[CPNet]阅读笔记粗略记录-cfsong
写在前边,这是很久之前看的。具体内容已经忘记,把过程粗略写出来供大家参考吧
Context Prior for Scene Segmentation
Abstract:有监督
最近的语义分割工作广泛探索了上下文相关性,以实现更准确的细分结果。但是,大多数方法很少区分不同类型的上下文依赖项,这可能会有损场景理解。在这项工作中,我们直接监督特征聚合以清楚地区分类内和类间上下文信息。具体来说,我们在Affinity Loss监督下开发出Context Prior(上下文先验)。 给定输入图像和相应的gt,Affinity Loss将构建Ideal Affinity Map,以监督Context Prior(上下文先验)的学习。 所学习的上下文先验提取属于同一类别的像素,而相反的先验则专注于不同类别的像素。 通过嵌入到传统的深度CNN中,提出的上下文先验层可以选择性地捕获类内和类间上下文相关性(同一类越近越好,不同类越远越好),从而实现可靠的特征表示。 为了验证有效性,我们设计了有效的上下文先验网络(CPNet)。大量的定量和定性评估表明,所提出的模型与最新的语义分割方法相比具有良好的表现。 更具体地说,我们的算法在ADE20K上达到46.3%的mIoU,在PASCAL-Context上达到53.9%的mIoU,在Cityscapes上达到81.3%的mIoU。
问题背景:
![[CPNet]阅读笔记粗略记录-cfsong_第1张图片](http://img.e-com-net.com/image/info8/cd1a1ec8fa5c470d8ab9d9b1a3442b52.jpg)
当前在上下文信息依赖上的语义分割工作主要有两种:
1)基于金字塔的聚合方法。几种方法采用基于金字塔的模块或全局池来规则聚合局部区域或全局上下文详细信息。但是,它们捕获了同质的上下文关系,而忽略了不同类别的上下文相关性。如图1(b)所示。当场景中存在混淆类别时,这些方法可能会导致上下文可靠性降低。
2)基于注意力的聚合方法。最近的基于注意力的方法学习通道注意力,空间注意力或像素点注意力以选择性地聚集异构上下文信息。但是,由于缺乏显式的正则化,注意力机制的关系描述不太清楚。因此,它可能会选择不良的上下文依赖关系。如图1(e)所示。总体而言,这两种路径都在没有明确区分的情况下汇总了上下文信息,从而导致了不同上下文关系的混合。
针对以往方法上下文信息不区分类别的问题,本文通过构造Context Prior,以将类内和类间的依赖关系建模为先验知识。将上下文先验公式化为二进制分类器,以区分当前像素属于同一类别的像素,而相反的先验可以集中于不同类别的像素。具体来说,本文首先使用全卷积网络来生成特征图和相应的先验图。 对于特征图中的每个像素,先验地图可以选择性地突出显示属于同一类别的其他像素,以聚集类内上下文,而相反的先验可以聚集类间上下文。为了将先验嵌入网络,本文开发了一个包含Affinity Loss的Context Prior Layer,它直接监督先验的学习。 同时,上下文先验还需要空间信息来推理这些关系。 为此,设计了一个聚合模块,该模块采用完全可分离的卷积(在空间和深度维度上均分开)有效地聚合空间信息。
具体方法:3*3 7*7 11*11(11*1 1*11)
![[CPNet]阅读笔记粗略记录-cfsong_第2张图片](http://img.e-com-net.com/image/info8/d56b00e39cd0406ea48f91d2da061659.jpg)
先介绍一下整体流程,再细说每个模块:
1.经过Backbone Network生成特征图X,其尺寸为H × W × C0
2.使用可以聚合空间信息的Aggregatation Module生成H × W × C1特征图
3.经过1*1卷积,生成H × W × (H * W)尺寸特征图(改变通道数),再进行Reshape,得到(H * W) × (H * W)的Context Prior Map,其中p为与其他像素是否同类的概率
5.对经过类内先验§和类间先验(1-p)的特征图与输入X进行Concat
6.为了保证Context Prior Map的准确,引入Affinity Loss监督学习
- Affinity Loss
这里算的loss是Context Prior Map与经过GT生成的Ideal Affinity Map之间的损失。首先介绍一下,Context Prior Map中H * W为输入特征的像素点个数,(H * W) × (H * W)的意思是输入特征图中每个像素点与其他像素点是否为同类别的概率。算loss之前,需要先生成Ideal Affinity Map。
- Ideal Affinity Map
![[CPNet]阅读笔记粗略记录-cfsong_第3张图片](http://img.e-com-net.com/image/info8/1e49f649d92c4c97b19e73246907b9e4.png)
N*C C*N = N*N
- Input image I -> Feature map X(H*W)
- Ground Truth L
- down-sample L into
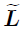
- one-of-Kscheme(one-hot encoding) to
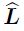 (H*W*C)
(H*W*C) - reshape N*C (N=H*W)
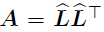 (N*N)
(N*N)
![[CPNet]阅读笔记粗略记录-cfsong_第4张图片](http://img.e-com-net.com/image/info8/79640aab69e34056a9fb64bf02d3d965.jpg)
- Binary cross Entropy
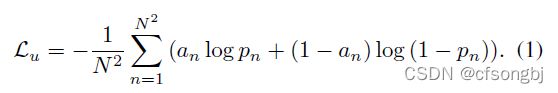
其中:PreDicted Prior Map P ![]()
Ideal Affinity Map A, ![]()
![[CPNet]阅读笔记粗略记录-cfsong_第5张图片](http://img.e-com-net.com/image/info8/ede708b7daf04b8fb52f54bf7631224e.jpg)
意思是将单个像素的类别预测与先验图全局的类内类间预测相关联。因此,Affinity Loss定义为:![[CPNet]阅读笔记粗略记录-cfsong_第6张图片](http://img.e-com-net.com/image/info8/0ad87db91cbe4d4ab848680413f6d2df.jpg)
