[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)
论文1: TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
年份:2020-10-26
论文链接: https://aclanthology.org/2020.coling-main.138.pdf
https://drive.google.com/file/d/1UAIVkuUgs122k02Ijln-AtaX2mHz70N-/view
https://drive.google.com/file/d/1iwFfXZDjwEz1kBK8z1To_YBWhfyswzYU/view
论文代码:https://github.com/131250208/TPlinker-joint-extraction
相关背景:
问题任务:Extracting entities and relations from unstructured texts
传统方法:Traditional pipelined approaches first extract entity mentions and then classify the relation types between candidate entity pairs.
传统方法问题:忽略了实体与关系之间的关系;
最近方法:实体与关系一起抽取的联合模型;
最近方法解决不了的问题:对于overlapping解决不了
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第1张图片](http://img.e-com-net.com/image/info8/752b366866a04ecc83b17750ae6eafda.jpg)
针对overlapping问题的解决方法:Decoder-based models 与 Decomposition-based models
overlapping方法的问题:exposure bias,训练与预测不一样。
综上:提出了TPLinker, 把联合抽取转换成一个Token对的链接问题。
Tagging
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第2张图片](http://img.e-com-net.com/image/info8/aab3cb1dd9ec477ebfb3a8fcf07c1148.jpg)
model
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第3张图片](http://img.e-com-net.com/image/info8/0e9fee56134c464c83c071093aa9bfc7.jpg)
句子中的词经过编码器编码后,直接拼接在一起,然后就是Handshaking Kernel:
![]()
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第4张图片](http://img.e-com-net.com/image/info8/87a56a047afb4eb4aceb97a7e1200456.jpg)
** 解码说明:**
EH-to-ET: entity head to entity tail
SH-to-OH : subject head to object head
ST-to-OT :subject tail to object tail
例子:
实体范畴:
(“New”, “York”), (“New”, “City”) and (“De”, “Blasio”) 在EH-to-ET被标注为1,表示实体:“New York”, “New York City”, and “De Blasio”;
关系范畴:
(“New”,“De”)在SH-to-OH中与对于关系“mayor”中被标记为1,表示“mayor”的Subject以"NEW"开始,Object是以“De”开始的。
(“City”, “Blasio”)的在ST-to-OT中在关系“mayor”中标注为1,表示“mayor”的Subject以“City”结束,Object是以"Blasion"结束。
综上实体范畴与关系范畴可得三元组:(“New York City”, mayor, “De Blasio”)
解码步骤:
第一步,根据EH-to-ET抽取出所以实体,并采用词典D来保存;
第二步,对于每个关系,首先处理了ST-to-OT序列的内容,然后处理SH-to-OH的内容;
第三步,迭代所以候选实体对判断E的tail位置。
损失函数

实验结果
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第5张图片](http://img.e-com-net.com/image/info8/0811a36a6b8140a5afe34e62c2109259.jpg)
结果还是很不错的,这里重点是提出一个新的标注方式,把实体与关系转成了token对来解决了。对于Handshaking Kernel里面,要两两组合,如果对于文本比较长,效率是一个问题。故目前来看,想法还是很新颖的,应用上还得优化一下。
论文2:PRGC: Potential Relation and Global Correspondence Based Joint Relational Triple Extraction
