R ddply()
在学习《概率图模型基于R》的过程中遇到了ddply(),而书中讲解较少,本文内容作为理解书中代码做的补充。也就是服务于这篇博客。若有错误之处,希望大家在留言区指出。
目录
一、 summarize()
二、 summarize() + ddply()
三、 自定义函数 + summarize()
简单地说,ddply(data,variables,fun)就是
-
对一个表格使用函数
-
在函数作用前先将表格进行分组
首先我们建一个简单的表格
> student = data.frame(name=c("a","b","c","d"),
years=c(12,13,14,12),
math=c(80,90,80,80))
> student
name years math
1 a 12 80
2 b 13 90
3 c 14 80
4 d 12 80一、 summarize()
接下来对这个表格用summarize函数。在此之前,我们先认识一下summarize函数:
> summarize(student,math)
math
1 80
2 90
3 80
4 80
> summarize(student,name)
name
1 a
2 b
3 c
4 d
> summarize(student,c(name,math))
c(name, math)
1 a
2 b
3 c
4 d
5 80
6 90
7 80
8 80可以看到summarize(),就是把表格里所需要的数据拎出来。
二、 summarize() + ddply()
现在我们将summarize()作用在表格data0上试试看,为了方便大家比较 summarize()和summarize() + ddply()的区别,我们特意将summarize()的结果也呈现出来:
> summarize(student,math)
math
1 80
2 90
3 80
4 80
> ddply(student,.(math),summarize,number=length(math))
math number
1 80 3
2 90 1实际上,我们对于对比两个结果之后,可以说很直接就得出了ddply()在这里起的作用,不过是统计math的类别数罢了。我一开始也是没去细究,后来书中代码是将一个自定义的函数作用在表格上,我一下子就搞不懂了。因此,尽管我们很显然的知道了summarize() + ddply()的效果,还是有必要讲一下这个过程。(以下都是我个人猜测的 ╮(╯▽╰)╭)(以下非可执行代码)
ddply(student,.(math),summarize,number=length(math))
这个代码,我是这么理解的,首先关注以下内容(***就是我们不要去关注的内容)
ddply(student,.(math),***,***)
上面的含义就是把表student按.(math)拆分,变成两个小表格,大概(我猜的)像下面这样吧
第一个表格,也就是math=80的行
name years math
1 a 12 80
3 c 14 80
4 d 12 80
第二个表格,也就是math=90的行
name years math
2 b 13 90
然后我们解封一个***,现在关注的是
ddply(student,.(math),summarize,***)
summarize现在就分别作用在我们得到的两个小表格上,同样得到两个结果
但是具体是怎么作用的,目前还是不清楚的,因为函数是在两个表格上作用summarize(***)
因此,我们进一步解封一个***看:
ddply(student,.(math),summarize,number=length(math))
上面这段的含义就是:在第一个小表格
name years math
1 a 12 80
3 c 14 80
4 d 12 80
上作用summarize(number=length(math))
因此得到
math number
1 80 3
在第二个小表格
name years math
2 b 13 90
上作用summarize(number=length(math))
因此得到
math number
2 90 1
因此总体为
math number
1 80 3
2 90 1
再补充关于.(math)的含义:
.()里面可以有多个参数
> ddply(student,.(math),summarize,number=length(math))
math number
1 80 3
2 90 1
