Pycharm中使用optuna调PyTorch超参基本操作
文章目录
- 0、基本流程
- 1、设定超参数搜索空间
- 2、记录训练过程`trial.report`
- 3、创建优化过程`optuna.create_study`
- 4、可视化`optuna.visualization`
-
- 4.1 等高线图
- 4.2 记录训练过程的intermediate
- 4.3 优化历史记录
- 4.4、高维度参数的关系图
- 4.5 超参重要性
- 4.6、参数关系切片图
- 5、安装
0、基本流程
import optuna
import plotly
from trainers import SimpleTrainer # 我自己写的训练器
import torch
from torch import nn
class BPNet(nn.Modules):
...
# 定义待优化的超参数目标函数
def objective(trial):
# 设定超参数搜索空间<1>
batch_size = trial.suggest_int('batch_size', 4, 7)
batch_size = 2 ** batch_size
flooding = trial.suggest_loguniform('flooding', 10 ** (-4), 10 ** (-2.5))
lr = trial.suggest_loguniform('lr', 10 ** (-2.5), 10 ** (-1.5))
weight_decay = trial.suggest_loguniform('weight_decay', 10 ** (-2.5), 10 ** (-1.5))
# network generation
model = BPNet(input_dim)
weight_p, bias_p = [], []
for name, p in model.named_parameters():
if 'bias' in name:
bias_p += [p]
else:
weight_p += [p]
optimizer = optim.Adam(
[{'params': weight_p, 'weight_decay': weight_decay},
{'params': bias_p, 'weight_decay': 0}
], lr=lr
)
criterion = nn.MSELoss()
# trainer
trainer = SimpleTrainer(net=model, batch_size=batch_size, num_epoch=num_epoch,
optimizer=optimizer, criterion=criterion, mode='adjust',
flooding=flooding, tsb_track=None, device='cuda',
print_interval=1, early_stop=70)
vali_acc_track = []
_, _, max_vali_acc, vali_acc_track = trainer.train(x_train, x_vali, t_train, t_vali)
# 如有需要,记录每个epoch的vali_acc<2>
if len(vali_acc_track):
for step, vali_acc in enumerate(vali_acc_track):
trial.report(vali_acc, step=step)
return max_vali_acc
# 创建优化过程<3>
study = optuna.create_study(study_name='baseline_reg',direction='maximize',storage='sqlite:///db.sqlite3')
# 开始优化
study.optimize(objective, n_trials=4)
# 可视化<4>
importance = optuna.visualization.plot_param_importances(study)
plot.offline.plot(importance)
下面针对代码中四处注释分别进行详细说明
1、设定超参数搜索空间
下面介绍的方法都是trial的方法,注意,用户无需自己实例化trial。另外,搜索的区间是闭区间,两端都能取到。

optuna将suggest_discrete_uniform、suggest_uniform、suggest_loguniform封装在了suggest_float中。
suggest_float(name: str, low: float, high: float, *, step: Optional[float] = None, log: bool = False) → float
注意:step与log不能同时使用,如果设定step,默认为discrete_uniform模式;如果设定log为True,默认为loguniform模式。
除了以上几种采样方法,optuna还提供了suggest_int和suggest_categorial
示例
suggest_int感觉上和suggest_float没啥区别,只不过输出整型。
suggest_int(name: str, low: int, high: int, step: int = 1, log: bool = False) → int
这边的log参数可以进行对数均匀采样,意思是说把 [ 1 , 10 ] [1,10] [1,10]这个区间映射到 [ 0 , ln 10 ] [0,\ln10] [0,ln10],再在 [ 0 , ln 10 ] [0,\ln10] [0,ln10]区间上均匀采样,因此较小的值更容易被采到。
所以我如果batch_size要选择2,4,8,16,32,64,128…这些值,还是没法用这个方法直接得到,而必须先在 [ 1 , 7 ] [1,7] [1,7]上均匀采出一个整数,然后再进行2的乘方运算。
suggest_categorial
kernel = trial.suggest_categorical('kernel', ['linear', 'poly', 'rbf'])
clf = SVC(kernel=kernel, gamma='scale', random_state=0)
2、记录训练过程trial.report
如果我要比较不同的trial训练过程,比方说在某个epoch损失下降到多少或者准确度上升到多少,可以用trial.report进行跟踪。在我写的基本流程里,因为我的训练器是训练完所有epoch才输出结果,所以我只能输出一个存储了loss或者acc(称之为中间值intermediate)的列表,然后用for循环把这些intermediate放到trial里。
当然,也可以像下面这样(来自官方doc),每训练一个epoch记录一次。
for step in range(100):
clf.partial_fit(X_train, y_train, np.unique(y))
intermediate_value = clf.score(X_valid, y_valid)
trial.report(intermediate_value, step=step)
3、创建优化过程optuna.create_study
optuna.study.create_study(storage=None, sampler=None, pruner=None, study_name=None, direction='minimize', load_if_exists=False)
我用过的关键字参数只有storage, study_name, direction,所以我只讲这三个参数,别的我不熟悉,您可以参阅官方doc。
- storage设置保存路径,一般是保存成sqlite,像下面这样:
storage='sqlite:///db.sqlite3',其中db是文件名,您可以随意设置。如storage='sqlite:///foo.sqlite3'。 study_name是您这个优化过程的名字,因为一个sqlite文件里面可以放好多个,第二次存储的时候,如果是同一个存储路径,需要修改study_name。direction设置优化方向,如果是loss,应该下降,设置成'minimize',也是缺省值;如果是accuracy,应该上升,设置成'maximize'。
补充:pruner作用是对无望的trial剪枝,所谓剪枝就是如果选的是比较烂的超参数,就提前终止
为什么要保存呢?下面这段话来自这篇知乎文章
出于各种目的,我们经常有保存优化过程的需求。比如你可能需要追踪或者debug 一个目标函数的优化过程,比如目标函数的参数空间太大,而一旦机器崩溃,你的优化过程必须从头再来。又或者,你想实现多台机器并行优化一个目标函数,这时候一个能保存优化试验历史并且能从中恢复/继续优化的特性就显得尤其重要。而 Optuna 支持这种特性。
所以保存了以后如何加载出来呢?
语法是这样
optuna.study.load_study(study_name, storage, sampler=None, pruner=None)
我一般这么用
study = optuna.study.load_study('baseline_reg','sqlite:///db.sqlite3')
4、可视化optuna.visualization
4.1 等高线图
如果有n个参数,则给出 n ( n − 1 ) n(n-1) n(n−1)幅等高线图。
graph_cout = optuna.visualization.plot_contour(study,['batch_size','lr','weight_decay'])
plotly.offline.plot(graph_cout)
注意,因为这是在Pycharm里,所以我只能用offline的模式显示绘出的图,如此会弹出一个plotly生成的网页,这个html网页会保存在当前目录下,如果不指定文件名,缺省值是'temp-plot.html'。

