第二章 序列构成的数组
目录
和第一版的变化
内置序列总览
列表推导式和生成器表达式
列表推导式和可读性
Listcomps 对比 map 和 filter内置函数
笛卡尔积
生成器表达式
元组不仅仅是不可变列表
元组作为记录
元组作为不可变列表
比较元组和列表方法
拆包序列和可迭代对象
使用 * 抓取多余的项
在函数调用和序列字面量中使用 *进行拆包
嵌套拆包
序列的模式匹配
解释器中的模式匹配序列
切片
为什么切片和range不包括最后一项
切片对象
多维切片和省略号
给切片赋值
在序列中使用 + 和 *
构建列表组成的列表
序列的增量赋值
一个关于 += 赋值的谜题
list.sort 与 内置的 sorted方法
当列表不是首选时
数组
内存视图
Numpy
双向队列和其他队列
您可能已经注意到,提到的几个操作同样适用于文本、列表和表格。文本、列表和表格一起称为序列。 […] FOR 命令也可以在所有的序列上使用
--Geurts, Meertens, and Pemberton, ABC Programmer’s Handbook
在创建 Python 之前,Guido 是 ABC 语言的贡献者,这是一个为期 10 年的研究项目,旨在为初学者设计一个编程环境。ABC 引入了许多我们现在认为是“Pythonic”的想法:对不同类型序列的泛型操作、内置元组和映射类型、缩进结构、没有变量声明的强类型等等。Python 对用户如此友好并非偶然。
Python 继承了 ABC 对序列的统一处理。字符串、列表、字节序列、数组、XML 元素和数据库结果共享一组丰富的常见操作,包括迭代、切片、排序和拼接。
了解 Python 中可用的各种序列使我们不需要重新发明轮子,这些通用接口可以帮助我们把自己定义的API设计的和原生序列一样。
本章的大部分讨论都适用于一般的序列,从熟悉的list到 Python 3 中添加的 str 和 bytes 类型。此处还涵盖了有关列表、元组、数组和队列的特定主题,但 Unicode 字符串和字节序列的细节出现在第 4 章中。此外,这里的想法是涵盖准备使用的序列类型。创建自定义序列类型是第 12 章的主题。
这些是本章将涵盖的主要主题:
- 列表推导式和生成器表达式的基础知识;
- 使用元组作为记录,而不是使用元组作为不可变列表;
- 序列拆包和序列模式;
- 从切片读取和写入切片;
- 特殊的序列类型,如数组和队列
和第一版的变化
序列类型是 Python 中非常稳定的部分,因此这里的大部分变化不是更新,而是对 Fluent Python 第一版的改进。最重要的包括以下几点:
- 容器序列和扁平序列的对比,序列内部结构的描述和图解
- 列表与元组的性能和存储特性的简单比较
- 具有可变项的元组的注意事项,以及如何在需要的情况下对它们进行测试
我在第 5 章中将命名元组的覆盖范围移至“经典命名元组”,在那里将它们与 Typing.NamedTuple 和 @dataclass 进行比较。
Note:为了为新内容腾出空间并使页数保持在合理范围内,第一版中的使用 Bisect 管理有序的序列部分现在是 fluentpython.com 配套网站上的一个帖子。
内置序列总览
标准库提供了多种用 C 实现的序列类型:
- 容器序列:list、tuple 和 collections.deque 可以保存不同类型的数据,包括嵌套容器。
- 扁平序列:str、bytes、bytearray、memoryview 和 array.array ,这类序列只能容纳一种简单的类型
容器序列保存对其包含的对象的引用,这些对象可以是任何类型;扁平序列将序列内容的值存储在自己的内存空间中,而不是作为一个独立的对象。如下图所示:
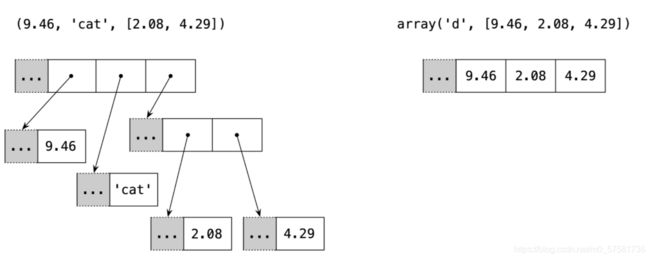
图 2-1。tuple和array的简化内存图,同时包含3个项。灰色单元格代表每个 Python 对象的内存头——未按比例绘制。元组中包含一个对列表对象的引用。每个项都是单独的 Python 对象,也可能是对其他 Python 对象的引用,比如那个包含2个项的list。相比之下,Python 的array是一个单独的对象-拥有3个double类型的 C 语言数组。
因此,扁平序列更紧凑,但它们仅限于保存原始机器值,例如字节、整数和浮点数。
Note:
内存中的每个 Python 对象都有一个包含元数据的头。例如python中的float对象,有一个对象值的字段和两个元数据字段。在 64 位 Python 构建中,表示float对象的结构具有以下 64 位字段:
-
ob_refcnt: 对象引用计数; -
ob_type: 对象类型指针; -
ob_fval: 存储float值的C语言的 double对象。
这就是为什么浮点数数组比浮点数元组紧凑得多的原因:数组是一个保存浮点数原始值的单个对象,而元组由多个对象组成——元组本身和包含在其中的每个float对象
另一种对序列类型进行分组的方法是可变性:
可变序列:list, bytearray, array.array, collections.deque, and memoryview
不可变序列:tuple, str, and bytes
图 2-2 形象化的展示了可变序列如何从不可变序列继承所有方法,并且实现额外的方法。内置的具体序列类型实际上并没有继承 Sequence 和 MutableSequence 抽象基类 (ABC),但它们是 注册为ABC 虚拟子类(abc.Sequence和abc.MutableSequence)。
作为虚拟子类,tuple和list可以通过下面的测试:
>>> from collections import abc
>>> issubclass(tuple, abc.Sequence)
True
>>> issubclass(list, abc.MutableSequence)
True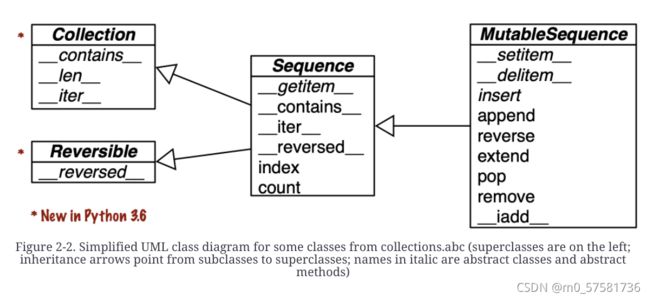
请记住这些共同特征:可变序列与不可变序列;容器序列与扁平序列。这样就可以将对一种序列类型的理论应用到其他类型。
最基本的序列类型是list:一个可变容器。我想您对列表已经非常熟悉了,因此我们将直接进入列表推导式,这是一种构建列表的强大方法,但有时未被充分利用,因为语法最开始可能看起来有些晦涩。掌握列表推导式为生成器表达式打开了大门,生成器可以生成各种类型的元素并用他们来填充序列。两者都是下一节的主题。
列表推导式和生成器表达式
构建序列的一种快速方法是使用列表推导式(如果目标是列表)或生成器表达式(对于其他类型的序列)。如果没有日常使用这些句法形式,我敢打赌您将错过编写更具可读性且速度更快的代码的机会。
如果您怀疑我声称这些结构“更具可读性”,请继续阅读。我会努力说服你。
TIP:
为简洁起见,许多 Python 程序员将列表推导式称为 listcomps,将生成器表达式称为 genexps。我也会用这些词。
列表推导式和可读性
这是一个测试:您觉得哪个更容易阅读,示例 2-1 还是示例 2-2?
例 2-1。从字符串构建 Unicode 码点列表
>>> symbols = '$¢£¥€¤'
>>> codes = []
>>> for symbol in symbols:
... codes.append(ord(symbol))
...
>>> codes
[36, 162, 163, 165, 8364, 164]例 2-2。使用 listcomp 从字符串构建 Unicode 码点列表
>>> symbols = '$¢£¥€¤'
>>> codes = [ord(symbol) for symbol in symbols]
>>> codes
[36, 162, 163, 165, 8364, 164]任何对 Python 有一点了解的人都可以阅读示例 2-1。然而,在了解了 listcomps 之后,我发现示例 2-2 更具可读性,因为它的意图是明确的。
for 循环可以用来做很多不同的事情:扫描一个序列来计数或选则项、计算聚合(总和、平均值)或任意数量的其他任务。 示例 2-1 中的代码正在构建一个列表。相比之下,listcomp 更为明确。它的目标是构建一个新列表。
当然,滥用列表推导式会编写出难以理解的代码。我见过带有 listcomps 的 Python 代码只是用来重复一段代码以消除其副作用。如果您没有对生成的列表执行某些操作,则不应使用该语法。另外,尽量保持简短。如果列表推导式跨越两行以上,最好将其拆分或重写为普通的旧 for 循环。使用您的最佳判断:对于 Python 和英语,清晰写作没有硬性规定。
语法提示:
在 Python 代码中,在 []、{} 或 () 对中会忽略换行符。所以你可以构建多行列表、listcomps、元组、字典等。不使用 \ 进行续行转义,如果您不小心在它后面键入一个空格,则该转义将不起作用。此外,当这些分隔符对用于定义具有逗号分隔的一系列项目的字面量时,将忽略尾随逗号。因此,例如,在对多行列表字面量进行编码时,最好在最后一项之后放置一个逗号,这样下一个编码人员就可以更轻松地向该列表中再添加一项,并减少读取差异时的噪音.
推导式和生成器表达式中的局部作用域:
在 Python 3 中,列表推导式、生成器表达式以及它们的兄弟 set 和 dict 推导式都有一个局部作用域来保存在 for 子句中分配的变量。但是,在这些推导式或表达式返回后,使用“海象运算符” := 赋值的变量仍然可以访问 - 这与函数中的局部变量不同。PEP 572—Assignment Expressions将 := 的目标范围定义为闭包函数,除非该目标有global或nonlocal声明。
>>> x = 'ABC'
>>> codes = [ord(x) for x in x]
>>> x 1
'ABC'
>>> codes
[65, 66, 67]
>>> codes = [last := ord(c) for c in x]
>>> last 2
67
>>> c 3
Traceback (most recent call last):
File "", line 1, in
NameError: name 'c' is not defined - x 没有被破坏:它仍然绑定到“ABC”;
- last变量被保留了下来
- c 只存在于 listcomp 中。
列表推导式通过过滤和转换项目从序列或任何其他可迭代类型构建列表。filter和map内置函数可以组合起来做同样的事情,但可读性会受到影响,我们将在接下来看到。
Listcomps 对比 map 和 filter内置函数
Listcomps 可以完成 map 和 filter 函数所做的一切,并且不会受到Python lambda 的扭曲导致的后果。考虑示例 2-3。
例 2-3。由 listcomp 和 map/filter 组合构建的相同列表
>>> symbols = '$¢£¥€¤'
>>> beyond_ascii = [ord(s) for s in symbols if ord(s) > 127]
>>> beyond_ascii
[162, 163, 165, 8364, 164]
>>> beyond_ascii = list(filter(lambda c: c > 127, map(ord, symbols)))
>>> beyond_ascii
[162, 163, 165, 8364, 164]我曾经相信 map 和 filter 比等效的 listcomps 更快,但 Alex Martelli 指出事实并非如此——至少在前面的例子中不是这样。Fluent Python 代码库中的 02-array-seq/listcomp_speed.py 脚本是一个简单的速度测试,将 listcomp 与 filter/map 进行比较。
我将在第 7 章中详细介绍 map 和 filter。现在我们转向使用 listcomps 计算笛卡尔积:一个包含由两个或多个列表中的所有项构建的元组的列表。
笛卡尔积
Listcomps 可以从两个或多个可迭代对象的笛卡尔积构建列表。构成笛卡尔积的项是由每个输入可迭代项的项组成的元组。result列表的长度等于输入可迭代对象的长度相乘。参见图 2-3。
例如,假设您需要生成有两种颜色和三种尺寸的 T 恤列表。示例 2-4 展示了如何使用 listcomp 生成该列表。结果有六个项。
例 2-4。使用列表推导式的笛卡尔积
>>> colors = ['black', 'white']
>>> sizes = ['S', 'M', 'L']
>>> tshirts = [(color, size) for color in colors for size in sizes] 1
>>> tshirts
[('black', 'S'), ('black', 'M'), ('black', 'L'), ('white', 'S'),
('white', 'M'), ('white', 'L')]
>>> for color in colors: 2
... for size in sizes:
... print((color, size))
...
