跑通Yolov5的一些心得
跑通Yolov5的一些心得
1.文件安装准备(版本要求)
#pytorch 1.5.1
#torchvision 0.6.1
#vs2015
conda create -n yolov5 python=3.7
conda install pytorch torchvision cudatoolkit=10.1
pip install -U -r requirements.txt
安装pycocotools
cd cocoapi/PythonAPI
python setup.py build_ext install
安装apex
cd apex-master
pip install -r requirements.txt
python setup.py install
2.数据集准备
数据集我用的是“robflow”网站下载的口罩数据集,图片大小大概是416×416的,里面包含训练集和label,还是测试集。
当然,如果你想自己创造数据集,用labelimg是一个不错的打标工具,因为里面可以选择输出yolov5专用的标签格式。

相对应的label文件是一个txt,一般就是bbox框框的各项坐标数据(用labelimg打一次标就知道了)。
3.训练数据
这里还是建议大家去yolov5的官网下载整套的源代码,因为这里我根据自己的数据集对代码进行了一定的改动。并且需要在官方网站下,下载属于yolov5的四个权重模型文件,yolov5s/m/l/x,根据自己的电脑的配置情况,选择合适自己的权值文件,训练效果相应也不同。
官方的read me文件是这么说的:
Download COCO, install Apex and run command below. Training times for YOLOv5s/m/l/x are 2/4/6/8 days on a single V100 (multi-GPU times faster). Use the largest --batch-size your GPU allows (batch sizes shown for 16 GB devices).
import argparse
import torch.distributed as dist
import torch.nn.functional as F
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler
import torch.utils.data
from torch.utils.tensorboard import SummaryWriter
import test # import test.py to get mAP after each epoch
from models.yolo import Model
from utils import google_utils
from utils.datasets import *
from utils.utils import *
mixed_precision = True
try: # Mixed precision training https://github.com/NVIDIA/apex
from apex import amp
except:
print('Apex recommended for faster mixed precision training: https://github.com/NVIDIA/apex')
mixed_precision = False # not installed
wdir = 'weights' + os.sep # weights dir
os.makedirs(wdir, exist_ok=True)
last = wdir + 'last.pt'
best = wdir + 'best.pt'
results_file = 'results.txt'
# Hyperparameters
hyp = {'lr0': 0.01, # initial learning rate (SGD=1E-2, Adam=1E-3)
'momentum': 0.937, # SGD momentum
'weight_decay': 5e-4, # optimizer weight decay
'giou': 0.05, # giou loss gain
'cls': 0.58, # cls loss gain
'cls_pw': 1.0, # cls BCELoss positive_weight
'obj': 1.0, # obj loss gain (*=img_size/320 if img_size != 320)
'obj_pw': 1.0, # obj BCELoss positive_weight
'iou_t': 0.20, # iou training threshold
'anchor_t': 4.0, # anchor-multiple threshold
'fl_gamma': 0.0, # focal loss gamma (efficientDet default is gamma=1.5)
'hsv_h': 0.014, # image HSV-Hue augmentation (fraction)
'hsv_s': 0.68, # image HSV-Saturation augmentation (fraction)
'hsv_v': 0.36, # image HSV-Value augmentation (fraction)
'degrees': 0.0, # image rotation (+/- deg)
'translate': 0.0, # image translation (+/- fraction)
'scale': 0.5, # image scale (+/- gain)
'shear': 0.0} # image shear (+/- deg)
print(hyp)
# Overwrite hyp with hyp*.txt (optional)
f = glob.glob('hyp*.txt')
if f:
print('Using %s' % f[0])
for k, v in zip(hyp.keys(), np.loadtxt(f[0])):
hyp[k] = v
# Print focal loss if gamma > 0
if hyp['fl_gamma']:
print('Using FocalLoss(gamma=%g)' % hyp['fl_gamma'])
def train(hyp):
epochs = opt.epochs # 300
batch_size = opt.batch_size # 64
weights = opt.weights # initial training weights
# Configure
init_seeds(1)
with open(opt.data) as f:
data_dict = yaml.load(f, Loader=yaml.FullLoader) # model dict
train_path = data_dict['train']
test_path = data_dict['val']
nc = 1 if opt.single_cls else int(data_dict['nc']) # number of classes
# Remove previous results
for f in glob.glob('*_batch*.jpg') + glob.glob(results_file):
os.remove(f)
# Create model
model = Model(opt.cfg).to(device)
assert model.md['nc'] == nc, '%s nc=%g classes but %s nc=%g classes' % (opt.data, nc, opt.cfg, model.md['nc'])
model.names = data_dict['names']
# Image sizes
gs = int(max(model.stride)) # grid size (max stride)