年份:2021-06-17
相关背景:提出的模型与之前听端到端的模型有点不一样,这个是从关系抽取开始的。目的是想把冗余的关系去掉。
基本概念
Single Entity Overlap (SEO) 单一实体重叠
Entity Pair Overlap (EPO) 实体对重叠 :即一个实体对之间存在着多种关系
Subject Object Overlap (SOO) 主客体重叠 :既是主体,又是客体
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第6张图片](http://img.e-com-net.com/image/info8/236b9f80004e4a85b71e2cad2718ba94.jpg)
模型
关系判断(Relation Judgement):(橙色虚线)Potential Relation Prediction
实体提取(Entity Extraction):(蓝色虚线)Relation-Specific Sequence Taggers
主宾语对齐(Subject-object Alignment):(绿色虚线)Global Correspondence
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第7张图片](http://img.e-com-net.com/image/info8/eb6de2f2564c4066853284c1c3e994a9.jpg)
Potential Relation Prediction
++ 对应上图的Orage box ++
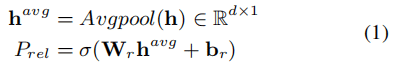
*Avgpool: 表示平均池化操作。P计算出的内容是所有的关系分布。*这一步把模型看成是多标签二进制分类。如果概率超过某个阈值λ,则为对应关系分配标签1,否则将对应的关系标签置为0;接下来只需要将特定于关系的序列标签应用于预测关系,而不是预测全部关系。
Relation-Specifific Sequence Tagging
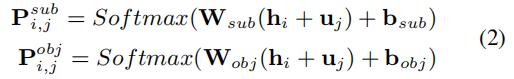
这里是对某个字符,判断它的BIO标注。
Global Correspondence
![]()
这部分主要是用来计算主体与客体是否有关系;
矩阵的分数。这个跟TPLinker那个还是比较像的。不过这个里面的编码求了平均值。同样的一个问题:如果句子长度太长最后subject-object的对齐工作消耗的空间资源会很大。
损失函数(三个)
关系的损失函数,在给定关系下的序列标注的预测,
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第8张图片](http://img.e-com-net.com/image/info8/bc76f716f83446dd86fba7cf5882ed32.png)
综上的模型总结:相对于流行的模型来看,这里加入了句子中的关系分类,目的是想过滤出潜在关系,然后,在过滤出的关系去找实体,这里是基于给定关系之后来判断这个实体是否是三元组中的sub或obj. 看到最后的损失函数,计算量还是比较大的。PRGC预测过程:首先预测潜在关系子集( potential relations)和包含所有主客体之间的对应分数的全局矩阵(global matrix); 然后序列标记(sequence tagging),抽取潜在关系的主体和客体;最后列举所有实体候选对,全局对应矩阵( global correspondence matrix)进行过滤。
实验结果
主要结果
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第9张图片](http://img.e-com-net.com/image/info8/8e4d6627d5c54798b4532fbbfea2006d.jpg)
模型各个模块的贡献情况
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第10张图片](http://img.e-com-net.com/image/info8/947faf09227c461998c1a984dfcf7d2c.png)
论文3:Unified Named Entity Recognition as Word-Word Relation Classification
[1] J. Li等, 《Unified Named Entity Recognition as Word-Word Relation Classification》, arXiv, arXiv:2112.10070, 12月 2021. doi: 10.48550/arXiv.2112.10070.
年份:2021-12-19
动机:
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第11张图片](http://img.e-com-net.com/image/info8/0626cc995920434481ed404bda60f931.png)
W2NER scheme:
主要是引入两个标注来使用NER统一化:Next-Neighboring-Word(NNW),Tail-Head-Word-(THW-*).
