模型推理加速系列|如何用ONNX加速BERT特征抽取(附代码)
简介
近期从事模型推理加速相关项目,所以抽空整理最近的学习经验。本次实验目的在于介绍如何使用ONNXRuntime加速BERT模型推理。实验中的任务是利用BERT抽取输入文本特征,至于BERT在下游任务(如文本分类、问答等)上如何加速推理,后续再介绍。
PS:本次的实验模型是BERT-base中文版。
环境准备
由于ONNX是一种序列化格式,在使用过程中可以加载保存的graph并运行所需要的计算。在加载ONNX模型之后可以使用官方的onnxruntime进行推理。出于性能考虑,onnxruntime是用c++实现的,并为c++、C、c#、Java和Python提供API/Bindings。
在本文的示例中,将使用Python API来说明如何加载序列化的ONNX graph,并通过onnxruntime在后端执行inference。Python下的onnxruntime有2种:
-
onnxruntime: ONNX + MLAS (Microsoft Linear Algebra Subprograms)
-
onnxruntime-gpu: ONNX + MLAS + CUDA
可以通过命令安装:
pip install transformers onnxruntime onnx psutil matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install transformers onnxruntime-gpu onnx psutil matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple/
本文这里先以 CPU 版进行对比。
PS:本次实验环境的CPU型号信息如下:
32 Intel(R) Xeon(R) Gold 6134 CPU @ 3.20GHz
Pytorch Vs ONNX
将 transformers 模型导出为 ONNX
huggingface 的 transformers 已经提供将 PyTorch或TensorFlow 格式模型转换为ONNX的工具(from transformers.convert_graph_to_onnx import convert)。Pytorch 模型转为 ONNX 大致有以下4个步骤:
-
基于transformers载入PyTorch模型
-
创建伪输入(dummy inputs),并利用伪输入在模型中前向inference,换一句话说用伪输入走一遍推理网络并在这个过程中追踪记录操作集合。因为
convert_graph_to_onnx这个脚本转为ONNX模型的时候,其背后是调用torch.onnx.export,而这个export方法要求Tracing网络。 -
在输入和输出tensors上定义动态轴,比如batch size这个维度。该步骤是可选项。
-
保存graph和网络参数
上述4个步骤在convert_graph_to_onnx.convert已经封装好,所以可以直接调用该函数将Pytorch模型转为ONNX格式:
from pathlib import Path
from transformers.convert_graph_to_onnx import convert
# Handles all the above steps for you
convert(framework="pt", model="/home/data/pretrain_models/bert-base-chinese-pytorch", output=Path("onnx/bert-base-chinese.onnx"), opset=11)
# 注意:因为convert_graph_to_onnx.convert中默认的pipeline_name是"feature-extraction"。如果是其他任务,则需要对应修改。具体支持哪些pipeline_name可以在官方接口中查阅。
PS:当自定义的任务不在pipeline_name中的时候,需要自己用 torch.onnx.export 导出 ONNX 模型。
ONNX模型优化
通过使用特定的后端来进行inference,后端将启动特定硬件的graph优化。有3种基本的优化:
-
Constant Folding: 将graph中的静态变量转换为常量
-
Deadcode Elimination: 去除graph中未使用的nodes
-
Operator Fusing: 将多条指令合并为一条(比如,Linear -> ReLU 可以合并为 LinearReLU)
在ONNX Runtime中通过设置特定的SessionOptions会自动使用大多数优化。注意:一些尚未集成到ONNX Runtime 中的最新优化可在优化脚本中找到,利用这些脚本可以对模型进行优化以获得最佳性能。
安装优化工具包onnxruntime-tools:
pip install onnxruntime-tools -i https://pypi.tuna.tsinghua.edu.cn/simple/
用 onnxruntime-tools 进行优化并保存优化后的ONNX模型:
# optimize transformer-based models with onnxruntime-tools
from onnxruntime_tools import optimizer
from onnxruntime_tools.transformers.onnx_model_bert import BertOptimizationOptions
# disable embedding layer norm optimization for better model size reduction
opt_options = BertOptimizationOptions('bert')
opt_options.enable_embed_layer_norm = False
opt_model = optimizer.optimize_model(
'onnx/bert-base-chinese.onnx',
'bert',
num_heads=12,
hidden_size=768,
optimization_options=opt_options)
opt_model.save_model_to_file('onnx/bert-base-chinese.opt.onnx')CPU上运行优化过的ONNX模型
ONNX Runtime 为支持不同的硬件加速ONNX models,引入了一个可扩展的框架,称为Execution Providers(EP),集成硬件中特定的库。在使用过程中只需要根据自己的真实环境和需求指定InferenceSession中的providers即可,比如如果想要用CPU那么可以如此创建会话:session =InferenceSession(model_path,options,providers=['CPUExecutionProvider'])。
优化后的graph可能包括各种优化,如果想要查看优化后graph中一些更高层次的操作(例如EmbedLayerNormalization、Attention、FastGeLU)可以通过比如Netron等可视化工具查看。
上述已经将优化过ONNX模型保存到磁盘。下面介绍如何加载ONNX模型进行inference。
from os import environ
from psutil import cpu_count
# Constants from the performance optimization available in onnxruntime
# It needs to be done before importing onnxruntime
environ["OMP_NUM_THREADS"] = str(cpu_count(logical=True)) # OMP 的线程数
environ["OMP_WAIT_POLICY"] = 'ACTIVE'
from onnxruntime import GraphOptimizationLevel, InferenceSession, SessionOptions, get_all_providers
from contextlib import contextmanager
from dataclasses import dataclass
from time import time
from tqdm import trange
def create_model_for_provider(model_path: str, provider: str) -> InferenceSession:
