python爬取B站视频历史弹幕,并去除同标签的重复弹幕,暴力拿下所有弹幕。
嘻嘻嘻,今天我们来爬小B站的弹幕。
文章目录
- 前言
-
- 一、爬取历史弹幕的思路讲解
-
- 1.如何找到弹幕的爬取位置
- 2.如何找到历史弹幕的位置
- 二、代码讲解部分
-
- 1.引入库
- 2.编写自己的headers
- 3.编写视频的oid与爬取的开始年份与结束年份
- 4.编写历史月份的网址后缀
- 5.爬取有效的历史弹幕网址的日期后缀
- 5.访问每一个历史弹幕网址,爬取有效信息
- 6.写字典,构建数据框
- 6.去重数据
- 总结
-
-
- 本次爬取仅作为学习研究使用
-
前言
在写这篇博客前,我也在csdn上搜索了关于爬取B站弹幕的内容,怎么说呢,关于历史弹幕的爬取实际上是少的。
这个也好理解,因为有些B站视频它从那个发布到爬取的时候弹幕内容都不到3000条(我印象里弹幕列表里面是显示的最近的3000条),自然也没有爬取历史弹幕的必要了,其实实际上是可以得到的,我不仅要得到,也需要得到实际上不重复的,这也算补了csdn这块爬虫的空缺。
以下是本篇文章正文内容。
一、爬取历史弹幕的思路讲解
1.如何找到弹幕的爬取位置
这个也是爬取弹幕信息的第一步,我开始觉得是十分简单,但是实际操作起来还是有难度的。我们用B站视频寻味顺德为例。
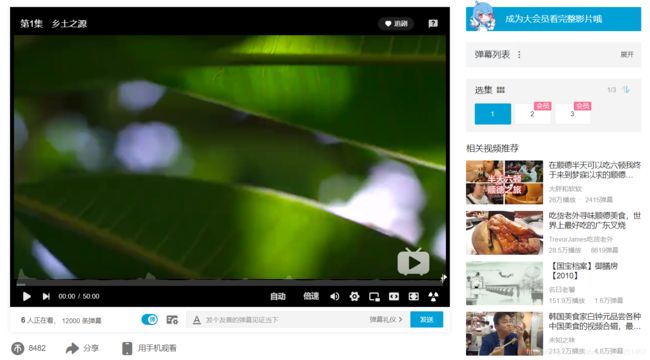
进入谷歌开发者工具,点击Network,展开弹幕列表,多点击几次查看历史历史弹幕,会出现很多xhr文件来,如果后面内容比较多可以点左上角的禁止符号,面板上的内容就会清理掉。
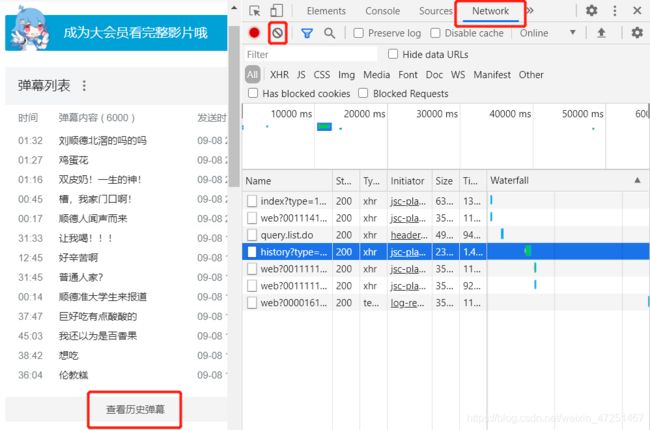
其实实际上一直点查看历史弹幕,是无法爬取到历史弹幕的,或者说连默认的弹幕列表里面的也爬不到,我们需要的是一个开头是history的文件,该文件的网址后缀是年月日形式的。
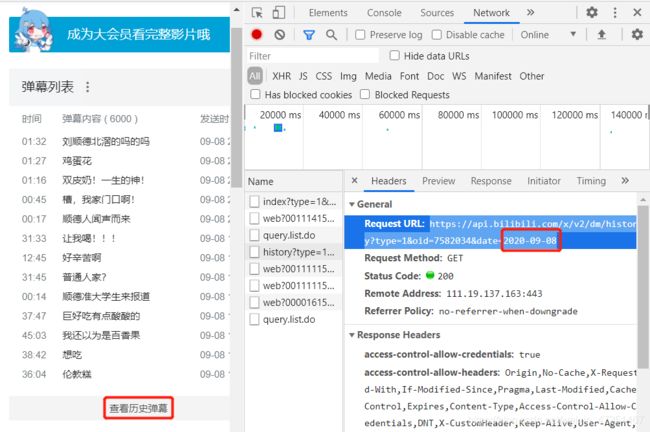
找到这个文件只需要先点击查看历史弹幕,再在页面上选择当日的(这个的是默认的最近多少条也是大部分的博主选择的爬取网址,这个网址是没有日期后缀的)或者其他日子的就可以在Network出现相应内容。
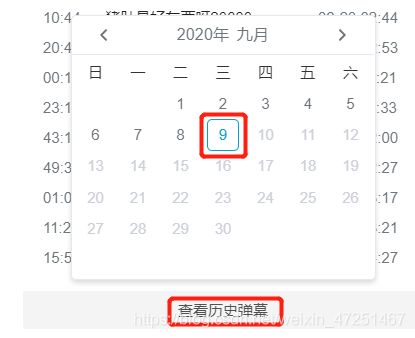
进入网址,就会发现这实际上就是一个又一个弹幕,其实到这里如果是爬取默认的弹幕的话,这块网站的部分就可以结束了,直接复制网址,爬取就欧克,不过历史弹幕的才是刚刚开始。

2.如何找到历史弹幕的位置
我们依旧是在查看历史弹幕这个选项里面下心思,那么网址的后缀是可变的那么直接编写网址的后缀不就好了,实际是方案是可行的,不过有些繁琐了。
