评估深度学习模型的指标:混淆矩阵、准确率、精确率和召回率

在计算机视觉任务重,目标检测用来定位出一张图像上的一个或多个物体。。处理传统的目标检测方法,基于深度学习的模型比如R-CNN和YOLO算法在不同类型的物体检测上都有着优异的检测效果。这些模型接收一张图像作为输入数据,然后返回每一个所检测物体的边界框的坐标。这个教程将会讨论如何计算混淆矩阵、准确率、精确率和召回率。具体而言,主要内容如下:
(1)二分类的混淆矩阵
(2)多分类的混淆矩阵
(3)使用Scikit-learn库来计算混淆矩阵
(4)准确率、精确率和召回率计算公式
(5)使用精确率还是召回率?
1. 二分类的混淆矩阵
在二分类中,输入样本的类别有一类或者两类。一般而言,那些只有两种类别的样本的标签用0和1或者positive和negative来表示。假设有一个二分类问题,用positive和negative来表示它们的类别。这边有七个样本的标签,用来训练检测模型,我们称这七类标签为样本的ground truth标签。
positive, negative, negative, positive, positive, positive, negative这些类别标签(positive和negative)只是帮助人类来区分不同的类别,但是对于机器而言,就需要使用数字得分(scores)来进行区分。当我们给模型输入一个样本的时候,模型并不会输出某一种具体的类别,而是输出该模型对每一类的预测得分(该样本属于每一类的可能性,又称之为置信度)。举一个例子,当这七个样本输入到模型之后,它们的得分可能是这样:
0.6, 0.2, 0.55, 0.9, 0.4, 0.8, 0.5有着这些得分,每个样本都有一个确定的类别标签。我们如何将这些得分转成标签呢?可以使用一个置信度阈值来进行划分,这个置信度阈值是我们自行设置的超参数。比如,当我们设置置信度阈值为0.5的时候,那些得分在0.5以上的样本就可以认为是positive,反之,得分在0.5以下的就认为是negative。下面就是预测这七个样本的预测结果标签:
positive (0.6), negative (0.2), positive (0.55), positive (0.9), negative (0.4), positive (0.8), positive (0.5)之后,将ground truth和预测标签放在一张表格中进行对比。我们可以看到该模型预测正确的个数为4,而预测错误的个数为3。需要注意的是,当我们改变置信度阈值的时候,结果或者会有所不同。比如,当我们设置置信度阈值为0.6的时候,就只有两个错误的预测结果了。
round-Truth: positive, negative, negative, positive, positive, positive, negative
Predicted : positive, negative, positive, positive, negative, positive, positive为了能够提取出更多关于模型性能的信息,混淆矩阵应运而生。混淆矩阵帮助我们可视化这个检测模型对区分这两类是否感到“迷糊”。在下一张图中有一个2*2的矩阵。如图所示,两行两列都分别是Positive和Negative来表示ground truth和prediction的两个类别。

矩阵的四个元素(红色和绿色的部分)代表4个指标,用来记录这个检测模型预测正确和错误的个数。矩阵的每一个元素所表示的指标都有下面两个单词构成:
(1)True or False
(2)Positive or Negative
True表示预测结果是正确的,即预测结果的标签和ground truth的标签一致,False表示不一致。Positive和Negative则表示该检测模型的预测结果。
总而言之,当检测模型预测的结果错误的时候,第一个单词就是False,反之就是True。我们的目标就是最大化True的个数(True Positive和True Negative)以及最小化其他两个指标(False Positive和False Negative)。混淆矩阵中的四个指标就是:
(1)True Positive(真阳性):检测模型将Positive样本正确地预测为Positive的个数。
(2)False Negative(假阴性):检测模型将Positive样本错误地预测为Negative的个数。
(3)False Positive(假阳性):检测模型将Negative样本错误地预测为Positive的个数。
(4)True Negative(真阴性):检测模型将Negative样本错误地预测为Negative的个数。
因此,我们可以计算上面七个预测值的四个评价指标,混淆矩阵的结果如下:

2. 多分类的混淆矩阵
如何计算多分类的混淆矩阵呢?很简单!假设有9个样本,它们总共有三种类别:White, Black和Red。下面就是这9个样本的ground truth
Red, Black, Red, White, White, Red, Black, Red, White当我们将这九个样本输入到模型之后,它们的预测结果如下:
Red, White, Black, White, Red, Red, Black, White, Red为了方便对比,我们将其放在一个表格中:
Ground-Truth: Red, Black, Red, White, White, Red, Black, Red, White
Predicted: Red, White, Black, White, Red, Red, Black, White, Red计算多分类的混淆矩阵之前,我们首先需要设置一个目标类(target)。比如我们先将Red设置为目标类,因此ground truth和prediction中的Red类都设置为Positive,White和Black设置为Negative。
Positive, Negative, Positive, Negative, Negative, Positive, Negative, Positive, Negative
Positive, Negative, Negative, Negative, Positive, Positive, Negative, Negative, Positive这样,就只有两种类别(Positive和Negative),这种类型的混淆矩阵在上文中已经计算过。需要注意的是,这只是Red类的混淆矩阵!

