李宏毅机器学习笔记——14. Attack ML Models and Defense(机器学习模型的攻击与防御)
摘要:本章讲解了机器学习模型的攻击与防御,主要是围绕攻击去展开一系列介绍。之所以要研究攻击与防御,是因为机器学习模型很可能会遭到恶意攻击,从而对模型结果造成错误。围绕攻击,讲解了攻击的基本原理与分类,以及攻击之所以会生效的原因。接着介绍了如何去攻击,与攻击方式(FGSM),以及对黑盒模型如何去攻击,与在现实世界中的实例应用。最后是有关防御Defense的部分。可分为被动防御Passive defense与主动防御Proactive defense,被动防御的基本思想是:不改变模型,只是另外加个防护罩;主动防御的基本思想是主动去找漏洞,补漏洞。但是防御能力是一直存在这巨大缺陷的!
文章目录
- 1. Attack (模型攻击)
-
- 1.1 Motivation(研究动机)
- 1.2 对图像模型进行攻击
- 1.3 Loss Function for Attack
- 1.4 Constraint(相似度的限制)
- 1.5 How to Attack ?
- 1.6 Attack Approaches(攻击方式)
-
- 1.6.1 FGSM(fast gradient sign method)
- 1.7 黑盒攻击
- 1.8 普遍对抗攻击(Universal Adversarial Attack)
- 1.9 对抗性重新编程(Adversarial Reprogramming)
- 1.10 现实世界的攻击
-
- 1.10.1 对人脸识别的攻击
- 2. Defense(模型防御)
-
- 2.1 passive defense (被动防御)
-
- 2.1 .1 feature Squeeze(特征挤压)
- 2.2 proactive defense (主动防御)
- 3. 总结与展望
1. Attack (模型攻击)
1.1 Motivation(研究动机)
神经网络不仅是用在研究上,而且实际上是要用在各种有意义的应用中。因此模型如果仅仅是对杂讯(噪声)和大部分时间work是不够的,还要去对抗恶意攻击(不暴露出弱点)。所以对模型可抗击性的研究有重要意义。
1.2 对图像模型进行攻击
如果给模型输入中加入一些杂讯(攻击),这些杂讯是人为处理过的,最后使得模型输出结果错误,如下图:
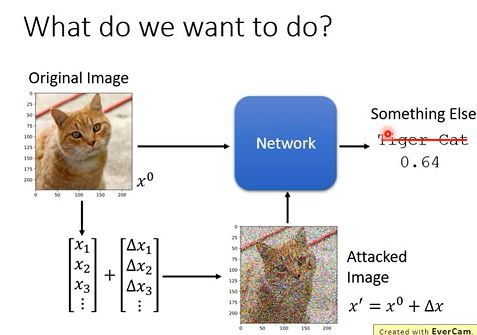
比如我们有一个Network用来做动物的图像识别。我们输入一张如图所示的图片 x0, Network预测为“Tiger Cat”。机器学习模型攻击是在x0上加上一个微小的噪音Δ x,使得图片看起来还是一只“Tiger Cat”,但是通过Network的预测结果却是其他动物了。
1.3 Loss Function for Attack
根据攻击达到的效果分为两类:
-
Non-targeted Attack:不需要使得被攻击的模型将输入,预测成特定某一类,只需要输出越远离目标结果就好。(即只要求预测结果远离类别)
-
Targeted Attack:使得被攻击的模型将输入,预测成特定某一类的。(既要求预测结果既要远离正确类别,又要接近某个错误类别)
下图中分别有一般训练的损失函数,与无目标攻击,以及目标攻击的损失函数:
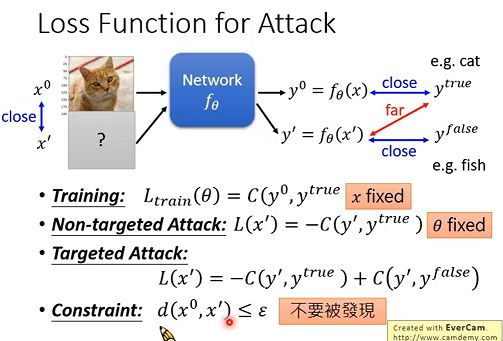
训练与攻击的本质区别:
训练的时候,我们的x是不变的,从而获得我们的θ;而在训练攻击图片的时候,我们是不改变模型本身的参数的,我们是固定住了θ ,而训练的是x。
但是对于Attack恶意攻击,首先我们还是要保证,我们攻击所用的输入 x ′ x' x′ 和原输入 x 0 x^0 x0应该相对很接近(差异不大),最起码人应该是不容易察觉的,因此我们要增加一个相似度的限制(Constraint)。
1.4 Constraint(相似度的限制)
距离 d 通常的定义方式有:
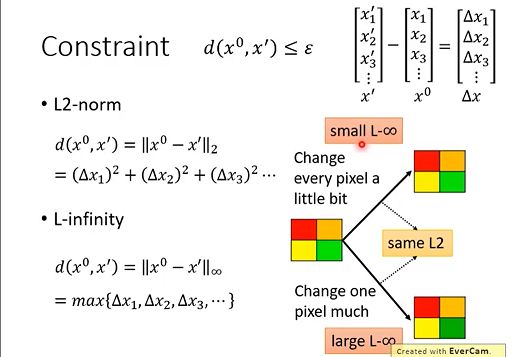
在上面图片识别例子中,我们更适合用无穷范数的定义方式。因为L2范式不能很好的描述人类感知的差别,它无法区分上图 (右上与右下)两张图片。如果有几个像素有明显的变化,我们人眼还是能轻易捕捉到的。但是当图片不是很简单的时候,整张图片每个像素都有很细微的变化,我们肉眼几乎是完全检查不出来的。
相似度定义的方法需要根据人类的感知差别去改变(比如图片识别,语音识别都会有所不同),所以对不同的任务可能有更好的定义方式。
1.5 How to Attack ?
我们现在的目标是找出这个能够欺骗模型的x, 怎么找呢?其实这和我们训练一个模型的方式是很类似的。现在,假设我们的损失函数:
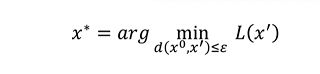
L的参数已经固定住了,我们现在要做的是找到x’,能使得L(x’)越小越好,这样才能骗过模型,那么怎么做呢?
gradient descent梯度下降(改善版)
- 首先将 真实的数据x0作为初始值,然后开始做梯度下降:
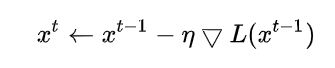
- 必须满足条件:
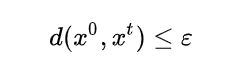
Attack gradient descent 相当于就是有了一定限制的梯度下降。每一步在对x做更新后,都要计算是否d符合限制条件才可。如下图:

