pytorch与paddlepaddle对比——以DCGAN网络实现为例
pytorch与paddlepaddle对比——以DCGAN网络实现为例
本文以手写数字生成实现为例对pytorch和paddlepaddle进行对比
参考资料:
- DCGAN原理分析与pytorch实现
- DCGAN论文详解
- PaddlePaddle与PyTorch的转换
一、pytorch与paddle对比
PaddlePaddle 2.0和PyTorch风格还是非常像的。使用PaddlePaddle可以直接调用百度AI Studio里的一些资源(包括GPU、预训练权重之类的),而且说明文档、社区都是中文的,比较友好;而PyTorch在Github有更多的代码与资源,两者配合使用是比较香的。下面整理了一些PaddlePaddle以及PyTorch中对应的函数。当然,最好的使用方法是知道对应关系之后, 去PyTorch、PaddlePaddle官网上的数据手册查看具体说明
- 官方对比链接:PyTorch-PaddlePaddle API映射表
二、DCGA原理分析
1、什么是生成对抗网络
生成对抗网络(GAN),包含生成器和判别器,两个模型通过对抗过程同时训练。
生成器,可以理解为“艺术家、创造者”,它学习创造看起来真实的图像。
判别器,可以理解为“艺术评论家、审核者”,它学习区分真假图像。
训练过程中,生成器在生成逼真图像方便逐渐变强,而判别器在辨别这些图像的能力上逐渐变强。
当判别器不能再区分真实图片和伪造图片时,训练过程达到平衡。
2、DCGAN网络架构
DCGAN主要是在网络架构上改进了原始GAN,DCGAN的生成器与判别器都利用CNN架构替换了原始GAN的全连接网络,主要改进之处有如下几个方面:
- DCGAN的生成器和判别器都舍弃了CNN的池化层,判别器保留CNN的整体架构,生成器则是将卷积层替换成了反卷积层(fractional-strided convolution)或者叫转置卷积层(Convolution Transpose)。
- 在判别器和生成器中在每一层之后都是用了Batch Normalization(BN)层,有助于处理初始化不良导致的训练问题,加速模型训练,提升了训练的稳定性。
- 利用1*1卷积层替换到所有的全连接层。
- 在生成器中除输出层使用Tanh(Sigmoid)激活函数,其余层全部使用ReLu激活函数。
- 在判别器所有层都使用LeakyReLU激活函数,防止梯度稀。
DCAGN通过以上的改进得到的生成器结构如下:
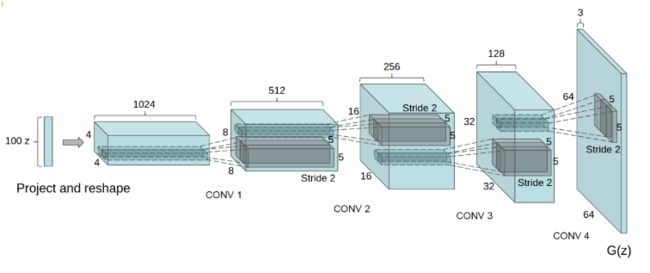
三、DCGAN手写数字生成

四、paddle实现DCGAN
本文只提供paddle版本的链接(pytorch代码是我对应paddle版本手敲的),建议pytorch版本和paddle版本分屏查看,从导入对应的包开始一一对应查看。其实pytorch和paddle区别很小,具体功能实现都很相似,希望在对照学习中能带给你启发。
- 如何从pytorch过度到paddle?——以DCGAN网络实现为例
五、pytorch实现DCGAN
import os
import random
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets
from torch.utils.data import DataLoader
from torchvision import transforms
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
# 定义数据集
dataset = datasets.MNIST(root='dataset/mnist/', train=True, download=True,
transform = transforms.Compose([
# resize -> (32,32)
transforms.Resize((32,32)),
# 将原始图像PIL变为张量tensor(H*W*C)
transforms.ToTensor(),
# 归一化到 -1~1
transforms.Normalize([127.5], [127.5])
]))
dataloader = DataLoader(dataset, shuffle=True, batch_size=32,num_workers=0)
#看看输入图片的维度
for data in dataloader:
break
data[0].shape
#参数初始化的模块,和paddle不一样
def weights_init(m):
classname = m.__class__.__name__
if hasattr(m, 'weight') and classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0) # nn.init.constant_()表示将偏差定义为常量0
# Generator Code
class Generator(nn.Module):
def __init__(self, ):
super(Generator, self).__init__()
self.gen = nn.Sequential(
# input is Z, [B, 100, 1, 1] -> [B, 64 * 4, 4, 4]
nn.ConvTranspose2d(100, 64 * 4, 4, 1, 0, bias=False), # 注意这个方法和paddle的名字区别和bias的区别
nn.BatchNorm2d(64 * 4),
nn.ReLU(True),
# state size. [B, 64 * 4, 4, 4] -> [B, 64 * 2, 8, 8]
nn.ConvTranspose2d(64 * 4, 64 * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 2),
nn.ReLU(True),
# state size. [B, 64 * 2, 8, 8] -> [B, 64, 16, 16]
nn.ConvTranspose2d( 64 * 2, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
# state size. [B, 64, 16, 16] -> [B, 1, 32, 32]
nn.ConvTranspose2d( 64, 1, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, x):
return self.gen(x)
netG = Generator()
netG.apply(weights_init)
# netG.load_state_dict(weights_init)
# Print the model
print(netG)
class Discriminator(nn.Module):
def __init__(self,):
super(Discriminator, self).__init__()