我在网址分析的时候发现B站会把有新弹幕的日期存在一个xhr文件里面,找到这个文件也很简单,只需要在查看历史弹幕那块进行月份的切换,边切边在Network找文件前缀是index,网址的后缀是年月形式的。

访问的结果是这样的,其实在这里大致的思路已经出来了,编写月份的网址,循环遍历月份的网址,提取出来含有新弹幕的日期,再通过这些日期编写当天的历史弹幕的网址,最后循环遍历将弹幕信息全部爬出来,爬取结束。
![]()
二、代码讲解部分
1.引入库
代码如下:
import re,requests,time,pandas as pd,json
json库是为了在月份里提取有效日期所使用的,其他的都好理解。
2.编写自己的headers
参数还是谷歌开发者工具里找就可以找到,字典形式用键值对连接起来,这里就不打完整代码了,大家自己都用自己的就好,我一般用的是cookie和user-agent这两个参数,当然爬B站弹幕这两个也是必备的。
h={'cookie':'自己的cookie',
'user-agent':'自己的user-agent'}
3.编写视频的oid与爬取的开始年份与结束年份
这个oid实际上在历史月份与历史日期的网址都是有的,如果仅仅是爬一次的话,那略过这里也是可以的,后期把循环编写的部分改掉就好,年份那块也是一样,这只是笔者的习惯罢了。
oid='7582034'
begin=2019###在这里输入你需要爬取的最初年份
end=2020###这里是结束年份
4.编写历史月份的网址后缀
y_m=[]###这个用来存年月份数据
for sz1 in range(begin,end+1):
for sz2 in range(1,13):
y_m.append(str(sz1)+'-0'+str(sz2))
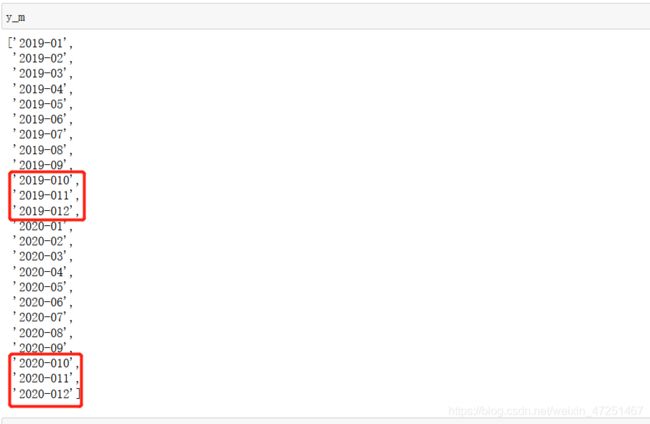
实际上这样编写,会出现如上图所示的情况,我把这样的后缀加到基出网址上访问,得到的不是我们需要的内容,我们需要对这样的进行替换,使它变成有效的后缀。
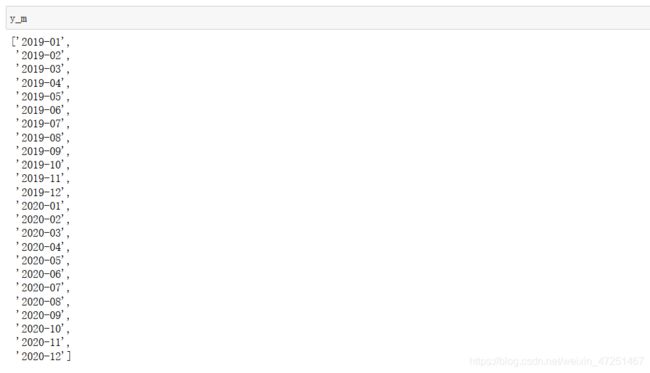
for s1 in range(len(y_m)):
y_m[s1]=re.sub('-010','-10',y_m[s1])
y_m[s1]=re.sub('-011','-11',y_m[s1])
y_m[s1]=re.sub('-012','-12',y_m[s1])
上面我编写的代码,出来的效果是非常成功的。
5.爬取有效的历史弹幕网址的日期后缀
前面的月份的后缀在这里也就用到了https://api.bilibili.com/x/v2/dm/history/index?type=1&oid='+oid+'&month='+月份后缀
这里需要看一下月份的网址,我在这截了一段。