imgsz, imgsz_test = [check_img_size(x, gs) for x in opt.img_size] # verify imgsz are gs-multiples
# Optimizer
nbs = 64 # nominal batch size
accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
pg0, pg1, pg2 = [], [], [] # optimizer parameter groups
for k, v in model.named_parameters():
if v.requires_grad:
if '.bias' in k:
pg2.append(v) # biases
elif '.weight' in k and '.bn' not in k:
pg1.append(v) # apply weight decay
else:
pg0.append(v) # all else
optimizer = optim.Adam(pg0, lr=hyp['lr0']) if opt.adam else \
optim.SGD(pg0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
optimizer.add_param_group({'params': pg1, 'weight_decay': hyp['weight_decay']}) # add pg1 with weight_decay
optimizer.add_param_group({'params': pg2}) # add pg2 (biases)
print('Optimizer groups: %g .bias, %g conv.weight, %g other' % (len(pg2), len(pg1), len(pg0)))
del pg0, pg1, pg2
# Load Model
google_utils.attempt_download(weights)
start_epoch, best_fitness = 0, 0.0
if weights.endswith('.pt'): # pytorch format
ckpt = torch.load(weights, map_location=device) # load checkpoint
# load model
try:
ckpt['model'] = {k: v for k, v in ckpt['model'].float().state_dict().items()
if model.state_dict()[k].shape == v.shape} # to FP32, filter
model.load_state_dict(ckpt['model'], strict=False)
except KeyError as e:
s = "%s is not compatible with %s. Specify --weights '' or specify a --cfg compatible with %s." \
% (opt.weights, opt.cfg, opt.weights)
raise KeyError(s) from e
# load optimizer
if ckpt['optimizer'] is not None:
optimizer.load_state_dict(ckpt['optimizer'])
best_fitness = ckpt['best_fitness']
# load results
if ckpt.get('training_results') is not None:
with open(results_file, 'w') as file:
file.write(ckpt['training_results']) # write results.txt
start_epoch = ckpt['epoch'] + 1
del ckpt
# Mixed precision training https://github.com/NVIDIA/apex
if mixed_precision:
model, optimizer = amp.initialize(model, optimizer, opt_level='O1', verbosity=0)
# Scheduler https://arxiv.org/pdf/1812.01187.pdf
lf = lambda x: (((1 + math.cos(x * math.pi / epochs)) / 2) ** 1.0) * 0.9 + 0.1 # cosine
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
scheduler.last_epoch = start_epoch - 1 # do not move
# https://discuss.pytorch.org/t/a-problem-occured-when-resuming-an-optimizer/28822
# plot_lr_scheduler(optimizer, scheduler, epochs)
# Initialize distributed training
if device.type != 'cpu' and torch.cuda.device_count() > 1 and torch.distributed.is_available():
dist.init_process_group(backend='nccl', # distributed backend
init_method='tcp://127.0.0.1:9999', # init method
world_size=1, # number of nodes
rank=0) # node rank
model = torch.nn.parallel.DistributedDataParallel(model)
# pip install torch==1.4.0+cu100 torchvision==0.5.0+cu100 -f https://download.pytorch.org/whl/torch_stable.html
# Trainloader
dataloader, dataset = create_dataloader(train_path, imgsz, batch_size, gs, opt,
hyp=hyp, augment=True, cache=opt.cache_images, rect=opt.rect)
mlc = np.concatenate(dataset.labels, 0)[:, 0].max() # max label class
assert mlc < nc, 'Label class %g exceeds nc=%g in %s. Correct your labels or your model.' % (mlc, nc, opt.cfg)
# Testloader
testloader = create_dataloader(test_path, imgsz_test, batch_size, gs, opt,
hyp=hyp, augment=False, cache=opt.cache_images, rect=True)[0]
# Model parameters
hyp['cls'] *= nc / 80. # scale coco-tuned hyp['cls'] to current dataset
model.nc = nc # attach number of classes to model
model.hyp = hyp # attach hyperparameters to model
model.gr = 1.0 # giou loss ratio (obj_loss = 1.0 or giou)
model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) # attach class weights
# Class frequency
labels = np.concatenate(dataset.labels, 0)
