label_length])
# 模型定义
model = Model(inputs=[input, labels, input_length, label_length], outputs=loss_out)
# 模型编译
model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer='adam', metrics=['accuracy'])
return model9. 模型训练方法定义
def start_train(train_index_file_path,train_img_root_dir,test_index_file_path,test_img_root_dir,model_output_dir="./image_ocr_data/models",train_epochs=10):
#图片大小定义
img_height = 32
img_width = 200
#训练批大小定义
batch_size = 32
#输出标签类别
char_set = open('./image_ocr_data/labels.txt', 'r', encoding='utf-8').readlines()
char_set = ''.join([ch.strip('\n') for ch in char_set][1:] + ['卍'])
num_class = len(char_set) + 2
# 加载定义模型
K.set_session(get_session())
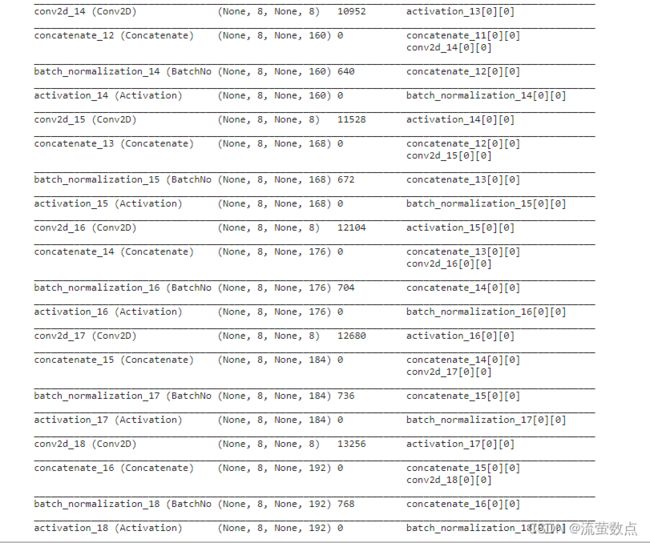
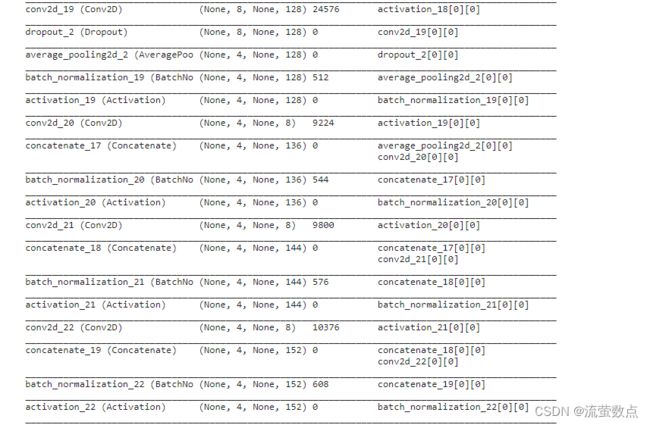
model = get_model(img_height, num_class)
model.summary()
# 如果有预训练模型,提前加载
modelPath = './image_ocr_data/models/pretrain_model.h5'
if os.path.exists(modelPath):
print("Loaded pretrained model weights...")
model.load_weights(modelPath)
# 训练数据读取器
train_loader = gen(train_index_file_path, train_img_root_dir, batchsize=batch_size, maxlabellength=num_class,
imagesize=(img_height, img_width))
# 测试数据加载器
test_loader = gen(test_index_file_path, test_img_root_dir, batchsize=batch_size, maxlabellength=num_class,
imagesize=(img_height, img_width))
# 定义模型保存位置
model_save_path = os.path.join(model_output_dir,'weights_model-{epoch:02d}-{val_loss:.2f}.h5')
checkpoint = ModelCheckpoint(filepath=model_save_path, monitor='val_loss',
save_best_only=True, save_weights_only=True)
# 定义学习率更新策略
lr_schedule = lambda epoch: 0.005 * 0.1 ** epoch
learning_rate = np.array([lr_schedule(i) for i in range(20)])
changelr = LearningRateScheduler(lambda epoch: float(learning_rate[epoch]))
# 定义提前终止策略
earlystop = EarlyStopping(monitor='val_loss', patience=4, verbose=1)
# 训练集样本数量
train_num_lines = sum(1 for line in open(train_index_file_path))
# 测试集样本数量
test_num_lines = sum(1 for line in open(test_index_file_path))
#模型训练
model.fit_generator(train_loader,
steps_per_epoch=train_num_lines // batch_size,
epochs=int(train_epochs),
initial_epoch=0,
validation_data=test_loader,
validation_steps=test_num_lines // batch_size,
callbacks=[checkpoint, earlystop, changelr])10.模型训练
# 模型训练迭代次数1次
# 模型训练结果保存在models目录下
start_train("./image_ocr_data/data_3_train.txt","./image_ocr_data/train_imgs"
,"./image_ocr_data/data_3_test.txt","./image_ocr_data/test_imgs","./image_ocr_data/models",1)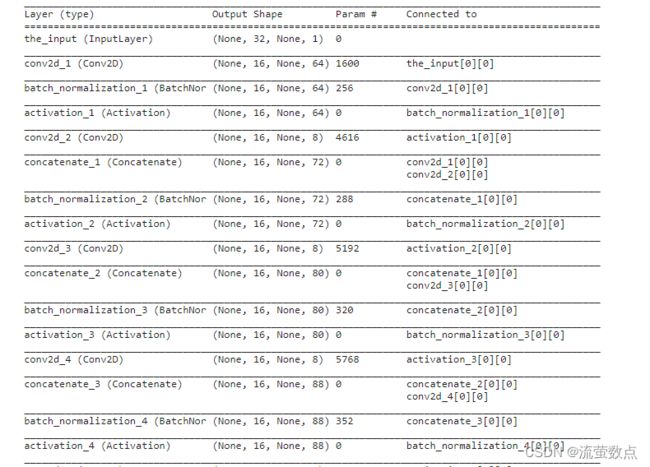



![]()
三、模型使用
1.导入库
- ImageOps模块包含了一些“ready-made”的图像处理操作。
- 通过from keras import backend as K方式导入后端模块,一旦引用了 keras 的 backed, 那么大多数你需要的张量操作都可以通过统一的Keras后端接口完成,不关心具体执行这些操作的是Theano还是TensorFlow。
import os
import numpy as np
from imp import reload
from PIL import Image, ImageOps
import matplotlib.pyplot as plt
from keras.layers import Input
from keras.models import Model
# import cv2
import random
from keras import backend as K