{“code”:0,“message”:“0”,“ttl”:1,“data”:[“2020-08-01”,“2020-08-02”,“2020-08-03”,“2020-08-04”,“2020-08-05”,“2020-08-06”,“2020-08-07”,“2020-08-08”,“2020-08-09”,“2020-08-10”,“2020-08-11”,“2020-08-12”,“2020-08-13”,“2020-08-14”,“2020-08-15”,“2020-08-16”,“2020-08-17”,“2020-08-18”,“2020-08-19”,“2020-08-20”,“2020-08-21”,“2020-08-22”,“2020-08-23”,“2020-08-24”,“2020-08-25”,“2020-08-26”,“2020-08-27”,“2020-08-28”,“2020-08-29”,“2020-08-30”,“2020-08-31”]}
很明显的用json就一部到位json.loads(''.join(文本))['data'],那么这里的代码也迎刃而解了。
Month_day=[]#这里用来存有效的日期
for _y_m in y_m:
Q=requests.get('https://api.bilibili.com/x/v2/dm/history/index?type=1&oid='+oid+'&month='+_y_m,headers=h)
if re.findall('("data":null)',Q.text)==['"data":null']:
print(oid+'的'+_y_m+'无效')
else:
Month_day=Month_day+json.loads(''.join(Q.text))['data']
print(oid+'的'+_y_m+'已到位')
time.sleep(20)
这里的时间休眠设了20秒,实际上不需要那么长,大概来个5秒就好,我设置的长是因为我都是晚上爬,时间多(实际是害怕被B站关小黑屋)。
这里也做了一个判断,是因为前面编写月份后缀的时候,没有办法排错的,在这里进行了排错,下面的是未存在的月份的页面反馈。
![]()
这里也是直接用正则做的判断,看看运行中打印的效果,还是蛮不错的。

5.访问每一个历史弹幕网址,爬取有效信息
这块就进行到爬取历史弹幕的网址了,看看网站吧。
有弹幕的部分,这个好理解,可是前面的数字都代表什么呢,这些要去问问度娘。

那自己需要什么呢,自己自行判断,博主这里选择了3个内容进行爬取,都是用的正则,看自己习惯吧,自己喜欢用那个就好。
dm=[]#弹幕主体
sjend=[]#弹幕发布时间
spsjend=[]#弹幕在视频中出现的位置