('black', 'S')
('black', 'M')
('black', 'L')
('white', 'S')
('white', 'M')
('white', 'L')
>>> tshirts = [(color, size) for size in sizes 3
... for color in colors]
>>> tshirts
[('black', 'S'), ('white', 'S'), ('black', 'M'), ('white', 'M'),
('black', 'L'), ('white', 'L')]
- 这会生成一个按color排列的元组列表,然后是size。
- 请注意结果列表的排列方式,就好像 for 循环的嵌套顺序与它们在 listcomp 中出现的顺序相同。
- 要按大小排列项目,然后按颜色排列,只需重新排列 for 子句即可;在 listcomp 中添加换行符可以更容易地查看结果的排序方式。
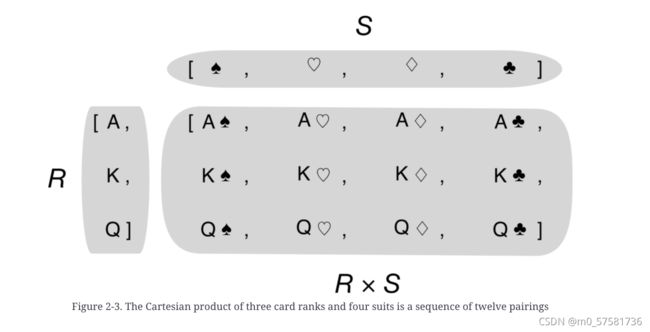
在示例 1-1(第 1 章)中,我使用以下表达式初始化一副牌组,其中包含来自 4 种花色的所有 13 个牌面的 52 张牌组成的列表,按花色排序然后排名:
self._cards = [Card(rank, suit) for suit in self.suits
for rank in self.ranks]Listcomps 只有一个目标:构建列表。要为其他序列类型生成数据,可以使用 genexp。下一节将在构建非列表序列的上下文中简要介绍 genexp。
生成器表达式
要初始化元组、数组和其他类型的序列,您也可以使用 listcomp ,但是 genexp 可以节省内存,因为它遵循迭代器协议逐个的产出项,而不是构建一个完整的列表来提供给某个构造函数。
Genexps 使用与 listcomps 相同的语法,但用圆括号而不是方括号括起来。
示例 2-5 展示了 genexps 构建元组和数组的基本用法。
例 2-5。从生成器表达式初始化元组和数组
>>> symbols = '$¢£¥€¤'
>>> tuple(ord(symbol) for symbol in symbols) 1
(36, 162, 163, 165, 8364, 164)
>>> import array
>>> array.array('I', (ord(symbol) for symbol in symbols)) 2
array('I', [36, 162, 163, 165, 8364, 164])-
如果生成器表达式是函数调用中的单个参数,则无需复制括号。
-
array构造函数接受两个参数,因此生成器表达式周围的括号是必需的。数组构造函数的第一个参数定义了用于数组中数字的存储类型,我们将在“数组”中看到。
示例 2-6 使用带有笛卡尔乘积的 genexp 打印出三种尺寸的两种颜色的 T 恤花名册。与示例 2-4 不同的是,内存中未构建由T 恤的六个项组成的列表:生成器表达式为 for 循环的每次循环生成一个项。
如果笛卡尔积中使用的两个列表各有 1,000 个项,则使用生成器表达式将节省构建包含一百万个项的列表以供 for 循环的成本。
例 2-6。生成器表达式中的笛卡尔积
>>> colors = ['black', 'white']
>>> sizes = ['S', 'M', 'L']
>>> for tshirt in (f'{c} {s}' for c in colors for s in sizes): 1
... print(tshirt)
...
black S
black M
black L
white S
white M
white L- 生成器表达式一一生成项;在此示例中从未生成包含所有六种 T 恤的列表的变量。
Note:
第 17 章详细解释了生成器的工作原理。这里的想法只是展示如何使用生成器表达式来初始化列表以外的序列,或者生成不需要保存在内存中的输出。
现在我们转到 Python 中的另一个基本序列类型:元组。
元组不仅仅是不可变列表
一些关于 Python 的教程将元组表示为“不可变列表”,但这没有完全概括元素的特点。元组有双重作用:它们可以用作不可变列表,也可以用作没有字段名称的记录。这种用法有时会被忽视,所以我们将从它开始。
元组和记录
元组保存记录:元组中的每个项保存一个字段的数据,项的位置给出了它的含义。
如果您将元组视为不可变列表,则项的数量和顺序可能重要也可能不重要,具体取决于上下文。但是当使用元组作为字段的集合时,项的数量通常是固定的,并且它们的顺序总是很重要的。
示例 2-7 显示了用作记录的元组。请注意,在每个表达式中,对元组进行排序都会破坏信息,因为每个字段的含义由其在元组中的位置给出。
例 2-7。用作记录的元组
>>> lax_coordinates = (33.9425, -118.408056) 1
>>> city, year, pop, chg, area = ('Tokyo', 2003, 32_450, 0.66, 8014) 2
>>> traveler_ids = [('USA', '31195855'), ('BRA', 'CE342567'), 3
... ('ESP', 'XDA205856')]
>>> for passport in sorted(traveler_ids): 4
... print('%s/%s' % passport) 5
...
BRA/CE342567
ESP/XDA205856
USA/31195855
>>> for country, _ in traveler_ids: 6
... print(country)
...
USA
BRA
ESP- 洛杉矶国际机场的经纬度。
- 关于东京的数据:名称、年份、人口(千)、人口变化(%)、面积(km²)。
- 格式为 (country_code,passport_number) 的元组列表。
- 当我们遍历列表时,passport 绑定到每个元组。
- % 格式化运算符理解元组并将每个项视为一个单独的字段。
- for 循环知道如何分别检索元组的项——这称为“拆包”。这里我们对第二项不感兴趣,所以我们将它分配给 _,一个虚拟变量。
TIP:
通常,使用 _ 作为虚拟变量只是一种约定。这只是一个奇怪但合法的变量名。在 match/case 语句中,_ 是一个通配符,它可以匹配任何值但从未被赋值。请参阅“与序列的模式匹配”。并且在 Python 控制台中,执行的前一条命令的结果被赋值给 _——除非这个结果是 None。
我们经常将记录视为具有命名字段的数据结构。第 5 章介绍了创建具有命名字段的元组的两种方法。
但通常,没有必要为了命名字段而麻烦地创建一个类,特别是如果您利用拆包并避免使用索引来访问字段。在示例 2-7 中,我们在一个语句中将 ('Tokyo', 2003, 32_450, 0.66, 8014) 分配给了 city、year、pop、chg、area。然后,% 运算符将passport元组中的每个项赋值给print参数中格式字符串中的相应位置。这是元组拆包的两个例子。
Note:
术语元组拆包被 Pythonistas 广泛使用,但可迭代对象拆包也将如此,如 PEP 3132 — Extended Iterable Unpacking的标题。“拆包序列和可迭代对象”不仅介绍了对元组的拆包,还介绍了一般的序列和可迭代对象的拆包。
现在让我们将tuple类视为list类的不可变的变体。
元组作为不可变列表
Python 解释器和标准库广泛使用元组作为不可变列表。这有两个主要好处:
- 明确:当你在代码中看到一个元组时,你知道它的长度永远不会改变。
- 性能:元组比相同长度的列表占用更少的内存,并且允许 Python 对项进行优化。
但是,请注意元组的不变性仅适用于其中包含的引用。元组中的引用不能被删除或替换。但是如果其中有某个引用指向一个可变对象,并且该对象发生了变化,那么元组的值就会发生变化。下面代码片段通过创建两个最初相等的元组(a 和 b)来演示这一点。当 b 中的最后一项发生变化,它们不再相等.图 2-4 表示内存中 b 元组的初始布局。
>>> a = (10, 'alpha', [1, 2])
>>> b = (10, 'alpha', [1, 2])
>>> a == b
True
>>> b[-1].append(99)
>>> a == b
False
>>> b
(10, 'alpha', [1, 2, 99])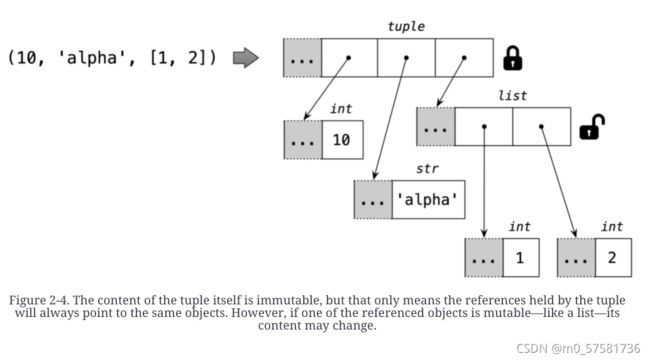
具有可变项的元组中可能会引入缺陷。正如我们将在“什么是可散列的?”中看到的,一个对象只有在其值永远不会改变时才是可散列的。不可散列的元组不能作为字典键或者集合的项。
如果要明确确定元组(或任何对象)的值是固定的,可以使用内置的hash方法来创建判断一个对象是否是固定的fixed函数,如下所示:
>>> def fixed(o):
... try:
... hash(o)
... except TypeError:
... return False
... return True
...