c = torch.tensor(labels[:, 0]) # classes
# cf = torch.bincount(c.long(), minlength=nc) + 1.
# model._initialize_biases(cf.to(device))
if tb_writer:
plot_labels(labels)
tb_writer.add_histogram('classes', c, 0)
# Check anchors
if not opt.noautoanchor:
check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
# Exponential moving average
ema = torch_utils.ModelEMA(model)
# Start training
t0 = time.time()
nb = len(dataloader) # number of batches
n_burn = max(3 * nb, 1e3) # burn-in iterations, max(3 epochs, 1k iterations)
maps = np.zeros(nc) # mAP per class
results = (0, 0, 0, 0, 0, 0, 0) # 'P', 'R', 'mAP', 'F1', 'val GIoU', 'val Objectness', 'val Classification'
print('Image sizes %g train, %g test' % (imgsz, imgsz_test))
print('Using %g dataloader workers' % dataloader.num_workers)
print('Starting training for %g epochs...' % epochs)
# torch.autograd.set_detect_anomaly(True)
for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
model.train()
# Update image weights (optional)
if dataset.image_weights:
w = model.class_weights.cpu().numpy() * (1 - maps) ** 2 # class weights
image_weights = labels_to_image_weights(dataset.labels, nc=nc, class_weights=w)
dataset.indices = random.choices(range(dataset.n), weights=image_weights, k=dataset.n) # rand weighted idx
# Update mosaic border
# b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
# dataset.mosaic_border = [b - imgsz, -b] # height, width borders
mloss = torch.zeros(4, device=device) # mean losses
print(('\n' + '%10s' * 8) % ('Epoch', 'gpu_mem', 'GIoU', 'obj', 'cls', 'total', 'targets', 'img_size'))
pbar = tqdm(enumerate(dataloader), total=nb) # progress bar
for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
ni = i + nb * epoch # number integrated batches (since train start)
imgs = imgs.to(device).float() / 255.0 # uint8 to float32, 0 - 255 to 0.0 - 1.0
# Burn-in
if ni <= n_burn:
xi = [0, n_burn] # x interp
# model.gr = np.interp(ni, xi, [0.0, 1.0]) # giou loss ratio (obj_loss = 1.0 or giou)
accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
for j, x in enumerate(optimizer.param_groups):
# bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
x['lr'] = np.interp(ni, xi, [0.1 if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])
if 'momentum' in x:
x['momentum'] = np.interp(ni, xi, [0.9, hyp['momentum']])
# Multi-scale
if opt.multi_scale:
sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs # size
sf = sz / max(imgs.shape[2:]) # scale factor
if sf != 1:
ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
imgs = F.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
# Forward
pred = model(imgs)
# Loss
loss, loss_items = compute_loss(pred, targets.to(device), model)
if not torch.isfinite(loss):
print('WARNING: non-finite loss, ending training ', loss_items)
return results
# Backward
if mixed_precision:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
# Optimize
if ni % accumulate == 0:
optimizer.step()
optimizer.zero_grad()
ema.update(model)
# Print
mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
mem = '%.3gG' % (torch.cuda.memory_cached() / 1E9 if torch.cuda.is_available() else 0) # (GB)
s = ('%10s' * 2 + '%10.4g' * 6) % (
'%g/%g' % (epoch, epochs - 1), mem, *mloss, targets.shape[0], imgs.shape[-1])
pbar.set_description(s)
# Plot
if ni < 3:
f = 'train_batch%g.jpg' % ni # filename
result = plot_images(images=imgs, targets=targets, paths=paths, fname=f)
if tb_writer and result is not None:
tb_writer.add_image(f, result, dataformats='HWC', global_step=epoch)