for _m_d in Month_day:
q=requests.get('https://api.bilibili.com/x/v2/dm/history?type=1&oid='+oid+'&date='+_m_d,headers=h)
txt=q.content.decode("utf-8")
dm=dm+re.findall('(.*?) ',txt)
sj=re.findall('.*? ',txt)
for zy in sj:
zy=time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime(int(zy)))
sjend.append(zy)
spsj=re.findall('.*? ',txt)
for zy1 in spsj:
zy1=time.strftime('%M:%S', time.gmtime(int(re.sub('\.\d+','',zy1))))
spsjend.append(zy1)
print(oid+'的'+_m_d+"已完成")
time.sleep(20)
在中间使用到了time.strftime()这个方法,用来做时间的转换,要求都是int格式的,所以做了一些操作。
6.写字典,构建数据框
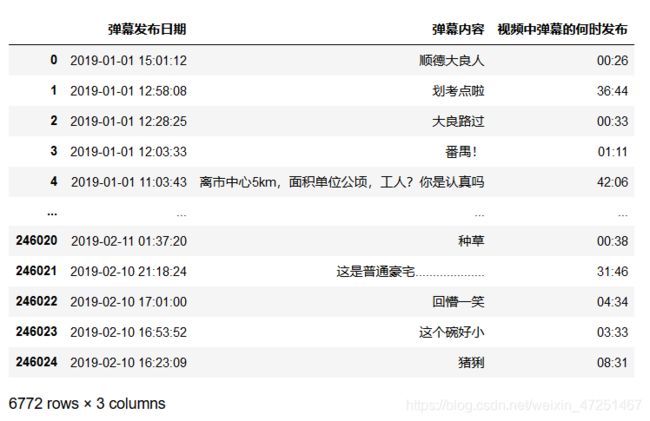
zd={'弹幕发布日期':sjend,'弹幕内容':dm,'视频中弹幕的何时发布':spsjend}
bg=pd.DataFrame(zd)
第五步运行完,爬取的内容就算结束了,这里是运行了10来页爬到的内容,是十分不错的,下面就是要做是处理掉三项都重复的数据。

6.去重数据
bgz=bg.drop_duplicates(subset=['弹幕发布日期','弹幕内容','视频中弹幕的何时发布'])
这里采取的是按照多列去重,看看去重完的数据。
25w去重变6000多,但的的确确是这样的,不过这只是一个来月的数据,并且不是热播时期,这样的结果已经很满意了。
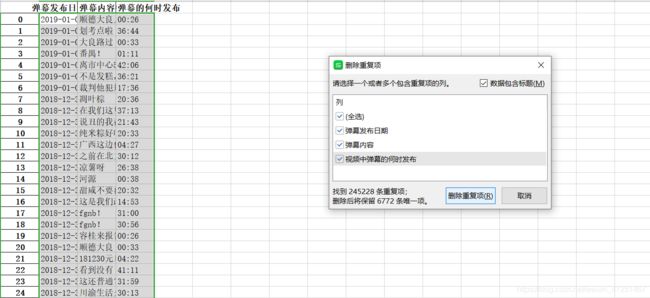
用excel去重的效果也是一样,证明代码可行,弹幕积少成多嘛。
总结
这种对历史弹幕的爬取还是十分容易理解的,不过最后的筛选我考虑的还是少了一些,会不会出现这种情况,在同一秒里同一时刻不同的人发布了相同的弹幕内容。
实际上,这样的情况我在写的时候是没有考虑到的,解决这种的方法还是有的,就是把去重时所考虑的参数增多(增加其他参数),或者再爬取时不用改为标准时间格式,去重后改为标准时间。这样也可以更加精准一点。
因为B站历史弹幕的特殊变换,爬取是十分暴力的,不过也得到了可观的效果,思路比较直接。
第一次编辑时间:2020/09/09