对于White类而言,只需要将所有的White类修改为Positive,其他的类别修改为Negative。经过修改之后,ground truth和prediction的标签列表如下。
Negative, Negative, Negative, Positive, Positive, Negative, Negative, Negative, Positive
Negative, Positive, Negative, Positive, Negative, Negative, Negative, Positive, Negative下面这张图就是White类的混淆矩阵:
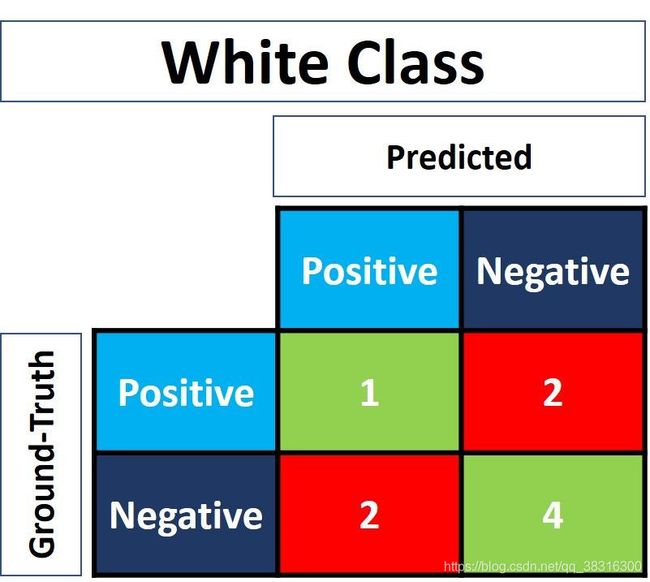
如法炮制,Black类的混淆矩阵的图像如下:

3 使用Scikit-Learn库来计算混淆矩阵
python中常用的Scikit-Learn库中有一个叫做metrics的模块,它可以用来计算混淆矩阵中的四个指标。对于二分类问题而言,可以使用confusion_matrix(),该函数有两个输入参数:
(1)y_true:ground truth标签
(2)y_pred:prediction标签
我们以上面二分类问题中使用的混淆矩阵为例:
import sklearn.metrics
y_true = ["positive", "negative", "negative", "positive", "positive", "positive", "negative"]
y_pred = ["positive", "negative", "positive", "positive", "negative", "positive", "positive"]
r = sklearn.metrics.confusion_matrix(y_true, y_pred)
print(r)它的输出结果如下:
array([[1, 2],
[1, 3]], dtype=int64)不难发现,输出结果和上述的结果有所出入。举例来说,在上述的True Positive的个数为3,在上述混淆矩阵中在矩阵的左上角,而在输出结果中,却在矩阵的右下角。为了结果这个问题,我们需要翻转一下输出矩阵:
import numpy
# flip的axis默认为Noone,就是x和y都进行翻转
r = numpy.flip(r)
print(r)输出结果如下:
array([[3, 1],
[2, 1]], dtype=int64)我们可以使用multilabel_confusion_matrix()函数来计算多分类的混淆矩阵。在该函数中,除了y_true和y_pred参数外,第三个参数labels形参接收类别名称列表。
import sklearn.metrics
import numpy
y_true = ["Red", "Black", "Red", "White", "White", "Red", "Black", "Red", "White"]
y_pred = ["Red", "White", "Black", "White", "Red", "Red", "Black", "White", "Red"]
r = sklearn.metrics.multilabel_confusion_matrix(y_true, y_pred, labels=["White", "Black", "Red"])
print(r)输出结果如下:
array([
[[4 2]
[2 1]]
[[6 1]
[1 1]]
[[3 2]
[2 2]]], dtype=int64)输出结果包括三种类别的混淆矩阵,其出现的顺序和该函数的形参labels中放置的类别一致。和二分类一样,每一类的混淆矩阵都需要进行翻转,才能得到在第一节中所示的对应的混淆矩阵。
# White class confusion matrix
[[1 2]
[2 4]]
# Black class confusion matrix
[[1 1]
[1 6]]
# Red class confusion matrix
[[2 2]
[2 3]]在下面的教程中,我们主要关心二分类问题。在下面一小节中,我们讨论一下基于混淆矩阵所延伸出来的三个关键指标。
4 准确率、精确率和召回率
在上面案例中,我们发现混淆矩阵提供了四个不同的指标,基于这些指标可以计算其它的、反应模型性能的指标:
(1)Accuracy(准确率)
(2)Precision(精确率)
(3)Recall(召回率)
4.1 Accuracy
准确率反映该检测模型对所有类别的检测性能,当所有类都同样重要的时候,使用这个指标会很管用(但是在目标检测任务中,我们更关心正样本的检测结果,因此这个指标并不常用)。准确率是该模型预测正确的个数和所有预测个数的比值:

