【图解】连狗子都能看懂的Python基础总结(二)什么是库、包、模块?
【图解】连狗子都能看懂的Python基础总结!(二)什么是库、包、模块?
本章内容
- 什么是模块?
- 什么是包?
- 什么是库?
- 什么是标准库和第三方库?
上次,我们解释了“变量”、“数组”、“函数”和“类”,它们是编程的基础。
在学习 Python 时,您会经常看到术语“模块”、“包”和“库”
这一次,我将解释这三个词的含义,它们的作用以及它们的区别
通过了解这三件事,您可以更好地了解使用 Python 进行编程。请看到最后
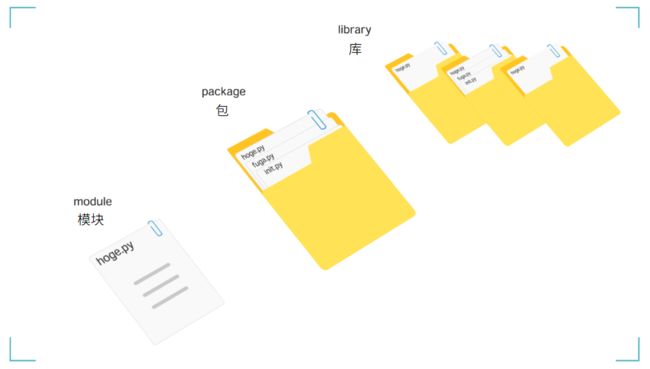
首先,我想用一个词来介绍模块、包和库
- 一个模块是几个函数和类的集合。
- 一个包是几个模块的集合。
- 库是几个包的集合。
概念的大小按如下顺序排列。
库>包>模块>类>函数>变量
在这篇图文中我会很详细的向你讲解
什么是模块?

模块是单个 Python 文件,用于表示程序的一部分。
如果你想用 Python 编程,创建一个扩展名为 .py 的文件并在其中编写代码。在开发应用程序或系统时,它通常不是一个文件。创建 10 个或 20 个或超过 100 个 Python 文件并将它们组合起来以使其作为程序运行。
这时,从整个程序的角度来看,一个文件被认为是一个部分。单个应用程序由大量部分组成。在 Python 中,单个文件称为模块。因此,一个模块包含几个变量、数组、函数和类。
举个例子
你目前正在用Python开发一个RPG游戏应用程序。 当你继续写程序时,代码量已经大到有些难以阅读。
所以你把程序分成三个文件,并命名为character.py、monster.py和magic.py。 每个文件都包含一个角色程序、一个怪物程序和一个魔法程序。 这三个文件在python世界中被称为模块。
character.py
monster.py
magic.py
模块是组合使用的。 例如,你可能经常想在character.py中使用magic.py中创建的一个函数。 在这种情况下,Python 允许你通过使用导入过程来调用其他模块的函数。
# 有关于魔术的技能
def fire():
print("火魔法!")
def ice():
print("水魔法!")
def thunder():
print("雷魔法!")
# 包含有关该人物的过程的文件
import magic
print("我是一个法师!")
print("哈撒给!")
magic.fire()
# 执行结果
我是一名法术!
哈撒给!
火魔法!
通过这种方式,代码可以被分为每个角色的模块(部分),一个模块有一个功能,使代码易于阅读。 这在以后重读代码或作为一个团队开发时非常有用。
另外,通过将它们分组为模块,代码可以在以后被反复使用。
什么是包?

一个包是几个模块的集合。
包是管理几个模块的一个有用的工具。 在大型项目中,所需模块的数量可能会增加。 在这种情况下,有可能将模块组合成一个单一的包,并对其进行管理以方便使用。
如何创建一个包
当创建一个包时,首先把你想打包的模块放在一个目录中。 在该目录中,创建一个新的特殊文件,名为__init__.py。 这只是一个单一的Python文件,因为它的扩展名是.py。 然而,通过这样一个名为 init.py 的文件,该目录下的文件被视为一个单一的包。
# 目录结构
.
├── creatures
│ ├── __init__.py
│ ├── character.py
│ └── moster.py
└── magic
├── __init__.py
└── magic.py
包也可以是分层的。 如果代码量变得很大,尽量组织模块和包,以方便程序开发。
什么是库?
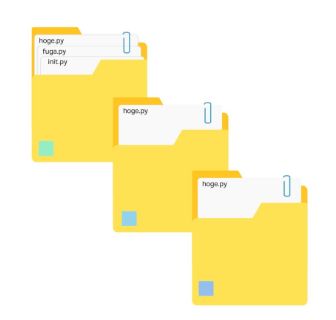
一个库是几个包的集合。
在library的情况下,它们可以在互联网上发布,供任何人安装。
由天才工程师创建的程序以这些库的形式分发。 通过将你自己的程序以库的形式组合起来,你可以将它们提供给全世界的Python程序员。
到此为止的内容被总结了一次。
- 模块 一个函数和类的集合
- 包 一个模块的集合
- 库 一个包的集合。
一个模块内的功能、模块本身和包本身有时被称为库。 库可以被认为是一个程序中使用的部分的总称。 在这篇文章中,我们将把它们都称为库,并对它们进行解释。
什么是标准库和第三方库?
标准库和第三方库的区别
1.常用的标准库
- ① 常用的标准库 random
- ② 常用的标准库 math
- ③ 常用的标准库 os
2.常用的第三方库
- ① Numpy
- ② Pandas
- ③ Matplotlib
- ④ Scikit-learn
- ⑤ pip
标准库和第三方库
库可以被分为标准库和第三方库
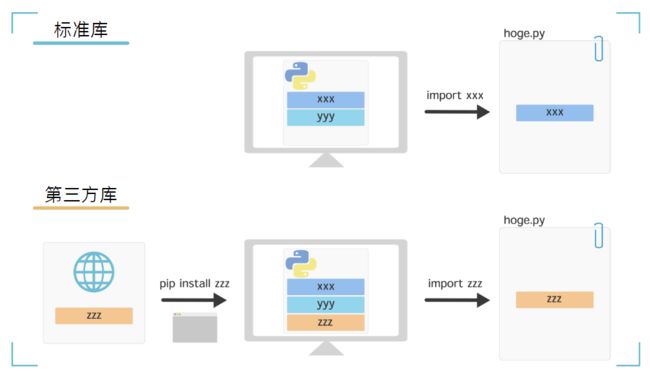
1、标准库