因为横纵坐标不能都是同一个参数,所以对角线上没有,这就是 n ( n − 1 ) n(n-1) n(n−1)个图的来历。令我很迷惑的是,等高线竟然交叉了???所以我决定放弃使用等高线图来visualize。
4.2 记录训练过程的intermediate
画出这个图前提是在objective函数里调用了trial的report方法。具体见第二节。
interm = optuna.visualization.plot_intermediate_values(study)
plotly.offline.plot(interm,filename='baseline_interm.html')

如果训练过程振荡的厉害,图会比较丑,更要吐槽的是他不给图例,只能把光标移动到折线上才显示,所以,我也不采用!
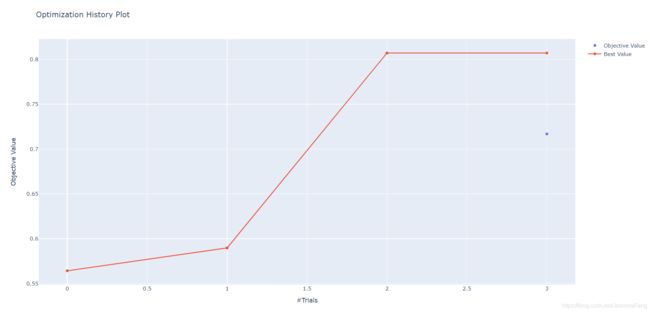
4.3 优化历史记录
这个可视化感觉上还可以,红色线是已达到的最优值(当前最小loss或当前最大accuracy),蓝色点是当前值。
history = optuna.visualization.plot_optimization_history(study)
plotly.offline.plot(history)
4.4、高维度参数的关系图
把一个trial的所有超参数和objective value连在了一起,看起来好像有一点点乱,但这个图比较牛b,让人看起来很炫酷。至少比等高线图好一点,因为这里只输出一张图。
parallel = optuna.visualization.plot_parallel_coordinate(study,['batch_size','weight_decay','lr','flooding'])
plotly.offline.plot(parallel)

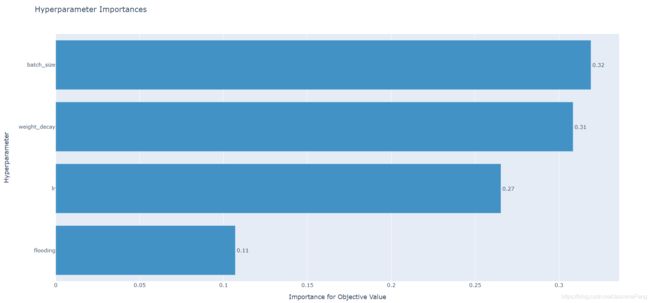
4.5 超参重要性
重要性指标默认下是根据平均不纯度下降值(MDI)算出来的,具体您可以参阅官方doc。
importance = optuna.visualization.plot_param_importances(study)
plotly.offline.plot(importance)
4.6、参数关系切片图
点很少,看起来不那么exciting。
slices= optuna.visualization.plot_slice(study,['batch_size','weight_decay','lr','flooding'])
plotly.offline.plot(slices)

5、安装
plotly这个包我建议用conda命令安装。
conda install -c plotly plotly
optuna可以用pip。
optuna-dashboard是一个自动化可视化的界面,不用自己plot,具体可以参考该博主文章。我试了之后感觉高位参数关系图没有optuna的好,但dashboard比较好的是有一个可以拖动的表格,这样我就不用把结果输出为excel再看了。
另一个需要说明的是,如果用dashboard,并不一定要像那个博主一样把sqlite文件放到主目录下,这样不方便管理,看起来很乱。我喜欢在终端先cd到存放sqlite文件的目录,再用
optuna-dashboard