>>> tf = (10, 'alpha', (1, 2))
>>> tm = (10, 'alpha', [1, 2])
>>> fixed(tf)
True
>>> fixed(tm)
False除了这个警告外,元组被广泛用作为不可变列表。 Python 核心开发人员 Raymond Hettinger 在 StackOverflow 上对问题(Are tuples more efficient than lists in Python? )的回答中解释:元组具有性能优势。总而言之:
- 为了计算元组的字面量,Python 编译器通过一次操作为元组常量生成字节码;对于列表字面量,生成的字节码又将每个项作为单独的常量推送到数据栈,然后构建列表。
- 给定一个可散列的元组 t,tuple(t) 调用直接返回t的引用。根本无需复制,因为如果 t 是可散列的,则其值是固定的。相反,给定一个列表 l,list(l) 构造函数必须创建一个全新的l副本。
- 由于元组的长度是固定的,其实例分配到的内存空间是确定的。而list的实例分配有空闲空间,用以应对将来发生的append操作。
- 元组结构中的数组存储了元组中指向其各项的引用,而列表则包含一个指向存储在别的地方的引用数组的指针。间接寻址是必要的,因为当列表增长到超出当前分配的空间时,Python 需要重新分配引用数组以增加空间。额外的间接寻址降低了 CPU 缓存的效率
比较元组和列表方法
当使用元组作为列表的不可变变体时,最好知道它们的 API 很相似。正如您在表 2-1 中看到的那样,元组支持所有不涉及添加或删除项的列表方法,只有一个例外——元组缺少 __reversed__ 方法。然而,这只是为了优化;reversed(my_tuple) 可以正确执行。
| list | tuple | ||
|---|---|---|---|
|
|
● |
● |
|
|
|
● |
|
|
|
|
● |
Append one element after last |
|
|
|
● |
Delete all items |
|
|
|
● |
● |
|
|
|
● |
Shallow copy of the list |
|
|
|
● |
● |
Count occurrences of an element |
|
|
● |
Remove item at position |
|
|
|
● |
Append items from iterable |
|
|
|
● |
● |
|
|
|
● |
Support for optimized serialization with |
|
|
|
● |
● |
Find position of first occurrence of |
|
|
● |
Insert element |
|
|
|
● |
● |
Get iterator |
|
|
● |
● |
|
|
|
● |
● |
|
|
|
● |
|
|
|
|
● |
● |
|
|
|
● |
Remove and return last item or item at optional position |
|
|
|
● |
Remove first occurrence of element |
|
|
|
● |
Reverse the order of the items in place |
|
|
|
● |
Get iterator to scan items from last to first |
|
|
|
● |
|
|
|
|
● |
Sort items in place with optional keyword arguments |
a.反转运算符在第 16 章中进行了解释。
b.也用于覆盖子序列。请参阅“分配给切片”。
现在让我们切换到惯用 Python 编程的一个重要主题:元组、列表和可迭代对象的拆包。
拆包序列和可迭代对象
拆包很重要,因为它避免了不必要且容易出错的通过索引从序列中获得项。此外,拆包可以将任何可迭代对象作为数据源——包括不支持索引符号 [] 的迭代器。唯一的要求是可迭代对象在接收端为每个变量生成一个项,除非您使用星号 (*) 来捕获多余的项,如“Using * to grab excess items”中所述。
最明显的拆包形式是并行赋值;也就是说,将可迭代项中的项赋值给变量元组,如您在此示例中所见:
>>> lax_coordinates = (33.9425, -118.408056)
>>> latitude, longitude = lax_coordinates # unpacking
>>> latitude
33.9425
>>> longitude
-118.408056拆包的一个优雅应用是在不使用临时变量的情况下交换变量的值:
>>> b, a = a, b
另一个拆包示例是在调用函数时在参数前加上 * 前缀:
>>> divmod(20, 8)
(2, 4)
>>> t = (20, 8)
>>> divmod(*t)
(2, 4)
>>> quotient, remainder = divmod(*t)
>>> quotient, remainder
(2, 4)前面的代码展示了拆包的另一种用法:允许函数返回多个值为调用者提供方便。 作为另一个例子, os.path.split() 函数从文件系统路径构建一个元组 (path, last_part):
>>> import os
>>> _, filename = os.path.split('/home/luciano/.ssh/id_rsa.pub')
>>> filename
'id_rsa.pub'拆包时仅使用部分项的另一种方法是使用 * 语法,我们马上就会看到。
使用 * 获取多余的项
使用 *args 定义函数参数以获取任意多余的参数是一个经典的 Python 特性。
在 Python 3 中,这个想法被扩展到也适用于平行赋值:
>>> a, b, *rest = range(5)
>>> a, b, rest
(0, 1, [2, 3, 4])
>>> a, b, *rest = range(3)
>>> a, b, rest
(0, 1, [2])
>>> a, b, *rest = range(2)
>>> a, b, rest
(0, 1, [])在平行赋值的上下文中,* 前缀只能应用于一个变量,但它可以出现在任何位置:
>>> a, *body, c, d = range(5)
>>> a, body, c, d
(0, [1, 2], 3, 4)
>>> *head, b, c, d = range(5)
>>> head, b, c, d
([0, 1], 2, 3, 4)在函数调用和序列字面量中使用 *进行拆包
PEP 448—Additional Unpacking Generalizations 介绍了可迭代变量拆包的更灵活的语法, 已经总结在 What’s New In Python 3.5.
在函数调用时,我们可以多次使用 *:
>>> def fun(a, b, c, d, *rest):
... return a, b, c, d, rest
...
>>> fun(*[1, 2], 3, *range(4, 7))
(1, 2, 3, 4, (5, 6))* 也可以在定义列表、元组或集合字面量时使用,如 Python 3.5 中的新增功能中的这些示例所示:
>>> *range(4), 4
(0, 1, 2, 3, 4)
>>> [*range(4), 4]
[0, 1, 2, 3, 4]
>>> {*range(4), 4, *(5, 6, 7)}
{0, 1, 2, 3, 4, 5, 6, 7}PEP 448 为 ** 引入了类似的新语法,我们将在“映射拆包”中看到。
最后,元组拆包的一个强大功能是它适用于嵌套结构。
嵌套拆包
拆包的目标可以使用嵌套,例如(a, b, (c, d))。如果值具有相同的嵌套结构,Python 会做正确的事情。示例 2-8 展示了嵌套拆包的实际操作。
例 2-8。拆包嵌套元组以访问经度
metro_areas = [
('Tokyo', 'JP', 36.933, (35.689722, 139.691667)), 1
('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)),
('Mexico City', 'MX', 20.142, (19.433333, -99.133333)),
('New York-Newark', 'US', 20.104, (40.808611, -74.020386)),
('São Paulo', 'BR', 19.649, (-23.547778, -46.635833)),
]
def main():
print(f'{"":15} | {"latitude":>9} | {"longitude":>9}')
for name, _, _, (lat, lon) in metro_areas: 2
if lon <= 0: 3
print(f'{name:15} | {lat:9.4f} | {lon:9.4f}')
if __name__ == '__main__':
main()- 每个元组保存有四个字段的记录,最后一个是坐标对。
- 通过将最后一个字段分配给嵌套元组,我们对坐标进行拆包。
- lon <= 0:测试仅选择西半球的城市。
示例 2-8 的输出是:
| lat. | lon.
Mexico City | 19.4333 | -99.1333
New York-Newark | 40.8086 | -74.0204
São Paulo | -23.5478 | -46.6358进行拆包赋值的目标也可以是一个列表,但用例很少见。 这是我所知道的唯一一个:如果您有一个返回单个记录的数据库查询(例如,SQL 代码有一个 LIMIT 1 子句),那么您可以拆包,同时确保此代码只有一个结果:
[record] = query_returning_single_row()
如果记录只有一个字段,可以这样直接获取:
>>> [[field]] = query_returning_single_row_with_single_field()这两个都可以用元组编写,但不要忘记单项元组必须在项的后面加上逗号。所以第一个目标是 (record,) 和第二个 ((field,),)。在这两种情况下,如果您忘记了逗号,就会产出错误。
现在让我们研究模式匹配,它支持更强大的拆包序列的方法。
序列的模式匹配
Python 3.10 中最显著的新特性是 PEP 634—Structural Pattern Matching: Specification中提出的 match/case 模式匹配语句。
Note:
python 核心开发人员 Carol Willing 在 What’s New In Python 3.10的“Structural Pattern Matching” 部分中写了一篇优秀的模式匹配快速介绍。在本书中,我选择根据模式类型将模式匹配的内容分成不同的章节:“Pattern Matching with Mappings” 和 “Pattern Matching Class Instances”. 一个扩展的例子是 “Pattern Matching in lis.py: A Case Study”.
PEP 634: Structural Pattern Matching
结构模式匹配以match语句和具有关联动作的模式的 case 语句的形式进行添加。模式由序列、映射、原始数据类型以及类实例组成。模式匹配使程序能够从复杂的数据类型中提取信息,对数据结构进行分支,并根据不同形式的数据应用特定的操作。
Syntax and operations
match subject:
case :
case :
case :
case _:
match 语句采用表达式并将其值与作为一个或多个 case 块给出的连续模式进行比较。具体来说,模式匹配通过以下方式运作:
- 使用具有类型和形状的数据(subject)
- 计算match 语句中的subject
- 将subject与 case 语句中的每个模式从上到下进行比较,直到确认匹配。
- 执行与确认匹配的模式相关的操作
- 如果未确认完全匹配,则最后一种情况,通配符 _(如果提供)将用于匹配所有情况。如果没有出现完全匹配且不存在最后匹配所有模式的_,则整个匹配块是一个空操作。
声明式方法
读者可能会通过使用 C、Java 或 JavaScript(以及许多其他语言)中的 switch 语句将subject(数据对象)与字面量(模式)进行匹配的简单示例来了解模式匹配。switch 语句通常用于将对象/表达式与包含字面量的 case 语句进行比较。
在 Scala 和 Elixir 等语言中可以找到更强大的模式匹配示例。对于结构模式匹配,该方法是“声明性的”并明确说明数据匹配的条件(模式)。
虽然使用嵌套的“if”语句的“命令式”系列指令可用于完成类似于结构模式匹配的事情,它不如“声明式”方法清晰。相反,“声明式”方法声明了匹配要满足的条件,并且通过其显式模式使其更具可读性。
虽然可以以最简单的形式使用结构模式匹配,将变量与 case 语句中的文字进行比较。它对 Python 的真正价值在于它对subject对象的类型和形状的处理。
最简单的模式:匹配字面量
让我们把这个例子看成最简单形式的模式匹配:一个值,subject,匹配几个字面量,模式。在下面的示例中,status是匹配语句的subject。模式是每个 case 语句,其中字面量表示请求状态代码。匹配后执行与case关联的操作:
def http_error(status):
match status:
case 400:
return "Bad request"
case 404:
return "Not found"
case 418:
return "I'm a teapot"
case _:
return "Something's wrong with the internet"如果上述函数的status为 418,则返回“I'm a teapot”。 如果上述函数的status为 500,则带有 _ 的 case 语句将作为通配符匹配,并返回“Something’s wrong with the internet”。请注意最后一个块:变量名称 _ 充当通配符并确保subject始终能够匹配。最后的_通配符是可选的。
您可以使用 | 或者 or 在单个模式中组合多个字面量:
case 401 | 403 | 404:
return "Not allowed"不匹配任何通配符的行为
如果我们修改上面的示例:删除最后一个 case 块,则示例变为:
def http_error(status):
match status:
case 400:
return "Bad request"
case 404:
return "Not found"
case 418:
return "I'm a teapot"如果不在case 语句中的最后使用 _,则可能存在不匹配的项。如果存在不匹配项,则行为为空操作。例如,如果传递的status码为500,则会发生空操作。
带有字面量和变量的模式
模式可能看起来像拆包赋值,并且模式可用于绑定变量。在这个例子中,一个数据的点可以拆包为它的 x 坐标和 y 坐标:
# point is an (x, y) tuple
match point:
case (0, 0):
print("Origin")
case (0, y):
print(f"Y={y}")
case (x, 0):
print(f"X={x}")
case (x, y):
print(f"X={x}, Y={y}")
case _:
raise ValueError("Not a point")第一个模式有两个字面量,(0, 0),可以被认为是上面字面量模式的扩展。接下来的两个模式组合了一个字面量和一个变量,变量绑定了一个来自subject(point)的值。第四个模式捕获了两个变量,这使得它在概念上类似于拆包 (x, y) = point。
模式和类
如果您使用类来构造数据,则可以使用类名作为模式,后跟类似于构造函数的参数列表。此模式能够将类属性捕获到变量中:
class Point:
x: int
y: int
def location(point):
match point:
case Point(x=0, y=0):
print("Origin is the point's location.")
