dalle:zero-shot text-to-image generation
DALL·E—从文本到图像,超现实主义的图像生成器 - 知乎欢迎关注Smarter,构建CV世界观超现实主义强调梦幻与现实的统一才是绝对的真实,而如今OpenAI创造的DALL·E图像生成器,能够直接通过文本描述生成类似超现实主义的图像,让机器也能拥有顶级画家、设计师的创造力。… https://zhuanlan.zhihu.com/p/394467135如何评价DALL-E模型的实现? - 知乎DALL-E的具体实现,openAI没有公布,github上发布的代码只有一个dVAE的模型,相当于只有一半。但Hugging …https://www.zhihu.com/question/447757686/answer/2326092032
https://zhuanlan.zhihu.com/p/394467135如何评价DALL-E模型的实现? - 知乎DALL-E的具体实现,openAI没有公布,github上发布的代码只有一个dVAE的模型,相当于只有一半。但Hugging …https://www.zhihu.com/question/447757686/answer/2326092032
漫谈VAE和VQVAE,从连续分布到离散分布 - 知乎欢迎关注Smarter,构建CV世界观最近DALLE和VQGAN展现出了非常强大的图片生成能力,DALLE可以通过输入文字生成匪夷所思的超现实主义图片,VQGAN可以生成百万像素的高清图片,而这两个生成模型都跟VAE和VQVAE的思想…https://zhuanlan.zhihu.com/p/388299884dalle是个分阶段的算法,dalle要训练三个模型,dvae,dalle和clip,dvae中encoder用来对图像提特征,dalle是个组合了图像特征和文本特征的自回归的语言模型,这块一定要注意,看代码还以为是类似clip的代理任务,其实不是的,text和image的特征做了拼接,是按照自回归transformer的思路做的,说白了就是一个gpt,最终输入text产生了图像特征再用dvae进行decoder解码,生成了的图像再采用clip进行排序输出。这三个部分都是分别训练的。但是一般clip是不训,找个预训练的就能用,或者直接像gan一样生成一个batch的图也可以。
训练阶段:
1)Stage One先单独做dVAE的训练(得到encoder、visual codebook、decoder);
2)Stage Two做Transformer,text和image分别做编码,concat在一起之后做类似GPT-3的left-to-right自回归LM语言模型,这里的小细节是,输入是text在左,image在右,这样后面在推理时根据text生成image就非常自然了~
推理阶段:
输入分2种情况:1)只输入text;2)输入text + image
1)只输入text时,先对text编码之后进入transformer进行自回归解码出image tokens,之后将生成的image tokens通过dVAE的codebook得到latent code,再送入dVAE的decoder做解码出图片;
2)输入text + image,可以理解是在上面生成image tokens的时候引入一些prefix信息(看代码是默认用前面14*32个),我理解这样会更可控一些,其他都是一样的。
最后,用CLIP对生成的图片进行排序,为什么会有多个呢?是因为在解码image tokens的时候,是根据概率分布做的采样,而不是直接argmax取greedy decode的那个,这样假设要生成n张图片,就跑n次解码(可以放在batch里面并行),而每次采样的不同,就可以生成n个不同的image token序列。
1.Introduction
用GAN不用VAE,可以提高图像保真度,其实在生成领域,包括超分等场景,最后使用gan去做decoder是很普遍的,就是因为gan生成的图的保真度好,但是gan也有问题,样本可能遭受严重的伪影,例如对象失真,不合逻辑的对象放置或前景和背景元素的不自然混合,之前看超分领域,cnn解码出来的图会有明显的平滑属性,没有sharp的棱角,但是gan的方法又会生成一些和原图无关的东西。
2.method
stage 1:训练一个dVAE将输入图的256x256压缩成32x32图片token,每个位置有8192种可能的值,也就是说dVAE的encoder输出是维度为32x32x8192的logits,然后通过logits索引codebook的特征进行组合,codebook的embedding是可学习的.