NNW: 实体中两个词是否相邻;
THW-*:标记实体的边界与类型;
例子:Figure 1 (b)中,NNW表示相邻,可以生成{aching in, in legs, in shoulders, aching in legs, aching in shoulders};
THW-S表示,实体Tail到Head的连接,可以得到上面的候选中的{aching in legs, aching in shoulders};这个都是S类型的实体。
模型:
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第12张图片](http://img.e-com-net.com/image/info8/423dbc8ea10549949f0183e91dac8959.jpg)
Encoder Layer
论文提到两种方法:BERT , Bi-LSTM
Convolution Layer
卷积层包括三个模块:
1.Conditional Layer Normalization; 用来生成词对表格。
2. BERT-Style Grid Representation Build-Up; 丰富单词对表格表示;
3. Multi-Granularity Dilated Convolution,用来捕捉距离与远距离词相关性的;
Conditional Layer Normalization
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第13张图片](http://img.e-com-net.com/image/info8/e2723c60d88f491f9bce73e4266eacec.png)
BERT-Style Grid Representation Build-Up
![]()
V: 词信息;
Ed: 每个词对的关系位置信息;
Et: 表示区分词关系网格上下三角形区域的区域信息。
Multi-Granularity Dilated Convolution
空洞卷积(Dilated Convolution)中文名也叫膨胀卷积或者扩张卷积,英文名也叫Atrous Convolution
空洞卷积最初的提出是为了解决图像分割的问题而提出的,常见的图像分割算法通常使用池化层和卷积层来增加感受野(Receptive Filed),同时也缩小了特征图尺寸(resolution),然后再利用上采样还原图像尺寸,特征图缩小再放大的过程造成了精度上的损失,因此需要一种操作可以在增加感受野的同时保持特征图的尺寸不变,从而代替下采样和上采样操作,在这种需求下,空洞卷积就诞生了
这里应用了multiple 2-dimensional dilated convolutions (DConv), l取1,2,3.
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第14张图片](http://img.e-com-net.com/image/info8/6ea1cd8e4d6c4a36bcba4e5973af579a.png)
Co-predictor layer
Biaffifine Predictor
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第15张图片](http://img.e-com-net.com/image/info8/460d03f5dd004098a669501e6af7850d.png)
MLP Predictor
![]()
这个Q是卷积得到结果。
![]()
这个体现了残差的形式。
损失函数

decodeing
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第16张图片](http://img.e-com-net.com/image/info8/e3f71dfdf0794f7399b67d734c211584.png)
预测把词及词关系看成有向词图。解码就是使用NNW在词图中找到确定的词路径,THW辅助地去辨别有用的实体,并加上类型。
在示例(a)中,两条路径“A→B”和“D→E”对应于Flat实体,而THW关系表示它们的边界和类型;
在示例(b)中,如果没有THW关系,我们只能找到一条路径,因此缺少“BC”。相比之下,借助THW关系,很容易确定“BC”是嵌套在“ABC”中的,这说明了THW关系的必要性。
案例©显示了如何识别不连续的实体。可以找到两条路径“A→B→C”和“A→B→D”,并且NNW关系有助于连接不连续的“AB”和“D”.
案例(d)中,通过有向词图,采用NNW与THW可以得到“ACD”,“BCE”两实体。
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第17张图片](http://img.e-com-net.com/image/info8/cf362a22faed427da460be3962a8c877.png)
各个模块的作用。
实验
正常NER
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第18张图片](http://img.e-com-net.com/image/info8/e7ee4454c9b141b085a502aeec990a6a.jpg)
重叠NER
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第19张图片](http://img.e-com-net.com/image/info8/a751cbb371ad42aaa850e43cbee3baf1.jpg)
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第20张图片](http://img.e-com-net.com/image/info8/b8fd1e5a97dc4f988264ee2bd5c90b81.png)
非连续NER
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第21张图片](http://img.e-com-net.com/image/info8/c0f056a0858c4f33bad291cef9a61e91.jpg)
一个模型解决三种典型的NER,效果并不比较各种模型差,可以考虑尝试。
补充一个ENR种类图与典型的流派:
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第22张图片](http://img.e-com-net.com/image/info8/6314e4cf03bc42a0a4ca97c4157453fc.jpg)
代码相关
输入数据格式—对于英文,包括了sentence与ner两个信息。
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第23张图片](http://img.e-com-net.com/image/info8/9b6adeb7654c4857a1b30dd6e4c18d88.jpg)
对于中文:不但包括了sentence与ner信息,还包含了word的分词信息
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第24张图片](http://img.e-com-net.com/image/info8/3d2f4f2600814a848cc5eddac6b413d0.jpg)
数据预处理及数据集-- process_bert函数与RelationDataset类:
这里面还一个是piece的概念,它表示比word更小的分割,这个在英文单词上会比较常一些。对于中文如果用单字分割了,不会有这种piece分开了。
句子:[‘高’, ‘勇’, ‘:’, ‘男’, ‘,’, ‘中’, ‘国’, ‘国’, ‘籍’, ‘,’, ‘无’, ‘境’, ‘外’, ‘居’, ‘留’, ‘权’, ‘,’]
bert_input:[ 101 7770 1235 8038 4511 8024 704 1744 1744 5093 8024 3187 1862 1912 2233 4522 3326 8024 102]
grid_labels:
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第25张图片](http://img.e-com-net.com/image/info8/9f55e59e9e864d71a7b13b348e63be04.jpg)
对于这个数据的解释,要查看下面一个变量:
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第26张图片](http://img.e-com-net.com/image/info8/99b4c62250bf4304af397ac74f0f0b5c.jpg)
1表地后继表示即论文中的NNW,2表示名字,3表示国家,以此类推的数字表示。
dist_inputs:距离矩阵
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第27张图片](http://img.e-com-net.com/image/info8/e9047b2d8cab485cac5611eb6b706854.jpg)
处理器返回的结果为:bert_inputs, grid_labels, grid_mask2d, pieces2word, dist_inputs, sent_length, entity_text
毫无疑问,数据集(RelationDataset)中也采用了这七个字段:
class RelationDataset(Dataset):
def __init__(self, bert_inputs, grid_labels, grid_mask2d, pieces2word, dist_inputs, sent_length, entity_text):
self.bert_inputs = bert_inputs
self.grid_labels = grid_labels
self.grid_mask2d = grid_mask2d
self.pieces2word = pieces2word
self.dist_inputs = dist_inputs
self.sent_length = sent_length
self.entity_text = entity_text
def __getitem__(self, item):
return torch.LongTensor(self.bert_inputs[item]), \
torch.LongTensor(self.grid_labels[item]), \
torch.LongTensor(self.grid_mask2d[item]), \
torch.LongTensor(self.pieces2word[item]), \
torch.LongTensor(self.dist_inputs[item]), \
self.sent_length[item], \
self.entity_text[item]
def __len__(self):
return len(self.bert_inputs)
模型:
第一个内容,bert编码器:
self.bert = AutoModel.from_pretrained(config.bert_name, cache_dir="./cache/", output_hidden_states=True)
这里做了一个是否选择bert后面4层的开关:
if self.use_bert_last_4_layers:
bert_embs = torch.stack(bert_embs[2][-4:], dim=-1).mean(-1)
else:
bert_embs = bert_embs[0]
第二个内容:把piece最大池化成word表达:
# 处理pieces, 采用最大池化把pieces变成词表达
length = pieces2word.size(1)
min_value = torch.min(bert_embs).item()
_bert_embs = bert_embs.unsqueeze(1).expand(-1, length, -1, -1)
_bert_embs = torch.masked_fill(_bert_embs, pieces2word.eq(0).unsqueeze(-1), min_value)
word_reps, _ = torch.max(_bert_embs, dim=2)
word_reps = self.dropout(word_reps)
第三个内容: 词编码-bi_LSTM