case Point(x=0, y=y):
print(f"Y={y} and the point is on the y-axis.")
case Point(x=x, y=0):
print(f"X={x} and the point is on the x-axis.")
case Point():
print("The point is located somewhere else on the plane.")
case _:
print("Not a point")具有位置参数的模式
您可以将位置参数与一些提供属性顺序排序的内置类(如dataclass)一起使用。 您还可以通过在类中设置 __match_args__ 特殊属性来定义模式中属性的特定位置。如果设置为 ("x", "y"),则以下模式都是等效的(并且都将 y 属性绑定到 var 变量):
Point(1, var)
Point(1, y=var)
Point(x=1, y=var)
Point(y=var, x=1)嵌套模式
模式能够进行嵌套。例如,如果我们的数据是一个简短的由点组成的列表,它可以像这样匹配:
match points:
case []:
print("No points in the list.")
case [Point(0, 0)]:
print("The origin is the only point in the list.")
case [Point(x, y)]:
print(f"A single point {x}, {y} is in the list.")
case [Point(0, y1), Point(0, y2)]:
print(f"Two points on the Y axis at {y1}, {y2} are in the list.")
case _:
print("Something else is found in the list.")复杂模式和通配符
前面的示例中,我们在最后一个 case 语句中单独使用了 _以匹配所有数据。通配符可用于更复杂的模式,例如 ('error', code, _)。例如:
match test_variable:
case ('warning', code, 40):
print("A warning has been received.")
case ('error', code, _):
print(f"An error {code} occurred.")在上述情况下, test_variable 将匹配 (‘error’, code, 100) 和 (‘error’, code, 800)。
设置守卫
我们可以在模式中添加一个 if 子句,称为“守卫”。如果守卫为False,程序会继续尝试匹配下一个case块。请注意,值的获取发生在计算守卫之前:
match point:
case Point(x, y) if x == y:
print(f"The point is located on the diagonal Y=X at {x}.")
case Point(x, y):
print(f"Point is not on the diagonal.")其他主要功能:
- 与拆包赋值一样,元组和列表模式具有完全相同的含义并且实际上匹配任意序列。从技术上讲,subject必须是一个序列。因此,一个严重的异常情况是模式不匹配任何迭代器。此外,为了防止常见错误,序列模式不匹配字符串。
- 序列模式支持通配符:[x, y, *rest] 和 (x, y, *rest) 的工作方式类似于解包赋值中的通配符。 * 后面的名字也可能是 _,所以 (x, y, *_) 匹配至少两个项的序列,但是会丢弃多余的项。
- 映射模式:{"bandwidth": b, "latency": l} 从字典中捕获“bandwidth”和“latency”值。与序列模式不同,额外的键被忽略。还支持通配符 **rest。 (但 ** 将是多余的,所以是不允许的。)
- 可以使用 as 关键字捕获子模式:
case (Point(x1, y1), Point(x2, y2) as p2): ...这将 x1, y1, x2, y2 与您在没有 as 子句的情况下预期的一样,将 p2 绑定到主题的整个第二项。
-
大多数字面量通过相等进行比较。但是,单例 True、False 和 None 是按id比较的。
-
命名常量可以在模式中使用。这些命名常量必须是A.B,以防止常量被解释器捕获为变量:
from enum import Enum class Color(Enum): RED = 0 GREEN = 1 BLUE = 2 match color: case Color.RED: print("I see red!") case Color.GREEN: print("Grass is green") case Color.BLUE: print("I'm feeling the blues :(")
这match/case处理序列的第一个示例。想象一下,您正在设计一个机器人,它接受以单词和数字序列形式发送的命令,例如 BEEPER 440 3。拆分成部分并解析数字后,您会收到类似 ['BEEPER', 440, 3] 的消息。您可以使用这样的方法来处理此类消息:
示例 2-9。来自虚构Robot类的方法
def handle_command(self, message):
match message: 1
case ['BEEPER', frequency, times]: 2
self.beep(times, frequency)
case ['NECK', angle]: 3
self.rotate_neck(angle)
case ['LED', ident, intensity]: 4
self.leds[ident].set_brightness(ident, intensity)
case ['LED', ident, red, green, blue]: 5
self.leds[ident].set_color(ident, red, green, blue)
case _: 6
raise InvalidCommand(message)- match 关键字后面的表达式是subject(主题)。主题是 Python 将尝试与每个 case 子句中的模式匹配的数据。
- 此模式匹配具有三个项的序列的任意主题。第一项必须是字符串“BEEPER”。第二项和第三项可以是任何对象,它们将按顺序绑定到变量frequency和times。
- 这匹配具有两个项的任何主题,第一项必须是“NECK”。
- 这将匹配具有以“LED”开头的三个项的主题。如果项数不匹配,Python 将继续执行下一个case。
- 另一个以“LED”开头的序列模式,现在有五个项——包括“LED”常量。
- 这是默认情况。它将匹配与之前模式不匹配的任何主题。 _ 变量比较特殊,我们很快就会看到。
从表面上看,match/case 可能看起来像 C 语言中的 switch/case 语句——但这只是故事的一半。match over switch 的一个关键改进是解构——一种更高级的解包形式。解构是 Python 词汇表中的一个新词,但它通常用于支持模式匹配的语言(如 Scala 和 Elixir)的文档中。
作为解构的第一个示例,示例 2-10 显示了使用match/case重写的示例 2-8 的一部分。
示例 2-10。解构嵌套元组——需要 Python ≥ 3.10
metro_areas = [
('Tokyo', 'JP', 36.933, (35.689722, 139.691667)),
('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)),
('Mexico City', 'MX', 20.142, (19.433333, -99.133333)),
('New York-Newark', 'US', 20.104, (40.808611, -74.020386)),
('São Paulo', 'BR', 19.649, (-23.547778, -46.635833)),
]
def main():
print(f'{"":15} | {"latitude":>9} | {"longitude":>9}')
for record in metro_areas:
match record: 1
case [name, _, _, (lat, lon)] if lon <= 0: 2
print(f'{name:15} | {lat:9.4f} | {lon:9.4f}')-
match的主题是record——即,metro_areas 中的每个元组。
- case 子句有两部分:一个模式和一个带有 if 关键字的可选的守卫。
通常,如果满足以下条件,则序列模式匹配主题:
- 主题是一个序列,并且;
- 主题和模式具有相同数量的项目,并且;
- 每个对应的项都匹配,包括嵌套项。
例如,示例 2-10 中的模式 [name, _, _, (lat, lon)] 匹配一个有四个项的序列,最后一个项必须是一个两个项的序列。
序列模式可以写成元组或列表或嵌套元组和列表的任何组合,但使用哪种语法没有区别:在序列模式中,方括号和圆括号的含义相同。我将模式写成一个带有嵌套 2 元组的列表,只是为了避免在示例 2-10 中重复方括号或圆括号。
序列模式可以匹配 collections.abc.Sequence 的大多数实际或虚拟子类的实例,但 str、bytes 和 bytearray 除外。
WARNING
str、bytes 和 bytearray 的实例在 match/case 的上下文中不作为序列处理。其中一种类型的匹配主题被视为“原子”值——就像整数 987 被视为一个值,而不是数字序列。将这三种类型视为序列可能会由于意外匹配而导致错误。如果要将这些类型的对象视为序列主题,请在 match 子句中对其进行转换。例如,请参见下面的 tuple(phone):
match tuple(phone):
case ['1', *rest]: # North America and Caribbean
...
case ['2', *rest]: # Africa and some territories
...
case ['3' | '4', *rest]: # Europe
...在标准库中,这些类型与序列模式兼容:
list memoryview array.array
tuple range collections.deque与解包不同,模式不会解构非序列的可迭代对象(例如迭代器)。
_ 符号在模式中是特殊的:它匹配该位置的任何单个项,但它永远不会绑定到匹配项的值。此外,_ 是唯一可以在模式中出现多次的变量。
您可以使用 as 关键字将模式的任何部分与变量绑定:
case [name, _, _, (lat, lon) as coord]:对于主题 ['Shanghai', 'CN', 24.9, (31.1, 121.3)],前面的模式将匹配,并设置以下变量:
| Variable | Set Value |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
我们可以通过添加类型信息使模式更具体。例如,以下模式匹配与上一个示例相同的嵌套序列结构,但第一项必须是 str 的实例,并且 2 元组中的两个项都必须是 float 的实例:
case [str(name), _, _, (float(lat), float(lon))]:TIP:
表达式 str(name) 和 float(lat) 看起来像构造函数调用,这样做会将 name 和 lat 转换为 str 和 float。但是在模式的上下文中,该语法执行运行时类型检查:前面的模式将匹配一个四项序列,其中项 0 必须是 str,项 3 必须是一对浮点数。此外,第 0 项中的 str 将绑定到 name 变量,第 3 项中的浮点数将分别绑定到 lat 和 lon。因此,尽管 str(name) 借用了构造函数调用的语法,但语义在模式的上下文中完全不同。在“模式匹配类实例”中介绍了在模式中使用任意类。另一方面,如果我们想匹配以 str 开头并以两个浮点数的嵌套序列结尾的任何主题序列,我们可以这样写:
case [str(name), *_, (float(lat), float(lon))]:*_ 匹配任意数量的项,而不会把它们绑定到变量。使用 *extra 而不是 *_ 会将项目绑定到 extra 作为包含 0 个或更多项的列表。
仅当模式匹配时才执行以 if 开头的可选守卫子句,并且可以引用模式中绑定的变量,如示例 2-10 所示:
match record:
case [name, _, _, (lat, lon)] if lon <= 0:
print(f'{name:15} | {lat:9.4f} | {lon:9.4f}')带有print语句的嵌套块仅在模式匹配成功且guard表达式为真时才运行。
TIP:使用模式进行解构非常具有表现力,以至于有时与单个case/match可以使代码更简单。Guido van Rossum 收集了一系列case/match示例,其中包括他命名为A very deep iterable and type match with extraction的示例。
示例 2-10 不是对示例 2-8 的改进。这只是一个对比两种做同一件事的方式的例子。下一个示例展示了模式匹配如何有助于清晰、简洁和有效的代码。
解释器中的模式匹配序列
斯坦福大学的 Peter Norvig 用132 lines of beautiful and readable Python code.编写了 lis.py:Lisp Scheme 方言子集的解释器。我采用了 Norvig 的 MIT 许可代码并将其更新到 Python 3.10 以展示模式匹配。在本节中,我将用 if/elif 和拆包的 Norvig 部分代码与使用 match/case 的重写实现进行对比。
lis.py 的两个主要功能是parse和evaluate方法。 解析器采用 Scheme 括号表达式并返回 Python 列表。例如:
>>> parse('(gcd 18 44)')
['gcd', 18, 44]
>>> parse('(define double (lambda (n) (* n 2)))')
['define', 'double', ['lambda', ['n'], ['*', 'n', 2]]]
evaluater获取这些列表并执行它们。
我们这里的重点是解构,所以我不会解释evaluator的内部执行的工作原理。请参阅“Pattern Matching: a Case Study” 以了解有关 lis.py 工作原理的更多信息。
这是 Norvig 的evaluator,略有变化,缩写为仅显示序列模式:
例 2-11。没有match/case的匹配模式。
def evaluate(exp: Expression, env: Environment) -> Any:
"Evaluate an expression in an environment."