基于上述计算的混淆矩阵,下面是使用Scikit-learn库来计算准确率的代码。变量acc表示True Positive和True Negative的个数与所有预测结果的比值。最终的结果是0.5714,这表示该模型做出一个正确预测的准确率是57.14%.
import numpy
import sklearn.metrics
y_true = ["positive", "negative", "negative", "positive", "positive", "positive", "negative"]
y_pred = ["positive", "negative", "positive", "positive", "negative", "positive", "positive"]
r = sklearn.metrics.confusion_matrix(y_true, y_pred)
r = numpy.flip(r)
acc = (r[0][0] + r[-1][-1]) / numpy.sum(r)
print(acc)0.571sklearn.metrics模型中还有一个叫做accuracy_score()的函数可以用来计算准确率,它将ground truth和prediction的标签作为函数的形参。
acc = sklearn.metrics.accuracy_score(y_true, y_pred)需要注意的是,这个指标已经被废弃不用了。特别是当数据中出现样本不均衡现象的时候。鸡舍这边由600个样本,其中属于Positive标签的有550个,而属于Negative标签的有50个。不难发现很多样本的都偏向于一类,这会造成Positive的准确率会高于Negative的准确率。如果该模型预测Positive标签的个数为530/550,而预测Negative标签的个数为5/50,那它们总共的准确率就是(530 + 5) / 600 = 0.8917,这意味着该模型的准确率是89.17%。因此,你可能会认为该模型的检测用来检测Positive或Negative的准确率都是89.17%,这显然是不合理的!
4.2 Precision
Precision是正确预测的Positive的个数与该模型预测的为Positive的样本的个数之比(不管预测的正不正确,只要是Positve就行),Precision衡量的是给模型预测positive的准确率(准相比于精确率,更准确到某一类)。

当该检测模型的预测结果中,错误的Positve (False Positive)的个数很多或者正确的Positive (True Positive)的个数很少的时候,公式的分母会增加从而导致精确率变得很小。另一方面,出现一下情况时,精确率会很高:
(1)检测模型的预测结果中,正确的Positive的个数很多
(2)检测模型的预测结果中,错误的Positive的个数很少
准确率反映该检测模型预测为Positive的可靠性(而精确率反映检测模型预测的可靠性,准确率更精准到某一类)
在下面这幅图中,绿色表示样本被划分为Positive,而红色表示样本被划分Negative。该检测模型将Postive正确划分为Positive的个数为2,而将Positve错误划分为Negative的个数为1。因此该检测模型的Precision就是2/(2+1) = 0.667。换句话说,该模型将检测结果识别为Positive的可靠性是66.7%。

Precision的目标是将所有为Positive的样本划分划分为Positive,而不是将Positive样本划分为Negative。下一张图中,所有Positive的样本都被划分为Positive,而只有一个Negative别划分为Positive。因此,该模型的精确率就是 3 / (3+1) = 0.75,所以可以说该模型有75%的准确率正确预测positive样本。