# tb_writer.add_graph(model, imgs) # add model to tensorboard
# end batch ------------------------------------------------------------------------------------------------
# Scheduler
scheduler.step()
# mAP
ema.update_attr(model)
final_epoch = epoch + 1 == epochs
if not opt.notest or final_epoch: # Calculate mAP
results, maps, times = test.test(opt.data,
batch_size=batch_size,
imgsz=imgsz_test,
save_json=final_epoch and opt.data.endswith(os.sep + 'coco.yaml'),
model=ema.ema,
single_cls=opt.single_cls,
dataloader=testloader)
# Write
with open(results_file, 'a') as f:
f.write(s + '%10.4g' * 7 % results + '\n') # P, R, mAP, F1, test_losses=(GIoU, obj, cls)
if len(opt.name) and opt.bucket:
os.system('gsutil cp results.txt gs://%s/results/results%s.txt' % (opt.bucket, opt.name))
# Tensorboard
if tb_writer:
tags = ['train/giou_loss', 'train/obj_loss', 'train/cls_loss',
'metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/F1',
'val/giou_loss', 'val/obj_loss', 'val/cls_loss']
for x, tag in zip(list(mloss[:-1]) + list(results), tags):
tb_writer.add_scalar(tag, x, epoch)
# Update best mAP
fi = fitness(np.array(results).reshape(1, -1)) # fitness_i = weighted combination of [P, R, mAP, F1]
if fi > best_fitness:
best_fitness = fi
# Save model
save = (not opt.nosave) or (final_epoch and not opt.evolve)
if save:
with open(results_file, 'r') as f: # create checkpoint
ckpt = {'epoch': epoch,
'best_fitness': best_fitness,
'training_results': f.read(),
'model': ema.ema.module if hasattr(model, 'module') else ema.ema,
'optimizer': None if final_epoch else optimizer.state_dict()}
# Save last, best and delete
torch.save(ckpt, last)
if (best_fitness == fi) and not final_epoch:
torch.save(ckpt, best)
del ckpt
# end epoch ----------------------------------------------------------------------------------------------------
# end training
n = opt.name
if len(n):
n = '_' + n if not n.isnumeric() else n
fresults, flast, fbest = 'results%s.txt' % n, wdir + 'last%s.pt' % n, wdir + 'best%s.pt' % n
for f1, f2 in zip([wdir + 'last.pt', wdir + 'best.pt', 'results.txt'], [flast, fbest, fresults]):
if os.path.exists(f1):
os.rename(f1, f2) # rename
ispt = f2.endswith('.pt') # is *.pt
strip_optimizer(f2) if ispt else None # strip optimizer
os.system('gsutil cp %s gs://%s/weights' % (f2, opt.bucket)) if opt.bucket and ispt else None # upload
if not opt.evolve:
plot_results() # save as results.png
print('%g epochs completed in %.3f hours.\n' % (epoch - start_epoch + 1, (time.time() - t0) / 3600))
dist.destroy_process_group() if device.type != 'cpu' and torch.cuda.device_count() > 1 else None
torch.cuda.empty_cache()
return results
if __name__ == '__main__':
check_git_status()
parser = argparse.ArgumentParser()
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16)
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='*.cfg path')
parser.add_argument('--data', type=str, default='data/coco128.yaml', help='*.data path')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='train,test sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', action='store_true', help='resume training from last.pt')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--weights', type=str, default='', help='initial weights path')
parser.add_argument('--name', default='', help='renames results.txt to results_name.txt if supplied')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--adam', action='store_true', help='use adam optimizer')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%')
parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
opt = parser.parse_args()
opt.weights = last if opt.resume else opt.weights