如果更新出现到达的点在范围外的情况,我们就把它调整为符合限制的x。
如何调整呢?
需要这样的一个操作,就是一种把所谓的外面的点拉回来的方式。相对来说最靠谱的就是,拉到距离之前的点最近的边界上。下面的图片就是对2-范数和无穷范数的情况: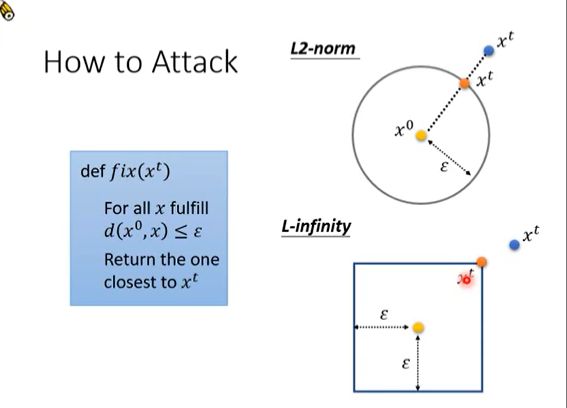
简而言之,就是把更新后的 x t x^t xt拉到符合限制区域的最近的向量上,用它来替代 x t x^t xt。
1.6 Attack Approaches(攻击方式)
其实攻击方式有多种,主要区别在于限制的不同和用不同的方法计算loss函数,下面介绍一种简单的攻击方式:
1.6.1 FGSM(fast gradient sign method)
更新参数X方法是,x* = x0 - ε △x(ε是约束的最大值)
△x等于每个维度loss函数的微分,当微分为正时,取+1,微分为负时,取-1。
FGSM方式相当于往梯度最大的下降方向走固定长的一步即可,也就是说只考虑梯度方向而不考虑梯度大小,并且给一个非常大的learning rate,一次update就会跑出范围,然后把它拉回对应的角。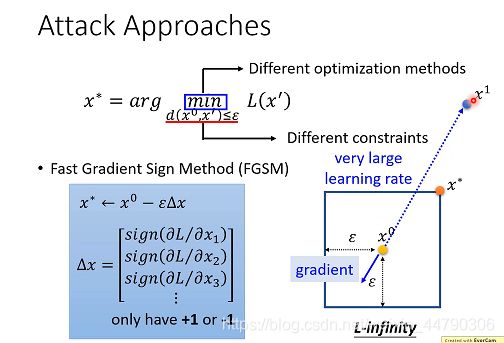
在FGSM中,我们只在乎gradient的方向,不在乎大小。
原理:设立了一个非常大的学习率,这样一次更新就会超出限制范围,这时再将x1拉回限制边界。得到的就是x*。
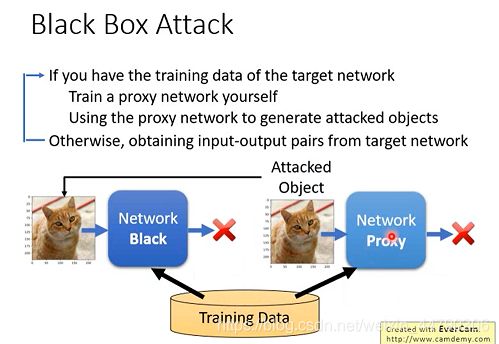
1.7 黑盒攻击
之前我们讲的都是白盒攻击,即模型的网络结构(参数已知)我们都是知道的。那么,如果一个未知结构的Black模型,该如何攻击?
我们只知道要用了哪些数据训练出来的一个神经网络,那我们只要用相同的数据训练某个自定义结构的Proxy模型(自己训练出的NN),在该Proxy模型上做attack,然后找出那个图片x*,再用这个x* 去攻击黑盒模型,这样往往会结果不错!
1.8 普遍对抗攻击(Universal Adversarial Attack)