stage 2:使用BPE encoder对文本进行编码,得到最多256个文本token,不够的pad,将256文本token和1024图像token进行concat,得到1280维度的特征,将拼接的特征输入transformer进行自回归训练。
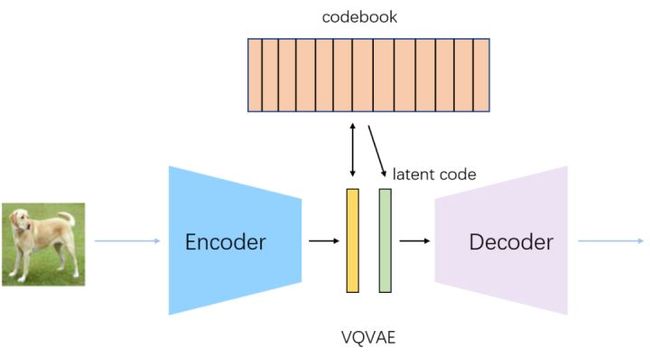
dVAE是VQVAE,VQVAE和VAE不同,VAE是学均值方差刻画高斯分布,通过引入后验分布,通过KL散度约束先验和后验,重参数从均值方差刻画的高斯中参数,进行decode。VQVAE通过encode学习中间编码,然后通过最近邻搜索将中间编码映射为codebook中k个向量之一,然后通过decode对latent code进行重建。最近邻搜索采用argmax来找codebook中索引位置,不可导,dalle使用Gumbel softmax trick来解决这个问题,argmax不可导,softmax近似max,而arg softmax是可导的。

第一部分是生成模型decode的,在KL中的第一部分是encode的,第二部分是先验分布。
2.1 stage 1:learning the visual codebook
kl weight=6.6,K=8196
2.2 stage 2:learning the prior
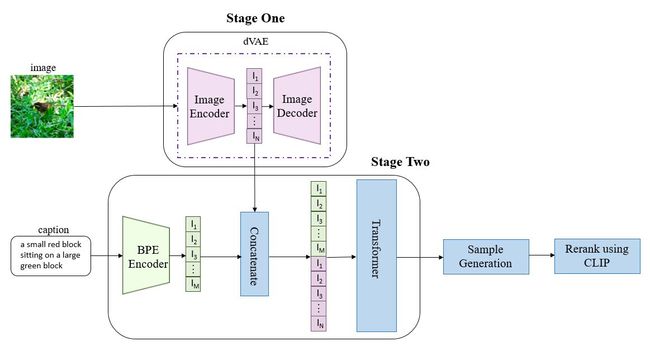
这一部分是dalle模型,就是一个先验的学习阶段,使用一个自回归的transformer做的,在dalle2中已经变成了扩散模型,这个自回归的transformer输入是BPE encoder之后的文本和dVAE encoder之后的图像,这块整个loss设计其实和clip是一致的。
2.3 推理
在推理时用的是dVAE的decode部分,产生的结果再用clip选择一个最合适的进行输出。
2.4 data collection
120亿的参数量,3.3m对text-image对。
3.代码
VAE:
vae = DiscreteVAE(
image_size=256,
num_layers=3, # number of downsamples - ex. 256 / (2 ** 3) = (32 x 32 feature map)
num_tokens=8192, # number of visual tokens. in the paper, they used 8192, but could be smaller for downsized projects
codebook_dim=512, # codebook dimension
hidden_dim=64, # hidden dimension
num_resnet_blocks=1, # number of resnet blocks
temperature=0.9, # gumbel softmax temperature, the lower this is, the harder the discretization
straight_through=False, # straight-through for gumbel softmax. unclear if it is better one way or the other
)img:4,3,256,256->norm->logits=encoder(img):4,8196,32,32->soft_one_hot=F.gumbel_softmax(logits):4,8196,32,32->sampled=einsum('b n h w,nd->b d h w',soft_one_hot,self.codebook_weight:8192,512):4,512,32,32->out=decoder(sampled):4,3,256,256
DiscreteVAE(
(codebook): Embedding(8192, 512)
(encoder): Sequential(
(0): Sequential(
(0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(1): ReLU()
)
(1): Sequential(
(0): Conv2d(64, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(1): ReLU()
)
(2): Sequential(
(0): Conv2d(64, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(1): ReLU()
)
(3): ResBlock(
(net): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
)
(4): Conv2d(64, 8192, kernel_size=(1, 1), stride=(1, 1))
)
(decoder): Sequential(
(0): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))
(1): ResBlock(
(net): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
)
(2): Sequential(
(0): ConvTranspose2d(64, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(1): ReLU()
)
(3): Sequential(
(0): ConvTranspose2d(64, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(1): ReLU()
)
(4): Sequential(
(0): ConvTranspose2d(64, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(1): ReLU()
)
(5): Conv2d(64, 3, kernel_size=(1, 1), stride=(1, 1))
)
)dalle:
dalle = DALLE(
dim=1024,
vae=vae, # automatically infer (1) image sequence length and (2) number of image tokens
num_text_tokens=10000, # vocab size for text
text_seq_len=256, # text sequence length
depth=12, # should aim to be 64
heads=16, # attention heads
dim_head=64, # attention head dimension
attn_dropout=0.1, # attention dropout
ff_dropout=0.1 # feedforward dropout
)image:4,3,256,256/text:4,256->text_range:256,text_seq_len:1280,num_image_tokens:8192,num_text_tokens:10256->text:4,256->text=F.pad:4,257->tokens=text_emb(text):4,257,1024->image=vae.get_codebook_indices(image)->logits=self(image):4,8196,32,32->codebook_indices=logits.argmax:4,1024->image_emb=image_emb(image):4,1024,1024->tokens:4,1281,1024->out=self.transformers(tokens:4,1280,1024):4,1280,1024->logits:4,1280,18448->offsetted_image:4,1028,text:4,257,labels:4,1280->logits:4,18448,1280
DALLE(
(vae): DiscreteVAE(
(codebook): Embedding(8192, 1024)
(encoder): Sequential(
(0): Sequential(
(0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(1): ReLU()
)
(1): Sequential(
(0): Conv2d(64, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(1): ReLU()
)
(2): Sequential(
(0): Conv2d(64, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(1): ReLU()
)
(3): ResBlock(