opt.cfg = check_file(opt.cfg) # check file
opt.data = check_file(opt.data) # check file
print(opt)
opt.img_size.extend([opt.img_size[-1]] * (2 - len(opt.img_size))) # extend to 2 sizes (train, test)
device = torch_utils.select_device(opt.device, apex=mixed_precision, batch_size=opt.batch_size)
if device.type == 'cpu':
mixed_precision = False
# Train
if not opt.evolve:
tb_writer = SummaryWriter(comment=opt.name)
print('Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/')
train(hyp)
# Evolve hyperparameters (optional)
else:
tb_writer = None
opt.notest, opt.nosave = True, True # only test/save final epoch
if opt.bucket:
os.system('gsutil cp gs://%s/evolve.txt .' % opt.bucket) # download evolve.txt if exists
for _ in range(10): # generations to evolve
if os.path.exists('evolve.txt'): # if evolve.txt exists: select best hyps and mutate
# Select parent(s)
parent = 'single' # parent selection method: 'single' or 'weighted'
x = np.loadtxt('evolve.txt', ndmin=2)
n = min(5, len(x)) # number of previous results to consider
x = x[np.argsort(-fitness(x))][:n] # top n mutations
w = fitness(x) - fitness(x).min() # weights
if parent == 'single' or len(x) == 1:
# x = x[random.randint(0, n - 1)] # random selection
x = x[random.choices(range(n), weights=w)[0]] # weighted selection
elif parent == 'weighted':
x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
# Mutate
mp, s = 0.9, 0.2 # mutation probability, sigma
npr = np.random
npr.seed(int(time.time()))
g = np.array([1, 1, 1, 1, 1, 1, 1, 0, .1, 1, 0, 1, 1, 1, 1, 1, 1, 1]) # gains
ng = len(g)
v = np.ones(ng)
while all(v == 1): # mutate until a change occurs (prevent duplicates)
v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
hyp[k] = x[i + 7] * v[i] # mutate
# Clip to limits
keys = ['lr0', 'iou_t', 'momentum', 'weight_decay', 'hsv_s', 'hsv_v', 'translate', 'scale', 'fl_gamma']
limits = [(1e-5, 1e-2), (0.00, 0.70), (0.60, 0.98), (0, 0.001), (0, .9), (0, .9), (0, .9), (0, .9), (0, 3)]
for k, v in zip(keys, limits):
hyp[k] = np.clip(hyp[k], v[0], v[1])
# Train mutation
results = train(hyp.copy())
# Write mutation results
print_mutation(hyp, results, opt.bucket)
strip_optimizer(best)
# Plot results
# plot_evolution_results(hyp)
输入:
python train.py --img 640 --batch 16 --epochs 300 --data …/Mask/data.yaml --cfg models/yolov5x.yaml --weights weights/yolov5x.pt
开始训练!

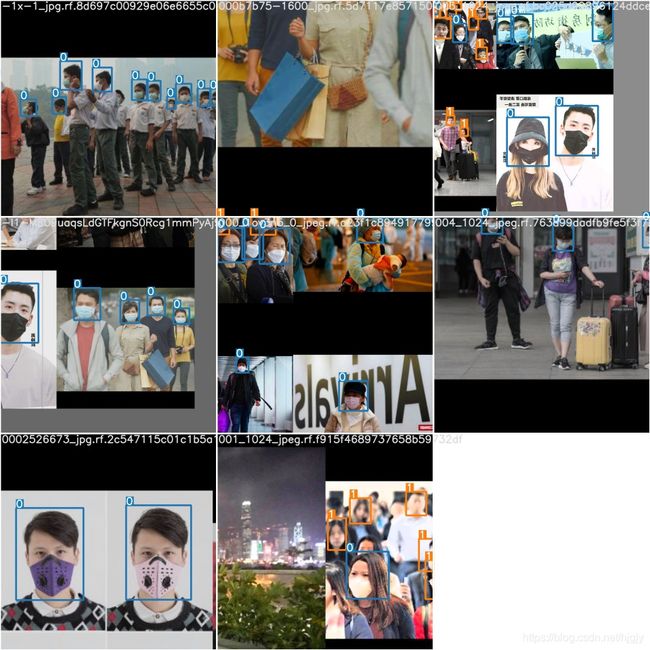
4.预测结果
import argparse
import torch.backends.cudnn as cudnn
from utils import google_utils
from utils.datasets import *
from utils.utils import *
def detect(save_img=False):
out, source, weights, view_img, save_txt, imgsz = \
opt.output, opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_size
webcam = source == '0' or source.startswith('rtsp') or source.startswith('http') or source.endswith('.txt')
# Initialize
device = torch_utils.select_device(opt.device)
if os.path.exists(out):
shutil.rmtree(out) # delete output folder
os.makedirs(out) # make new output folder
half = device.type != 'cpu' # half precision only supported on CUDA
# Load model
#google_utils.attempt_download(weights)
model = torch.load(weights, map_location=device)['model'].float() # load to FP32
# torch.save(torch.load(weights, map_location=device), weights) # update model if SourceChangeWarning
# model.fuse()
model.to(device).eval()
if half:
model.half() # to FP16
# Second-stage classifier
classify = False
if classify:
modelc = torch_utils.load_classifier(name='resnet101', n=2) # initialize
modelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']) # load weights
modelc.to(device).eval()