assert provider in get_all_providers(), f"provider {provider} not found, {get_all_providers()}"
# Few properties that might have an impact on performances (provided by MS)
options = SessionOptions()
options.intra_op_num_threads = 1
options.graph_optimization_level = GraphOptimizationLevel.ORT_ENABLE_ALL
# Load the model as a graph and prepare the CPU backend
session = InferenceSession(model_path, options, providers=[provider])
session.disable_fallback()
return session
@contextmanager
def track_infer_time(buffer: [int]):
start = time()
yield
end = time()
buffer.append(end - start)
@dataclass
class OnnxInferenceResult:
model_inference_time: [int]
optimized_model_path: str
在CPU上加载ONNX模型,并进行推理:
from transformers import BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained("/home/data/pretrain_models/bert-base-chinese-pytorch") # 使用 Pytorch 模型的字典
cpu_model = create_model_for_provider("onnx/bert-base-chinese.opt.onnx", "CPUExecutionProvider") # 使用 优化过的 onnx
# Inputs are provided through numpy array
model_inputs = tokenizer("大家好, 我是卖切糕的小男孩, 毕业于华中科技大学", return_tensors="pt")
inputs_onnx = {k: v.cpu().detach().numpy() for k, v in model_inputs.items()}
# Run the model (None = get all the outputs)
sequence, pooled = cpu_model.run(None, inputs_onnx)
# Print information about outputs
print(f"Sequence output: {sequence.shape}, Pooled output: {pooled.shape}")
CPU上运行Pytorch 模型(作为对比基准)
from transformers import BertModel
PROVIDERS = {
("cpu", "PyTorch CPU"),
# Uncomment this line to enable GPU benchmarking
# ("cuda:0", "PyTorch GPU")
}
results = {}
for device, label in PROVIDERS:
# Move inputs to the correct device
model_inputs_on_device = {
arg_name: tensor.to(device)
for arg_name, tensor in model_inputs.items()
}
# Add PyTorch to the providers
model_pt = BertModel.from_pretrained("/home/data/pretrain_models/bert-base-chinese-pytorch").to(device)
for _ in trange(10, desc="Warming up"):
model_pt(**model_inputs_on_device)
# Compute
time_buffer = []
for _ in trange(100, desc=f"Tracking inference time on PyTorch"):
with track_infer_time(time_buffer):
model_pt(**model_inputs_on_device)
# Store the result
results[label] = OnnxInferenceResult(
time_buffer,
None
)
CPU上运行ONNX模型
PROVIDERS = {
("CPUExecutionProvider", "ONNX CPU"),
# Uncomment this line to enable GPU benchmarking
# ("CUDAExecutionProvider", "ONNX GPU")
}
# ONNX
for provider, label in PROVIDERS:
# Create the model with the specified provider
model = create_model_for_provider(model_onnx_path, provider)
# Keep track of the inference time
time_buffer = []
# Warm up the model
model.run(None, inputs_onnx)
# Compute
for _ in trange(100, desc=f"Tracking inference time on {provider}"):
with track_infer_time(time_buffer):
model.run(None, inputs_onnx)
# Store the result
results[label] = OnnxInferenceResult(
time_buffer,
model.get_session_options().optimized_model_filepath
)
# ONNX opt
PROVIDERS_OPT = {
("CPUExecutionProvider", "ONNX opt CPU")
}
for provider, label in PROVIDERS_OPT:
# Create the model with the specified provider
model = create_model_for_provider(model_opt_path, provider)
# Keep track of the inference time
time_buffer = []
# Warm up the model
model.run(None, inputs_onnx)
# Compute
for _ in trange(100, desc=f"Tracking inference time on {provider}"):
with track_infer_time(time_buffer):
model.run(None, inputs_onnx)
# Store the result
results[label] = OnnxInferenceResult(
time_buffer,
model.get_session_options().optimized_model_filepath
)
# 将 result save 处理, 绘制结果对比图
import pickle
with open('results.pkl', 'wb') as f:
pickle.dump(results, f, pickle.HIGHEST_PROTOCOL)
三者实验结果对比
CPU上运行Pytorch 、 ONNX 和 优化过的ONNX:
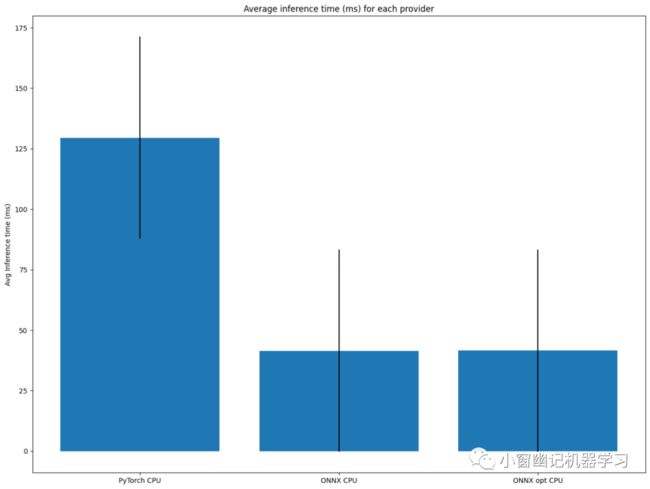
结论:
基于BERT进行特征抽取,每次处理单个文本时,CPU上运行ONNX模型比Pytorch模型大约提速3倍。但是,这里有一点疑惑的是优化过的 ONNX 和未优化过的 ONNX 性能基本相同。这着实与预期不符,有待后续进一步实验,也欢迎大家一起讨论!