之前提到的攻击,对于每个图片 x x x,会有不同的噪声 x ′ x' x′进行攻击,有人提出了通用的噪声,可以让所有图片的辨识结果都出错。(也可以做黑箱攻击)
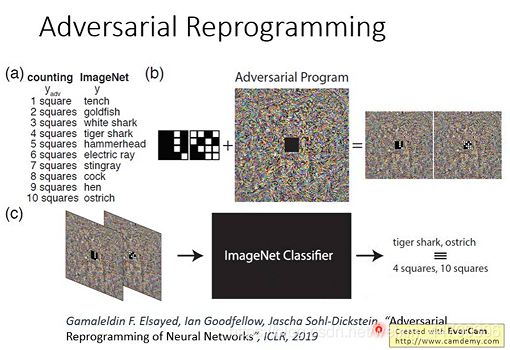
1.9 对抗性重新编程(Adversarial Reprogramming)
我们可以改变一个NN原本想做的事,给它加了一些方块后,就会去使NN做其他的事。
1.10 现实世界的攻击
引入:真实的世界中机器是从镜头看世界,那些微小的杂讯透过镜头后机器可能会看不见,这样的攻击也许没有效果。但是洗衣机图片的实验表明,微小的杂讯确实会对结果产生影响。
1.10.1 对人脸识别的攻击
对人脸识别上进行攻击,把噪声变成眼镜,带着眼镜就可以实现攻击。(人脸识别系统就会出现辨识错误):

将眼镜做成真实世界的东西时,也是需要考虑很多东西:
- 保证多角度都是成功的
- 噪声不要有非常大的变化(比如只有1像素与其他不同),要以色块方式呈现,这样方便摄像头能看清
- 不要用打印机打不出来的颜色
2. Defense(模型防御)
Regularization,dropout和model ensemble并不能保证ml可以挡住攻击。事实上,攻击时可以跨模型的,攻击model A的效果,在model B可能也会有作用。
防御手段主分成两大类:passive defense (被动防御)和proactive defense (主动防御)
- passive defense (被动防御): 不改变模型,只是另外加个防护罩,去处理被攻击的图片,使得攻击效果失效
- proactive defense (主动防御): 训练模型的过程中,就要将防御考虑在其中,主要在于要自己找到漏洞并补起来
2.1 passive defense (被动防御)
在原来的network前,加入一个filter(过滤器),这个filter的功能就是减少attack signal 的影响。
举个例子,在数据输入前,加上一个Filter,如对该图片进行Smoothing处理:

因为在某些方向上信号变化使猫变成键盘,进行平滑化处理后,这些方向的信号发生了改变(在特定方向上的一些小小改动,就很有可能是 x ’ x’ x’回到 tiger cat概率很大的区域,那么attack signal的影响就减小了),进而攻击就失效了。
缺陷:filter其实就相当于在原始的NN前面加了一层layer,如果对方知道你的filter结构,仍然可以进行有效的attack。
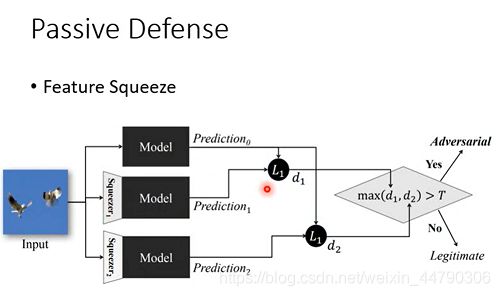
2.1 .1 feature Squeeze(特征挤压)
如果同一张图片,被squeeze前和squeeze后,辨识结果差很多,说明这张图片可能是被攻击过的。
squeezer(挤压器)指的是不同的filter:
2.2 proactive defense (主动防御)
Proactive Defense 基本思想是:找出漏洞,补起来。直观的去想,做法也很简单:
- 训练数据 train出 model
- 对每个训练数据,train出可以attack model的 新数据,并用原数据的label 作为新数据的label
- 生成的新数据再用于训练model,填补model的漏洞
- 在重新去训练模型,重复以上步骤,得到一个具有一定自我防御能力的model

但是无论如何修补,总是有一个新的方向可能会出漏洞,因此对模型的防御确实一直是一个难点。
3. 总结与展望
总的来说,在机器学习模型中攻击远比防御容易,不管是主动防御还是被动防御目前都有相应的不足之处,所以对于模型受到不同的攻击可以根据具体情况去defense,使得模型具有足够的防御能力。当前,防御手段还不够好,这会对机器学习的实际应用产生很大安全隐患。(比如人脸识别系统,语音识别等)所以对机器学习模型如何更好的在现实中去应用,还存在一定的不足之处!