if isinstance(exp, Symbol): # variable reference
return env[exp]
# ... lines omitted
elif exp[0] == 'quote': # (quote exp)
(_, x) = exp
return x
elif exp[0] == 'if': # (if test conseq alt)
(_, test, consequence, alternative) = exp
if evaluate(test, env):
return evaluate(consequence, env)
else:
return evaluate(alternative, env)
elif exp[0] == 'lambda': # (lambda (parm…) body…)
(_, parms, *body) = exp
return Procedure(parms, body, env)
elif exp[0] == 'define':
(_, name, value_exp) = exp
env[name] = evaluate(value_exp, env)
# ... more lines omitted注意 elif 块如何检查列表的第一项,然后对列表进行拆包,忽略列表的第一项。拆包的广泛使用表明 Norvig 是模式匹配的粉丝,但他最初为 Python 2 编写了该代码(尽管它现在适用于任何 Python 3)。
使用 Python 3.10,我们可以像这样重构evaluate
例 2-12。使用 match/case 进行模式匹配——需要 Python ≥ 3.10。
def evaluate(exp, env):
"Evaluate an expression in an environment."
match exp:
case ...: # several lines omitted
...
case ['quote', exp]: 1
return exp
case ['if', test, conseq, alt]: 2
exp = (conseq if evaluate(test, env) else alt)
return evaluate(exp, env)
case ['define', Symbol(var), exp]: 3
env[var] = evaluate(exp, env)
case ['lambda', parms, *body] if len(body) >= 1: 4
return Procedure(parms, body, env)
# more lines omitted
case _:
raise SyntaxError(repr(exp)) 5- 匹配主题是以“quote”开头的 2 项序列
- 匹配主题是以“if”开头的 4 项序列
- 匹配主题是以 'define' 开头的 3 项序列,后跟一个 Symbol 实例。
- 匹配主题是以 'lambda' 开头的 3 个或更多项的序列。if守卫确保 *body 捕获至少一个项。
- 当有多个 case 子句时,最好有一个包括所有情况的 case。在此示例中,如果 exp 与任何模式都不匹配,则表达式格式错误,并抛出SyntaxError异常。
如果没有最后的catch-all case,当一个主题不匹配任何情况时,整个 match 语句什么都不做——这可能是一个无声的失败。
Norvig 故意避免在 lis.py 中进行错误检查,以保持代码易于理解。通过模式匹配,我们可以添加更多检查并保持可读性。例如:在 'define' 模式中,原始代码不确保 var 是 Symbol 的实例——这将需要一个 if 块、一个 isinstance 调用和更多代码。示例 2-12 比示例 2-11 更短且更安全。
我们可以使用嵌套序列模式使 'lambda' 模式更安全。这是 Scheme 中 lambda 的语法
(lambda (params...) body1 body2...)lambda 案例中 'lambda' 的一个简单模式是:
case ['lambda', parms, *body] if body:lambda 关键字后面的嵌套列表是声明函数形参名称的地方,它必须是一个列表,即使它只有一个项。如果函数没有参数,它也可能是一个空列表——比如 Python 的 random.random()。
但是,如示例 2-11 中所写,case“lambda”匹配 params 位置中的任何值,包括此非法主题中的第一个“x”:
['lambda', 'x', ['*', 'x', 2]]Scheme 中 lambda 关键字后面的嵌套列表保存了函数形式参数的名称,即使它只有一个元素,它也必须是一个列表。如果函数没有参数,它也可能是一个空列表——比如 Python 的 random.random()。
在示例 2-12 中,我使用嵌套序列模式使“lambda”模式更安全:
case ['lambda', [*parms], *body] if len(body) >= 1:
return Procedure(parms, body, env)在序列模式中, * 在每个序列只能出现一次。这里我们有两个序列:外部和内部。
在 parms 周围添加字符 [*] 使模式看起来更像它处理的 Scheme 语法,并为我们提供了额外的结构检查。
函数定义的快捷语法
Scheme 有另一种定义语法来创建命名函数,而不使用嵌套的 lambda。这是语法:
(define (name parm…) body1 body2…)define 关键字后跟一个列表,其中包含新函数的名称和零个或多个参数名称。在该列表之后是带有一个或多个表达式的函数体。
将这两行添加到 match 会负责实现:
case ['define', [Symbol() as name, *parms], *body] if body:
env[name] = Procedure(parms, body, env)我会将该case放在示例 2-12 中的另一个define案例之后。在此示例中,define案例之间的顺序无关紧要,因为没有主题可以匹配这两种模式:第二个元素必须是原始define案例中的Symbol,但它必须是在函数定义的define快捷方式中以Symbol开头的序列。
现在考虑在没有示例 2-11 中的模式匹配帮助的情况下,我们需要做多少工作来添加对第二个define语法的支持。 match 语句比类 C 语言中的 switch 做的更多。
模式匹配是声明式编程的一个例子:代码描述了你想要匹配的“什么”,而不是“如何”匹配它。代码的形状遵循数据的形状。
| Scheme syntax | Pattern |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
我希望通过模式匹配重构 Norvig 的evaluator使您相信 match/case 可以使某些代码更具可读性和安全性。回想一下,这是一个专注于序列模式的快速概览。我们将在后面的章节中介绍其他模式形式。Carol Willing 对introduction to pattern matching 的介绍提供了更多的动机、解释和示例。
Note:我们将在“模式匹配:案例研究”中看到更多 lis.py,届时我们将在evaluate中查看完整的match/case示例。如果您想了解更多关于 Norvig 的 lis.py,请阅读他的精彩文章(如何编写(Lisp)解释器(在 Python 中))
这结束了我们对序列的解包、解构和模式匹配的第一次概述。我们将在后面的章节中介绍其他类型的模式。
每个 Python 程序员都知道可以使用 s[a:b] 语法对序列进行切片。我们现在转向一些关于切片的鲜为人知的事实。
切片
Python 中 list、tuple、str 和所有序列类型的一个共同特点是支持切片操作,它比大多数人想象中的更强大。
在本节中,我们将描述这些高级切片形式的使用它们在用户定义的类中的实现将在第 12 章中介绍,这与我们在本书的这一部分中介绍即用类并在第 IV 部分中创建新类的理念保持一致。
为什么切片和range不包括最后一项
切片和range取值不包括最后一项的 Pythonic 约定与 Python、C 和许多其他语言是一致的,这些语言也都在使用从零开始的索引。一些公认的方便的特点是:
- 当只给出stop位置时,很容易得到切片或范围的长度:range(3) 和 my_list[:3] 都产生三个项。
- 当给定start和stop时,很容易计算切片或range的长度:只需要计算stop-start。
- 很容易在任何索引 x 处将序列分成两部分,而不会产生重叠:只需获取 my_list[:x] 和 my_list[x:]。例如:
>>> l = [10, 20, 30, 40, 50, 60]
>>> l[:2] # split at 2
[10, 20]
>>> l[2:]
[30, 40, 50, 60]
>>> l[:3] # split at 3
[10, 20, 30]
>>> l[3:]
[40, 50, 60]荷兰计算机科学家 Edsger W. Dijkstra 撰写了支持该约定的最佳论据(请参阅“进一步阅读”中的最后一篇参考文献)。
现在让我们仔细看看 Python 如何解释切片符号。
切片对象
这不是秘密,但值得重复以防万一: s[a:b:c] 可用于指定步幅 c,导致结果切片跳过项。步幅也可以是负数,反向返回项。下面三个例子清楚地说明了这一点:
>>> s = 'bicycle'
>>> s[::3]
'bye'
>>> s[::-1]
'elcycib'
>>> s[::-2]
'eccb'另一个例子显示在第 1 章,当我们使用deck[12::13] 获取未洗牌的扑克牌中的所有 A 时:
>>> deck[12::13]
[Card(rank='A', suit='spades'), Card(rank='A', suit='diamonds'),
Card(rank='A', suit='clubs'), Card(rank='A', suit='hearts')]符号 a:b:c 仅在用作索引或下标运算符时在 [] 内有效,并且它产生一个切片对象:slice(a, b, c)。正如我们将在“切片的工作原理”中看到的,为了计算表达式 seq[start:stop:step],Python 调用 seq.__getitem__(slice(start, stop, step))。即使您没有实现自己的序列类型,了解切片对象也很有用,因为它可以让您为切片指定名称,就像电子表格允许命名单元格范围一样。
假设您需要像示例 2-12 中所示的纯文本收据文件。使用有名字的切片,而不是用硬编码切片填充您的代码。查看这使在示例的末尾处的 for 循环的可读性有多强。
例 2-13。来自纯文本文件形式发票的以行进行解析
>>> invoice = """
... 0.....6.................................40........52...55........
... 1909 Pimoroni PiBrella $17.50 3 $52.50
... 1489 6mm Tactile Switch x20 $4.95 2 $9.90
... 1510 Panavise Jr. - PV-201 $28.00 1 $28.00
... 1601 PiTFT Mini Kit 320x240 $34.95 1 $34.95
... """
>>> SKU = slice(0, 6)
>>> DESCRIPTION = slice(6, 40)
>>> UNIT_PRICE = slice(40, 52)
>>> QUANTITY = slice(52, 55)
>>> ITEM_TOTAL = slice(55, None)
>>> line_items = invoice.split('\n')[2:]
>>> for item in line_items:
... print(item[UNIT_PRICE], item[DESCRIPTION])
...