(net): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
)
(4): Conv2d(64, 8192, kernel_size=(1, 1), stride=(1, 1))
)
(decoder): Sequential(
(0): Conv2d(1024, 64, kernel_size=(1, 1), stride=(1, 1))
(1): ResBlock(
(net): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
)
(2): Sequential(
(0): ConvTranspose2d(64, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(1): ReLU()
)
(3): Sequential(
(0): ConvTranspose2d(64, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(1): ReLU()
)
(4): Sequential(
(0): ConvTranspose2d(64, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(1): ReLU()
)
(5): Conv2d(64, 3, kernel_size=(1, 1), stride=(1, 1))
)
)
(transformer): Transformer(
(layers): SequentialSequence(
(layers): ModuleList(
(0): ModuleList(
(0): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): CachedAs(
(fn): Attention(
(to_qkv): Linear(in_features=1024, out_features=3072, bias=False)
(to_out): Sequential(
(0): Linear(in_features=1024, out_features=1024, bias=True)
(1): Dropout(p=0.1, inplace=False)
)
)
)
)
)
)
)
(1): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): FeedForward(
(net): Sequential(
(0): Linear(in_features=1024, out_features=8192, bias=True)
(1): GEGLU()
(2): Dropout(p=0.1, inplace=False)
(3): Linear(in_features=4096, out_features=1024, bias=True)
)
)
)
)
)
)
)
(1): ModuleList(
(0): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): CachedAs(
(fn): Attention(
(to_qkv): Linear(in_features=1024, out_features=3072, bias=False)
(to_out): Sequential(
(0): Linear(in_features=1024, out_features=1024, bias=True)
(1): Dropout(p=0.1, inplace=False)
)
)
)
)
)
)
)
(1): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): FeedForward(
(net): Sequential(
(0): Linear(in_features=1024, out_features=8192, bias=True)
(1): GEGLU()
(2): Dropout(p=0.1, inplace=False)
(3): Linear(in_features=4096, out_features=1024, bias=True)
)
)
)
)
)
)
)
(2): ModuleList(
(0): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): CachedAs(
(fn): Attention(
(to_qkv): Linear(in_features=1024, out_features=3072, bias=False)
(to_out): Sequential(
(0): Linear(in_features=1024, out_features=1024, bias=True)
(1): Dropout(p=0.1, inplace=False)
)
)
)
)
)
)
)
(1): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): FeedForward(
(net): Sequential(
(0): Linear(in_features=1024, out_features=8192, bias=True)
(1): GEGLU()
(2): Dropout(p=0.1, inplace=False)
(3): Linear(in_features=4096, out_features=1024, bias=True)
)
)
)
)
)
)
)
(3): ModuleList(
(0): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): CachedAs(
(fn): Attention(
(to_qkv): Linear(in_features=1024, out_features=3072, bias=False)
(to_out): Sequential(
(0): Linear(in_features=1024, out_features=1024, bias=True)
(1): Dropout(p=0.1, inplace=False)
)
)
)
)
)
)
)
(1): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): FeedForward(
(net): Sequential(
(0): Linear(in_features=1024, out_features=8192, bias=True)
(1): GEGLU()
(2): Dropout(p=0.1, inplace=False)
(3): Linear(in_features=4096, out_features=1024, bias=True)
)
)
)
)
)
)
)
(4): ModuleList(
(0): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): CachedAs(
(fn): Attention(
(to_qkv): Linear(in_features=1024, out_features=3072, bias=False)
(to_out): Sequential(
(0): Linear(in_features=1024, out_features=1024, bias=True)
(1): Dropout(p=0.1, inplace=False)
)
)
)
)
)
)
)
(1): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): FeedForward(
(net): Sequential(
(0): Linear(in_features=1024, out_features=8192, bias=True)
(1): GEGLU()
(2): Dropout(p=0.1, inplace=False)
(3): Linear(in_features=4096, out_features=1024, bias=True)
)
)
)
)
)
)
)
(5): ModuleList(
(0): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): CachedAs(
(fn): Attention(
(to_qkv): Linear(in_features=1024, out_features=3072, bias=False)
(to_out): Sequential(
(0): Linear(in_features=1024, out_features=1024, bias=True)
(1): Dropout(p=0.1, inplace=False)
)
)
)
)
)
)
)
(1): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): FeedForward(