标准库是 Python 自带的标准库。
安装 Python 时,标准库也会自动安装。因此,您以后无需自行安装即可使用该功能。
下面是一个常用的机器学习标准库的列表。
- ramdom
- math
- os
经常使用的标准库 ①random
random是一个可以生成各种随机数的库。
# 举个例子
import random
print(random.random())
#结果
0.447948002492365
经常使用的标准库 ②math
math是一个帮助你进行数学计算的库。
# 举个例子
import math
print(math.pi)
print(math.ceil(4.2))
print(math.sqrt(4))
#结果
3.141592653589793
5
2.0
经常使用的标准库 ③OS
os主要能够进行文件和目录操作,允许你获得文件列表和路径,并创建新的文件和目录
# 举个例子
import os
path = './dir'
flist = os.listdir(path)
print(flist)
#结果
['hoge.py', 'sample1.txt', 'sample2.txt']
2、第三方库
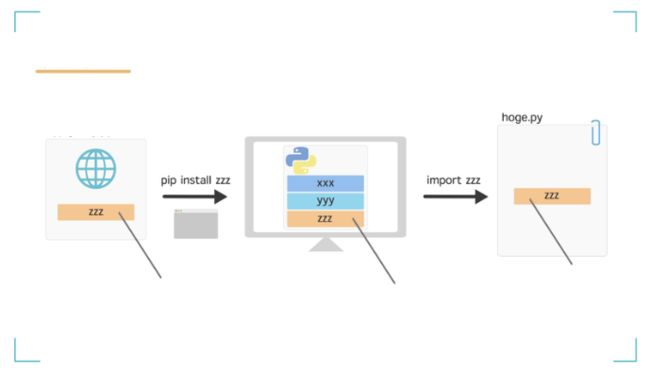
第三方库是没有作为标准提供的库,需要安装。
可以与Python一起使用的外部库主要是在PyPI网站上编译的。
以下是做机器学习时常用的第三方库列表。
- Numpy
- Pandas
- Matplotlib
- Scikit-learn
- pip
经常使用的第三方库 ①Numpy
NumPy是一个用于快速矩阵计算的库,通常用于科学和数值计算。
# 举个例子
import numpy as np
data = [[1, 2, 3, 4], [5, 6, 7, 8]]
arr = np.array(data)
print(arr)
print(arr.ndim)
print(arr.shape)
经常使用的第三方库 ②Pandas
Pandas是一个数据分析库,使数据分析变得简单。
# 举个例子
import pandas as pd
cnt = pd.Series([10, 20, 30, 50, 80, 130])
print(cnt)
#结果
0 10
1 20
2 30
3 50
4 80
5 130
dtype: int64
经常使用的第三方库 ③Matplotlib
Matplotlib是一个Python绘图库。
# 举个例子
import math
import numpy as np
from matplotlib import pyplot
pi = math.pi
x = np.linspace(0, 2*pi, 100)
y = np.sin(x)
pyplot.plot(x, y)
pyplot.show()

经常使用的第三方库 ④Scikit-learn
Scikit-learn是一个实现各种机器学习方法的库。
# 举个例子
#导入所需的库和数据集
import pandas as pd
import sklearn
from sklearn.datasets import load_iris, load_boston
#读取虹膜数据集。
iris = load_iris()
#将这些特征存储在一个数据框中,并显示前五行。
iris_features = pd.DataFrame(data = iris.data, columns = iris.feature_names)
#将标签串联起来存放。
iris_label =pd.Series(iris.target)
#分为训练和测试数据。
from sklearn.model_selection import train_test_split
features_train, features_test, label_train, label_test = train_test_split(iris_features, iris_label,test_size =0.5, random_state=0)
#导入所需的模块。
from sklearn import svm
#创建一个LinearSVM的实例。
Linsvc = svm.LinearSVC(random_state=0, max_iter=3000)
#用LinearSVM学习数据。
Linsvc.fit(features_train,label_train)
#用LinearSVM预测虹膜种类。
label_pred_Linsvc = Linsvc.predict(features_test)
print(label_pred_Linsvc)
#结果
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 2 0 0 2 0 0 1 1 0 2 2 0 2 2 1 0
2 1 1 2 0 2 0 0 1 2 2 1 2 1 2 2 1 2 2 2 2 1 2 2 0 2 1 1 1 1 2 0 0 2 1 0 0
1]
经常使用的第三方库 ⑤PIP
pip是一个管理库(包)的库
# 举个例子
pip install numpy
pip uninstall numpy
pip list
pip -v
这就是这篇文章的所有内容。
如果你也正在学习python,欢迎加入我的大本营,解答疑惑、python资料,兼职副业应有尽有