$17.50 Pimoroni PiBrella
$4.95 6mm Tactile Switch x20
$28.00 Panavise Jr. - PV-201
$34.95 PiTFT Mini Kit 320x240当我们在“Vector Take #2: A Sliceable Sequence”中讨论创建您自己的集合时,我们还会继续回到切片对象的介绍。同时,从用户的角度来看,切片包括两个额外的功能,例如多维切片和省略号 (...) 符号。请继续读下去。
多维切片和省略号
[] 运算符还可以采用以逗号分隔的多个索引或切片。处理 [] 运算符的 __getitem__ 和 __setitem__ 特殊方法只是将 a[i, j] 中的索引作为元组接收。换句话说,要得到 a[i, j]的值,Python 调用 a.__getitem__((i, j))。
例如,这在外部 NumPy 包中使用,其中二维数组 numpy.ndarray 的项目可以使用语法 a[i, j] 和使用类似 a[m:n, k:l]的表达式获取二维切片。本章后面的示例 2-21 显示了这种表示法的用法。除了memoryview,Python内置的序列类型都是一维的,所以只支持一个索引或者一个切片,不支持切片和索引的元组。
省略号——用三个英文的句号 (...) 而不是... (Unicode U+2026)——被 Python 解析器识别为一个标记。它是 Ellipsis 对象的别名,ellipsis类的单例。因此,它可以作为参数传递给函数,也可以作为切片规范的一部分,如 f(a, ..., z) 或 a[i:...]。NumPy 使用 ... 作为切片多维数组时的快捷方式;例如,如果 x 是一个四维数组,则 x[i, ...] 是 x[i, :, :, :,] 的快捷方式。请参阅 Tentative NumPy Tutorial 以了解更多相关信息。
在撰写本文时,我不知道 Python 标准库中使用了ellipsis或多维索引和切片的用法。如果你发现一个,请告诉我。这些语法特性的存在是为了支持用户定义的类型和扩展,例如 NumPy。
切片不仅可用于从序列中提取信息;它们还可以用于就地更改可变序列——也就是说,无需从头开始重建它们。
给切片赋值
可以在赋值语句的左侧使用切片符号或作为 del 语句的目标,对可变序列进行嫁接、切除和就地修改。接下来的几个例子给出了这个符号的强大的功能:
>>> l = list(range(10))
>>> l
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> l[2:5] = [20, 30]
>>> l
[0, 1, 20, 30, 5, 6, 7, 8, 9]
>>> del l[5:7]
>>> l
[0, 1, 20, 30, 5, 8, 9]
>>> l[3::2] = [11, 22]
>>> l
[0, 1, 20, 11, 5, 22, 9]
>>> l[2:5] = 100 1
Traceback (most recent call last):
File "", line 1, in
TypeError: can only assign an iterable
>>> l[2:5] = [100]
>>> l
[0, 1, 100, 22, 9] - 当赋值的目标是一个切片时,右侧必须是一个可迭代对象,即使它只有一个项。
每个编码人员都知道连接是序列的常见操作。介绍性 Python 教程解释了 + 和 * 为此目的的使用,但有一些关于它们如何工作的微妙细节,我们接下来将介绍。
在序列中使用 + 和 *
Python 程序员希望序列支持 + 和 *。通常,+ 的两个操作数必须是相同的序列类型,并且它们都不会被修改,而是作为连接的结果创建了一个相同类型的新序列。
要连接同一序列的多个副本,请将其乘以一个整数。再次创建一个新序列:
>>> l = [1, 2, 3]
>>> l * 5
[1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3]
>>> 5 * 'abcd'
'abcdabcdabcdabcdabcd'+ 和 * 总是创建一个新对象,并且永远不会改变它们的操作对象。
WARNING:
当 a 是包含可变项的序列时,请注意像 a * n 这样的表达式,因为结果可能会让您感到惊讶。例如,尝试将列表列表初始化为 my_list = [[]] * 3 将导致列表具有对同一内部列表的三个引用,这可能不是您想要的。
下一节介绍尝试使用 * 初始化列表列表的陷阱。
构建列表组成的列表
有时我们需要用一定数量的嵌套列表初始化一个列表——例如,将学生分配到一个团队列表中或在游戏板上表示方块。最好的方法是使用列表推导式,如示例 2-13 所示。
例 2-13。构建一个包含三个长度为 3 的列表的列表表示一个井字棋盘
>>> board = [['_'] * 3 for i in range(3)] 1
>>> board
[['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]
>>> board[1][2] = 'X' 2
>>> board
[['_', '_', '_'], ['_', '_', 'X'], ['_', '_', '_']]- 创建一个包含三个列表的列表,每个列表包含三个项目。检查其结构。
- 在第 1 行第 2 列中放置一个标记,并检查结果。
一个诱人但错误的捷径是像示例 2-14 那样做。
例 2-14。对含有同一个列表的三个引用的列表是无用的
>>> weird_board = [['_'] * 3] * 3 1
>>> weird_board
[['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]
>>> weird_board[1][2] = 'O' 2
>>> weird_board
[['_', '_', 'O'], ['_', '_', 'O'], ['_', '_', 'O']]- 外部列表由对同一个内部列表的三个引用组成。当不做修改的时候,一切似乎都是正确的。
- 在第 1 行第 2 列中放置标记表明所有行都是引用同一对象的别名。
示例 2-14 的问题在于,本质上,它的行为类似于以下代码:
row = ['_'] * 3
board = []
for i in range(3):
board.append(row) 1- 同一行在 board 上被追加了 3 次。
相反,示例 2-13 中的列表推导式等效于以下代码:
>>> board = []
>>> for i in range(3):
... row = ['_'] * 3 1
... board.append(row)
...
>>> board
[['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]
>>> board[2][0] = 'X'
>>> board 2
[['_', '_', '_'], ['_', '_', '_'], ['X', '_', '_']]- 每次迭代都会构建一个新行并将其追加到board上。
- 正如预期的那样,只更改了第 2 行
TIP:
如果您不清楚本节中的问题或解决方案,请放松。第 6 章旨在阐明引用和可变对象的机制和陷阱。
到目前为止,我们已经讨论了对序列使用普通的 + 和 * 运算符,但还有 += 和 *= 运算符,它们会根据目标序列的可变性产生非常不同的结果。以下部分解释了它是如何工作的。
序列的增量赋值
增强赋值运算符 += 和 *= 的行为完全不同,具体取决于第一个操作对象。为了简化讨论,我们将首先关注增量加法 (+=),但这些概念也适用于 *= 和其他增量赋值运算符。
使 += 起作用的特殊方法是 __iadd__(用于“就地添加”)。但是,如果 __iadd__ 没有实现,Python 会退一步调用 __add__。考虑这个简单的表达式:
>>> a += b如果 a 实现了 __iadd__,那么它将被调用。在可变序列的情况下(例如,列表、字节数组、数组数组),a 将就地更改(即,效果将类似于 a.extend(b))。但是,当 a 未实现 __iadd__ 时,表达式 a += b 与 a = a + b 具有相同的效果:首先计算表达式 a + b,生成一个新对象,然后将其绑定到 a。换句话说,绑定到 a 的对象的身份可能会也可能不会改变,这取决于 __iadd__ 的可用性。
通常,对于可变序列,最好实现 __iadd__ 并且 += 为就地加法。对于不可变序列,显然不可能发生这种情况。
我刚刚写的关于 += 的内容也适用于 *=,它是通过 __imul__ 实现的。 __iadd__ 和 __imul__ 特殊方法在第 16 章中讨论。
这是一个 *= 的演示,其中包含一个可变序列,然后是一个不可变序列:
>>> l = [1, 2, 3]
>>> id(l)
4311953800 1
>>> l *= 2
>>> l
[1, 2, 3, 1, 2, 3]
>>> id(l)
4311953800 2
>>> t = (1, 2, 3)
>>> id(t)
4312681568 3
>>> t *= 2
>>> id(t)
4301348296 4- 初始列表ID
- 乘法后,列表是同一个对象,追加了新的项
- 初始元组的 ID
- 运用增量乘法后,创建了一个新元组
不可变序列的重复连接是低效的,因为解释器必须复制整个目标序列以创建一个新的序列,而不是仅仅追加新的项,并将新项目连接起来。
我们已经看到了 += 的常见用例。下一节展示了一个有趣的极端案例,强调了“不可变”在元组上下文中的真正含义。
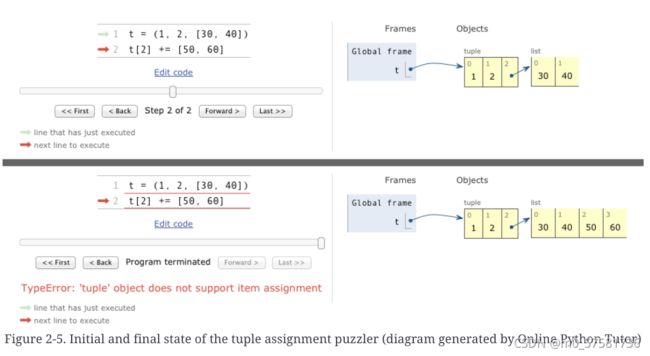
一个关于 += 赋值的谜题
尝试在不使用控制台的情况下回答:对示例 2-15 中的两个表达式求值的结果是什么?