![]()
二、Context Prior Layer即插
![[CPNet]阅读笔记粗略记录-cfsong_第7张图片](http://img.e-com-net.com/image/info8/3c18107b17114f77a6f7f977047ebd14.jpg)
![[CPNet]阅读笔记粗略记录-cfsong_第8张图片](http://img.e-com-net.com/image/info8/45ecbd3fb77748c7b4997a15563956a2.jpg)
- Input feature X

- Aggregation Module X to
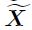 shape
shape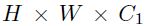
- 1*1Conv2d,bN,sigmoid P
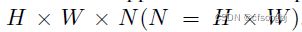 (改变通道数)
(改变通道数) - Reshape【H*W,H*W】
- Intra-Class
 其中
其中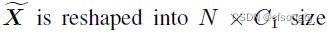
- Inter-Class
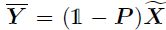
![[CPNet]阅读笔记粗略记录-cfsong_第9张图片](http://img.e-com-net.com/image/info8/69280026b3f2497f97bb888e8626bf50.jpg)
x2用于论文提出的AffinityLoss计算,output用于普通的softmax损失计算
三、Aggregatation Module:
The Context Prior Map require some local spatial imformation to reason the semantic correlation(由于上下文先验图需要一些局部空间信息来推理语义相关性)。 一般的卷积层3*3只能聚合周边的空域信息。一个自然的方法是用一个大的卷积核获取更多的空间信息,但是计算量太大了。因此,we factorize the standard convolution into two asymmetric convolutions spatially. 本文设计了一种高效的聚合模块,该模块具有完全可分离的卷积(在空间和深度维度上均独立),以聚合空间信息。![[CPNet]阅读笔记粗略记录-cfsong_第10张图片](http://img.e-com-net.com/image/info8/61e6c13d5af94f4dba3e44a59a23e900.jpg)
TensorFlow pytorch
class Agggregation(nn.Module):
def __init__(self, inChannel, outChannel): # num_classes == inChannel
super(Agggregation, self).__init__()
self.conv1 = nn.Conv2d(inChannel, outChannel, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(outChannel)
self.relu = nn.ReLU()
self.dsc1 = depthwise_separable_conv(outChannel, outChannel, kernel_size=(1, 11))
self.dsc2 = depthwise_separable_conv(outChannel, outChannel, kernel_size=(11, 1))
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu
x1 = self.dsc1(x)
x1 = self.dsc2(x1)
x2 = self.dsc2(x)
x2 = self.dsc1(x2)
x = x1 + x2
x = self.bn1(x)
x = self.relu(x)
return x
如上图所示,由于常规卷积无法提取空间信息,本文使用1 × k DW + k × 1 DW代替k × k 卷积,作者这种方式为Fully Separable Convolution.。 we set the filter size of the fully separable convolution in the aggretation Module as 11.
四、Network Architecture
![]()
![]()
![]()
Experiments:
Optimization: 0.9Momentum, 10-4weight decay,16 batch size。
![[CPNet]阅读笔记粗略记录-cfsong_第11张图片](http://img.e-com-net.com/image/info8/76153a6f2b2d4aca9f63730d8e7b9725.jpg)
1.消融实验:![[CPNet]阅读笔记粗略记录-cfsong_第12张图片](http://img.e-com-net.com/image/info8/0991edae62ab48338047fd6f8fb2b68f.jpg)
2.Aggregatation Module:![[CPNet]阅读笔记粗略记录-cfsong_第13张图片](http://img.e-com-net.com/image/info8/c4896207dd2d45ddb7ce5f974f8e5de4.jpg)
3.ADE20K:![[CPNet]阅读笔记粗略记录-cfsong_第14张图片](http://img.e-com-net.com/image/info8/2c7dd31990e74e5aa95b64b0f9f3aff0.jpg)
4.PASCAL-Context:![[CPNet]阅读笔记粗略记录-cfsong_第15张图片](http://img.e-com-net.com/image/info8/e50f7fd984a44b5c9650d53d4ec90006.jpg)
5.Context Prior Map:![[CPNet]阅读笔记粗略记录-cfsong_第16张图片](http://img.e-com-net.com/image/info8/489fe1be245846d2b842b97c470fe02b.jpg)