(net): Sequential(
(0): Linear(in_features=1024, out_features=8192, bias=True)
(1): GEGLU()
(2): Dropout(p=0.1, inplace=False)
(3): Linear(in_features=4096, out_features=1024, bias=True)
)
)
)
)
)
)
)
(6): ModuleList(
(0): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): CachedAs(
(fn): Attention(
(to_qkv): Linear(in_features=1024, out_features=3072, bias=False)
(to_out): Sequential(
(0): Linear(in_features=1024, out_features=1024, bias=True)
(1): Dropout(p=0.1, inplace=False)
)
)
)
)
)
)
)
(1): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): FeedForward(
(net): Sequential(
(0): Linear(in_features=1024, out_features=8192, bias=True)
(1): GEGLU()
(2): Dropout(p=0.1, inplace=False)
(3): Linear(in_features=4096, out_features=1024, bias=True)
)
)
)
)
)
)
)
(7): ModuleList(
(0): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): CachedAs(
(fn): Attention(
(to_qkv): Linear(in_features=1024, out_features=3072, bias=False)
(to_out): Sequential(
(0): Linear(in_features=1024, out_features=1024, bias=True)
(1): Dropout(p=0.1, inplace=False)
)
)
)
)
)
)
)
(1): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): FeedForward(
(net): Sequential(
(0): Linear(in_features=1024, out_features=8192, bias=True)
(1): GEGLU()
(2): Dropout(p=0.1, inplace=False)
(3): Linear(in_features=4096, out_features=1024, bias=True)
)
)
)
)
)
)
)
(8): ModuleList(
(0): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): CachedAs(
(fn): Attention(
(to_qkv): Linear(in_features=1024, out_features=3072, bias=False)
(to_out): Sequential(
(0): Linear(in_features=1024, out_features=1024, bias=True)
(1): Dropout(p=0.1, inplace=False)
)
)
)
)
)
)
)
(1): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): FeedForward(
(net): Sequential(
(0): Linear(in_features=1024, out_features=8192, bias=True)
(1): GEGLU()
(2): Dropout(p=0.1, inplace=False)
(3): Linear(in_features=4096, out_features=1024, bias=True)
)
)
)
)
)
)
)
(9): ModuleList(
(0): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): CachedAs(
(fn): Attention(
(to_qkv): Linear(in_features=1024, out_features=3072, bias=False)
(to_out): Sequential(
(0): Linear(in_features=1024, out_features=1024, bias=True)
(1): Dropout(p=0.1, inplace=False)
)
)
)
)
)
)
)
(1): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): FeedForward(
(net): Sequential(
(0): Linear(in_features=1024, out_features=8192, bias=True)
(1): GEGLU()
(2): Dropout(p=0.1, inplace=False)
(3): Linear(in_features=4096, out_features=1024, bias=True)
)
)
)
)
)
)
)
(10): ModuleList(
(0): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): CachedAs(
(fn): Attention(
(to_qkv): Linear(in_features=1024, out_features=3072, bias=False)
(to_out): Sequential(
(0): Linear(in_features=1024, out_features=1024, bias=True)
(1): Dropout(p=0.1, inplace=False)
)
)
)
)
)
)
)
(1): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): FeedForward(
(net): Sequential(
(0): Linear(in_features=1024, out_features=8192, bias=True)
(1): GEGLU()
(2): Dropout(p=0.1, inplace=False)
(3): Linear(in_features=4096, out_features=1024, bias=True)
)
)
)
)
)
)
)
(11): ModuleList(
(0): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): CachedAs(
(fn): Attention(
(to_qkv): Linear(in_features=1024, out_features=3072, bias=False)
(to_out): Sequential(
(0): Linear(in_features=1024, out_features=1024, bias=True)
(1): Dropout(p=0.1, inplace=False)
)
)
)
)
)
)
)
(1): LayerScale(
(fn): PreNorm(
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm_out): Identity()
(fn): CachedAs(
(fn): PreShiftToken(
(fn): FeedForward(
(net): Sequential(
(0): Linear(in_features=1024, out_features=8192, bias=True)
(1): GEGLU()
(2): Dropout(p=0.1, inplace=False)
(3): Linear(in_features=4096, out_features=1024, bias=True)
)
)
)
)
)
)
)
)
)
)
(to_logits): Sequential(
(0): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(1): Linear(in_features=1024, out_features=18448, bias=True)
)
(text_emb): Embedding(10256, 1024)
(image_emb): Embedding(8192, 1024)
)