packed_embs = pack_padded_sequence(word_reps, sent_length.cpu(), batch_first=True, enforce_sorted=False)
packed_outs, (hidden, _) = self.encoder(packed_embs)
word_reps, _ = pad_packed_sequence(packed_outs, batch_first=True, total_length=sent_length.max())
**附:pack_padded_sequence与pad_packed_sequence。**在LSTM中,因为pad会影响模型的效果,所以要把pad删除再传进模型。pack_padded_sequence把pad的内容去掉,输入为
(B×T×* )的格式。当LSTM处理完之后,进行一次pad_packed_sequence,然后再把pad加回去了。
第四个内容—内容信息(内容信息,位置信息,区域信息):
cln是一个layerNorm层
self.cln = LayerNorm(config.lstm_hid_size, config.lstm_hid_size, conditional=True)
cln编码后:
cln = self.cln(word_reps.unsqueeze(2), word_reps)
# 位置信息
dis_emb = self.dis_embs(dist_inputs)
# 矩阵的区域信息
tril_mask = torch.tril(grid_mask2d.clone().long())
reg_inputs = tril_mask + grid_mask2d.clone().long()
reg_emb = self.reg_embs(reg_inputs)
==附:torch.tril:==pytorch中tril函数主要用于返回一个矩阵主对角线以下的下三角矩阵,其它元素全部为0 00。当输入是一个多维张量时,返回的是同等维度的张量并且最后两个维度的下三角矩阵的。
第五点内容卷积
conv_inputs = torch.cat([dis_emb, reg_emb, cln], dim=-1)
conv_inputs = torch.masked_fill(conv_inputs, grid_mask2d.eq(0).unsqueeze(-1), 0.0)
conv_outputs = self.convLayer(conv_inputs)
conv_outputs = torch.masked_fill(conv_outputs, grid_mask2d.eq(0).unsqueeze(-1), 0.0)
第六点预测器–CoPredictor
class CoPredictor(nn.Module):
def __init__(self, cls_num, hid_size, biaffine_size, channels, ffnn_hid_size, dropout=0):
super().__init__()
self.mlp1 = MLP(n_in=hid_size, n_out=biaffine_size, dropout=dropout)
self.mlp2 = MLP(n_in=hid_size, n_out=biaffine_size, dropout=dropout)
self.biaffine = Biaffine(n_in=biaffine_size, n_out=cls_num, bias_x=True, bias_y=True)
self.mlp_rel = MLP(channels, ffnn_hid_size, dropout=dropout)
self.linear = nn.Linear(ffnn_hid_size, cls_num)
self.dropout = nn.Dropout(dropout)
def forward(self, x, y, z):
h = self.dropout(self.mlp1(x))
t = self.dropout(self.mlp2(y))
o1 = self.biaffine(h, t)
z = self.dropout(self.mlp_rel(z))
o2 = self.linear(z)
return o1 + o2
附:掩码操作masked_fill,用value填充tensor中与mask中值为1位置相对应的元素。mask的形状必须与要填充的tensor形状一致。
再看一下Biaffine:
class Biaffine(nn.Module):
def __init__(self, n_in, n_out=1, bias_x=True, bias_y=True):
super(Biaffine, self).__init__()
self.n_in = n_in
self.n_out = n_out
self.bias_x = bias_x
self.bias_y = bias_y
weight = torch.zeros((n_out, n_in + int(bias_x), n_in + int(bias_y)))
nn.init.xavier_normal_(weight)
self.weight = nn.Parameter(weight, requires_grad=True)
def forward(self, x, y):
if self.bias_x:
x = torch.cat((x, torch.ones_like(x[..., :1])), -1)
if self.bias_y:
y = torch.cat((y, torch.ones_like(y[..., :1])), -1)
# [batch_size, n_out, seq_len, seq_len]
s = torch.einsum('bxi,oij,byj->boxy', x, self.weight, y)
# remove dim 1 if n_out == 1
s = s.permute(0, 2, 3, 1)
return s
这里最有趣的就是对einsum(爱因斯坦求和)进行理解,三个变量的规则就在其中了。论文中的biaffine公式也有描述了。
爱因斯坦求和是一种对求和公式简洁高效的记法,其原则是当变量下标重复出现时,即可省略繁琐的求和符号。
其中, i,j为自由指标, k为哑指标.