例 2-15。一个谜语
>>> t = (1, 2, [30, 40])
>>> t[2] += [50, 60]接下来发生什么?选择最佳答案:
-
t变成(1, 2, [30, 40, 50, 60]). -
抛出TypeError异常,消息为'tuple' object does not support item assignment. -
都不是
-
A和B
当我看到这个时,我很确定答案是 B,但实际上是 D,“A 和 B”!示例 2-16 是 Python 3.9 控制台的实际输出。
例 2-16。意外结果:项 t2 已更改并抛出异常
>>> t = (1, 2, [30, 40])
>>> t[2] += [50, 60]
Traceback (most recent call last):
File "", line 1, in
TypeError: 'tuple' object does not support item assignment
>>> t
(1, 2, [30, 40, 50, 60]) Online Python Tutor是一个很棒的在线工具,可以详细地可视化 Python 的工作原理。图 2-5 是两个屏幕截图的组合,显示了示例 2-16 中元组 t 的初始和最终状态。
如果您查看 Python 为表达式 s[a] += b 生成的字节码(示例 2-17),就会很清楚这是如何发生的。
例 2-17。表达式 s[a] += b 的字节码
>>> dis.dis('s[a] += b')
1 0 LOAD_NAME 0 (s)
3 LOAD_NAME 1 (a)
6 DUP_TOP_TWO
7 BINARY_SUBSCR 1
8 LOAD_NAME 2 (b)
11 INPLACE_ADD 2
12 ROT_THREE
13 STORE_SUBSCR 3
14 LOAD_CONST 0 (None)
17 RETURN_VALUE-
将 s[a] 的值放在 TOS(栈顶)上。
-
执行 TOS += b.如果 TOS 引用一个可变对象(它是一个列表,在示例 2-16 中),则此操作会成功。
-
赋值 s[a] = TOS。如果 s 是不可变的(示例 2-16 中的 t 元组),则会失败。
这个例子是一个非常极端的案例——在使用 Python 的 20 年里,我从未见过这种奇怪的行为真的有人遇到过。
我从中吸取了三个教训:
- 避免将可变项放在元组中。
- 增量赋值不是原子操作——我们只是看到它在完成部分工作后抛出异常。
- 检查 Python 字节码并不太困难,有助于了解幕后发生的事情。
在见证了使用 + 和 * 进行连接的微妙之处之后,我们可以将主题更改为另一个使用序列的基本操作:排序。
list.sort 与 内置的 sorted方法
list.sort 方法就地对列表进行排序——也就是说,不复制。方法返回 None 以提醒我们它更改了接收者 并且不会创建新列表。这是一个重要的 Python API 约定:就地更改对象的函数或方法应该返回 None 以向调用者明确表示接收者已更改,并且没有创建新对象。例如,在 random.shuffle(s) 函数中可以看到类似的行为,该函数就地打乱可变序列 s,并返回 None。
NOTE:返回 None 以指示就地更改的约定有一个缺点:我们不能级联调用这些方法。相比之下,返回新对象的方法(例如,所有 str 方法)可以在流畅的接口风格中级联。有关此主题的进一步说明,请参阅维基百科的 “Fluent interface” entry。
相反,内置函数 sorted 创建一个新列表并返回它。它接受任何可迭代对象作为参数,包括不可变序列和生成器(参见第 17 章)。不管给 sorted 传入的可迭代类型是什么,它总是返回一个新创建的列表。
list.sort 和 sorted 都采用两个可选的、仅限关键字的参数:
reverse:
如果为 True,则按降序返回项目(即,通过颠倒项目的比较)。默认值为False。
key:
将应用于每个项以生成其排序键的单参数函数。例如,在对字符串列表进行排序时,可以使用 key=str.lower 执行不区分大小写的排序,而 key=len 将按字符长度对字符串进行排序。默认值为恒等函数(即比较项本身)。
TIP:您还可以将可选关键字参数 key 与 min() 和 max() 内置函数以及标准库中的其他函数(例如 itertools.groupby() 和 heapq.nlargest())一起使用。
这里有几个例子来阐明这些函数和关键字参数的用法。这些示例还表明 Python 的排序算法是稳定的(即,它保留了比较相等项的相对顺序)
>>> fruits = ['grape', 'raspberry', 'apple', 'banana']
>>> sorted(fruits)
['apple', 'banana', 'grape', 'raspberry'] 1
>>> fruits
['grape', 'raspberry', 'apple', 'banana'] 2
>>> sorted(fruits, reverse=True)
['raspberry', 'grape', 'banana', 'apple'] 3
>>> sorted(fruits, key=len)
['grape', 'apple', 'banana', 'raspberry'] 4
>>> sorted(fruits, key=len, reverse=True)
['raspberry', 'banana', 'grape', 'apple'] 5
>>> fruits
['grape', 'raspberry', 'apple', 'banana'] 6
>>> fruits.sort() 7
>>> fruits
['apple', 'banana', 'grape', 'raspberry'] 8- 这会生成一个按字母顺序排序的新字符串列表
- 检查原始列表,我们看到它没有变化。
- 这是颠倒的“字母”顺序。
- 一个新的字符串列表,现在按长度排序。由于排序算法稳定,长度为5的“grape”和“apple”按原顺序排列。
- 这些是按长度降序排列的字符串。与之前的结果不是相反,因为排序是稳定的,所以“grape”再次出现在“apple”之前。
- 到目前为止,原始fruits列表的顺序没有改变。
- 这会对列表进行就地排序,并返回 None (控制台会省略)。
- 现在fruits已经被排序好了
Warning:默认情况下,Python 按字符代码按字典顺序对字符串进行排序。这意味着 ASCII 大写字母将排在小写字母之前,并且非 ASCII 字符不太可能以合理的方式进行排序。“Sorting Unicode Text” 涵盖了人类所期望的对文本进行排序的正确方法。
一旦您的序列被排序,就可以非常有效地搜索它们。 Python 标准库的 bisect 模块中已经提供了二分搜索算法。该模块还包括 bisect.insort 函数,您可以使用它来确保已排序的序列保持顺序。您可以在 fluentpython.com 配套网站的 Managing Ordered Sequences with Bisect 中找到对bisect模块的插图介绍。
到目前为止,我们在本章中看到的大部分内容都适用于一般的序列,而不仅仅是列表或元组.Python 程序员有时会过度使用列表类型,因为它非常方便——我知道我已经做到了。例如,如果您正在处理大量数字列表,则应考虑使用数组代替。本章的其余部分专门讨论列表和元组的替代方案.
当列表不是首选时
列表类型灵活且易于使用,但面对具体的需求的时候,我们可能会有更好的选择。例如,当您需要处理数百万个浮点值时,使用数组可以节省大量内存。另一方面,如果您不断地从列表的两端添加和删除项,那么知道deque(双端队列)是一种更高效的 FIFO 数据结构是件好事。
TIP:如果您的代码经常检查集合中是否存在某个项目(例如,检查某项是否在my_collection中),请考虑为 my_collection 使用一个set,尤其是当它包含大量项时。set也是可迭代的,但它不是序列,因为set是无序的。我们将在第 3 章中介绍它们。
在本章的剩余部分,我们将讨论可以在许多情况下替换列表的可变序列类型,让我们从数组开始。
数组
如果列表中只包含数字,则 array.array 是更有效的替代品。数组支持所有可变序列操作(包括 .pop、.insert 和 .extend),以及用于快速加载和保存的其他方法,例如 .frombytes 和 .tofile。
Python 数组与 C 数组一样精简。如图 2-1 所示,浮点值数组不包含完整的浮点实例,而只包含表示其机器值的压缩字节——类似于 C 语言中的double数组。创建数组时,您提供一个类型代码,一个字母来确定用于存储数组中每个项对应的底层 C 类型。例如,b 是 C 所称的有符号字符的类型代码,一个范围从 –128 到 127 的整数。如果你创建一个array('b'),那么每一项都将被存储在一个字节中并被解释为一个整数.对于大型数字序列,这可以节省大量内存。 Python 不会让你存入任何与数组类型不匹配的数字。
示例 2-18 显示了创建、保存和加载一个由 1000 万个浮点随机数组成的数组。
例 2-18。创建、保存和加载浮点型数组
>>> from array import array 1
>>> from random import random
>>> floats = array('d', (random() for i in range(10**7))) 2
>>> floats[-1] 3
0.07802343889111107
>>> fp = open('floats.bin', 'wb')
>>> floats.tofile(fp) 4
>>> fp.close()
>>> floats2 = array('d') 5
>>> fp = open('floats.bin', 'rb')
>>> floats2.fromfile(fp, 10**7) 6
>>> fp.close()
>>> floats2[-1] 7
0.07802343889111107
>>> floats2 == floats 8
True- 导入array类型
- 从任何可迭代对象(在本例中为生成器表达式)创建一个双精度浮点数(类型代码“d”)数组。
- 观察数组的最后一项
- 将数组保存到二进制文件。
- 创建一个空的double数组。
- 从二进制文件中读取 1000 万个数字。
- 观察数组的最后一项
- 比较值是否相等
如您所见,array.tofile 和 array.fromfile 很容易使用。如果你尝试这个例子,你会发现它们也非常快。一个快速实验表明,array.fromfile 从使用 array.tofile 创建的二进制文件加载 1000 万个双精度浮点数大约需要 0.1 秒。这比从文本文件中读取数字快近 60 倍,后者还涉及使用内置float解析每一行。使用 array.tofile 保存比在文本文件中每行写入一个浮点数快 7 倍。另外,1000万个双精度的二进制文件大小为8000万字节(每个双精度8个字节,其余零开销),而对于相同的数据,文本文件有181515739个字节。
对于表示二进制数据的数值数组的特定情况,例如光栅图像,Python 具有的 bytes 和 bytearray 类型,我们会在第 4 章中讨论。
我们用表 2-3 结束了关于数组的这一节,比较了 list 和 array.array 的特性。
| list | array | ||
|---|---|---|---|
|
|
● |
● |
|
|
|
● |
● |
|
|
|
● |
● |
Append one element after last |
|
|
● |
Swap bytes of all items in array for endianness conversion |
|
|
|
● |
Delete all items |
|
|
|
● |
● |
|
|
|
● |
Shallow copy of the list |
|
|
|
● |
Support for |
|
|
|
● |
● |
Count occurrences of an element |
|
|
● |
Optimized support for |
|
|
|
● |
● |
Remove item at position |
|
|
● |
● |
Append items from iterable |
|
|
● |
Append items from byte sequence interpreted as packed machine values |
|
|
|
● |
Append |
|
|
|
● |
Append items from list; if one causes |
|
|
|
● |
● |
|
|
|
● |
● |
Find position of first occurrence of |
|
|
● |
● |
Insert element |
|
|
● |
Length in bytes of each array item |
|
|
|
● |
● |
Get iterator |
|
|
● |
● |
|
|
|
● |
● |
|
|
|
● |
● |
|
|
|
● |
● |
|
|
|
● |
● |
Remove and return item at position |
|
|
● |
● |
Remove first occurrence of element |
|
|
● |
● |
Reverse the order of the items in place |
|
|
● |
Get iterator to scan items from last to first |
|
|
|
● |
● |
|
|
|
● |
Sort items in place with optional keyword arguments |
|
|
|
● |
Return items as packed machine values in a |
|
|
|
● |
Save items as packed machine values to binary file |
|
|
|
● |
Return items as numeric objects in a |
|
|
|
● |
One-character string identifying the C type of the items |
|
| a Reversed操作符将在 Chapter 16讲解. |
|||
TIP:从 Python 3.10 开始,array类型没有像 list.sort() 这样的就地排序方法。如果需要对数组进行排序,请使用内置的 sorted 函数来重建数组:
a = array.array(a.typecode, sorted(a))要在向其中添加项目时保持已排序数组的排序,请使用 bisect.insort 函数。
如果您对array进行了大量工作并且不了解 memoryview,那么您就错过了。请参阅下一个主题。
内存视图
它的灵感来自 NumPy 库(我们将在“NumPy”中稍后讨论)。 NumPy 的主要作者 Travis Oliphant 回答什么时候应该使用 memoryview?是这样说的:
memoryview 本质上是 Python 本身中的广义 NumPy 数组结构(去数学化)。它允许您在数据结构(例如 PIL 图像、SQLite 数据库、NumPy 数组等)之间共享内存,而无需先进行复制。这对于大型数据集非常重要。
使用类似于array模块的符号,memoryview.cast 方法允许您更改多个字节作为单位读取或写入的方式,而无需移动字节。memoryview.cast 返回另一个 memoryview 对象,始终共享相同的内存。示例 2-19 显示了如何在相同的 6 字节数组上创建替代视图,以将其作为 2×3 矩阵或 3×2 矩阵进行操作:
例 2-19。处理 1×6、2×3 和 3×2 内存视图的 6 字节内存
>>> from array import array
>>> octets = array('B', range(6)) 1
>>> m1 = memoryview(octets) 2
>>> m1.tolist()
[0, 1, 2, 3, 4, 5]
>>> m2 = m1.cast('B', [2, 3]) 3
>>> m2.tolist()
[[0, 1, 2], [3, 4, 5]]
>>> m3 = m1.cast('B', [3, 2]) 4
>>> m3.tolist()
[[0, 1], [2, 3], [4, 5]]
>>> m2[1,1] = 22 5
>>> m3[1,1] = 33 6
>>> octets 7
array('B', [0, 1, 2, 33, 22, 5])- 构建 6 个字节的数组(类型代码“B”)。
- 从该数组构建 memoryview,然后将其导出为列表。
- 从前一个构建新的内存视图,但有 2 行和 3 列。
- 另一个内存视图,现在有 3 行和 2 列。
- 用 22 覆盖 m2 中第 1 行第 1 列的字节。
- 用 33 覆盖 m3 中第 1 行第 1 列的字节。
- 显示原始数组,证明内存在octets、m1、m2 和 m3 之间共享。
memoryview 的强大功能也可能会导致问题。示例 2-20 展示了如何更改 16 位整数数组中项目的单个字节。
例 2-20。通过更改其中一个字节来更改 16 位整数数组项的值
>>> numbers = array.array('h', [-2, -1, 0, 1, 2])
>>> memv = memoryview(numbers) 1
>>> len(memv)
5
>>> memv[0] 2
-2
>>> memv_oct = memv.cast('B') 3
>>> memv_oct.tolist() 4
[254, 255, 255, 255, 0, 0, 1, 0, 2, 0]
>>> memv_oct[5] = 4 5
>>> numbers
array('h', [-2, -1, 1024, 1, 2]) 6- 从 5 个 16 位有符号整数数组(类型代码“h”)构建 memoryview。
- memv 看到的项和数组中的 5 个项相同。
- 通过将 memv 的元素转换为字节(类型代码“B”)来创建 memv_oct。
- 将 memv_oct 的元素导出为 10 个字节的列表,以供观察。
- 将值 4 赋值给偏移量 为5的字节。
- 请注意numbers的变化:2 字节无符号整数的最高有效字节中的 4 变成了 1024。
Note:您可以在 fluentpython.com 上找到使用 struct 包检查 memoryview 的示例:fluentpython.com: Parsing binary records with struct.