self.dis = nn.Sequential(
# input [B, 1, 32, 32] -> [B, 64, 16, 16]
nn.Conv2d(1, 64, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2),
# state size. [B, 64, 16, 16] -> [B, 128, 8, 8]
nn.Conv2d(64, 64 * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 2),
nn.LeakyReLU(0.2),
# state size. [B, 128, 8, 8] -> [B, 256, 4, 4]
nn.Conv2d(64 * 2, 64 * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(64 * 4),
nn.LeakyReLU(0.2),
# state size. [B, 256, 4, 4] -> [B, 1, 1, 1] -> [B, 1]
nn.Conv2d(64 * 4, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, x):
return self.dis(x)
netD = Discriminator()
netD.apply(weights_init)
print(netD)
# Initialize BCELoss function
loss = nn.BCELoss() # 二分类交叉熵损失
# Create batch of latent vectors that we will use to visualize
# the progression of the generator
fixed_noise = torch.randn([32, 100, 1, 1])
# Establish convention for real and fake labels during training
real_label = 1.
fake_label = 0.
# Setup Adam optimizers for both G and D
optimizerD = optim.Adam(netD.parameters(), lr=0.0002, betas=(0.5,0.999))
optimizerG = optim.Adam(netG.parameters(), lr=0.0002, betas=(0.5,0.999))
losses = [[], []]
#plt.ion()
now = 0
for pass_id in range(100):
for batch_id, (data, target) in enumerate(dataloader):
############################
# (1) Update D network: maximize log(D(x)) + log(1 - D(G(z)))
###########################
optimizerD.zero_grad()
real_img = data
bs_size = real_img.shape[0]
label = torch.full((bs_size, 1, 1, 1), real_label)
real_out = netD(real_img)
errD_real = loss(real_out, label)
errD_real.backward()
noise = torch.randn([bs_size, 100, 1, 1])
fake_img = netG(noise)
label = torch.full((bs_size, 1, 1, 1), fake_label)
fake_out = netD(fake_img.detach())
errD_fake = loss(fake_out,label)
errD_fake.backward()
optimizerD.step()
optimizerD.zero_grad()
errD = errD_real + errD_fake
losses[0].append(errD.detach().numpy())
############################
# (2) Update G network: maximize log(D(G(z)))
###########################
optimizerG.zero_grad()
noise = torch.randn([bs_size, 100, 1, 1])
fake = netG(noise)
label = torch.full((bs_size, 1, 1, 1), real_label)
output = netD(fake)
errG = loss(output,label)
errG.backward()
optimizerG.step()
optimizerG.zero_grad()
losses[1].append(errG.detach().numpy())
############################
# visualize
###########################
if batch_id % 100 == 0:
generated_image = netG(noise).detach().numpy()
imgs = []
plt.figure(figsize=(15,15))
try:
for i in range(10):
image = generated_image[i].transpose()
image = np.where(image > 0, image, 0)
image = image.transpose((1,0,2))
plt.subplot(10, 10, i + 1)
plt.imshow(image[...,0], vmin=-1, vmax=1)
plt.axis('off')
plt.xticks([])
plt.yticks([])
plt.subplots_adjust(wspace=0.1, hspace=0.1)
msg = 'Epoch ID={0} Batch ID={1} \n\n D-Loss={2} G-Loss={3}'.format(pass_id, batch_id, errD.detach().numpy(), errG.detach().numpy())
print(msg)
plt.suptitle(msg,fontsize=20)
plt.draw()
# plt.savefig('{}/{:04d}_{:04d}.png'.format('work', pass_id, batch_id), bbox_inches='tight')
plt.pause(0.01)
except IOError:
print(IOError)
paddle.save(netG.state_dict(), "generator.pth")