from datetime import datetime
from tensorflow import Graph, Session
from keras.models import load_model2.加载标签信息
这些标签是识别结果的词典,即预测结果中总共的类别数量,代码如下:
alphabet = u""" 0123456789.-ABCDEFGHIJKLMNOPQRSTUVWXYZ/"""
characters_abc = alphabet[:]
characters_abc = characters_abc[1:] + u'卍'
nclass_abc = len(characters_abc) + 2
print("abc class count:", nclass_abc)![]()
3.定义模型加载的方法
使用Tensorflow中的Graph组件加载模型,并计算模型加载的总耗时长,代码如下:
# 模型加载
def model_abc():
graph2 = Graph()
with graph2.as_default():
session2 = Session(graph=graph2)
with session2.as_default():
print('loading abc model...', datetime.now())
model_path = './image_ocr_data/models/pretrain_model.h5'
# 定义模型输入
input = Input(shape=(32, None, 1), name='the_input')
y_pred = dense_cnn(input, nclass_abc)
basemodel = Model(inputs=input, outputs=y_pred)
# 模型存放位置,如果存在则加载模型
modelPath = os.path.join(os.getcwd(), model_path)
if os.path.exists(modelPath):
basemodel.load_weights(modelPath)
else:
print("error: abc model not exists!")
print("load abc complete", datetime.now())
return basemodel, session2, graph2# 将预测结果转化为文字内容
def labels_to_text(labels):
ret = []
for c in labels:
if c == len(alphabet):
ret.append("")
else:
ret.append(alphabet[c])
return "".join(ret)# 执行预测并将结果转化为文本内容
def decode_predict_ctc(out, top_paths=1):
results = []
beam_width = 3
if beam_width < top_paths:
beam_width = top_paths
for i in range(top_paths):
lables = K.get_value(K.ctc_decode(out, input_length=np.ones(out.shape[0]) * out.shape[1],
greedy=False, beam_width=beam_width, top_paths=top_paths)[0][i])[0]
# 执行文字转化
text = self.labels_to_text(lables)
results.append(text)
return results
# 基于加载的模型进行图片文字识别
def predict(model_abc,session_abc, graph_abc, imgX):
with graph_abc.as_default():
with session_abc.as_default():
y_pred = model_abc.predict(imgX)
char_list = []
y_pred = y_pred[:, :, :]
pred_text = y_pred.argmax(axis=2)[0]
# 对识别结果进行后续处理
for i in range(len(pred_text)):
if pred_text[i] != nclass_abc - 1 and ((not (i > 0 and pred_text[i] == pred_text[i - 1])) or (i > 1 and pred_text[i] == pred_text[i - 2])):
char_list.append(characters_abc[pred_text[i] - 1])
# 将结果合并
result = ''.join(char_list)
return result4.加载模型
basemodel, session2, graph2 = model_abc()
5.调用模型进行文字识别
# 定义输入图片大小
MAX_WIDTH = 200
HEIGHT = 32
#从测试集中随选图识别
directory = "./image_ocr_data/test_imgs/samples_images/"
images = random.choices(os.listdir(directory), k=6)
# 构造多图显示
fig = plt.figure(figsize=(30, 10))
# 3列
columns = 3
# 2行
rows = 2
for x, i in enumerate(images):
path = os.path.join(directory,i)
img = plt.imread(path)
fig.add_subplot(rows, columns, x+1)
# 图片预处理
image = np.array(Image.open(path).convert('RGB'))
image = Image.fromarray(image).convert('L')
# 图片归一化
img_array = np.array(image).astype(np.float32) / 255.0 - 0.5
# 图片大小转化
imgX = img_array.reshape([1, HEIGHT, MAX_WIDTH, 1])
# 模型识别文字
text = predict(basemodel, session2, graph2,imgX)
# 识别结果可视化
plt.title(text)
plt.imshow(img)