同时,如果您在数组中进行高级数值处理,则应该使用 NumPy 库。我们将立即对它们进行简要介绍。
Numpy
在整本书中,我重点强调了 Python 标准库中已有的内容,以便您可以充分利用它。但是 NumPy 太棒了,所以有时候绕道而行也是必要的。
对于高级数组和矩阵运算,NumPy 是 Python 成为科学计算应用主流的原因。NumPy 实现了多维、同构的数组和矩阵类型,它们不仅包含数字,还包含用户定义的记录,并提供高效的元素操作。
SciPy 是一个基于 NumPy 编写的库,提供了许多来自线性代数、数值微积分和统计学的科学计算算法。SciPy 快速可靠,因为它利用了 Netlib 存储库中广泛使用的 C 和 Fortran 代码库。换句话说,SciPy 为科学家提供了两全其美的优势:交互式提示和高级 Python API,以及在 C 和 Fortran 中优化的工业级数字运算功能。
作为一个非常简短的 NumPy 演示,示例 2-21 展示了二维数组的一些基本操作。
例 2-21。 numpy.ndarray 中行和列的基本操作
>>> import numpy as np 1
>>> a = np.arange(12) 2
>>> a
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
>>> type(a)
>>> a.shape 3
(12,)
>>> a.shape = 3, 4 4
>>> a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> a[2] 5
array([ 8, 9, 10, 11])
>>> a[2, 1] 6
9
>>> a[:, 1] 7
array([1, 5, 9])
>>> a.transpose() 8
array([[ 0, 4, 8],
[ 1, 5, 9],
[ 2, 6, 10],
[ 3, 7, 11]]) - 安装后导入 NumPy(它不在 Python 标准库中)。按照惯例,numpy 导入后别名为np。
- 使用整数 0 到 11 构建并查看 numpy.ndarray。
- 检查数组的维度:这是一个一维的 12 元素数组。
- 更改数组的形状,添加一维,然后观察结果。
- 获取索引 2 处的行。
- 获取索引 2, 1 处的元素。
- 获取索引 1 处的列
- 通过转置(用行交换列)创建一个新数组。
NumPy 还支持加载、保存和操作 numpy.ndarray 的所有元素的高级操作:
>>> import numpy
>>> floats = numpy.loadtxt('floats-10M-lines.txt') 1
>>> floats[-3:] 2
array([ 3016362.69195522, 535281.10514262, 4566560.44373946])
>>> floats *= .5 3
>>> floats[-3:]
array([ 1508181.34597761, 267640.55257131, 2283280.22186973])
>>> from time import perf_counter as pc 4
>>> t0 = pc(); floats /= 3; pc() - t0 5
0.03690556302899495
>>> numpy.save('floats-10M', floats) 6
>>> floats2 = numpy.load('floats-10M.npy', 'r+') 7
>>> floats2 *= 6
>>> floats2[-3:] 8
memmap([ 3016362.69195522, 535281.10514262, 4566560.44373946])- 从文本文件加载 1000 万个浮点数。
- 使用序列切片符号检查最后三个数。
- 将 floats 数组中的每个元素乘以 0.5 并再次检查最后三个元素。
- 导入高分辨率性能测量计时器(自 Python 3.3 起引入)。
- 将每个元素除以 3; 1000 万次浮点数所用的时间小于 40 毫秒。
- 将数组保存在 .npy 二进制文件中。
- 将数据作为内存映射文件加载到另一个数组中;这允许有效处理数组的切片,即使它不完全适合内存。
- 将每个元素乘以 6 后检查最后三个元素
这只是开胃菜。
NumPy 和 SciPy 是强大的库,并且是其他很棒的工具(例如 Pandas)的基础,Pandas实现了可以保存非数字数据的高效数组类型,并为许多不同的格式(如 .csv、.xls、SQL 转储、HDF5 等)提供导入/导出功能。— 和 Scikit-learn — 目前使用最广泛的机器学习工具集。大多数 NumPy 和 SciPy 函数是用 C 或 C++ 实现的,并且可以利用所有 CPU 内核,因为它们释放了 Python 的 GIL(全局解释器锁)。Dask 项目支持跨机器集群并行处理 NumPy、Pandas 和 Scikit-Learn 处理。这些包值得用整本关于它们的书。但这不是其中的一本书。但是,如果不至少快速概览 NumPy 数组,那么 Python 序列的概述就不会完整。
看过扁平序列(标准数组和 NumPy 数组)后,我们现在转向一种完全不同的可以取代普通列表的数据结构:队列。
双向队列和其他队列
append 和 .pop 方法使列表可用作堆栈或队列(如果您使用 .append 和 .pop(0),您将获得 FIFO 行为)。但是从列表的头部(0-index 结尾)插入和删除是昂贵的,因为整个列表必须在内存中移动。
类 collections.deque 是一个线程安全的双端队列,设计用于从两端快速插入和删除。如果您需要保留“最后看到的项目”或类似性质的列表,这也是一种可行的方法,因为 deque 可以是有界的——即,以固定的最大长度创建。如果有界双端队列已满,则当您添加新项时,它会丢弃另一端的项。示例 2-22 显示了对双端队列执行的一些典型操作。
例 2-22。使用双端队列
>>> from collections import deque
>>> dq = deque(range(10), maxlen=10) 1
>>> dq
deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
>>> dq.rotate(3) 2
>>> dq
deque([7, 8, 9, 0, 1, 2, 3, 4, 5, 6], maxlen=10)
>>> dq.rotate(-4)
>>> dq
deque([1, 2, 3, 4, 5, 6, 7, 8, 9, 0], maxlen=10)
>>> dq.appendleft(-1) 3
>>> dq
deque([-1, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
>>> dq.extend([11, 22, 33]) 4
>>> dq
deque([3, 4, 5, 6, 7, 8, 9, 11, 22, 33], maxlen=10)
>>> dq.extendleft([10, 20, 30, 40]) 5
>>> dq
deque([40, 30, 20, 10, 3, 4, 5, 6, 7, 8], maxlen=10)- 可选的 maxlen 参数设置此双端队列实例中允许的最大项目数;这将设置只读 maxlen 实例属性。
-
旋转 n > 0 从右端获取项目并将它们添加到左侧;当 n < 0 项从左侧取出并附加到右侧时。
-
附加到已满的双端队列 (len(d) == d.maxlen) 会丢弃另一端的项目;请注意在下一行中删除了 0
-
向右侧添加三个项会挤掉最左侧的 -1、1 和 2。
-
请注意,extendleft(iter) 的工作原理是将 iter 参数的每个连续项目附加到双端队列的左侧,因此项目的最终位置是相反的。
表 2-4 比较了特定于 list 和 deque 的方法(删除了那些也出现在 object 中的方法)。
请注意,deque 实现了大多数列表方法,并添加了一些特定于其设计的方法,例如 popleft 和 rotate。但是有一个隐藏的成本:从双端队列中间删除项目并没有那么快。它确实针对从末端追加和弹出进行了优化。append 和 popleft 操作是原子操作,因此 deque 可以安全地用作多线程应用程序中的 FIFO 队列,而无需使用锁。
| list | deque | ||
|---|---|---|---|
|
|
● |
|
|
|
|
● |
● |
|
|
|
● |
● |
Append one element to the right (after last) |
|
|
● |
Append one element to the left (before first) |
|
|
|
● |
● |
Delete all items |
|
|
● |
|
|
|
|
● |
Shallow copy of the list |
|
|
|
● |
Support for |
|
|
|
● |
● |
Count occurrences of an element |
|
|
● |
● |
Remove item at position |
|
|
● |
● |
Append items from iterable |
|
|
● |
Append items from iterable |
|
|
|
● |
● |
|
|
|
● |
Find position of first occurrence of |
|
|
|
● |
Insert element |
|
|
|
● |
● |
Get iterator |
|
|
● |
● |
|
|
|
● |
|
|
|
|
● |
|
|
|
|
● |
|
|
|
|
● |
● |
Remove and return last itemb |
|
|
● |
Remove and return first item |
|
|
|
● |
● |
Remove first occurrence of element |
|
|
● |
● |
Reverse the order of the items in place |
|
|
● |
● |
Get iterator to scan items from last to first |
|
|
● |
Move |
|
|
|
● |
● |
|
|
|
● |
Sort items in place with optional keyword arguments |
|
|
b a_list.pop(p) 允许从位置 p 删除,但 deque 不支持该选项。 |
|||
除了 deque,还有其他 Python 标准库包也有队列的实现:
queue:
这提供了同步(即线程安全)类 SimpleQueue、Queue、LifoQueue 和 PriorityQueue。这些可用于线程之间的安全通信。除了 SimpleQueue 之外的所有都可以通过向构造函数提供大于 0 的 maxsize 参数来限制。但是,他们不会像 deque 那样丢弃项以腾出空间。相反,当队列已满时,新项目的插入会阻塞——即,它会等待其他线程通过从队列中取出项目来腾出空间,这对于限制活动线程的数量非常有用。
multiprocessing
实现了自己的 unbounded SimpleQueue 和 bounded Queue,与 queue 包中的非常相似,但专为进程间通信而设计。提供了专门的 multiprocessing.JoinableQueue 用于任务管理。
asyncio
为 Queue、LifoQueue、PriorityQueue 和 JoinableQueue 提供受队列和多处理模块中类启发的 API,但适用于管理异步编程中的任务。
heapq
与前三个模块相比,heapq 没有实现队列类,而是提供了 heappush 和 heappop 等功能,让您可以使用可变序列作为堆队列或优先队列。
这结束了我们对列表类型替代品的概述,以及我们对序列类型的一般探索——除了 str 和二进制序列的细节,它们有自己的一章(第 4 章)