哑指标: 在表达式的某项中, 若某指标重复出现两次, 则表示要把该项指标在取值范围内遍历求和. 该重复指标称为哑指标或简称哑标. (未被求和的指标称为自由指标)
自由指标: 在表达式的某项中, 若某指标只出现一次, 若在取值范围内轮流取该指标的任一值时, 关系式恒成立. 该指标称为自由指标.
einsum的本质是嵌套循环。
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第28张图片](http://img.e-com-net.com/image/info8/b9ea2a1ce54d4a17bbe1cb7206343cde.png)
后来修改成多GPU来使用,不过在lstm输出后要修改一下那个padding的长度。要不concat那里就会报接不起来的错误了。
论文4:OneRel: Joint Entity and Relation Extraction with One Module in One Step
年份:2022-03-17
看题目与作者
用一个模型去解决实体及关系的联合抽取任务,名字叫OneRel;
作者:北理工
看摘要
忽略三元组依赖信息,会造成级联错误与信息冗余,提出了OneRel: 把实体关系联合抽取看成fine-grained triple分类任务来处理,由scoring-based classififier 与 relation-specifific horns tagging strategy组成。效果SOTA。
看结论(与摘要相应的,多出展望):
1. 把联合抽取任务转制换成一个粒度三元组分类问题。
2. 提出了基于分数分类器与Rel-Spec Horns标注策略的单步联合单模型。
展望(不足):
- 评分函数会影响模型效率;
- 在其实信息抽取任务的深探。
看实验结果(主要是看图表)
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第29张图片](http://img.e-com-net.com/image/info8/3481acb5b8044440b921e7f538e927f5.jpg)
表现还不错。
看方法
两部分内容: 标注体系(Rel-Spec Horns Tagging)及模型(Scoring-based Classififier)
一般看来创新点有两个地方:标注体系、模型
Rel-Spec Horns Tagging strategy && decoding algorithm
tagging
“BIE” :Begin, Inside, End
“HB”: 实体的开始token(the beginning token of the head entity)
“TE” : 尾实体的结束token(the end token of the tail entity)
tagging strategy
(1)“HB-TB”: 具体关系下的一对实体的头实体开始token及尾实体token; 例如:对于三元组(“New York City” ,Located in, “New York
State”)中,(“New”, Located in, “New”) 标注为“HB-TB”;
(2)“HB-TE”: 以上同理,(“New”, Located in, “State”) 标注为“HB-TE”;
(3)“HE-TE”: 以上同理,(“City”, Located in, “State”)标注为“HE-TE”;
(4)“-”: 除了上面三种情况之外的情况 ,都标注为“-”
只用三个角被标注所以叫:Rel-Spec Horns Tagging
例子:![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第30张图片](http://img.e-com-net.com/image/info8/fa442b80775d4a319c20942af62e57c0.jpg)
tagging体系优点:
- 把9种标注变成三角标注;
- 负样本容易构建;
- 解码简单有效;
- 对于*EntityPairOverlap *(EPO) 、 *SingleEntityOverlap *(SEO) 和 HeadTailOverlap(HTO1 )问题可以容易解决。
Decoding
Scoring-based Classififier
编码:{e1, e2, …, eL} = BERT({x1, x2, …, xL})
最终的评分函数:

![]()
损失函数:
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第31张图片](http://img.e-com-net.com/image/info8/844599913b464edd8263450f31e5cdac.png)
补充说明一下多模块多步与单模块单步区别
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第32张图片](http://img.e-com-net.com/image/info8/00dc979909ec41c1af8b393ca7517966.png)
这篇文章感觉有点啰嗦。提出了一种新的标注方案。这种抽取三元组的方法,是否少了实体类型?其实我还比较关注实体类型的,是否可以在关系上推导出实体类型?