precision变成100%的方法处理将所有Positive样本划分为Positive之外,还需要不能将Negative样本划分为Positive。
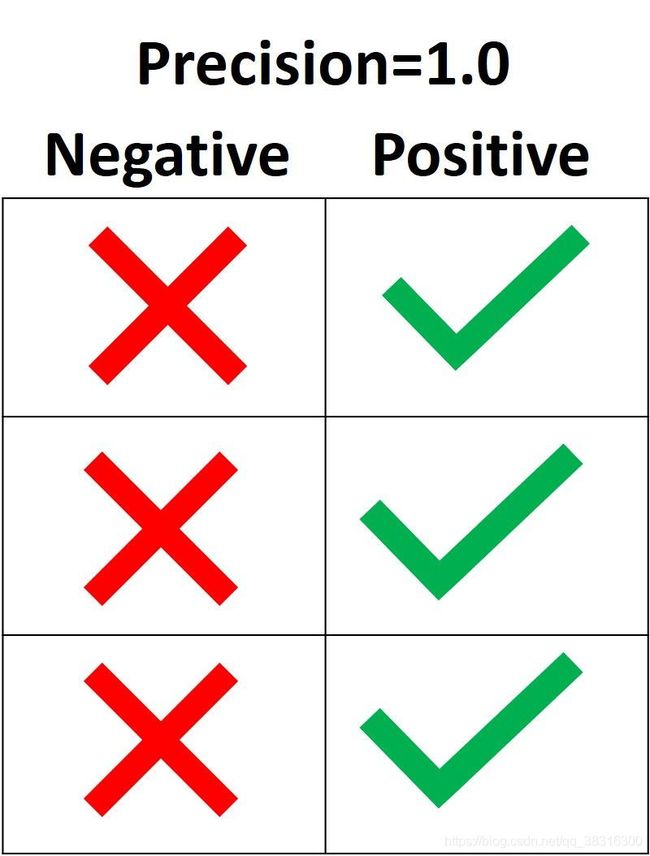
在Scikit-learn库函数中,sklean.metrics模块有一个叫做precision_score()的函数,它接收ground-truth和prediction标签,然后返回精确率,而pos_label参数接收Positive类别的标签。
import sklearn.metrics
y_true = ["positive", "positive", "positive", "negative", "negative", "negative"]
y_pred = ["positive", "positive", "negative", "positive", "negative", "negative"]
precision = sklearn.metrics.precision_score(y_true, y_pred, pos_label="positive")
print(precision)输出结果就是:
0.66666666666666664.3 Recall
召回率表示模型预测正确的Positive样本的个数与ground truth中Positve样本个数的比值。它用来衡量该模型检测出Positive样本的能力。召回率越高,说明该模型越能检测出positive样本。

召回率只关心ground truth中positive的样本被如何划分,它和ground truth中negative的样本被如何划分是相互独立的。当这个模型将所有的positive样本都划分为Positive,这时候召回率就为100%。在下一张图中,由四中不同的情况(A到D),而它们的召回率都是0.667。四种情况中只有Negative样本被如何划分是变化的,而所有Positive样本被如何划分都是一样的,因此它们的召回率都是一样的,True positive的个数为2,而False negative的额个数为1,因此召回率就是:2 / (2+1) = 0.667:

因为召回率不关心Negative样本被如何划分,因此你可以忽略negative样本。在下面这张图中,你可以只考虑positive样本是如何划分的:

什么时候召回率会低或者会高?当召回率较高的时候,这意味着模型能够将Positive样本正确的划分为Positive。因此,可以相信模型检测出positive样本的能力。在下一张图中,召回率是1.0,这是因为所有的positive样本都被正确地划分为Positive。True Positive为3,并且False Negative为0,因此召回率就等于3 / (3+0) = 1。这意味着该检测模型能够检测出所有的positive样本。

另一种情况下,当模型未能检测出任何positive样本的情况下,召回率就为0.0。在下一张图中,所有的positive样本都被错误地划分为Negative。这意味着模型不能够检测出positive样本。

和precision_score()函数类型,在sklearn.metrics模块下还有一个recall_score()函数。我们仍然以上一节中的例子,其召回率如下:
import sklearn.metrics
y_true = ["positive", "positive", "positive", "negative", "negative", "negative"]
y_pred = ["positive", "positive", "negative", "positive", "negative", "negative"]
recall = sklearn.metrics.recall_score(y_true, y_pred, pos_label="positive")
print(recall)0.6666666666666666学习了精确率和召回率之后,我们来总结一下:
(1)召回率(查全率)表示模型能够检测出positive样本的能力,而精确率(查准率)表示模型检测出的positive样本的准确率。一个偏重于全,一个偏重于准。
(2)精确率既要考虑到positive样本,又要考虑negative样本,但是召回率只需要考虑positive样本。
(3)当一个模型的召回率较高而精确率较低的时候,说明该模型预测结果由有较多的positive;当召回率较低而精确率较高的时候,说明该模型的预测结果有较多的negative。
5 使用精确率还是召回率?
具体情况具体分析,这是因为使用精确率还是准确率要依赖于我们需要解决什么样的问题。如果我们需要检测出所有的positive样本(并不需要考虑negative样本被划分的情况),我们可以使用召回率。如果我们所处理的问题对样本划分为Positive比较敏感,也就是说需要考虑Negative样本被错误的划分为Positive的情况,就可以使用精确率。
设想给你一张图像,让你去找出图像中所有的车,你使用哪一个指标》因为要找到所有的车,我们可以使用召回率。如果给你一张医学检测图像,然你检测该病人是否患病,你应该使用哪一个指标》因为要考虑到是否患病,你就需要考虑将Negative划分为Positive的情况,因此可以使用精确率。