# Set Dataloader
vid_path, vid_writer = None, None
if webcam:
view_img = True
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz)
else:
save_img = True
dataset = LoadImages(source, img_size=imgsz)
# Get names and colors
names = model.module.names if hasattr(model, 'module') else model.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in range(len(names))]
# Run inference
t0 = time.time()
img = torch.zeros((1, 3, imgsz, imgsz), device=device) # init img
_ = model(img.half() if half else img) if device.type != 'cpu' else None # run once
for path, img, im0s, vid_cap in dataset:
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Inference
t1 = torch_utils.time_synchronized()
pred = model(img, augment=opt.augment)[0]
# Apply NMS
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
t2 = torch_utils.time_synchronized()
# Apply Classifier
if classify:
pred = apply_classifier(pred, modelc, img, im0s)
# Process detections
for i, det in enumerate(pred): # detections per image
if webcam: # batch_size >= 1
p, s, im0 = path[i], '%g: ' % i, im0s[i].copy()
else:
p, s, im0 = path, '', im0s
save_path = str(Path(out) / Path(p).name)
txt_path = str(Path(out) / Path(p).stem) + ('_%g' % dataset.frame if dataset.mode == 'video' else '')
s += '%gx%g ' % img.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
if det is not None and len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += '%g %ss, ' % (n, names[int(c)]) # add to string
# Write results
for *xyxy, conf, cls in det:
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * 5 + '\n') % (cls, *xywh)) # label format
if save_img or view_img: # Add bbox to image
label = '%s %.2f' % (names[int(cls)], conf)
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=3)
# Print time (inference + NMS)
print('%sDone. (%.3fs)' % (s, t2 - t1))
# Stream results
if view_img:
cv2.imshow(p, im0)
if cv2.waitKey(1) == ord('q'): # q to quit
raise StopIteration
# Save results (image with detections)
if save_img:
if dataset.mode == 'images':
cv2.imwrite(save_path, im0)
else:
if vid_path != save_path: # new video
vid_path = save_path
if isinstance(vid_writer, cv2.VideoWriter):
vid_writer.release() # release previous video writer
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*opt.fourcc), fps, (w, h))
vid_writer.write(im0)
if save_txt or save_img:
print('Results saved to %s' % os.getcwd() + os.sep + out)
if platform == 'darwin': # MacOS
os.system('open ' + save_path)
print('Done. (%.3fs)' % (time.time() - t0))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='weights/yolov5s.pt', help='model.pt path')
parser.add_argument('--source', type=str, default='inference/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--output', type=str, default='inference/output', help='output folder') # output folder
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.4, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.5, help='IOU threshold for NMS')
parser.add_argument('--fourcc', type=str, default='mp4v', help='output video codec (verify ffmpeg support)')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
opt = parser.parse_args()
opt.img_size = check_img_size(opt.img_size)
print(opt)
with torch.no_grad():
detect()
# Update all models
# for opt.weights in ['yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt', 'yolov3-spp.pt']:
# detect()
# create_pretrained(opt.weights, opt.weights)
划重点
输入:python detect.py --source ./Garbage/images/test2020/ --weights=“weights/best.pt” --view-img
即可开始test预测,
另外,如果要开启外置摄像头,进行实时预测,只需要输出指令:
python detect.py --source 0 --weights="weights/yolov5x.pt"