> ddply(student,.(years,math),summarize,number=length(math))
years math number
1 12 80 2
2 13 90 1
3 14 80 1
#写成.()的含义就是说math是在data里面的,我们要在data0里面找math。直接写math是找不到的三、 自定义函数 + summarize()
首先我们先给出一个有向图(生成有向图可参考我的另一篇博客),并做一些基本的设置:
> data0 <- data.frame(
x=c("a","a","a","a","b","b","b","b"),
y=c("t","t","u","u","t","t","u","u"),
z=c("c","d","c","d","c","d","c","d"))
> edges0 <- list(x=list(edges=2),y=list(edges=3),z=list())
> g0 <- graphNEL(nodes=names(data0),edgeL=edges0,edgemod="directed")
> plot(g0)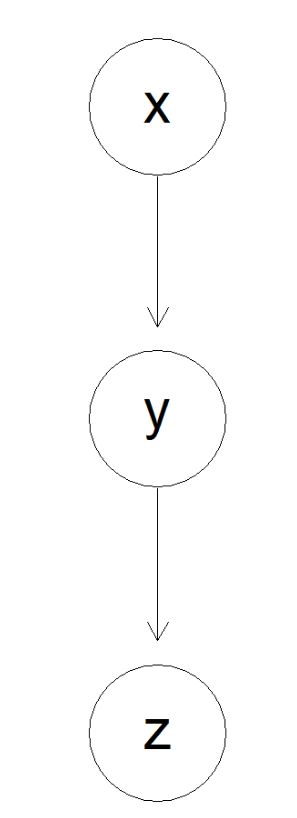
为了方便寻找节点(我们以y为例)的父节点(也就是x),我们将有向图翻转:
> rg <- reverseEdgeDirections(g0)
> plot(rg)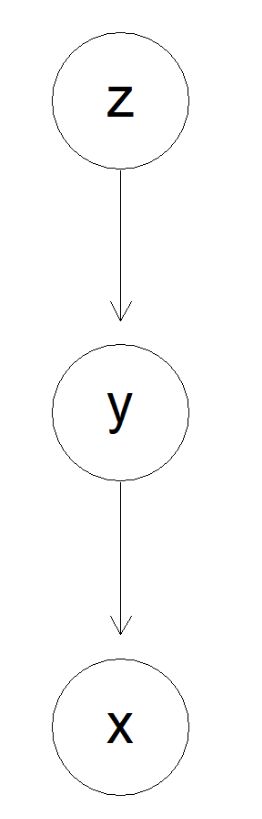
> var<-rg@nodes[2] #我们取var为y
> adj(rg,var) #这是一个列表
$y
[1] "x"
> pa <- unlist(adj(rg,var)) #这是一个字符
y
"x"
接下来我们自定义一个函数make_cpt
> make_cpt<-function(df,pa)
{
prob <- nrow(df) # df的行数
parents <- data.frame(df[1,pa]) #第一行父节点对应的值
names(parents) <- pa #parent内容是父节点对于的值,名字是父节点
data.frame(parents,prob)
}
#特别的,父节点为x时
> data.frame(parents,prob)
x prob
1 a 8
> make_cpt(data0,pa)
x prob
1 a 8
#结合
data0
> data0
x y z
1 a t c
2 a t d
3 a u c
4 a u d
5 b t c
6 b t d
7 b u c
8 b u d
#我们应当理解
> make_cpt(data0,pa) #x为父节点时
x prob
1 a 8
> make_cpt(data0,pa) #y为父节点时
y prob
1 t 8
接下来我们看自定义函数 + summarize():
> ddply(data0, c(var,pa), make_cpt, pa) #父节点为x
y x prob
1 t a 2
2 t b 2
3 u a 2
4 u b 2
#我们应当理解,首先会得到4个小表格:
#第一个,不妨记作data1
# x y z
# 1 a t c
# 2 a t d
#第二个,不妨记作data2
# x y z
# 3 a u c
# 4 a u d
#第三个,不妨记作data3
# 5 b t c
# 6 b t d
#第四个,不妨记作data4
# 7 b u c
# 8 b u d
接下来make_cpt分别作用在这四个表格上,也就相当于
make_cpt(data1,c(var,pa))
make_cpt(data2,c(var,pa))
make_cpt(data3,c(var,pa))
make_cpt(data4,c(var,pa))
#因此,我们对输出应当足够清楚
# y x prob
# 1 t a 2
# 2 t b 2
# 3 u a 2
# 4 u b 2接下来我们研究一下代码中最后的pa起到了什么作用
> pa
y
x"
> var
[1] "y"
> ddply(data0, c(var,pa), make_cpt, pa) #make_cpt(data0,pa)
y x prob
1 t a 2
2 t b 2
3 u a 2
4 u b 2
> ddply(data0, c(var,pa), make_cpt, var) #make_cpt(data0,var)
y prob
1 t 2
2 t 2
3 u 2
4 u 2
#上一个例子中,存在.(math)是因为math是在表格中的,不能用c(math)表示