论文5:OneEE: A One-Stage Framework for Fast Overlapping and Nested Event Extraction
[1] H. Cao et al., ‘OneEE: A One-Stage Framework for Fast Overlapping and Nested Event Extraction’. arXiv, Sep. 06, 2022. Accessed: Oct. 12, 2022. [Online]. Available: http://arxiv.org/abs/2209.02693
年份:2022-09-26
解决问题:
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第33张图片](http://img.e-com-net.com/image/info8/ace1b21e8fb740949293009622abdb1d.png)
论文提出OneEE, 把EE任务采用word-word关系识别任务来解决。触发语或相关参数一齐识别与抽取。模型由adaptive enven fusion module与distance-aware predictor构成。
标签方案
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WbRZMhcD-1666014120039)(https://www.jianguoyun.com/c/tblv2/Xu0c-GgQsUSNnT28QzkliG7VkhHvlD6PpcEdy_tzPqE4M5ukEWYl770yYFYshtsm5NcqC-lF/U-lATKLRCvNj4EgWWIRemw/l)]
设计成两种关系标注,一种是spnas标签:S-*,即是用它来表示实体, 一种是role标签:R-*,即是用来表示事件的中心词与参数的关系。
S-*处理Trigger与argument关系;R-*表示参数的角色分类。
“S-T”: 是用来标记trigger的首尾边界的关系;
“S-A”:是用来标记argument的首尾边界的关系;
“R-S”:表示“subject”参数与trigger之间的关系;
“R-O”,“R-T”,"R-P"分别表示“object”,“target”,"proportion"参数所trigger之间的关系。
例如(a)中, 事件:Invesment, 由“s-” 表示的trigger实体:acquired; argument实体有“Citic Securities”与“Guangzhou Securities”; 由“R-*”表示的关系为R-S上的边与R-O的边,用了gmw
模型:
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第34张图片](http://img.e-com-net.com/image/info8/b235316c59574ae580b85b313459472a.jpg)
模型包含了三个部分。
Encoder Layer :BERT
Adaptive Event Fusion Layer
fuse层: event信息 + 上下文信息
内容包括:关注力模块,两个门整合模块(用来融合全局与target事件信息)。
Attention Mechanism
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第35张图片](http://img.e-com-net.com/image/info8/18d9d8aaf0594b57ad717597c96ab730.png)
Gate Fusion Mechanism
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第36张图片](http://img.e-com-net.com/image/info8/3a2c69a34dfa44d98b9ace1d2764764a.png)
p,q就输入向量,g是全连接经过激活函数的结果。
应用attention Mechanism与Gate Fusion Mechanism两公式
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第37张图片](http://img.e-com-net.com/image/info8/610dc49ade774c23a5abed57d732762c.png)
E表示事件的嵌入,采用随机初始化的方法来初始化的。
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第38张图片](http://img.e-com-net.com/image/info8/bda135c768d34de28dfccf124c4ba98c.png)
这里的目的是使用词表达带有事件的信息,叫做具有事件感知的词表达。
Joint Prediction Layer
联合预测两词之间的span与role关系。
对于每个词对,计算一个分数去衡量关系(span关系与role关系)的可能性。
Distance-aware Score
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第39张图片](http://img.e-com-net.com/image/info8/cb41a77344b04e74b589c1d8b4262be0.png)
损失函数
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第40张图片](http://img.e-com-net.com/image/info8/9282b0e4638b4cc1a4a6fa1813c239c9.png)
这里引了一个阈值δ,当存在关系的大于δ,否则小于δ.
模型训练过程中是经过采样的,关系采样数K,如下的效果:
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第41张图片](http://img.e-com-net.com/image/info8/857f0472c3f647239494d383e0acb3a5.png)
实验效果
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第42张图片](http://img.e-com-net.com/image/info8/ead0635b39de4a829cafe112c650cee4.jpg)
模型的各个部分的作用:
![[论文阅读笔记70]基于token-token grid模型的信息抽取(5篇)_第43张图片](http://img.e-com-net.com/image/info8/bb9d303c25e3449d9af7e7f7081fcd29.png)
总结: 其实事件抽取是实体与关系抽取的另个角度,不过它会显得更详细,它有一个事件背景。就好像分词与NER的关系。分词的任务,只要可以把词分开就好,可是NER还有一个类型在。实体与关系的模型,只要把实体抽出来有关系就好,可是事件中还要有事件的角色,就是中心词,其它实体要围绕它,其它的实体就叫做中心词的属性了,这个中心词还决定了事件是什么与事件类型。NLP的任务是环环相关扣的,就看你站在哪个角度来看它。可以是end-end的形式,也可以每步每步都拆开,看任务而定。
made by happyprince